
Deep Recurrent Q-Learning for Partially Observable MDPs
[Before starting]
기존의 DQN은 연속적인 state들을 알아야 하는 문제들에 대해서 특정 개수의 연속적인 state들을 쌓아 neural network에 넣는 것으로 해결을 합니다.
해당 논문은 이러한 문제를 recurrent neural network로 보다 개선될 수 있다고 얘기하고 있습니다.
[Abstraction]
-
기존의 DQN 논문에서 제시되었던 단점은 replay memory에서 sampling시 importance sampling이 아닌 random sampling이어서 sampling 자체 뿐만 아니라 behavior network에도 이러한 점이 반영이 안된다는 것이 었습니다. - 요건 논문의 내용이 아닌 그냥 remind 입니다.
-
이것 외로 해당 논문에서는 DQN의 단점으로
1) limited replay memory
2) rely on being able to perceive the complete game screen ar each decision point
를 얘기 하고 있습니다.
즉 1)은 말 그대로 replay memory에 크기가 정해져있어 해당 크기 이전의 과거 experience를 잃어버린다는 문제이고 2)는 observation에 해당하는 game screen이 도중에 잠깐 안 들어온다던지 하는 문제에 취약하다는 것을 말합니다. game screen은 항상 온전하게 들어온다는 것을 전제로 학습이 이루어진다는 점입니다. -
해당 논문은 이러한 단점들을 DQN의 convolutional layer 후에 처음 나오는 fully connected layer를 LSTM으로 바꾸어 이를 Deep Recurrent Q-Network라 말하고 이 DRQN으로 위의 문제점들을 개선 할 수 있다고 말하고 있습니다.
-
이러한 DRQN은 DQN 처럼 4개의 frame을 받아 state를 생성할 필요 없이 하나의 frame을 받는 것만으로도 information들을 합칠 수 있으며, 일반적인 atari game 환경에서만이 아니라 flickering 즉 일부 frame들이 들어오지 않는 상황에서도 DQN의 성능과 유사한 성능을 낼 수 있다고 얘기합니다.
-
위와 같이 frame이 온전히 들어오지 못하는 상황을 partial observation이라고 하고 온전히 frame이 들어오는 상황을 complete observation이라고 합니다.
-
DRQN은 partial observation 상황에서 학습 후 점차 complete observation으로 바꾸면서 평가를 했을 시 observation이 complete에 가까워짐에 따라 성능이 좋아지며, full observation에서 학습 후 partial observation에서 평가할 경우 DQN에 비해 보다 성능이 덜 나빠진다고 합니다.
-
즉 main contribution은
1) DQN의 4개 frame을 받아오는 부분을 recurrent network로 대체할 수 있으며
2) observation quality에 DQN보다 덜 영향을 받는 점이라고 얘기합니다.
[Introduction]
-
기존의 DQN은 특정 개수(보통 4)의 screen을 쌓아서 input으로 학습을 진행합니다.
그러나 해당 개수보다 더 오래된 screen을 기억해야만 game을 학습할 수 있는 경우에는 DQN으로는 학습이 불가합니다.
이러한 경우 해당 state만으로는 decision을 할 수가 없으므로 해당 문제는 기존의 MDP에서 POMDP(Partially-Observable Markov Decision Process)가 됩니다. -
예를 들어 아래의 그림에서 pong이라는 게임의 경우 상대가 튕겨내는 공을 다시 튕겨보내야 합니다.
그러려면 공의 속도를 알아야하는데 하나의 game screen만을 받아오는 경우 공의 속도를 알기가 불가능 합니다.
이러한 온전한 state를 알 수 없는 경우를 POMDP 문제라고 합니다.
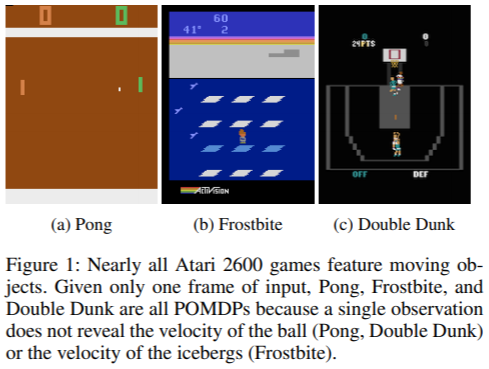
-
해당 논문은 이러한 POMDP에서 기존 DQN의 network에 recurrent neural network인 LSTM을 추가하여 partially observable한 상황에 잘 학습이 가능할 뿐 아니라 observation의 quality가 감소하여도 기존의 DQN에 비해 덜 성능이 나빠진다고 합니다. (위에서 말했던 내용입니다.)
