이번 포스팅에서는 Spring JDBC를 사용하여 Batch Insert 적용해보도록 하겠습니다.
🙌 문제점
Evertrip 프로젝트를 진행하는 중 게시글 생성과 관련하여 게시글의 본문에 저장된 파일 ID의 목록을 받아서 게시글-파일 중간 테이블에 INSERT 해줘야했습니다.
저장하려는 엔티티의 목록을 Iterator를 통해 순회하며 save() 메서드를 사용하여 저장한다면 엔티티 당 INSERT 쿼리가 나가게 됩니다.
이러한 문제를 개선하기 위해 크게 두가지 방법이 있었습니다.
1. JPA Batch Insert 활용
saveAll() 메서드를 사용하여 JPA Batch Insert를 구현할 수 있습니다. JPA Batch Insert는 여러 개의 INSERT 문을 하나의 커넥션을 통해 한꺼번에 전송하여 성능을 최적화시켜줍니다.
하지만 진행중인 프로젝트에서는 @GeneratedValue(strategy = GenerationType.IDENTITY)을 사용하고 있기 때문에 JPA Batch Insert이 제대로 동작하지 않았습니다. IDENTITY 전략은 각 INSERT문이 실행될 때마다 즉시 데이터베이스로 보내져야 하기 때문에(PK 반환을 위해) 여러 개의 쿼리를 한꺼번에 보내주는 JPA Batch Insert이 제대로 동작하지 않는 것입니다.
📝 테스트
@RestController
@RequiredArgsConstructor
public class TestController {
private final PostContentFileRepository repository;
@PostMapping("/test")
@Transactional
public void save(@RequestBody List<Long> fileIds) {
List<PostContentFile> files = new ArrayList<>();
for (Long id: fileIds) {
PostContentFile file = new PostContentFile(id, 1L);
files.add(file);
}
repository.saveAll(files);
System.out.println(files);
}
}saveAll() 메서드를 사용하여 JPA Batch Insert를 적용해보았습니다.
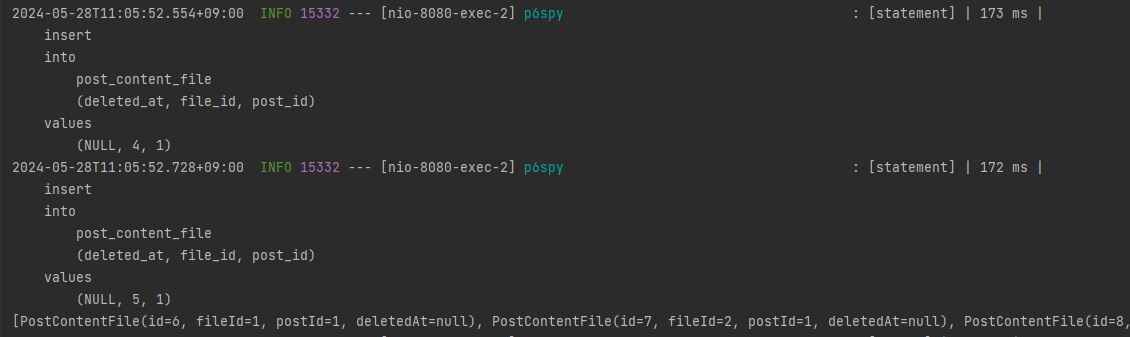
위의 로그를 확인하시면 INSERT 쿼리가 실행된 후 System.out.println(files)가 실행된 것을 확인할 수 있습니다. 즉, 각각의INSERT 문들이 따로 쿼리 전송이 일어난 것을 확인할 수 있습니다.
2. Spring JDBC 활용
다른 방법으로 Spring JDBC를 사용하여 Batch Insert를 적용할 수 있습니다.

현재 사용중인 spring-boot-starter-data-jpa 라이브러리 내부에 jdbc 라이브러리 의존성을 포함하고 있기 때문에 바로 사용할 수 있습니다.
📝 Repository
@RequiredArgsConstructor
public class PostContentFileRepositoryImpl implements PostContentFileCustom {
private final JdbcTemplate jdbcTemplate;
@Override
public void batchInsertPostContentFiles(List<PostContentFile> postContentFiles) {
String sql = "INSERT INTO post_content_file "
+ "(post_id, file_id, deleted_at) VALUES (?, ?, ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
PostContentFile postContentFile = postContentFiles.get(i);
ps.setLong(1,postContentFile.getPostId());
ps.setLong(2,postContentFile.getFileId());
ps.setObject(3, postContentFile.getDeletedAt());
}
@Override
public int getBatchSize() {
return postContentFiles.size();
}
});
}
}위의 JdbcTemplate의 batchUpdate() 메서드를 사용하여 batch Insert를 적용해보았습니다.

실행 쿼리 로그를 확인해보니 개별 쿼리가 아닌 배치 전체가 한 번에 표시되는 것을 확인할 수 있었습니다. 즉, 여러 개의 SQL 문이 하나의 배치로 묶여서 실행됨을 알 수 있습니다.
