
서버 부하 테스트를 해볼 것이다.
여러번 서버 테스트를 진행하였고, 그 값들 중 필요한 것을 글을 적으며 다시 테스트하였기에
테스트 시간이 들쭉날쭉하다.
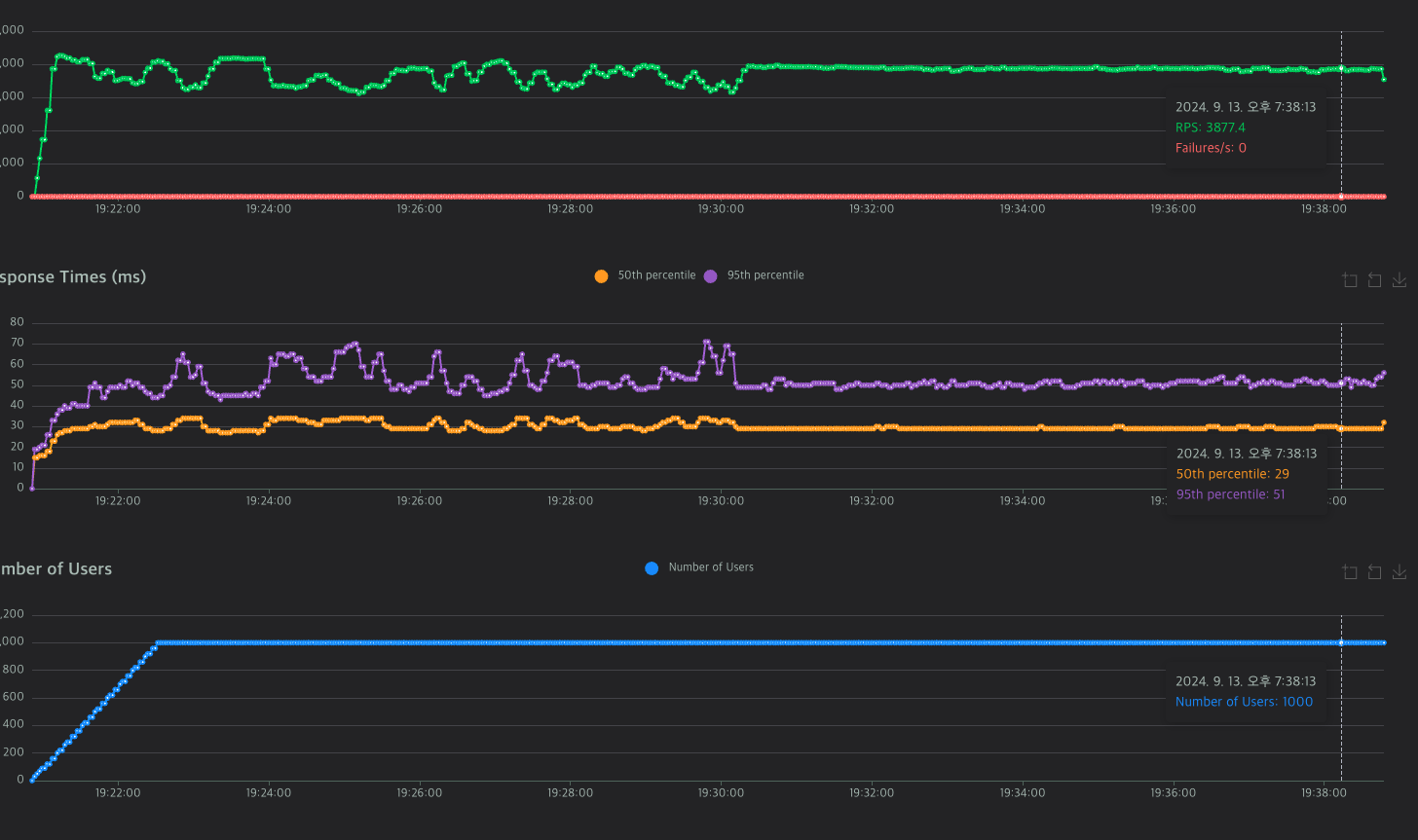
서버에 요청을 보내는 테스트이다.
