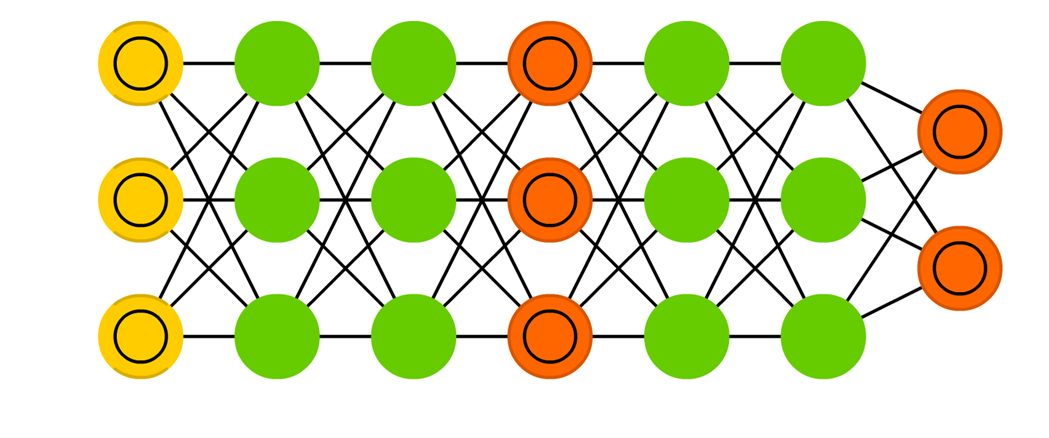
1. 딥러닝이란?
1. 딥러닝 모델이란?
딥러닝 모델은 입력값을 넣으면 출력값이 나오는 기계라고 생각하면 된다!
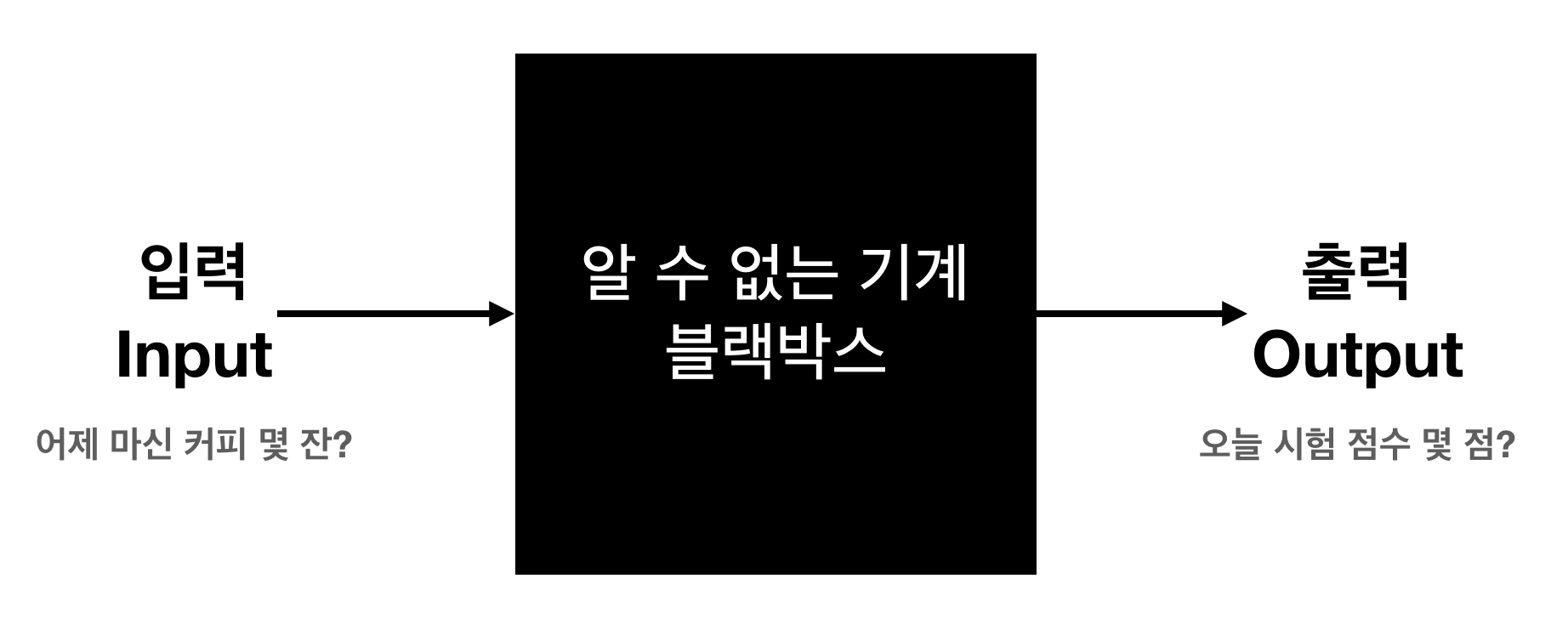
딥러닝 모델은 인간이 해결할 수 없는 문제를 대신 풀어주는 기계같은 것이다!
