1. Splitters
- 파일 불러오기
with open('파일 경로') as f:
text_gen_ai = f.read()- 라이브러리 설치
!pip install langchain pypdf- 어떤 기준으로 나눌 것인지 정하기
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator='\n\n', # 문단으로 나누기
chunk_size= 1000, # 1000자씩 나누기
chunk_overlap=100, # 겹치는 크기 설정
length_function=len # 길이를 세는 단위 지
)- text를 documents로 만들기
docs = text_splitter.create_documents(texts)- PDF 파일 Split
from langchain.document_loaders import PyPDFLoader
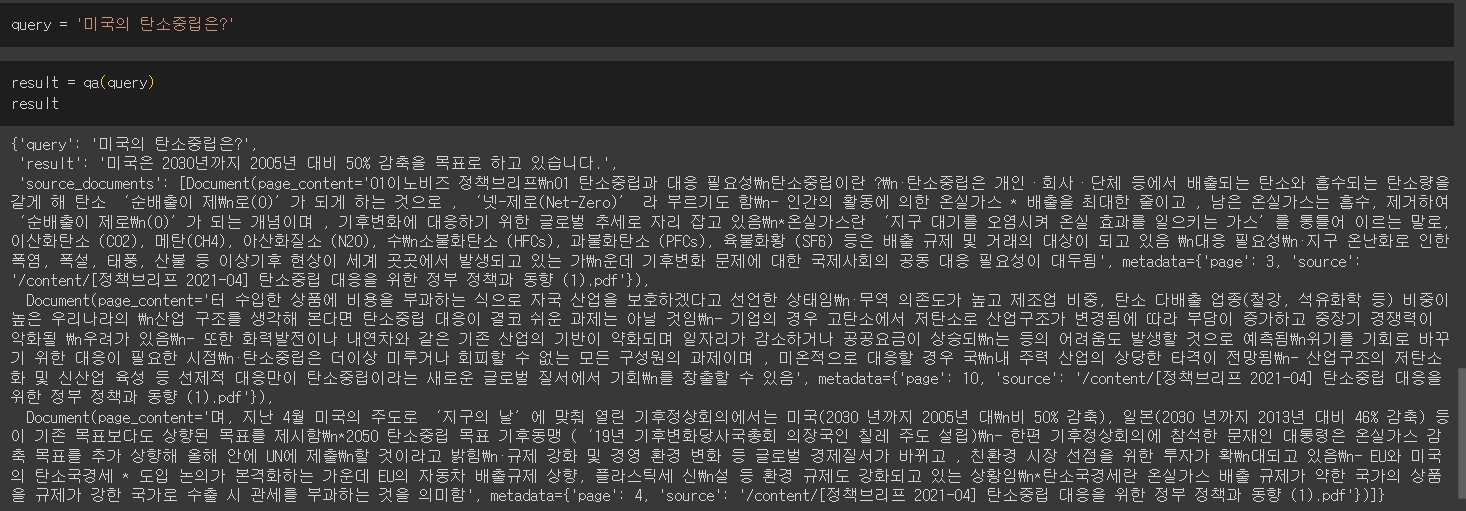
loader = PyPDFLoader('/content/[정책브리프 2021-04] 탄소중립 대응을 위한 정부 정책과 동향 (1).pdf')
pages = loader.load_and_split()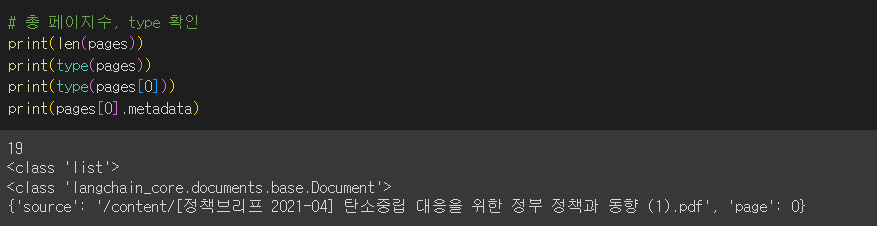
- docs 만들기
docs = text_splitter.split_documents(pages)- 각 페이지별 문자 수 출력
char_list = []
for i in range(len(docs)):
char_list.append(len(docs[i].page_content))
print(char_list) # 각 페이지별 문자 수 출력 -> 글자수가 넘쳐도 출력해줌 - RecursiveCharacterTextSplitter 사용
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap=100,
length_function=len
)
docs = text_splitter.create_documents([text_gen_ai])
-> 1000자가 넘는 페이지가 없음을 확인 가능
2. 토큰 단위 텍스트 분할기
!pip install tiktoken-
토큰 수를 세는 함수
import tiktoken
tiktoken.get_encoding('cl100k_base') -
토큰 수를 세는 함수
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
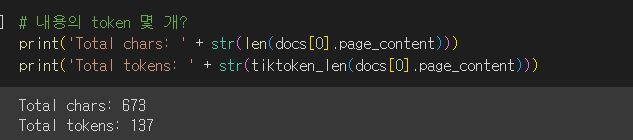
# 토큰 수를 세는 함수
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)-> 결과
- PDF의 내용을 Token 단위로 페이지 자르기
- splitter 변경
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap=50,
length_function=tiktoken_len
)
docs = text_splitter.split_documents(pages)- 각 페이지의 글자 수 출력
token_list = []