🙌 성능 테스트
실제 서비스 로직에 두 가지 방법에 대해 적용하고 성능 테스트를 진행해보도록 하겠습니다.
1. 게시글 생성 로직 V1 - JPA saveAll() 사용
public ApiResponse<PostSimpleResponseDto> createPostV1(PostRequestDto dto, Long memberId) {
Member member = memberRepository.findByIdNotDeleted(memberId).orElseThrow(() -> new ApplicationException(ErrorCode.USER_NOT_FOUND));
Post post;
// File Id 여부에 따른 분기 처리
if (dto.getFileId()==null) {
post = new Post(member, dto.getTitle());
postRepository.save(post);
} else {
File file = fileService.findFile(dto.getFileId());
post = new Post(member, dto.getTitle(), file.getPath());
postRepository.save(post);
fileService.saveFileInfo(new FileInfo(TableName.POST, post.getId(), file));
}
PostDetail postDetail = new PostDetail(post, dto.getContent());
postDetailRepository.save(postDetail);
// PostContentFile 저장
if (dto.getContentFileIds()!=null && dto.getContentFileIds().size()!=0) {
List<Long> contentFileIds = dto.getContentFileIds();
List<PostContentFile> postContentFileList = new ArrayList<>();
for (Long id: contentFileIds) {
PostContentFile postContentFile = new PostContentFile(id, post.getId());
postContentFileList.add(postContentFile);
}
postContentFileRepository.saveAll(postContentFileList);
}
// Todo: TagsId 여부에 따른 분기 처리
// 레디스에 해당 post 정보 저장해주기
PostResponseDto postResponseDto = postRepository.getPostDetail(post.getId()).orElseThrow(() -> new ApplicationException(ErrorCode.POST_NOT_FOUND));
cachePost(postResponseDto);
return ApiResponse.successOf(new PostSimpleResponseDto(post.getId()));
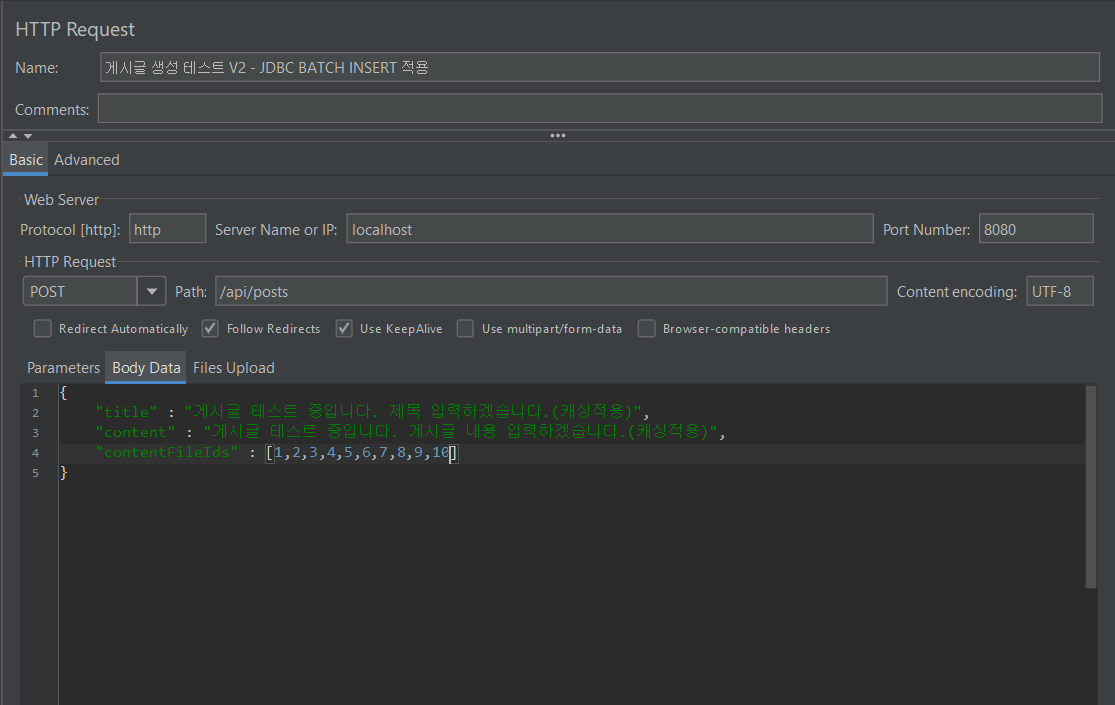
}2. 게시글 생성 로직 V2 - JDBC BATCH INSERT 사용
public ApiResponse<PostSimpleResponseDto> createPostV2(PostRequestDto dto, Long memberId) {
Member member = memberRepository.findByIdNotDeleted(memberId).orElseThrow(() -> new ApplicationException(ErrorCode.USER_NOT_FOUND));
Post post;
// File Id 여부에 따른 분기 처리
if (dto.getFileId()==null) {
post = new Post(member, dto.getTitle());
postRepository.save(post);
} else {
File file = fileService.findFile(dto.getFileId());
post = new Post(member, dto.getTitle(), file.getPath());
postRepository.save(post);
fileService.saveFileInfo(new FileInfo(TableName.POST, post.getId(), file));
}
PostDetail postDetail = new PostDetail(post, dto.getContent());
postDetailRepository.save(postDetail);
// PostContentFile 저장
if (dto.getContentFileIds()!=null && dto.getContentFileIds().size()!=0) {
List<Long> contentFileIds = dto.getContentFileIds();
List<PostContentFile> postContentFileList = new ArrayList<>();
for (Long id: contentFileIds) {
PostContentFile postContentFile = new PostContentFile(id, post.getId());
postContentFileList.add(postContentFile);
}
postContentFileRepository.batchInsertPostContentFiles(postContentFileList);
}
// Todo: TagsId 여부에 따른 분기 처리
// 레디스에 해당 post 정보 저장해주기
PostResponseDto postResponseDto = postRepository.getPostDetail(post.getId()).orElseThrow(() -> new ApplicationException(ErrorCode.POST_NOT_FOUND));
cachePost(postResponseDto);
return ApiResponse.successOf(new PostSimpleResponseDto(post.getId()));
}먼저 INSERT 해야하는 데이터의 갯수를 10개, 100개로 나누어 테스트해보겠습니다. 테스트는 동시 접속 사용자 30명, 10번 반복으로 동일한 환경에서 테스팅하였습니다.