-
Deep Q-Learning
-
DQN에 대한 내용은 다음을 참고하시면 됩니다.
https://velog.io/@kth811/1.-Playing-Atari-with-Deep-Reinforcement-Learning -
DQN은 model-free, off-policy 학습이며 target network를 behavior network와 구분하여 10000 iteration마다 update를 하였습니다.
-
Partially Observability
-
POMDP란 underlying system state에 대해서 agent가 일부분(논문에서는 glimpse 라는 표현을 사용하였습니다)만을 인지하는 decision process를 말합니다.
일반적인 상황에서는 Markov Property 자체가 굉장히 특수한 경우로 MDP의 경우 로 표현이 되지만 POMDP는 여기에 와 라는 observation 집합 와 underlying state로 부터의 observation의 분포 를 포함하여 라는 튜플로 표현하게 됩니다. -
이러한 POMDP에서 DQN의 경우 와 사이의 간극으로인해 학습이 잘 이루어지지 않지만 DRQN의 경우 이전의 state 정보를 recurrent neural network로 기억하는 특징으로 인해 보다 두 사이의 간극을 좁혀 학습이 보다 잘 이루어진다고 합니다.
[DRQN Architecture]
- DRQN의 network architecture 구조는 우선 아래의 그림과 같습니다.
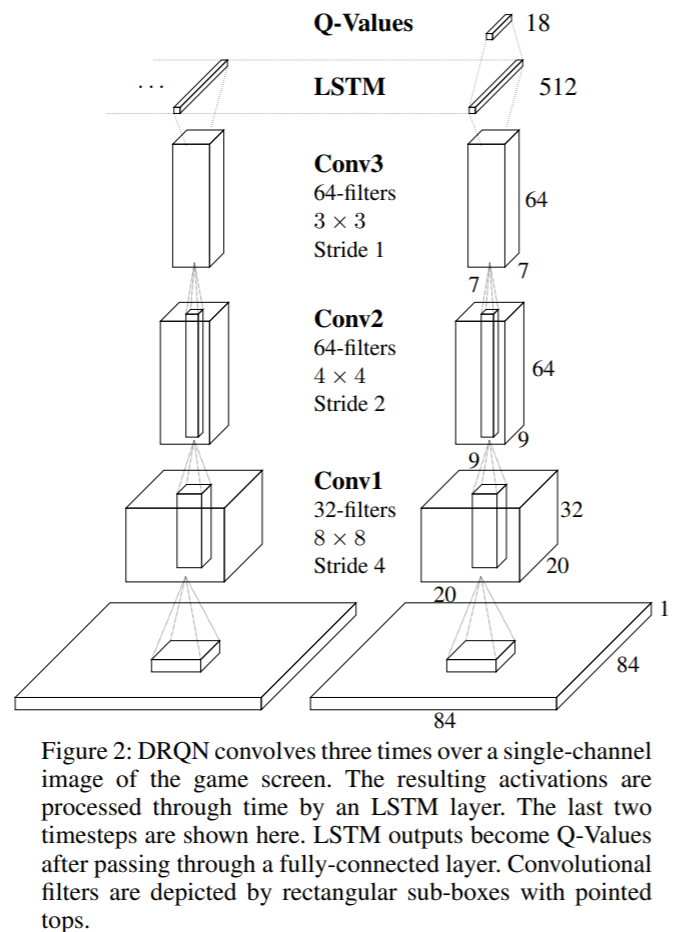
-
위에서 보이는 것과 같이 기존의 fully connected layer 대신 LSTM을 사용하였고 마지막에 action space와 맞는 크기의 output을 뽑아내기 위한 fully connected layer를 통과하는 것으로 구성되어 있습니다.
-
recurrent neural network를 통한 성능 개선을 살펴보기 위하여 기존 DQN에서 network architecture 변화를 최소화 하려고 하였으며 몇 가지 시도들을 하였는데 이러한 architecture에 대한 시도는 appendix A에서 다루고 있습니다.
[Stable Recurrent Updates]
-
LSTM의 initial hidden state를 0으로 줄 것인지 아니면 이전의 값들을 그대로 가져올지에 대한 문제로 network weigth update 방법을 다음의 두 가지를 제시하고 있습니다.
-
Bootstrapped Sequential Updates
replay memory에서 episode를 random하게 선택을 하고 해당 episode의 시작 부분에서 부터 쭉 학습을 진행 합니다.
