
CSAPP에서 가장 중요하다고 자주 언급되는 9장이다.
이번장은 메모리 관리, 동적 메모리 할당에 관련된 내용이 나온다.
우리가 가상메모리를 공부해야 하는 이유는 여러가지가 있다.
-
가상메모리는 거의 모든 컴퓨터 에서 사용하며, 하드웨어 예외, 어셈블러,링커,로더,공유 객체 ,파일,프로세스를 설계하는데 중요한 역할을 수행한다. 그러니까 모르면 시스템 이해에 큰 결점이 생긴다.
-
메모리를 효율적으로 관리할 수 있게 해준다.
-
메모리 동적 할당을 할 때 치명적인 오류를 발생 시킬 수 있다.
이러한 이유 때문에 우리는 가상 메모리에 대해 정확하게 알아야 한다.
9-1 물리 및 가상 주소 방식
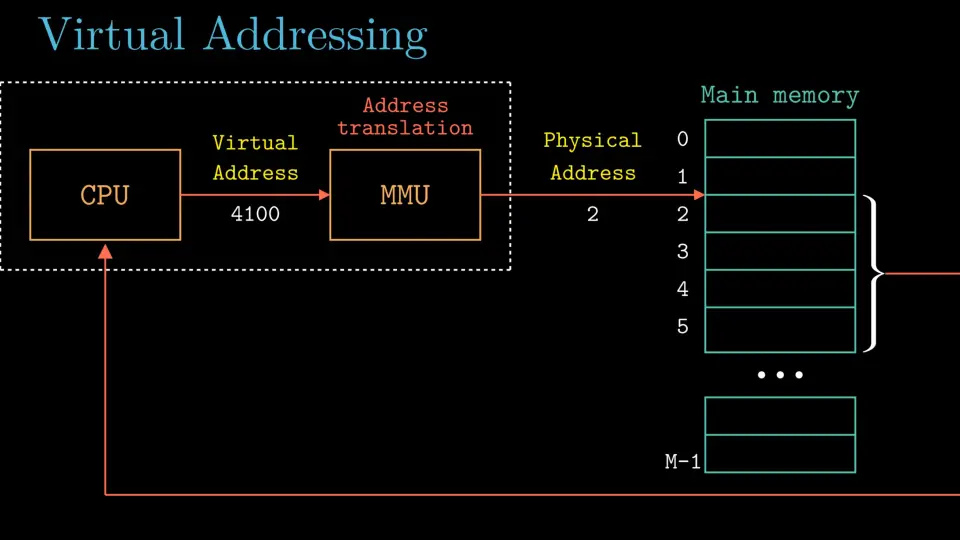
물리 주소는 말 그대로 물리적으로 데이터가 있는 위치를 지목한다.
하지만 가상 주소 방식은 CPU가 가상 주소(VA)로 데이터를 지목하는데, 이때 MMU가 물리 주소로 번역을 해 실제 주소 값을가리키게 된다.
위 그림은 가상 주소 방식을 나타낸 그림이고, 물리 주소 방식은 MMU가 없어진 대신 CPU가 물리 주소를 그대로 가리킨다고 보면 된다.
9-2 주소 공간
주소공간의 정수가 연속적이라면 이 공간을 선형 주소공간이라고 하는데,
이 책에서는 모든 경우를 선형주소공간으로 가정한다.
캐싱 도구로서의 VM
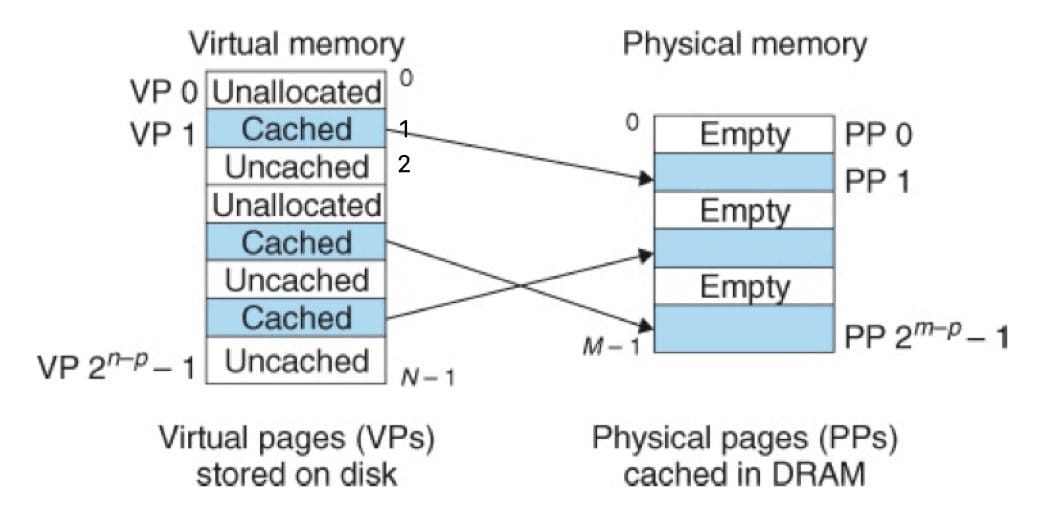
VM은 항상 3가지로 나눠진다.