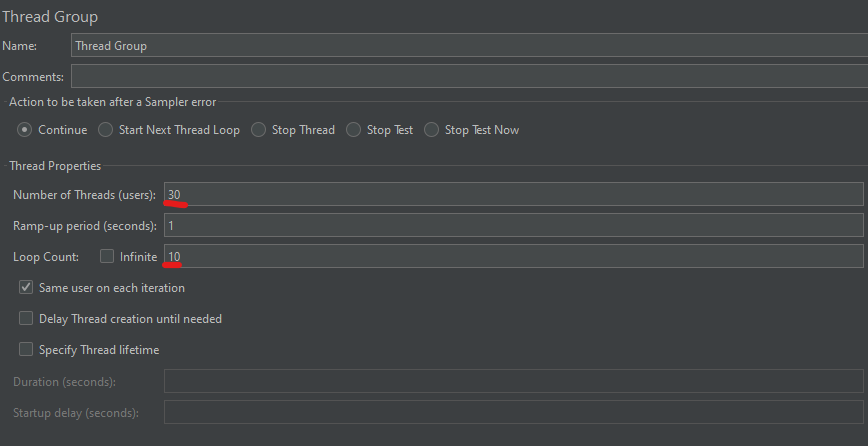
1. 데이터 10개 테스트
1-1. JPA saveall() 메서드 사용
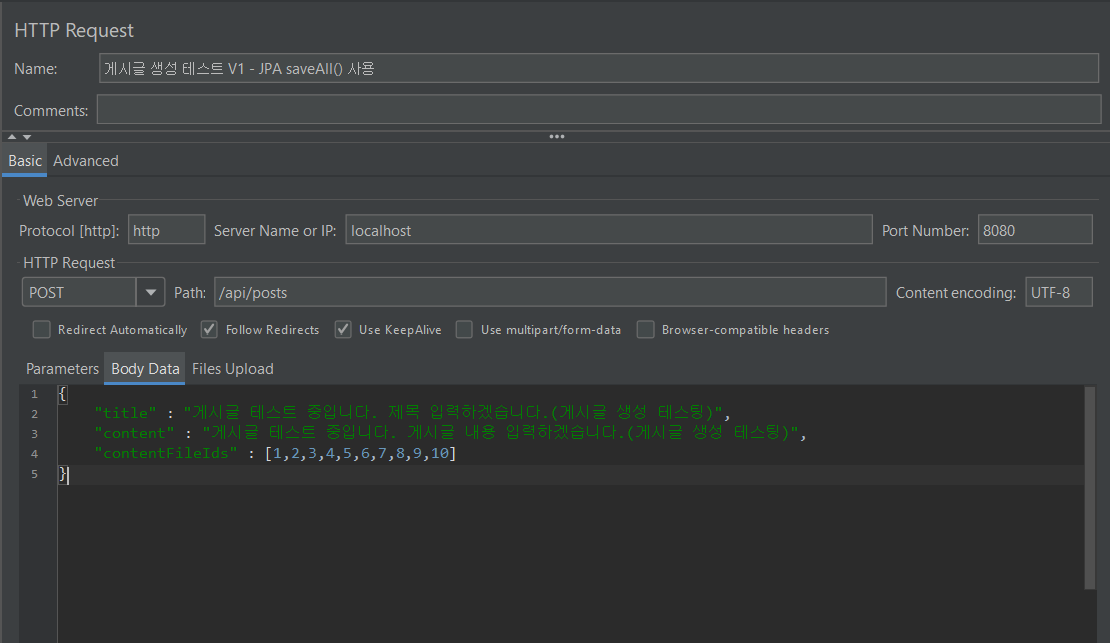
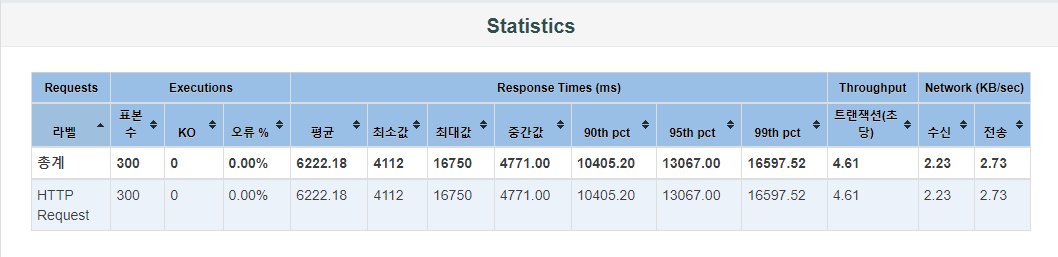
테스팅 결과 초당 4.61개의 트랜잭션을 처리하고 있습니다. 평균 응답 시간은 6222.18 ms 이며 최소 응답 시간은 4112 ms, 최대 응답 시간은 16570 ms으로 편차가 꽤 큰 편입니다.