때문에 사람은 모델이 문제를 정확하게 풀게 하기 위해 학습을 시켜주는 역할을 한다.
- 대표적인 딥러닝의 종류
- Deep Feedforward Network(DFN)
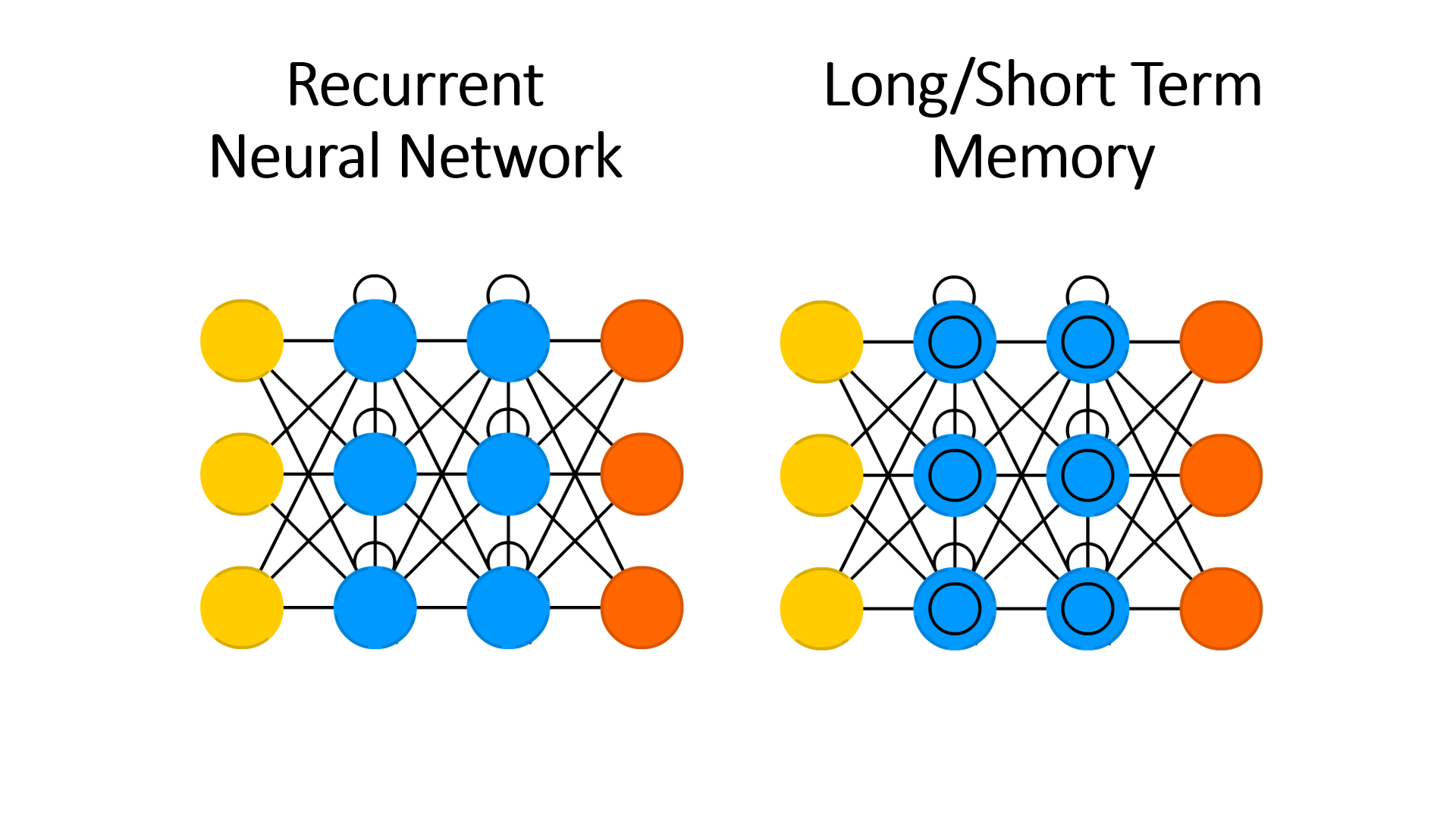
- Recurrent Neural Network (RNN)과 Long/Short Term Memory (LSTM)
- Convolutional Neural Network (CNN)
- Generative Adversarial Network (GAN)
2. 이미지 처리
- 이미지를 불러오는 방법
import cv2
img = cv2.imread('01.jpg')
print(img)
위 코드를 실행시키면 위의 사진과 같은 결과가 나오는데 이는 컴퓨터가 보는 사진의 형태로, 컴퓨터가 보는 사진의 형태는 숫자 라는 것이다.