-
Unallocated : VM 시스템에 의해 아직까지 할당되지 않은 페이지들.
-
Cached : VM시스템에 의해 할당되고, 물리 메모리에 캐시되어 할당된 페이지들.
-
Uncached : VM시스템에 의해 할당되고, 물리 메모리에 캐시되어 할당되지 않은 페이지들.
DRAM 캐시의 구성
이 책에서 L1,L2,L3는 SRAM 캐시라는 용어를 쓰고, 가상페이지를 메인 메모리로 캐싱하는 VM 시스템 캐시는 DRAM 캐시라 지칭한다.
DRAM 캐시는 SRAM캐시보다 10배정도 느리고, 디스크는 DRAM보다 약 100000배 더 느리다.
DRAM 캐시미스는 디스크에서 처리 되기 때문에, 속도가 끔찍하게 느리고 캐시 미스 발생시 치명적이다.
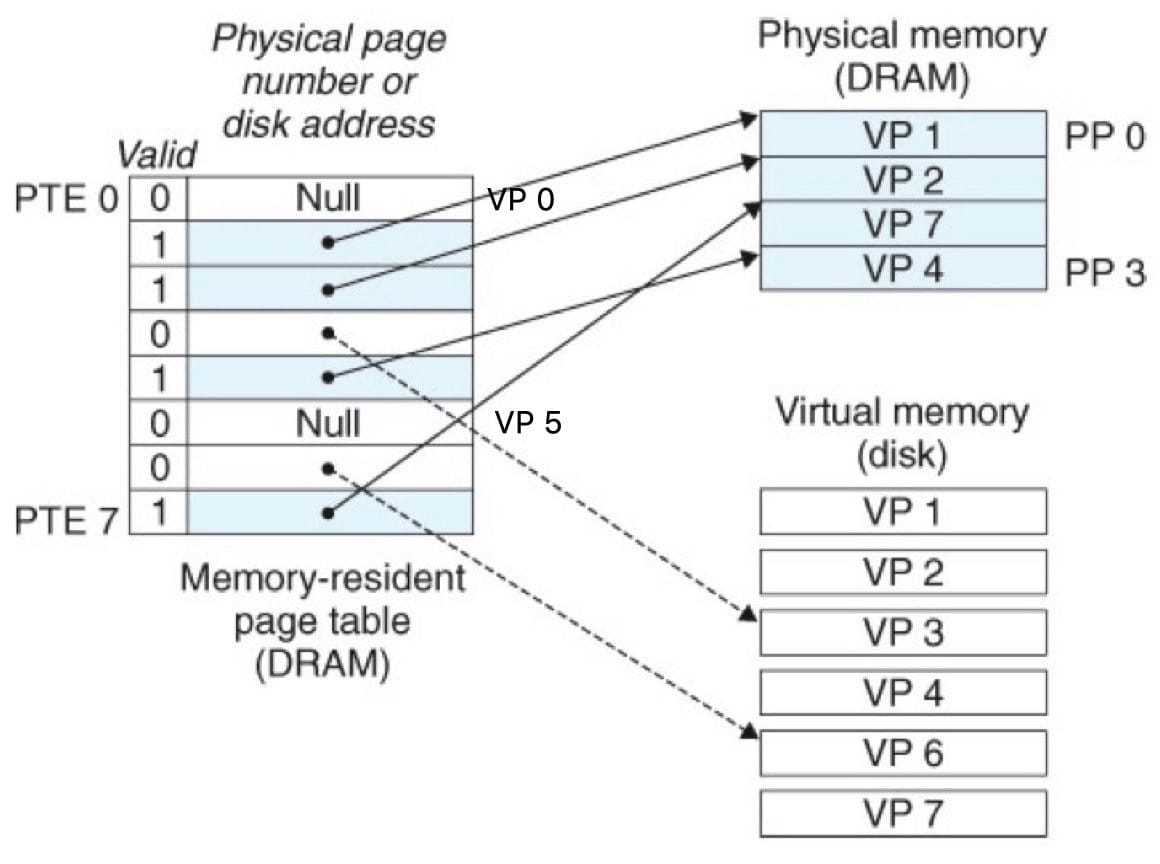
페이지 테이블
2차 기억 장치(RAM)는 메모리를 일정한 크기로 잘라 페이지라는 덩어리들을 만들어 데이터를 관리한다. 그렇기 때문에 VM 시스템은 이 페이지들 중 어떤 페이지를 캐싱했는지 알아야 한다.