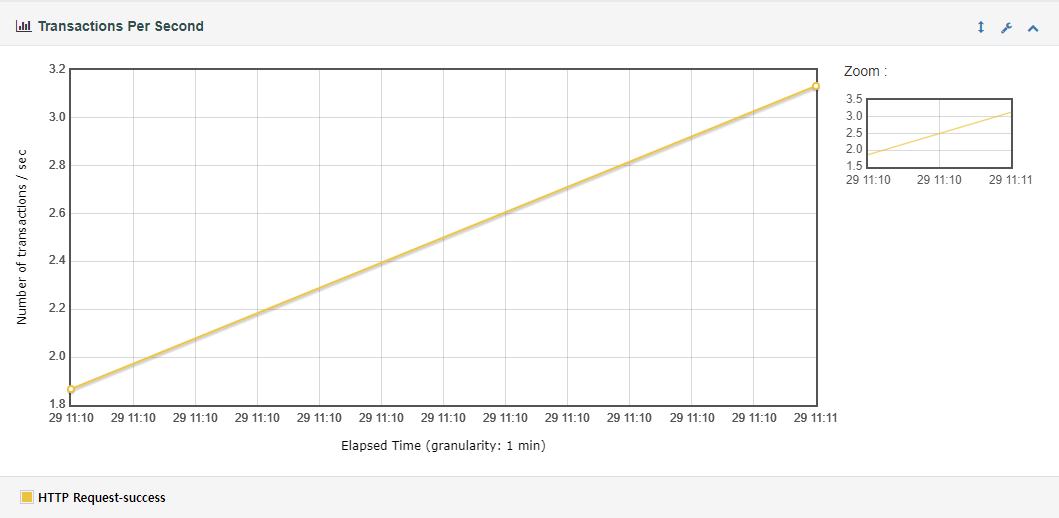
트랜잭션 그래프는 시간이 지남에 따라 초당 트랜잭션 수가 증가하는 경향을 보여줍니다. 시작 시점에서는 약 1.8 TPS에서 시작하여 마지막 시점에서는 약 3.2 TPS에 도달합니다. 아마 시스템의 부하가 증가하거나 요청 수가 증가하면서 트랜잭션 처리율이 증가한 것으로 예상됩니다.
1-2. JDBC Batch Insert 사용
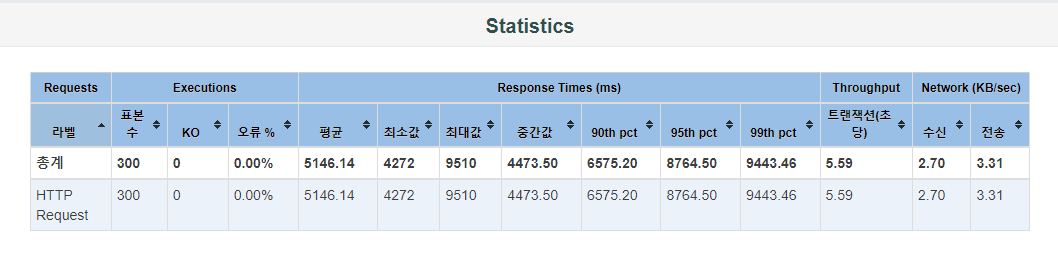
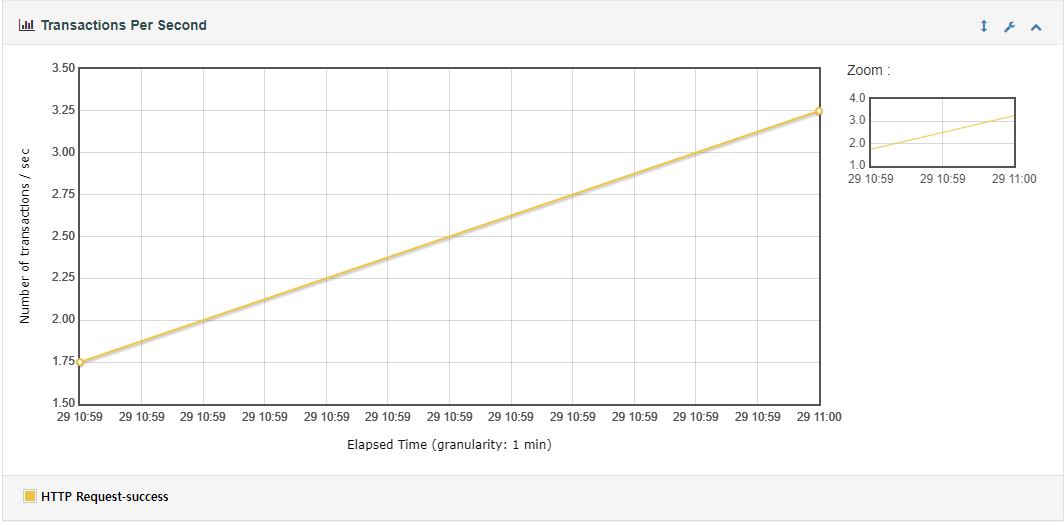