이때 LSTM의 hidden state 값들은 같은 episode에서 학습이 되는 한 이전의 값들을 쭉 받아서 합니다. -
Bootstrapped Random Updates
replay memory에서 episode를 random하게 선택 하고 해당 episode 내에서도 random하게 시작 지점을 선택하여 target network가 update 되는 시점까지만 학습을 진행합니다. - (이를 unroll iterations timesteps라고 합니다.)
이때 시작 지점을 random하게 선택하여 학습을 시작하는 순간에는 initial hidden state를 0으로 설정해 줍니다. -
위의 두 가지 방법은 각각 문제점이 있는데 첫번째의 sequential 방법은 DQN의 sampling policy에 위배되는 문제가 있고(이렇게 하면 혹여나 rnn의 차이가 아닌 sampling의 방법 차이로 성능이 올라간 것일 수도 있기 때문입니다.), 두번째의 random 방법은 initial hidden state가 분명 이전 state에서 받아 올 수 있는 상황임에도 시작을 episode의 시작 부분이 아닌 중간에서 시작해 버리므로 0으로 초기화 해버려 보다 긴 time step에 대한 학습이 어려워지는 문제가 있습니다.
-
그런데 실험을 해보니 두 방법 모두 비슷한 성능을 내는 policy로 수렴을 하여 본 논문에서는 두번째 방법인 Bootstrapped Random Update 방법으로 통일하여 학습하였다고 합니다.
[Atari Games: MDP or POMDP?]
- atari 게임의 대부분은 해당 screen만을 보게되면 POMDP에 속합니다.
이때 DQN은 이러한 문제를 4개의 previous screen을 쌓아서 input으로 사용하여 해결하는데 이렇게 4개의 previous screen을 input으로 사용하는 구조를 건드리지 않고도 partial observability를 부여하는 방안을 다음의 내용에서 제시하고 있습니다.
[Flickering Atari Games]
-
partial observability를 부여하기 위해 논문에서는 pong이라는 atari game에 0.5의 확률로 fully revealed screen과 fully obscured screen을 observation으로 부여합니다.
-
이때 아래는 기존의 DQN이 pong이라는 게임에서 velocity와 locomodation을 CNN에서 어떻게 반영하는 지를 보여주고 있습니다.

- 여기서 DRQN의 경우 CNN에서 velocity 및 locomodation을 파악하기에는 어려움이 있지만 LSTM에서 이를 잡아내는 것을 위의 그림 (d)에서 알 수 있습니다.
여기서 DRQN의 경우 LSTM의 한번 backpropation하는 데에 input으로 매 10 frame이 들어가게 되는데 그러면 이는 1 frame의 DRQN은 곧 10 frame의 DQN 학습과 같은 history를 본다고 볼 수 있습니다.
이를 통해 위의 사진들과 같이 DQN의 CNN을 활용하기 위해서 history length를 10으로 해도 되지만 이를 LSTM과 같은 recurrent neural network로 대체하면 1개의 frame을 매번 받아도 위와 같이 velocity 같은 특성의 state를 반영할 수 있다는 장점이 있습니다.
[Evaluation on Standard Atari Games]
- 아래의 표는 atari의 9개 게임에 대한 DQN과 DRQN 학습의 결과를 나타낸 표 입니다.
여기서 선택한 9개의 게임들은 4 frame을 볼 수 있다면 MDP 문제로 볼 수 있는 게임들입니다.
따라서 DQN이나 DRQN이나 성능에 큰 차이가 있지는 않을 것으로 기대 됩니다.
아래의 표를 보면 DQN 논문에서의 결과와 해당 논문에서 직접 구현한 결과가 조금은 다르지만 드래도 얼추 비슷한 것을 볼 수 있습니다.
