오픈 소스 LLM
정보 유출 우려가 적고, 서비스 안정성, 가격 측면에서 API 활용보다 좋은 선택지
OpenAI나 Google의 제미나이의 경우 지속적인 API 비용이 소모되고, API 의존성이 높아져서 서비스 안정성이 떨어진다. 그리고 API 통신 시 기업 정보 유출 우려가 있다.
오픈 소스의 경우 GPU 서버 구축이 필요하지만 추가 비용이 없고, 서버 운영만 잘하면 운영 리스크가 없다. 그리고 기업 내부 서버를 이용하므로 유출 우려가 없다.
오픈 소스의 경우 한국어 데이터가 부족해 한국어를 잘 못하는 모델들이 많다. 그래서 토종 오픈 소스 LLM들을 모앗허 어떤 모델이 맞는지 확인 하는 것이 필요하다.
업스테이지와 NIA가 주관한 한국어 오픈소스 LLM 리더보드가 운영 중이다.
이 리더보드를 통해 최신 오픈 소스 LLM의 성능을 비교하고 허깅페이스를 통해 활용 가능하다.
오픈 소스 LLM의 양자화
대부분의 LLM 모델은 개인 PC의 GPU에서는 구동하기에 힘든 수준이다. (70억개 수준이기 때문에)
따라서 양자화(Quantization)을 통해 경량화한 후 활용
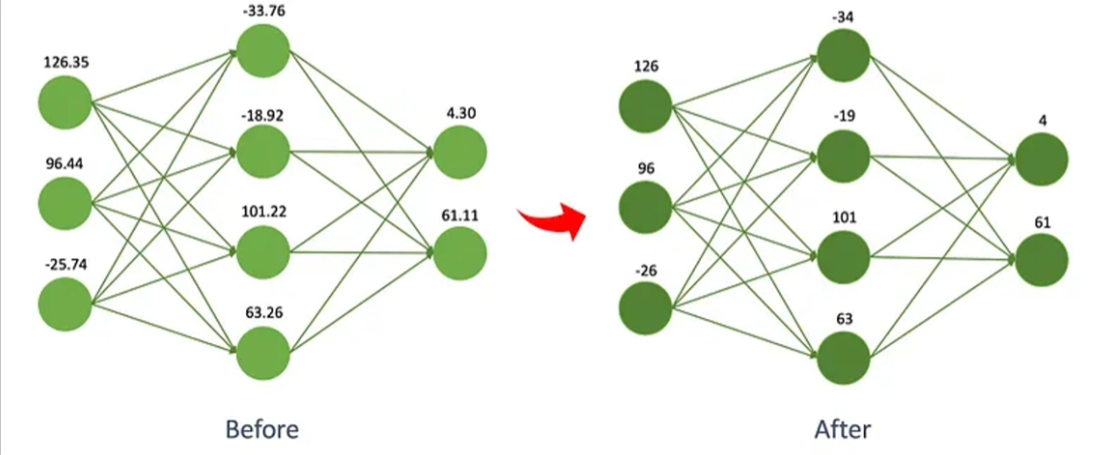
양자화는 Neural Network 상에서 계산하는 수의 소수점을 줄이는 것
오픈 소스 LLM 구동하기
- 1단계 - LLM 양자화에 필요한 패키지 설치
- bitsandbytes: Bitsandbytes는 CUDA 사용자 정의 함수, 특히 8비트 최적화 프로그램, 행렬 곱셈(LLM.int8()) 및 양자화 함수에 대한 경량 래퍼
- PEFT(Parameter-Efficient Fine-Tuning): 모델의 모든 매개변수를 미세 조정하지 않고도 사전 훈련된 PLM(언어 모델)을 다양한 다운스트림 애플리케이션에 효율적으로 적용 가능
- accelerate: PyTorch 모델을 더 쉽게 여러 컴퓨터나 GPU에서 사용할 수 있게 해주는 도구
Colab 런타임 유형은 T4 GPU 유형으로
!pip install -q -U bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git- 2단계 - 트랜스포머에서 BitsandBytesConfig를 통해 양자화 매개변수 정의하기
- load_in_4bit=True: 모델을 4비트 정밀도로 변환하고 로드하도록 지정
- bnb_4bit_use_double_quant=True: 메모리 효율을 높이기 위해 중첩 양자화를 사용하여 추론 및 학습
- bnd_4bit_quant_type="nf4": 4비트 통합에는 2가지 양자화 유형인 FP4와 NF4가 제공됨. NF4 dtype은 Normal Float 4를 나타내며 QLoRA 백서에 소개되어 있습니다. 기본적으로 FP4 양자화 사용
(bit and bite 를 조금 더 공부 하고 양자화에 대해서 더 알고 내 모델의 어떤 특성을 가져야 하는지 어떤 gpu 상에서 돌아야 하는지에 따라 달라짐) - bnb_4bit_compute_dype=torch.bfloat16: 계산 중 사용할 dtype을 변경하는 데 사용되는 계산 dtype. 기본적으로 계산 dtype은 float32로 설정되어 있지만 계산 속도를 높이기 위해 bf16으로 설정 가능
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)- 3단계 - 경량화 모델 로드하기
model_id = "kyujinpy/Ko-PlatYi-6B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map="auto")quantization_config은 경량화 기법을 어떻게 할 것인가?는 bnb_config에서 정의를 했기 때문에 그대로 넣어 줌
print(model)LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(78464, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=512, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=512, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear4bit(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=78464, bias=False)
)- 4단계 - 잘 실행되는지 확인
device = "cuda:0"
messages = [
{"role": "user", "content": "은행의 기준 금리에 대해서 설명해줘"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