테스팅 결과 초당 5.59개의 트랜잭션을 처리하고 있습니다. 평균 응답 시간은 6222.18 ms 이며 최소 응답 시간은 4272 ms, 최대 응답 시간은 9510 ms으로 앞서 테스트한 JPA saveAll() 사용보다는 편차가 적은 편입니다.
트랜잭션 그래프는 시간이 지남에 따라 초당 트랜잭션 수가 증가하는 경향을 보여줍니다. 시작 시점에서는 약 1.75 TPS에서 시작하여 마지막 시점에서는 약 3.25 TPS에 도달합니다. 위의 테스트와 마찬가지로 시스템의 부하가 증가하거나 요청 수가 증가하면서 트랜잭션 처리율이 증가한 것으로 예상됩니다.
2. 데이터 100개 테스트
2-1. JPA saveall() 메서드 사용
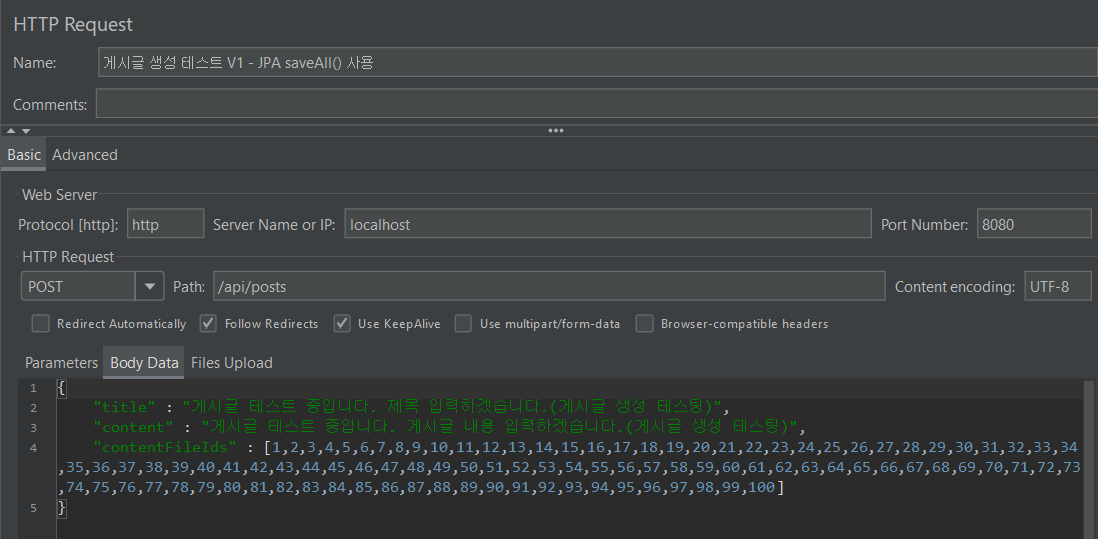