for i in range(len(docs)):
token_list.append(tiktoken_len(docs[i].page_content))
print(token_list)-> 한글을 사용하면 영어에 비해 토큰 수 증가
3. 임베딩
- 설치
!pip install openai langchain pypdf tiktoken- AzureOpenAIEmbeddings
embeddings_model = AzureOpenAIEmbeddings(
model ='dev-text-embedding-ada-002'
)
- embeddings
embedding_result = embeddings_model.embed_documents(
{
'안녕하세요',
'제 이름은 홍길동입니다.',
'이름은 무엇인가요?',
'랭체인은 유용합니다',
'Hello World'
}
)# 가장 가까운 벡터값을 찾아주는 것으로 결과 출력
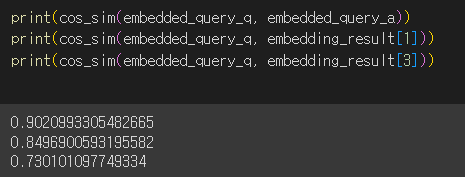
embedded_query_q = embeddings_model.embed_query('이 대화에서 언급한 이름은 무엇입니까?')
embedded_query_a = embeddings_model.embed_query('이 대화에서 언급한 이름은 홍길동입니다.')- 벡터의 거리를 측정
from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A,B):
distance = dot(A,B) / (norm(A)*norm(B))
return distance
4. Huggingface Embedding
- https://huggingface.co/
- !pip install sentence_transformers
1) BAAI/bge-small-en 모델
- model 다운로드
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = 'BAAI/bge-small-en'
model_kwargs = {'device':'cpu'} # cpu 사용
encode_kwargs = {'normalize_embeddings':True}
# 다운받을 모델명(영어만 가능 -> 낮은 차원으로 임베딩)
hf = HuggingFaceBgeEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)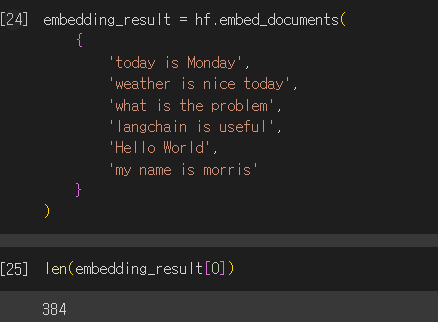
2) ko-sbert-nli 모델
- 모델 다운로드
model_name = 'jhgan/ko-sbert-nli'
model_kwargs = {'device':'cpu'}
encode_kwargs = {'normalize_embeddings':True}
hf = HuggingFaceBgeEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)sentence = [
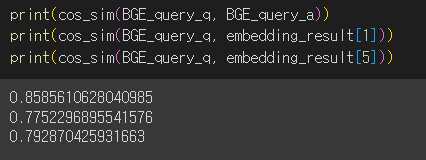
'안녕하세요',
'제 이름은 홍길동입니다.',
'이름이 무엇인가요?',
'랭체인은 유용합니다.',
'홍길동 아버지의 이름은 홍상직 입니다.'