메인 페이지로 이동하고,
backend connect complete! 라는 짧은 문장을 반환하는 코드만 담겨있다.
1000 User를 기준으로
속도 20ms, RTS 3500~4000대를 유지한다.
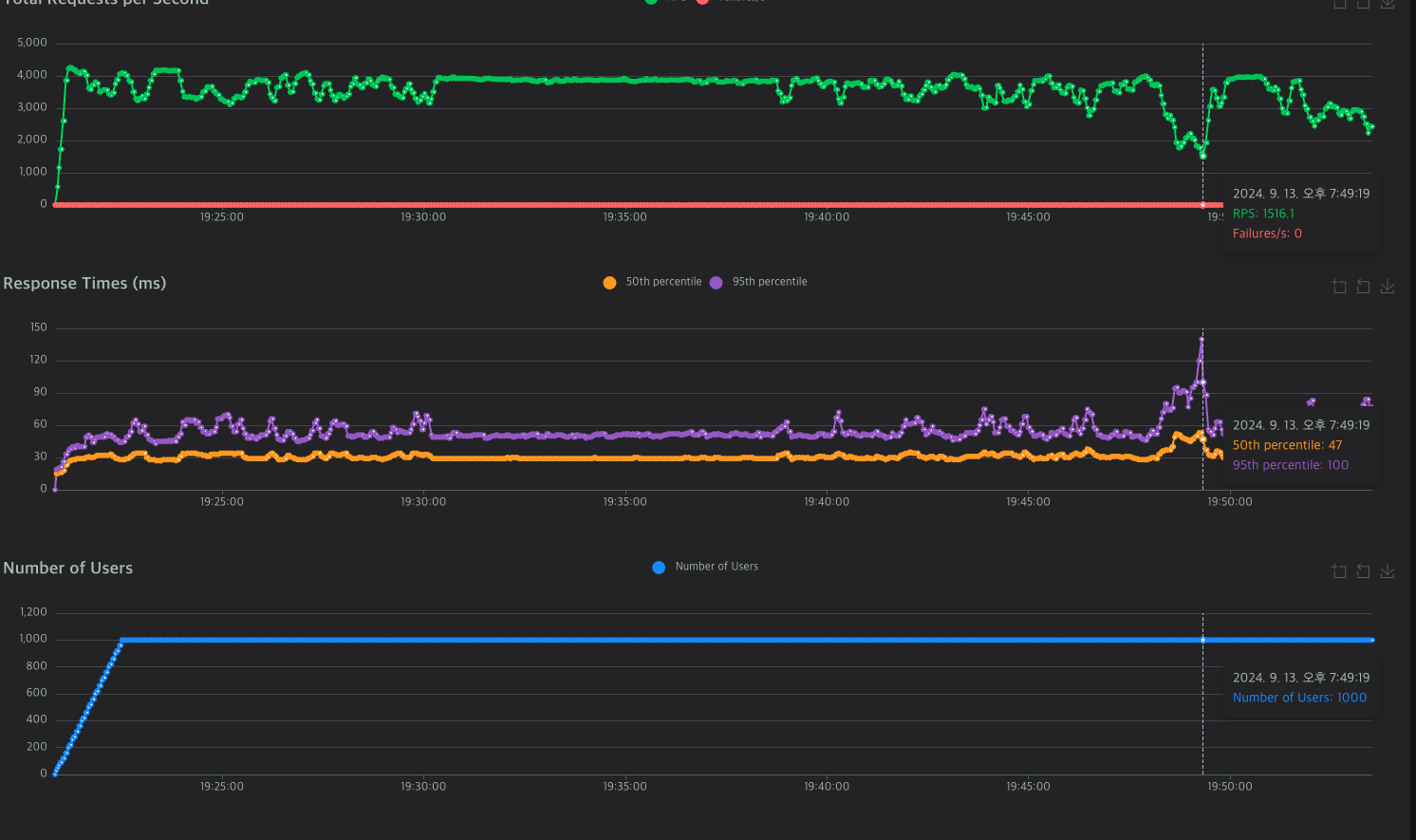
하지만 장시간 계속 데이터를 보내는 경우, RTS가 확 감소하고 응답시간이 튀어오르는 경우가 발생한다.