No chat template is defined for this tokenizer - using the default template for the LlamaTokenizerFast class. If the default is not appropriate for your model, please set `tokenizer.chat_template` to an appropriate template. See https://huggingface.co/docs/transformers/main/chat_templating for more information.
<|startoftext|> [INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
은행의 기준 금리에 대해서 설명해줘 [/INST]
[SYSTEM]
은행의 기준금리는 시장에서 대출 및 투자를 위해 시중의 유동성을 확보하고 관리하는 데 사용되며 대중에 영향을 미치는 금리다.
은행의 기준금리를 결정하는 데에는 다양한 변수, 즉 인플레이션, 경제의 경기 상황, 고용 및 물가 수요에 대한 전망 등 여러 가지가 고려됩니다. 이러한 요인들이 적절하게 균형을 이루면 자금 흐름이 원활해지고 경제는 순조롭게 성장하게 됩니다.
그러나 최근 금리 인상이 계속되면서 경제 성장 둔화와 부채 위기에 대한 우려가 제기되고 있습니다. 높은 금리가 기업과 가계의 재정 상황 및 경제 전반에 미치는 영향을 고려하여 통화정책을 신중하게 관리해야 합니다.<|endoftext|>- 5단계-RAG 시스템 결합
# pip install시 utf-8, ansi 관련 오류날 경우 필요한 코드
import locale
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencodingfrom langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from transformers import pipeline
from langchain.chains import LLMChain
text_generation_pipeline = pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
temperature=0.2,
return_full_text=True,
max_new_tokens=300,
)
prompt_template = """
### [INST]
Instruction: Answer the question based on your knowledge.
Here is context to help:
{context}
### QUESTION:
{question}
[/INST]
"""
koplatyi_llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
# Create prompt from prompt template
prompt = PromptTemplate(
input_variables=["context", "question"],
template=prompt_template,
)
# Create llm chain
llm_chain = LLMChain(llm=koplatyi_llm, prompt=prompt)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
from langchain.schema.runnable import RunnablePassthroughloader = PyPDFLoader("/content/drive/MyDrive/강의 자료/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_documents(pages)
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
encode_kwargs=encode_kwargs
)
db = FAISS.from_documents(texts, hf)
retriever = db.as_retriever(
search_type="similarity",
search_kwargs={'k': 3}
)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| llm_chain
)
result = rag_chain.invoke("혁신성장 정책 금융에서 인공지능이 중요한가?")
for i in result['context']:
print(f"주어진 근거: {i.page_content} / 출처: {i.metadata['source']} - {i.metadata['page']} \n\n")
print(f"\n답변: {result['text']}") /usr/local/lib/python3.10/dist-packages/transformers/generation/configuration_utils.py:389: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.2` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.