미스가 발생한 경우 물리페이지 중에서 희생자 페이지를 선택해서 교체하는 작업도 해야된다.
위 그림은 페이지 테이블의 기본 구조를 보여준다.
페이지 테이블은 PTE(페이지 테이블 엔트리, 페이지 테이블 시작지점)의 배열이다.
이후 설명은 적중, 오류를 설명한다.
적중은 말 그대로 찾는 메모리가 DRAM에 있다는 뜻이고,
오류는 말 그대로 찾는 메모리가 DRAM에 없다는 뜻이다.
페이지 오류가 발생하면 DRAM에서 희생자 페이지를 찾고, 이것을 우리가 찾는 데이터로 교체한다.
비효율?
VM은 할당과 교체, 그리고 MMU를 통한 번역까지 합쳐져서 엄청나게 비효율적인 것 처럼 보이지만,
사실 정말 좋은 지역성을 가지고 있기 때문에 프로그램이 정말 잘 작동하게 된다.
물론 모든 상황에서 좋다는 것은 아니고, 일명 '쓰래싱'이라는 상황이 나올수도 있다.
9-4 메모리 관리를 위한 도구로서의 VM
VM은 메모리 관리/보호를 위한 도구로서 성능이 아주 뛰어나다.
-
링킹의 단순화 : 물리적 주소는 메모리의 이곳 저곳에 퍼져있기 때문에 링킹이 힘들다. 하지만 VM은 이러한 주소들에 통일성을 주기 때문에 링커의 구현과 설계를 단순화 시켜준다.
-
로딩의 단순화 : 가상메모리는 실행/공유목적파일들을 메모리에 로드 하기 쉽게 해준다. 가상페이지를 임의의 위치로 매핑하는걸 '메모리 매핑'이라고 하는데, 이러한 매핑으로 인해 로딩이 단순해진다.
-
공유의 단순화 : VM의 독립적인 주소공간은 운영체제와 프로세스 사이의 데이터 공유를 관리하는데 도움을 준다.
-
메모리 할당의 단순화 : 흩어져있는 메모리에 할당하는 것 보다, VM의 연속적인 주소들이 메모리의 할당에 많은 도움을 준다.
9-5 메모리 보호를 위한 도구로서의 VM
일반적으로 컴퓨터의 메모리 데이터 중 절대로 변경되어서는 안되는 데이터들이 있다.
그 예시로는 커널의 코드/데이터 구조 등이 있는데, 이러한 데이터들은 VM을 통해 다른 프로세스로부터 완벽하게 격리시키는 것이 가능해진다.
일정한 규칙으로 데이터를 격리 시킨 후, 어떤 인스트럭션이 이러한 규칙에 위반되는 명령을 보내면, 커널 내의 예외 핸들러로 제어를 이동시킨 후, segmentation fault를 출력한다.
즉 규칙으로 데이터의 접근을 막은 후, 규칙을 어긴 데이터를 예외처리 한다는 것이다.