- 이미지 형태 보기
import cv2
img = cv2.imread('01.jpg')
print(img.shape) # (404, 640, 3) = (높이, 너비, 채널)
위 코드를 실행시키면 위의 사진과 같은 결과가 나오는데 이 결과로 컴퓨터는 사진을 3차원으로 인식한다는 것을 알 수 있다!
여기서 404는 높이, 640은 너비, 3은 색상 채널을 뜻한다.
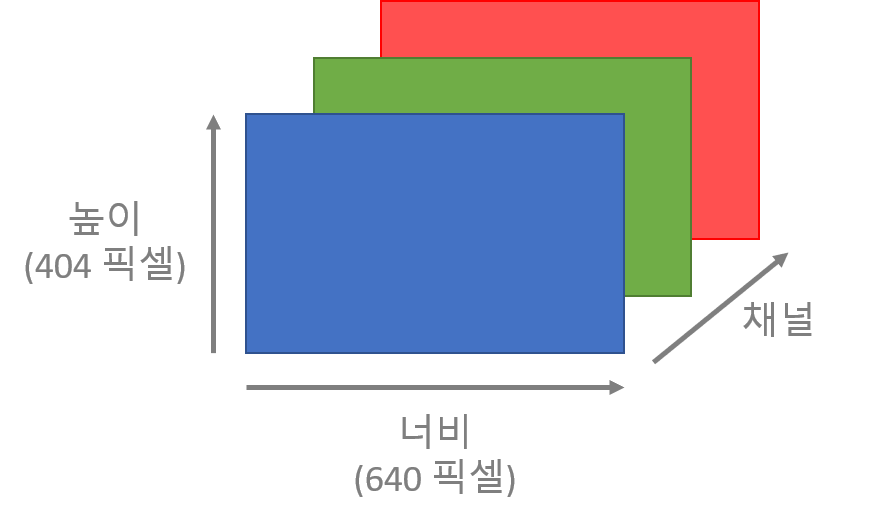
위 사진을 보면 색상 채널은 또 3가지 채널로 나뉘어져 있는데 이를 BGR(Blue-Green-Red)라고 하고 파랑, 초록, 빨강에 대한 색상 정보가 포함되어 있다.
- BGR
각 BGR은 0~255의 값을 가지며 컴퓨터는 BGR를 적절히 섞어 다양한 색상을 표현한다.