]
embedding_result = hf.embed_documents(sentence)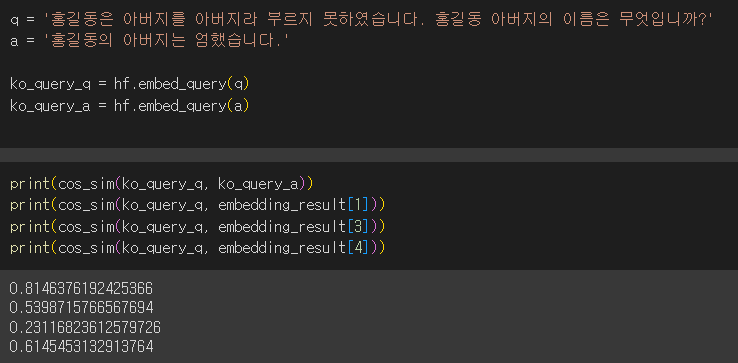
5. Vector DB
- 설치
!pip install langchain tiktoken pypdf sentence_transformers chromadb- splitter 만들기
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 50,
length_function=tiktoken_len
)- pdf 파일 읽어오기
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader('/content/[정책브리프 2021-04] 탄소중립 대응을 위한 정부 정책과 동향 (1).pdf')
pages = loader.load_and_split()
- 임베딩
from langchain.embeddings import HuggingFaceEmbeddings
model_name = 'jhgan/ko-sbert-nli'
model_kwargs={'device':'cpu'}
encode_kwargs={'normalize_embeddings':True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)- Vector store에 저장
# 데이터 split
docs = text_splitter.split_documents(pages)
# Vector Store 저장
from langchain.vectorstores import Chroma
db = Chroma.from_documents(docs, hf): 만들어진 db는 메모리에 저장됨 -> 껐다 켜면 날라감
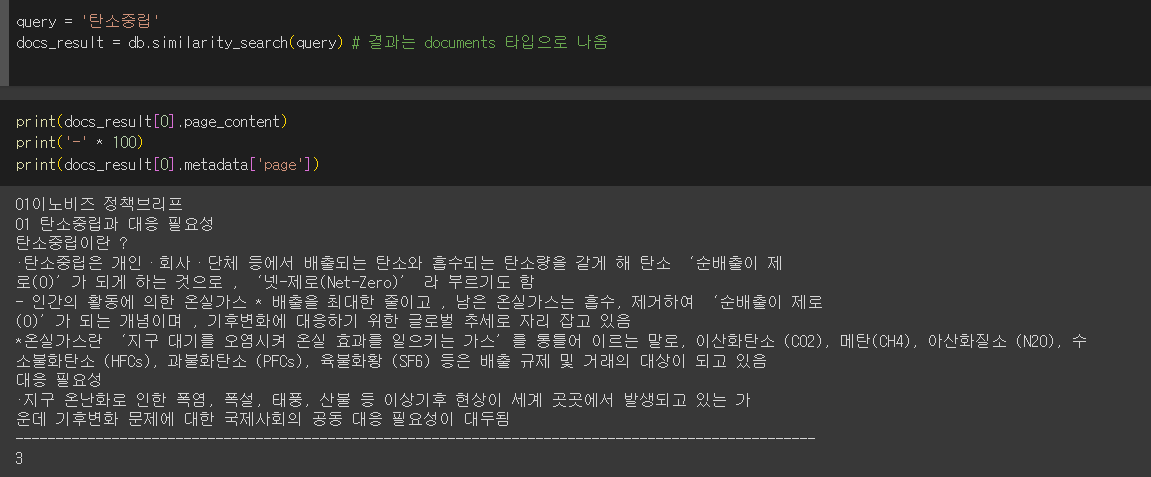
db = Chroma.from_documents(docs, hf, persist_directory='./chroma_db')
db2 = Chroma(persist_directory='./chroma_db',
embedding_function=hf)6. FAISS
대량의 고차원 벡터에서 유사성 검색 및 클러스터링을 빠르고 효율적으로 수행 가능
기능: 유사성 검색 + 인덱스 생성
- 설치
!pip install faiss-cpu- db
from langchain.vectorstores import FAISS
db = FAISS.from_documents(docs, hf)7. Retriveal
- 설치
!pip install openai langchain pypdf tiktoken sentence_transformers chromadb- PDF 파일 불러오기
# Data loading
import openai
import tiktoken
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import AzureChatOpenAI
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
loader = PyPDFLoader('/content/[정책브리프 2021-04] 탄소중립 대응을 위한 정부 정책과 동향 (1).pdf')
pages = loader.load_and_split()- splitter 준비
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=tiktoken_len
)- 모델 불러오기
from langchain.embeddings import HuggingFaceEmbeddings
model_name='jhgan/ko-sbert-nli'
model_kwargs={'device':'cpu'}
encode_kwargs={'normalize_embeddings':True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)- split + db에 넣기
# split
docs = text_splitter.split_documents(pages)
# db에 넣기
db = Chroma.from_documents(docs, hf)- 언어 모델 생성
chatgpt = AzureChatOpenAI(
deployment_name='dev-gpt-35-turbo'
)qa = RetrievalQA.from_chain_type(
llm = chatgpt,
chain_type = 'stuff',
retriever = db.as_retriever(
search_type = 'mmr',
search_kwargs = {'k':3,'fetch_k':10}
),
return_source_documents=True
)- 결과