warnings.warn(
주어진 근거: | 8 | CIS이슈리포트 2022-2 호 ▶(주요품목 ② : 인공지능 ) 정보통신 테마 내 기술분야 중 정책금융 공급규모 증가율이 가장 높은
능동형컴퓨팅 분야의 경우, 인공지능 품목의 정책금융 공급 비중이 가장 높으며 , 이는 빅데이터
분석기술의 발전으로 인해 인공지능의 활용처가 넓어짐에 따른 것으로 분석됨
[능동형컴퓨팅 분야 내 기술품목별 혁신성장 정책금융 공급액 추이]
(단위: 억 원)
주: 스마트물류시스템 품목은 2021 년부터 신규 품목으로 편임
▶인공지능은 인간의 학습능력과 추론·지각능력 , 자연언어 이해능력 등을 프로그램으로 구현한 기술로 ,
컴퓨터가 인간의 지능적인 행동을 모방하는 방향으로 발전하고 있음
○인공지능은 사람의 두뇌가 복잡한 연산을 수행하는 점을 모방해 뉴런(Neuron) 을 수학적으로 모방한
알고리즘인 퍼셉트론 (Perceptron) 을 이용하여 컴퓨터의 연산 로직을 처리하는 원리로 동작함
[인공지능 동작 개념]
구분 구조 / 출처: /content/drive/MyDrive/강의 자료/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf - 7
주어진 근거: 혁신성장 정책금융 동향 : ICT 산업을 중심으로
CIS이슈리포트 2022-2 호 | 9 |▶다양한 데이터나 복잡한 자료 속에서 핵심적인 특징을 요약하는 ①데이터 추상화 기술, 방대한 지식
체계를 이용하는 ②빅데이터 기술, 빅데이터를 처리하기 위한 ③고성능 컴퓨팅 기술이 인공지능
구현의 핵심임
○데이터를 추상화하는 방법은 크게 인공신경망 (ANN), 심층신경망 (DNN), 합성곱신경망 (CNN) 및
순환신경망 (RNN) 등으로 구분됨
[인공지능 데이터 추상화 기술]
구분 특징 장점 단점
인공신경망 (ANN)
Artificial Neural
Network사람의 신경망 원리와 구조를 모방하여 만든
기계학습 알고리즘으로 , 입력층 , 출력층 , 은닉층
으로 구성모든 비선형 함수
학습이 가능알고리즘을 최적화
하기 어려운 학습
환경 발생
심층신경망 (DNN)
Deep Neural
Network입력층과 출력층 사이에 2개 이상의 은닉층 / 출처: /content/drive/MyDrive/강의 자료/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf - 8
주어진 근거: 혁신성장 정책금융 동향 : ICT 산업을 중심으로
CIS이슈리포트 2022-2 호 | 3 |1. 들어가며
▶혁신성장 정책금융기관은 건강한 혁신산업 생태계를 조성하기 위해 기업 성장에 필요한 자금을
지원하는 혁신성장 정책금융 제도를 시행하고 있음
○혁신성장 정책금융기관은 혁신성장에 대한 정의를 구체화한 정책금융 가이드라인*에 따라 혁신성장
산업육성을 위한 정책금융 업무를 추진 중임
* 혁신성장 기업발굴 및 금융지원을 위해 활용하는 기준으로 , ‘9대 테마-46개 분야-296개 품목’으로 구성
▶혁신성장 정책금융 제도 시행 이후 공급 규모가 매년 증가하는 등, 미래 혁신성장 분야의 글로벌
경쟁력 확보를 위한 금융지원이 지속 추진 중임
○정책금융기관의 혁신성장 분야 정책금융 공급규모는 2017년 240,787 억 원에서 연평균 37.2% 증가
하여 2021 년 854,338 억 원에 이르는 등 그 외연을 확장해나가고 있음 / 출처: /content/drive/MyDrive/강의 자료/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf - 2
답변:
[ANSWER:
예, 혁신성장 정책 금융에서 인공지능은 중요한 역할을 합니다. 혁신성장 정책 금융은 건강한 혁신산업 생태계를 조성하기 위해 기업 성장에 필요한 자금을 지원하는 혁신성장 정책 금융 제도를 시행하고 있습니다. 혁신성장 정책 금융기관은 혁신성장에 대한 정의를 구체화한 정책금융 가이드라인에 따라 혁신성장 산업 육성을 위한 정책금융 업무를 추진하고 있습니다. 혁신성장 정책 금융에서 인공지능은 9대 테마, 46개 분야, 296개 품목으로 구성된 혁신성장 산업 육성의 핵심 분야 중 하나입니다. 혁신성장 정책 금융기관은 혁신성장 분야 정책금융 공급 규모를 매년 증가시켜 미래 혁신성장 분야의 글로벌 경쟁력을 확보하기 위한 금융 지원을 지속하고 있습니다