예1) B 255, G 0, R 0 → 파란색
예2) B 255, G 255, R 255 → 하얀색
예3) B 235, G 158, R 52 → 애매한 하늘색
- 이미지 미리보기
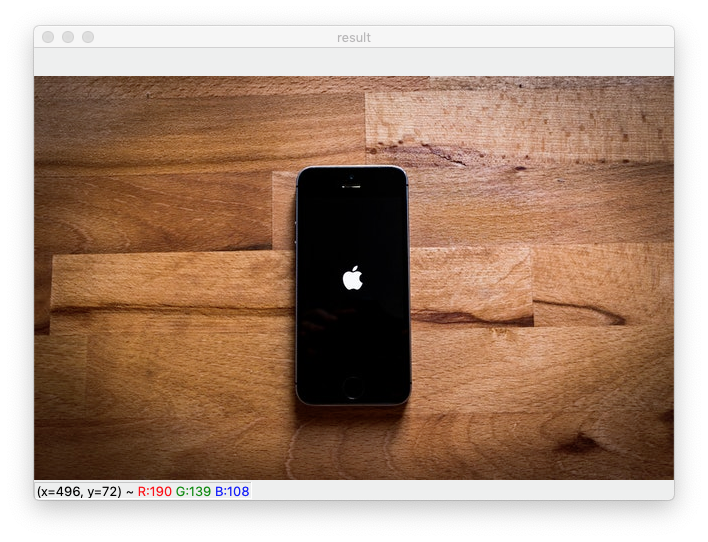
cv2.imshow('result', img)
cv2.waitKey(0)cv2.imshow 는 image show의 약자로, 'result'는 이미지를 띄우는 창의 이름이고 img 는 우리가 불러오는 이미지를 뜻한다.
cv2.waitKey(0) 으로 설정하면 아무 키를 입력할 때까지 이미지를 띄운 창이 사라지지 않는다.
3. 이미지 처리 기초
- 이미지 위에 도형 그리기
- 사각형 그리기
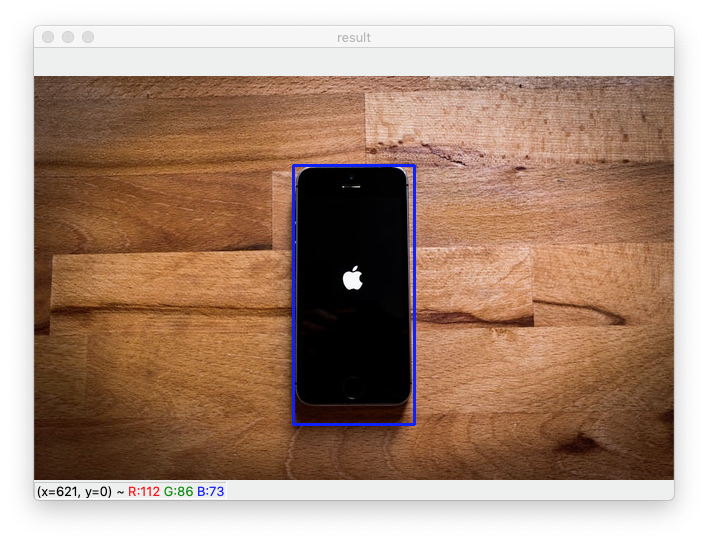
cv2.rectangle(img, pt1=(259, 89), pt2=(380, 348), color=(255, 0, 0), thickness=2)cv2.rectangle 함수는 직사각형을 그릴 수 있게 도와주는 함수이다.
img: 사각형을 그릴 이미지pt1: 사각형의 왼쪽 위 좌표pt2: 사각형의 오른쪽 아래 좌표color: 사각형의 색깔 (BGR 순서)thickness: 도형 선의 두께(음수를 사용하면 원 안이 채워진다!)
- 원 그리기
cv2.circle(img, center=(320, 220), radius=100, color=(255, 0, 0), thickness=2)cv2.circle 함수는 원을 그릴 수 있게 도와주는 함수이다.
img: 원을 그릴 이미지center: 원의 중심 좌표radius: 원의 반지름color: 원의 색깔 (BGR 순서)thickness: 도형 선의 두께(음수를 사용하면 원 안이 채워진다!)