9-6 주소의 번역
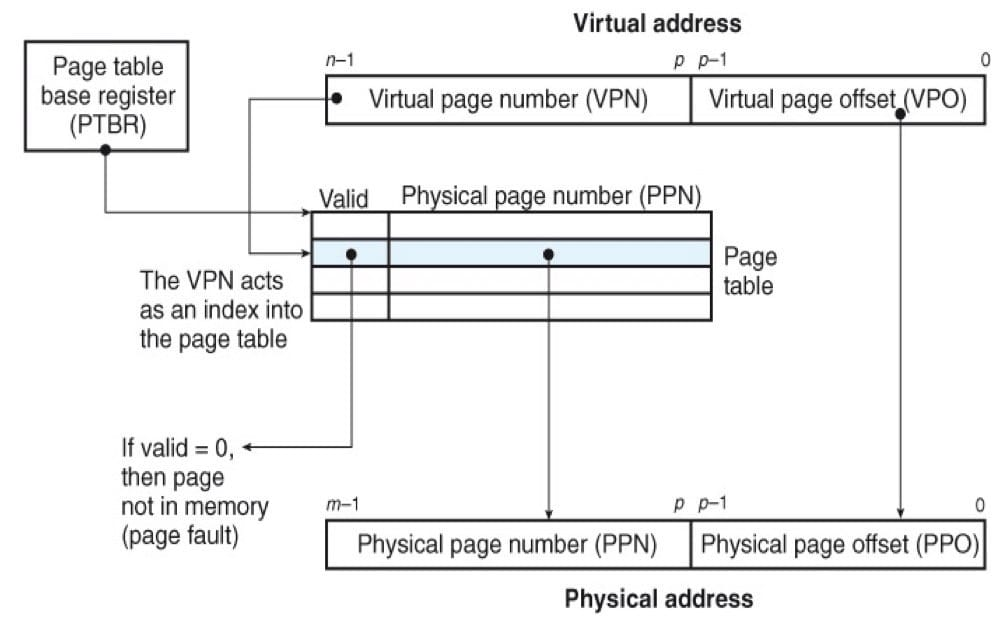
이 그림은 MMU가 매핑을 하기위해 페이지 테이블을 사용하는 과정이다.
-
PTBR(CPU내에 있는 제어 레지스터)가 현제 페이지 테이블을 가리킨다.
-
가상주소는 VPO(가상 페이지 오프셋)과 VPN(가상페이지 번호)를 가진다.
-
MMU는 VPN을 사용해서 PTE를 선택한다.(Ex/ VPN0 -> PTE0)
-
대응되는 PPN(물리페이지 번호)와 VPO를 연결한다.
-
물리/가상 페이지가 모두 P바이트이기 때문에 PPO와 VPO는 동일하다.
이후의 내용은 캐시와 VM의 통합, TLB를 사용한 주소 번역 속도의 개선,
그리고 2단계 페이지 테이블 계층구조, k단계 페이지 테이블을 사용한 주소 번역 등이 나온다.
9-6,9-7은 이정도로 하고, 메모리 매핑으로 넘어간다.
9-8 메모리 매핑
리눅스는 가상메모리 영역의 내용을 디스크 객체에 연결해서 초기화한다. 이 과정을 메모리 매핑이라고 하고, 다음 두 종류의 객체 중 하나로 매핑된다.
-
일반 파일(regular file) : 실행가능 목적파일과 같은 일반 디스크 파일이다. 이 파일들은 연속적인 섹션으로 매핑될 수 있는데, 파일 섹션은 페이지 크기의 조각들로 나눠지고, 각각 가상 페이지의 초기 내용을 포함하고 있다.
-
무기명 파일(anonymous file) : 이 파일들은 커널이 만든 것이며, 모두 이진수 0을 포함한다. cpu가 이 영역의 가상 페이지에 처음으로 접근 할 때, 커널은 물리 메모리 내에서 적당한 희생자 페이지를 찾아내고, 희생자 페이지를 이진수 0으로 덮어쓰고, 이 페이지가 존재한다고 표시하기 위해 페이지 테이블을 갱신한다. 하지만 데이터의 이동이 없기 때문에 demand-zero페이지라고 불린다.(요청이 없는 페이지)
9-9 동적 메모리 할당
가상메모리를 mmap과 munmap 함수를 통해서 생성/삭제 할 수 있지만, 저수준의 언어이기 때문에 C 프로그래머들은 동적 메모리 할당기를 사용하는 것을 선호한다.
할당기는 다양한 크기의 블록들을 집합으로 관리한다.
-
블록들은 allocated(할당)되었거나 free(가용)하다.
-
allocated된 블록들은 사용을 위해 보존된다.
-
free된 블록들은 할당을 위해 사용 가능하다.
여기서, 할당기는 2가지로 나눠지는데,
-
명시적 할당기 : 특정 블록에게 '명시적'으로 반환을 요구한다. malloc이 대표적이다.
-
묵시적 할당기 : 할당기가 '묵시적'으로 블록의 반환을 요구한다. garbage collector가 대표적이다.
이후 나오는 설명은 명시적 할당기의 설계/구현에 관한 것이다.