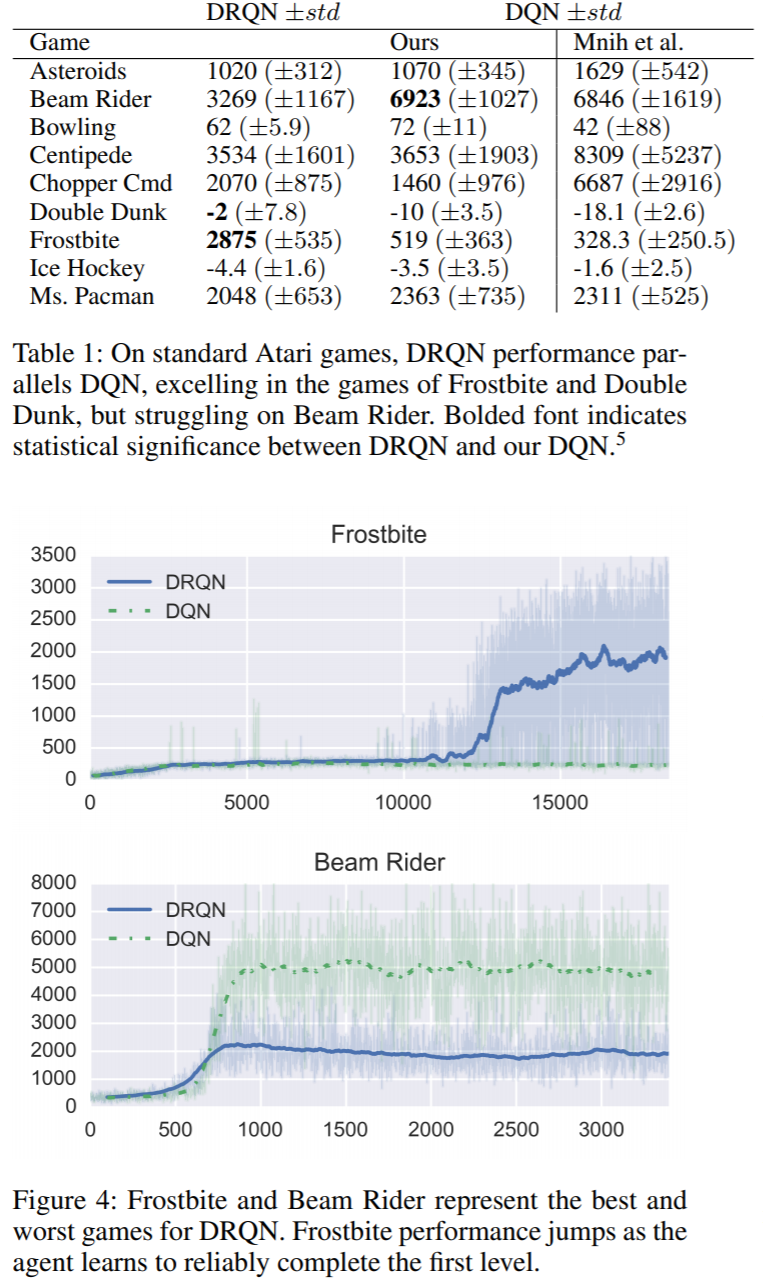
- Frostbite의 경우 DRQN이 더 좋은 policy를 찾았고 반면에 Beam Rider에서는 성능이 보다 안 좋은 것이 보입니다.
[MDP to POMDP Generalization]
- 이제 pong 게임에서 partial observability를 부여하여 POMDP를 만든 결과 아래의 그래프와 같이 나옵니다.
즉 위의 표에서는 DRQN이나 DQN이나 성능이 비슷했지만 POMDP가 되면서 성능에 차이가 나는 것을 볼 수 있습니다.
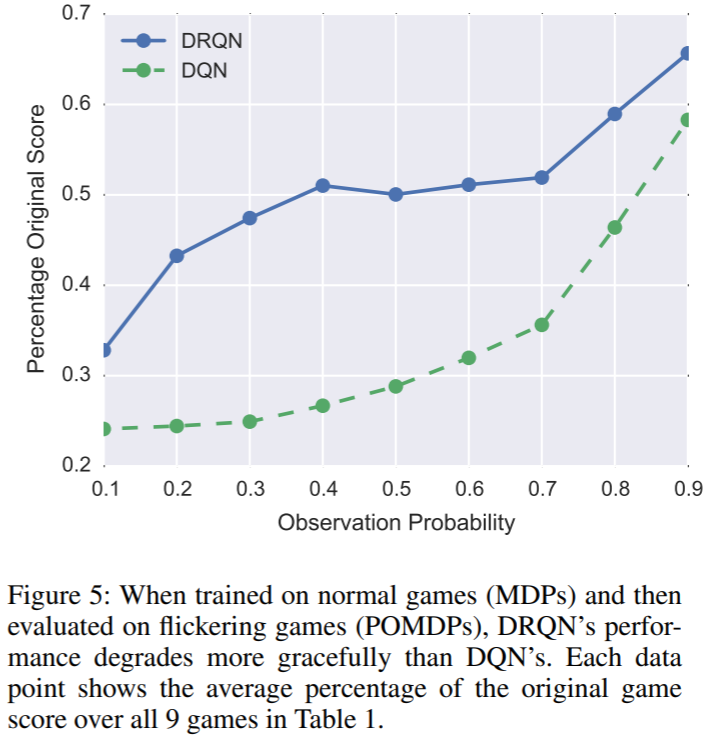
[Related Work]
- 이전에는 POMDP를 policy gradient로 해결했다는 내용과 LSTM에 대한 내용을 조금 담고 있습니다.