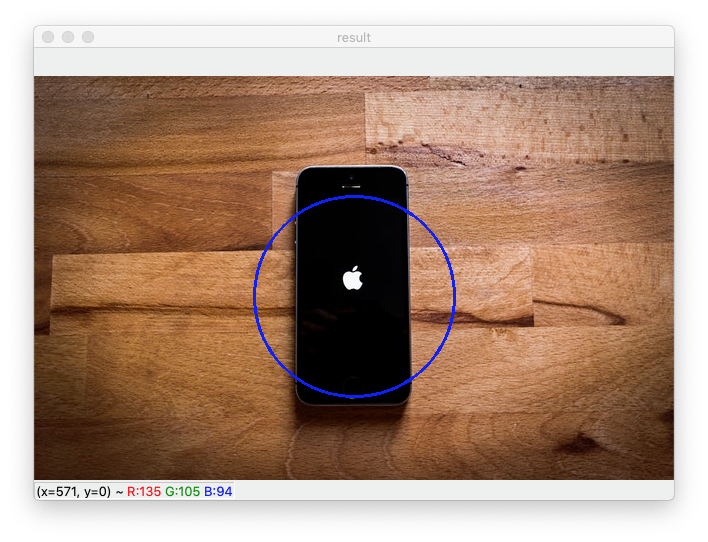
- 이미지 만져보기
- 이미지 자르기 (crop)
cropped_img = img[89:348, 259:380]
cv2.imshow('cropped', cropped_img)위의 코드는 y 축으로 89에서 348까지, x 축으로 259에서 380까지 자르려고 한다. 이미지를 자를 때는 y, x 순서로 쓴다.
이미지를 자를 때 y, x 순으로 쓰는 이유는 OpenCV가 이미지를 저장할 때 기본적으로 numpy 를 쓰기 때문이다. C 스타일의 언어에서는 y → x 순서로 사용하고 Fortran 스타일의 언어에서는 x → y 로 사용한다.
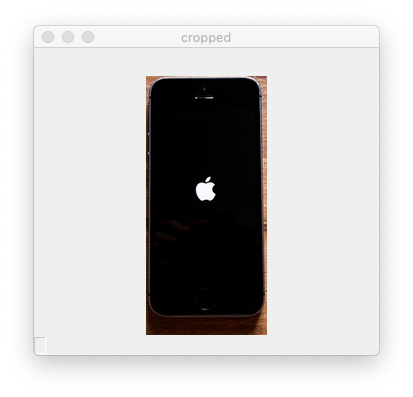
- 이미지 크기 변경하기 (resize)
딥러닝 모델에 이미지를 넣기 전에 꼭 필요한 작업이 이미지의 크기를 변경하는 작업이다! 왜냐하면 모델을 학습시킬 때 이미지의 크기를 고정해야 성능이 좋기 때문이다.
img_resized = cv2.resize(img, (512, 256))
cv2.imshow('resized', img_resized)
cv2.waitKey(0)cv2.resize 명령어를 사용하여 이미지의 크기를 자유자재로 변경할 수 있다. 위의 코드는 img 를 가로 512, 세로 256 으로 크기를 변경하여 resized 에 저장하고 img_resized 의 미리보기하는 코드이다.

- 이미지 컬러 시스템 바꾸기
컬러 시스템은 색깔을 표현하는 방법이다.
예를들면 BGR(파랑색, 초록색, 빨간색) 의 3가지 색깔을 섞어 색깔을 표현할 수도 있고, CMYK(하늘색, 분홍색, 노랑색, 검정색)의 4가지 색깔을 섞어 색깔을 표현할 수 있다.
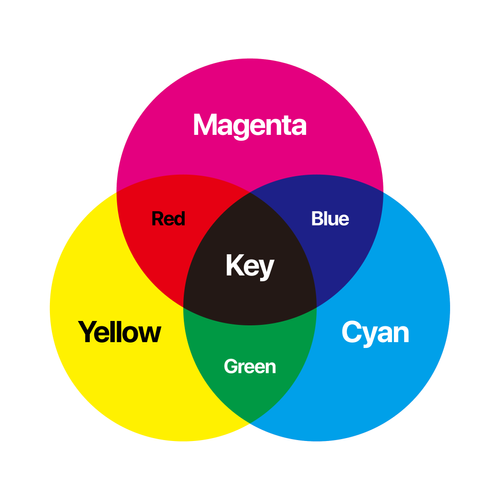
기본적으로는 BGR 시스템을 주로 사용하지만 경우에 따라 RGB 시스템을 사용해야하는 경우도 있고, Lab 시스템을 사용해야하는 경우도 있다.
모델을 만든 사람이 모델을 학습 시키면서 여러 컬러 시스템으로 변경하면서 학습을 시키는데 그 중 가장 정확도가 좋았던 컬러 시스템을 사용하기 때문!!