이후 9-10에서 묵시적 할당기에 대한 설명이 나온다.
malloc 함수
-
malloc은 heap영역의 메모리를 동적으로 할당(malloc,calloc...)/해제(free)하는 함수이다.
-
malloc은 mmap와 munmap함수를 사용해 명시적으로 heap메모리를 할당/반환하며 sbrk함수를 사용 할 수 있다.
-
sbrk 함수는 커널의 brk 포인터에 incr을 더해서 heap을 늘리거나 줄인다.
-wiki-
brk and sbrk are basic memory management system calls used in Unix and Unix-like operating systems to control the amount of memory allocated to the data segment of the process. These functions are typically called from a higher-level memory management library function such as malloc. In the original Unix system, brk and sbrk were the only ways in which applications could acquire additional data space; later versions allowed this to also be done using the mmap call
즉 sbrk는 리눅스 시스템에서 프로세스의 할당 데이터의 양을 컨트롤하기 위한 system call이다.
왜 동적 메모리 할당을 써야되는가?
->실제 실행 전까지 자료 구조의 크기를 알 수 없는 경우들이 있기 때문..
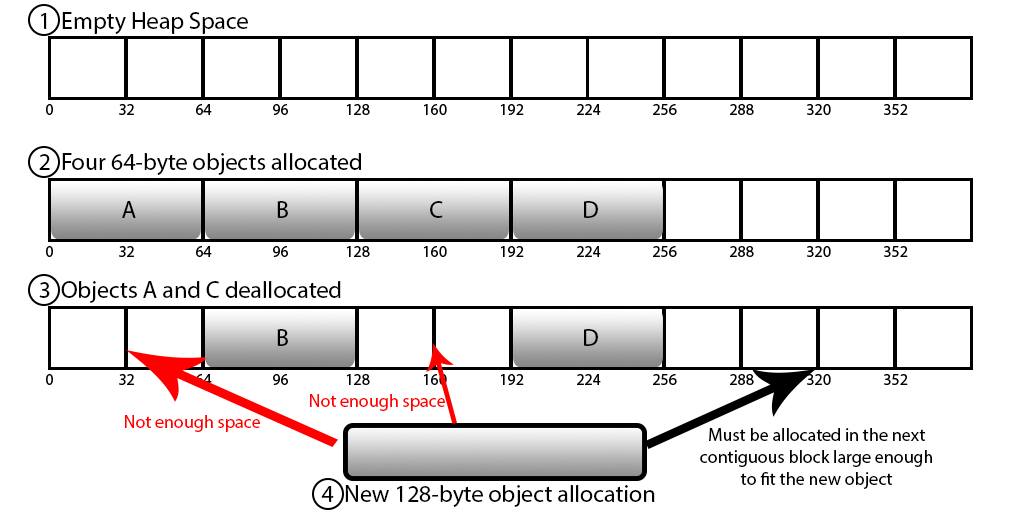
단편화
메모리 단편화는 상당히 큰 문제이다. 단편화가 심각해지면 위 그림처럼 메모리가 충분히 남아있음에도 불구하고 사용하지 못하는 경우가 생긴다. 단편화는 2가지가 존재한다.
-
내부 단편화 : 할당된 블록이 데이터 자체보다 더 클때 발생한다. 이때 할당은 받았지만, 할당된 블록이 더 크기 때문에 사용되진 않지만 할당은 되버린, 사용할 수 없는 블록이 생긴다.
-
외부 단편화 : 위 그림과 같이 메모리 공간이 전체적으로 봤을때 충분하지만, 요청을 처리할 가용 블럭은 없는 경우 발생한다.