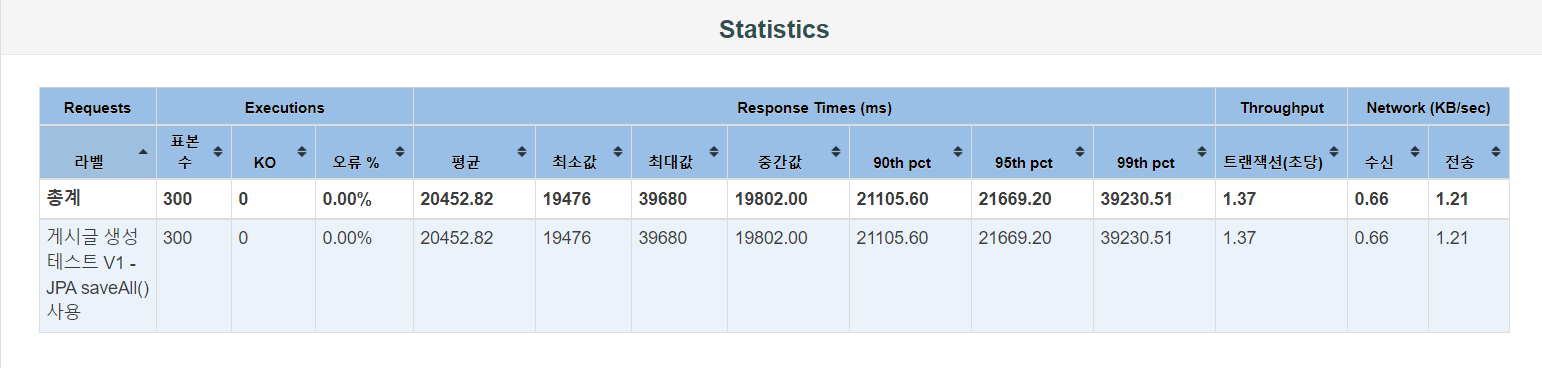
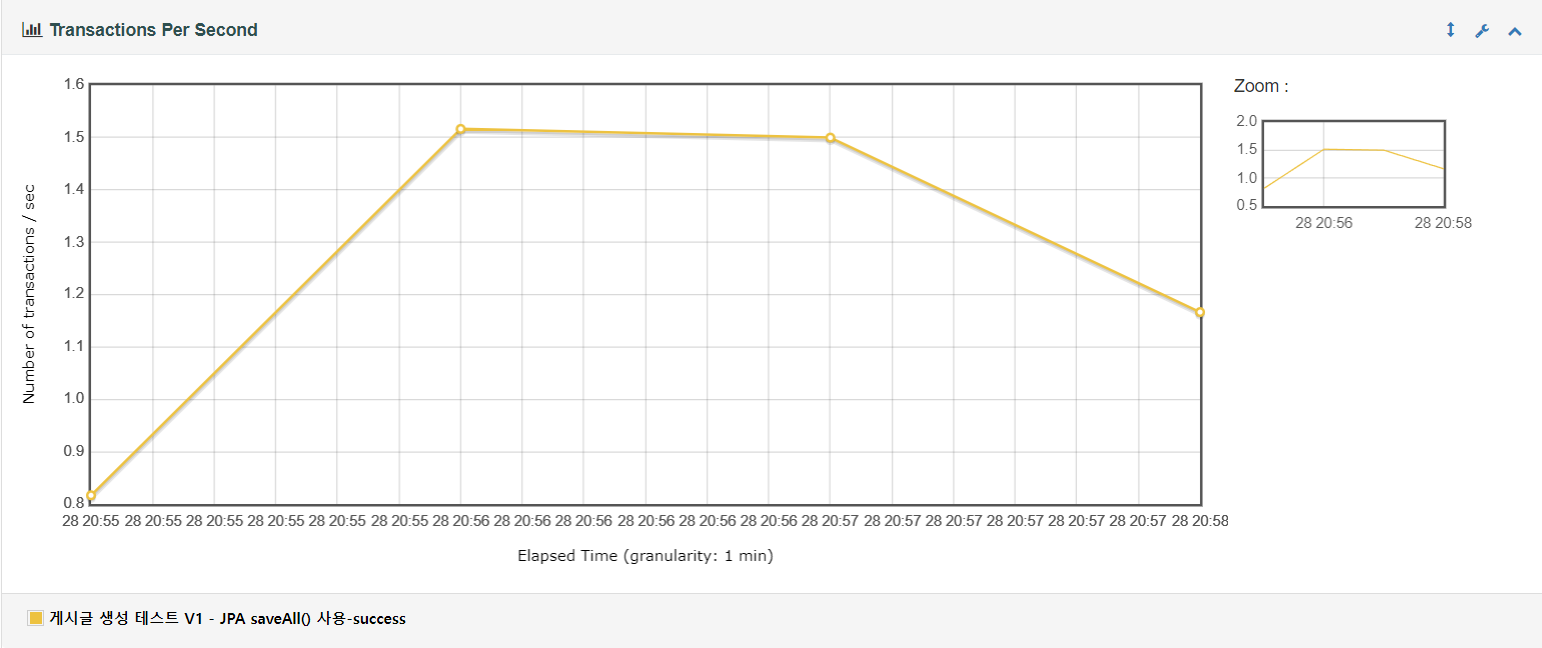
테스팅 결과 초당 1.37개의 트랜잭션을 처리하고 있습니다. 평균 응답 시간은 20452.82 ms 이며 최소 응답 시간은 19476 ms, 최대 응답 시간은 39680 ms으로 편차가 꽤 큰 편입니다.
트랜잭션 그래프를 살펴보면 트랜잭션 처리율이 처음에는 빠르게 증가하고 1분간 1.5 TPS로 일정하게 유지되다 이후 TPS가 일정하게 감소하는 것을 볼 수 있습니다. 시스템이 초기 부하를 잘 처리하고 안정적으로 최대 처리량을 유지하다 이후 부하가 줄거나 다른 요인들로 인해 트랜잭션 처리 속도가 감소하는 것을 볼 수 있습니다.