- 이미지 컬러 시스템 변경하기
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2.imshow('result', img_rgb)
cv2.waitKey(0)위의 코드를 실행하게 되면 BGR → RGB 로 컬러시스템을 변경했기 때문에 빨강과 파랑 채널이 바뀌어 이상한 색깔의 이미지가 윈도우에 출력된다.

img_rgb = cv2.cvtColor(img, cv2.COLOR_**BGR2GRAY**)
cv2.imshow('result', img_rgb)
cv2.waitKey(0)cv2.COLOR_BGR2 대신에 cv2.COLOR_BGR2GRAY를 사용하면 이미지가 흑백사진으로 출력된다.

4. 이미지 처리 심화
- 배경 이미지 위에 다른 이미지를 합성하기 (Overlay)
1. 오버레이 띄우기
import cv2
img = cv2.imread('01.jpg')
overlay_img = cv2.imread('dices.png', cv2.IMREAD_UNCHANGED)배경 이미지(아이폰)는 img변수에 저장하고 우리가 배경 이미지 위에 띄울 오버레이 이미지(주사위)를 overlay_img에 저장하면 된다.
똑같이 cv2.imread() 를 사용하여 이미지를 로드해 오지만 주사위 이미지에는 cv2.IMREAD_UNCHANGED 를 뒤에 붙여줘야 한다!
이 이유는 오버레이 할 이미지는 확장자가 .png 인 배경이 투명한 이미지여야 하는데, cv2.imread()를 사용하여 png 이미지를 로드할 때는 꼭 cv2.IMREAD_UNCHANGED를 붙여줘야 배경 투명도를 유지한 상태로 로드가 되기 때문이다!!

2. 이미지 크기 변환하기
overlay_img = cv2.resize(overlay_img, dsize=(150, 150))3. 투명도를 이용하여 이미지 끼워맞추기
- 투명도(Alpha)란?
각 픽셀이 얼마나 투명한지 나타내는 값!
완전히 투명하면 0, 불투명하다면 255의 값을 가진다.
BGR에 A까지 더해, 총 4개 채널을 이용하면 색 뿐만 아니라 반투명한 이미지, 바탕만 투명한 이미지, 픽셀의 색이 진할수록 불투명한 이미지 등 다양한 투명도를 나타낼 수 있다.
우리의 오버레이 이미지는 투명도가 있는 이미지이기 때문에 채널이 총 4개이다. (투명도 채널 추가!)
4번째 채널인 투명도 채널은 색깔을 표현하는게 아니라 투명도를 표현한다!
이미지에서 어느 부분이 투명하고 어느 부분이 불투명한지 표현하는 채널!
투명도를 표시할 때 불투명한 부분은 255로 표현하고 투명한 부분은 0으로 표현한다.
3-1. 오버레이 이미지
overlay_alpha = overlay_img[:, :, 3:] / 255.0
background_alpha = 1.0 - overlay_alpha위의 코드는 배경 이미지와 오버레이 이미지를 퍼즐처럼 끼워맞추기 위해 필요한 코드이다.
오버레이 이미지에서 어레이 슬라이싱을 할 때 투명도 채널 부분만 잘라줘야 하기 때문에 색상 채널부분을 3: 이라고 작성해야 한다.(0은 B 1은 G 2는 R 3은 A를 뜻함)
-> 알파채널(투명도 채널)만 가져올 수 있다!!
알파 채널은 0~255의 숫자로 이루어져 있는데 이걸 0~1사이의 값으로 만들어주기 위해 255로 나누어 준다.
-> 주사위의 알파값(투명도값)
또한 백그라운드 알파는 주사위와 반대의 값이므로 1에서 오버레이 알파를 빼주면 된다!
- 오버레이 이미지 입장에서 생각하기
오버레이 이미지 입장에서는 배경을 아무것도 없는 0으로 만들고(검은색) 주사위 부분을 색깔로 채워야한다.

- 배경 이미지 입장에서 생각하기
배경 이미지 입장에서는 주사위 부분 0으로 만들고(검은색) 나머지 부분은 배경으로 채워야한다.