크게 중요하다 생각치 않아서 이 정도 언급으로 넘어가겠습니다.
[Discussion and Conclusion]
-
앞의 내용을 쭉 언급하면서 결국에는 recurrent를 DQN에 부여하여 보다 observation에 robust해 졌음을 얘기하고 있습니다.
-
이때 pong에서 obscure를 0.5가 아닌 10 frame에 한 번 부여한 결과 DQN과 DRQN 보다 full observation과 큰 차이 없이 성능에 큰 변화가 없었다고 합니다.
즉 이 경우 4 frame을 쌓는 DQN에 obscure screen이 반영되지 않는 경우가 많고 즉 보다 MDP에 유사하여 DRQN과도 큰 차이가 없었다고 얘기합니다.
[Appendix A: Alternative Architecture]

-
논문에서는 LSTM의 위치에 따라서 성능을 비교해 보았는데 결국 fully connected layer의 첫번째 layer를 LSTM으로 바꾼 결과가 위에서 보이는 것처럼 가장 좋았다고 합니다.
-
여기서 IP1이 fully connected layer중 첫번째 layer를 말하는 것 같습니다.
[Appendix B: Computational Efficiency]
-
gtx titan black 과 caffe로 학습을 했다고 합니다.
-
학습하는데 필요한 연산량은 frame을 stack하는 갯수와 unrolled iteration 횟수에 비교적 선형적으로 증가한다고 합니다.
-
예시로 unrolled for 30 iterations with 10 stacked frames의 경우 10 million iteration 도달에 56일이 걸린다고 합니다.
[Appendix C: Experimental Details]
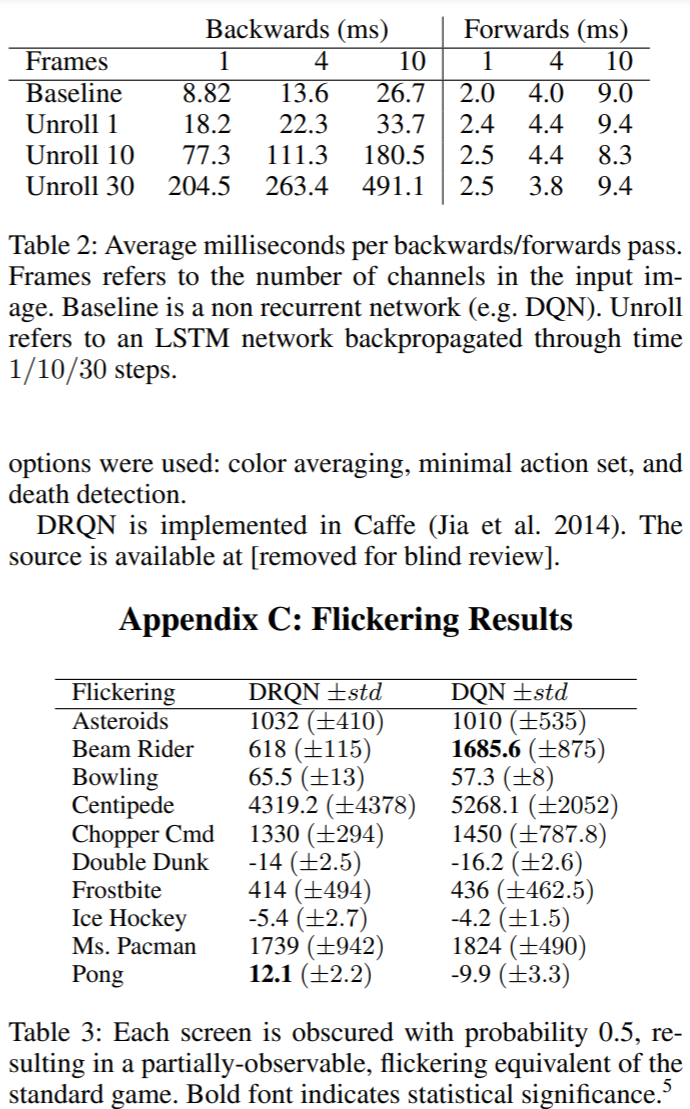
-
Experiment 결과는 위와 같습니다.
-
50000 iteration 마다 10 episode의 evaluation을 하였고 총 10 million iteration을 학습하였으며 memory size는 400000으로 하였고 ADADELTA optimizer를 사용하여 learning rate 0.1, momentum 0.95로 설정하였다고 합니다.
[Reference]
[Paper Link] - https://arxiv.org/abs/1507.06527 / 2015