2-2. JDBC Batch Insert 사용
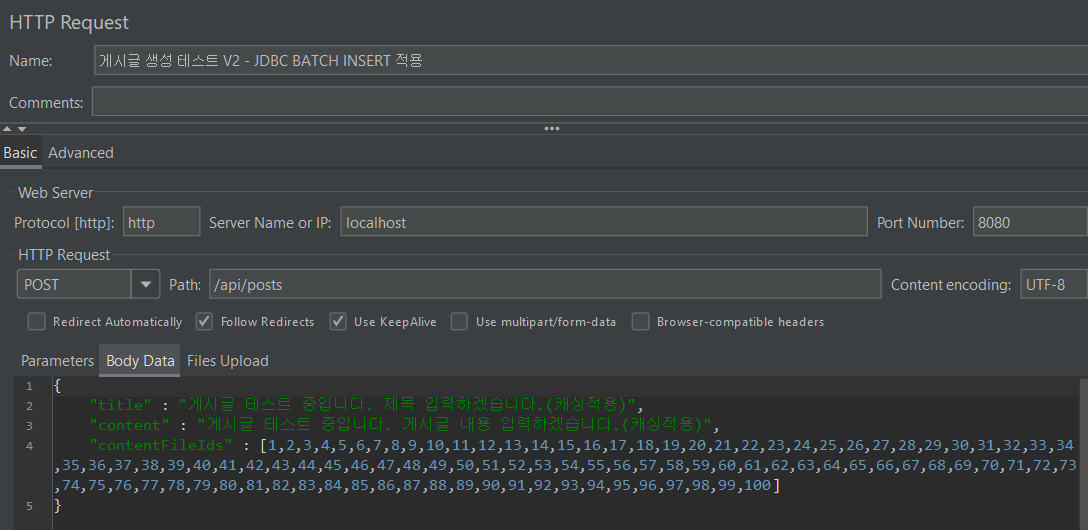
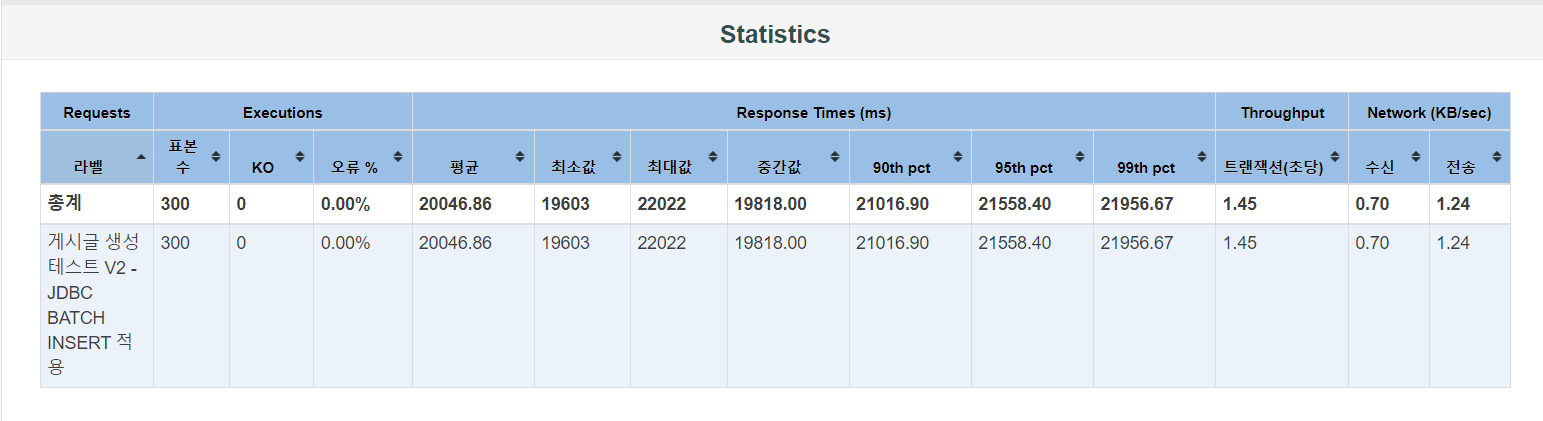
테스팅 결과 초당 1.45개의 트랜잭션을 처리하고 있습니다. 평균 응답 시간은 20046.86 ms 이며 최소 응답 시간은 19603 ms, 최대 응답 시간은 22022 ms으로 앞서 테스트한 JPA saveAll() 사용보다는 편차가 적은 편입니다.