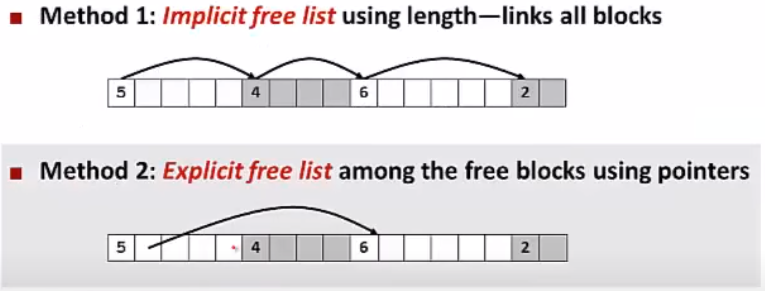
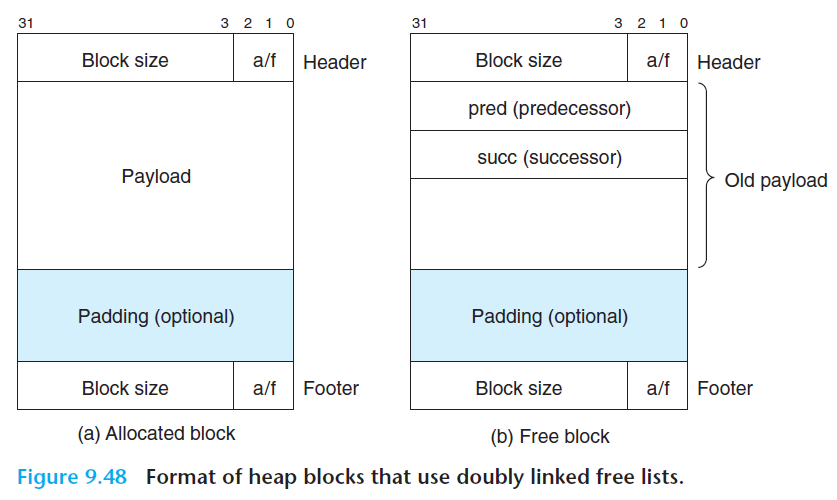
가용(free) 리스트
위 그림은 묵시적 가용 리스트와 명시적 가용 리스트의 설명이다.
-
묵시적 가용 리스트 : 헤더에 block size , allocated/free , payload, padding이 있다. block size가 있기 때문에 다음 블록의 헤더 위치가 어디있는지 '묵시적'으로 가리키기 때문에 묵시적 가용 리스트라고 한다.
장점은 단순성이다. 구조도 간단하고 구현도 편하다. 대신 가용 리스트 탐색시 전체 블럭들을 순회해야 한다는 단점이 있다. -
명시적 가용 리스트 : 묵시적 가용 리스트의 payload 안에 pred/succ가 있어서 다음 가용 리스트의 위치를 편하게 알 수 있다.
단점은 일반적으로 블록들의 크기가 포인터/헤더/풋터까지 포함을 해야 한다는 것이다. 그렇기 때문에 내부 단편화/블록의 크기 증가가 있다.
할당한 블록의 배치
여기서 쓸 내용은 어플리케이션이 블록을 allocate해서 가용블록을 찾는 것에 대한 설명이다.
이때, first fit,next fit , best fit이 주로 사용된다.
-
first fit : 리스트를 처음부터 검색해서 크기가 맞는 첫번째 가용 블록을 선택한다.
마지막에 가장 큰 가용 블록들을 남겨두는 장점이 있지만, 작은 가용블럭들을 앞에 남겨두는 경향이 있어 큰 블럭을 찾는데 시간이 오래 걸린다는 단점이 있다. -
next fit : 검색을 리스트의 처음에서 시작하는 대신, 이전 검색이 종료된 시점에서 검색을 시작한다.
first fit에 비해 매우 빠른 속도를 갖는 대신, first fit에 비해 최악의 메모리 이용도를 갖는다. -
best fit : 모든 가용블록을 검사하면서 크기가 맞는 가장 작은 블럭을 선택한다.
가용 블록 연결하기
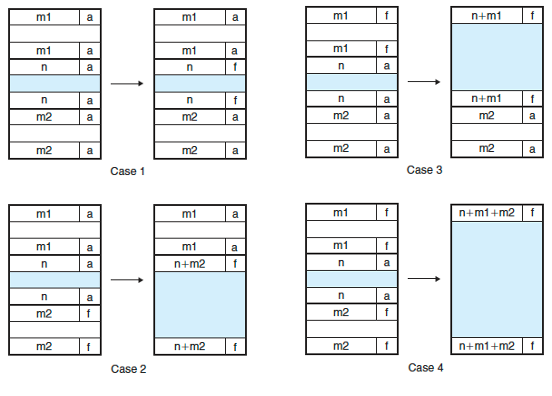
위 그림으로 모든게 설명이 된다.
할당 블록을 가용 블록으로 전환할 때, 주변의 블럭이 가용 블록이라면 그 블록까지 묶어서 가용 블록으로 만든다.

계란을 깨지 않고는 오믈렛을 만들 수 없다는 말이 있다. 지금 책의 내용이 머리에 들어오지도 않고 공부하는것도 힘들지만 성과를 내기 위해서는 이러한 과정도 감안해야 한다.
이후의 내용은 동적할당기 실습 내용이며, 프로잭트 회고때 내용 추가를 할 것 같다.