→ 위와 같이 가공한 두 개의 이미지를 합쳐주면 나무판 위에 주사위가 올라간 합성 이미지가 탄생!!
3-2. 이미지 합성하기
x1 = 100
y1 = 100
x2 = x1 + 150
y2 = y1 + 150
img[y1:y2, x1:x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[y1:y2, x1:x2]이미지 자르기를 할 때와 비슷하게 x1, y1, x2, y2 좌표를 사용하여 오버레이 이미지의 위치와 크기를 지정해준 후 배경 이미지의 (100, 100) 위치에 (150, 150) 크기의 오버레이 이미지를 올리면 된다.
주사위의 투명도값 * 주사위의 이미지(BGR 색상 정보만 포함)
-> 주사위가 있는 부분만 불투명하게 되고 주사위가 없는 부분은 투명하게 됨(투명도를 가지고 자기 자신의 색상 정보 또한 가지도록 해라)
백그라운드 투명도값 * 기존 이미지의 자른 부분
-> 주사위 부분만 투명하게, 백그라운드 부분은 불투명하게(이미지값은 원래 3채널이었기 때문에 슬라이싱 필요 없음)

5. 동영상 처리
- 동영상 출력하기
import cv2
cap = cv2.VideoCapture('04.mp4')
while True:
ret, img = cap.read()
if ret == False:
break
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
breakcv2.VideoCapture()
동영상 파일을 불러올 때 쓴다.
괄호 안에 동영상 파일의 경로를 입력하면 해당 영상 파일을 로드while True:
아래 코드를 반복하면서 실행한다. 무한루프!!ret, img = cap.read()
cap.read()를 사용하여 동영상 파일에서 한 개의 프레임을 읽어온다. 영상은 수 백개, 수 천개의 프레임으로 이루어져 있고 각 프레임은 사진 1장과 같다. 반대로 말하면 여러 프레임을 합치면 영상 파일이 된다는 것!!

ret변수에는 영상에서 제대로 프레임을 읽어 왔을 때True가 저장되고 프레임이 더 이상 존재하지 않거나 에러가 발생했을 때False가 저장된다.img변수에는 읽어 온 1개의 프레임이 저장된다. 만약ret이False일 경우None이 저장된다.
if ret == False:
break따라서 ret 이 False 라면 프레임이 더 이상 존재하지 않으므로 무한루프에서 빠져나와 프로그램을 종료해야 한다.
- 동영상 종료하기
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break위에 이미지와 마찬가지로 cv2.imshow() 를 사용하여 result라는 이름의 윈도우에 img를 출력한다.
cv2.waitKey(1) 1ms (0.001초) 동안 키보드의 입력을 기다린다.
만약 키보드의 q 버튼을 누르면 무한루프에서 빠져나와 프로그램을 종료한다.
6. 동영상 처리 심화
- 영상에서 도형 출력하기
영상에서 한 프레임씩 이미지를 받아올 때 cap.read() 를 사용해서 받아오고, 받아온 프레임(이미지)을 img 변수에 저장했으니 img 에는 이미지가 들어있을 것이다!! 그 이미지 위에 도형을 그리고 출력하면 끝!
cv2.rectangle(img, pt1=(721, 183), pt2=(878, 465), color=(255, 0, 0), thickness=2)- 영상 그레이스케일로 만들기
이미지의 경우와 마찬가지로 cv2.cvtColor() 를 사용하여 이미지를 그레이스케일로 변환한다.
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)- 영상 크기 변환하기 (Resize)
img = cv2.resize(img, dsize=(640, 360))- 영상 자르기 (Crop)
img = img[100:200, 150:250]- 캠 영상을 화면에 띄우기
동영상 출력하기 사용했던 cv2.VideoCapture() 함수를
cap = cv2.VideoCapture('03.mp4')웹캠 영상을 로드하려면 영상 파일 대신에 0 을 넣어주면 된다! 나머지
cap = cv2.VideoCapture(0)cv2.VideoCapture(0) 의 의미!
여기서 0의 의미는 0번 디바이스에 연결하라는 의미이다. 만약 컴퓨터에 연결되어 있는 웹캠이 3개라면 디바이스의 번호가 0, 1, 2 이렇게 3개로 나누어져 있을 것이다!!