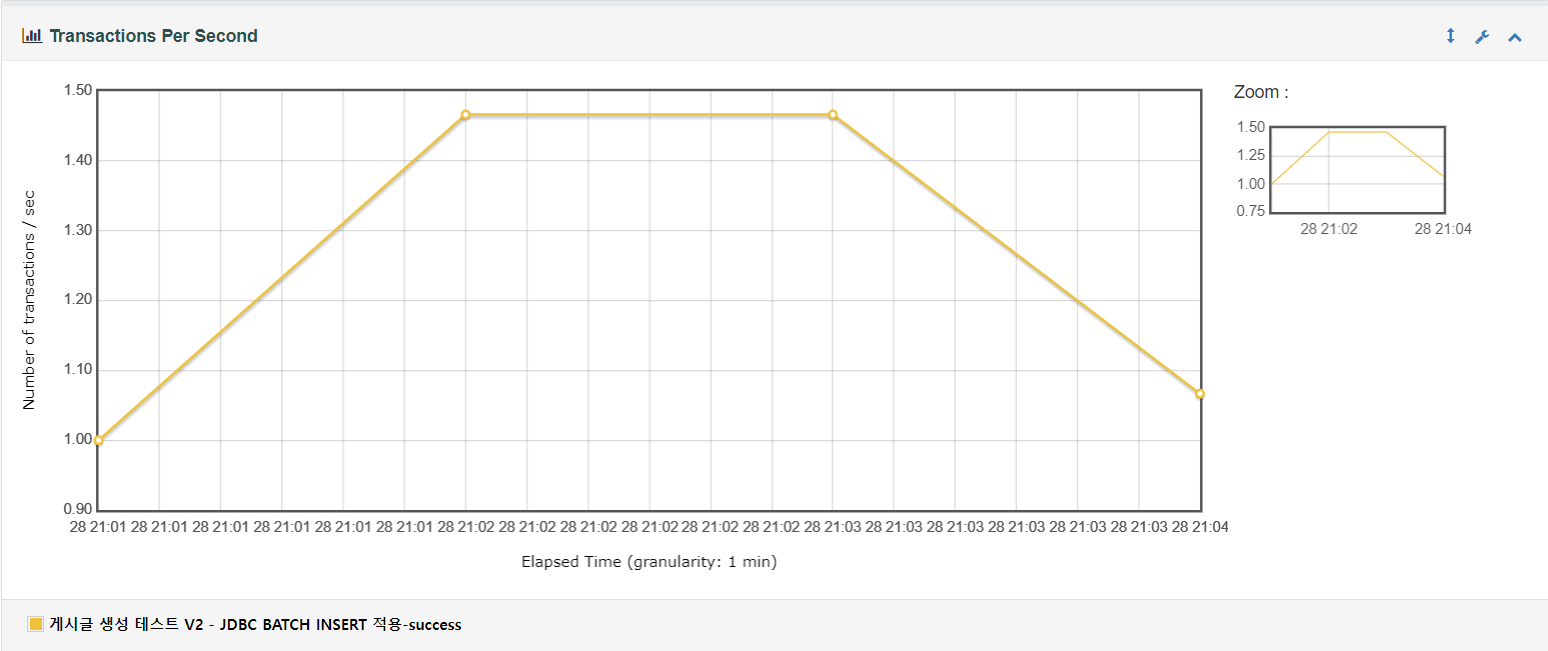
트랜잭션 그래프를 살펴보면 트랜잭션 처리율이 처음에는 빠르게 증가하고 1분간 1.46 TPS로 일정하게 유지되다 이후 TPS가 일정하게 감소하는 것을 볼 수 있습니다. JPA saveAll() 사용한 테스트와 유사한 것을 확인할 수 있습니다.
📝 테스트 결과
데이터 10개 INSERT에서는 JPA saveAll() 적용과 JDBC BATCH INSERT를 적용에 대한 테스트 결과가 각각 4.61 TPS, 5.59 TPS이므로 JDBC BATCH INSERT를 적용했을 때 성능이 약 21.26% 개선될 것으로 보입니다.
데이터 100개 INSERT에서는 JPA saveAll() 적용과 JDBC BATCH INSERT를 적용에 대한 테스트 결과가 각각 1.37 TPS, 1.45 TPS이므로 JDBC BATCH INSERT를 적용했을 때 성능이 약 5.84% 개선될 것으로 보입니다.
데이터의 갯수에 따라 성능 개선률이 다른 원인은 Batch Size에 있다고 판단하였습니다. 작은 Batch Size에서는 JDBC BATCH INSERT가 네트워크와 데이터베이스의 오버헤드를 줄여줌으로써 더 큰 성능 향상을 보일 수 있습니다. 각 Batch가 상대적으로 작은 작업을 처리하기 때문에, 네트워크 지연이나 트랜잭션 처리 오버헤드가 적을 것입니다.
반면 Batch Size가 커질수록, 각 Batch 처리에 필요한 메모리와 트랜잭션 관리 오버헤드가 증가할 수 있습니다. 대규모 Batch는 데이터베이스에 부하를 줄 수 있으며, 최적화되지 않은 경우 성능 이점이 감소할 수 있습니다.
진행 중인 프로젝트에서 게시글 본문에 들어갈 파일 이미지 개수는 평균적으로 20개 미만으로 예상됩니다. 따라서, 해당 수에 맞는 Batch Size를 설정함으로써 JDBC BATCH INSERT를 적용할 경우 유의미한 성능 개선을 기대할 수 있습니다.

GOAT