DB 부하 테스트
public Electricity getRandomElectricity() {
return electricityRepository.findRandomEntity()
.orElseThrow(() -> new RuntimeException("랜덤한 데이터를 찾을 수 없습니다."));
}
간단하게 랜덤으로 데이터를 불러와 봤다.
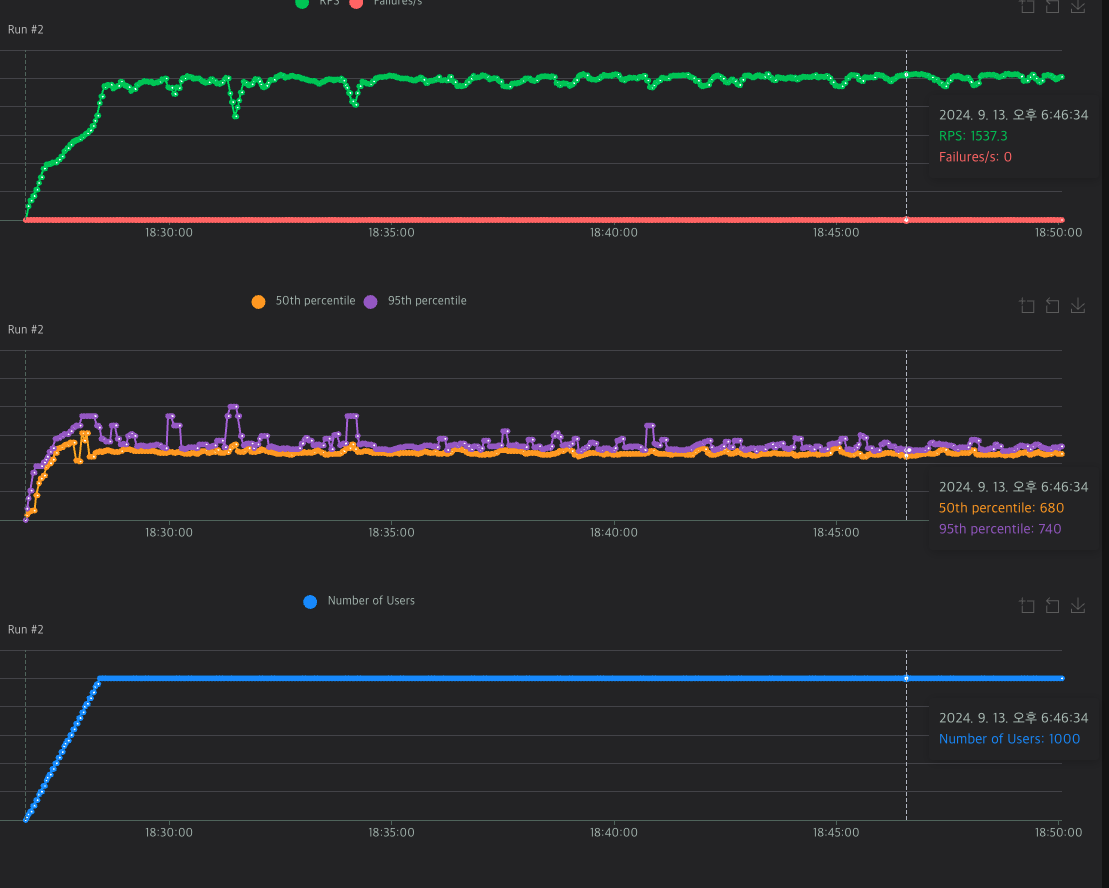
Locust로 호출시 1000 user에 rps 1500, 반응 시간은 약 700ms가 나왔다.
생각보다 서버 자원을 엄청 먹는거 같다. cpu 사용률이 100프로를 찍었다.
답도없이 느리다. 진짜 이정도로 느릴줄은 몰랐다.
위에서 서버 응답시간이 20~40 사이인거를 감안하면 DB 속도 때문에 서버 병목현상이 발생한다.
병목현상이란 두 구성요소의 성능 차이로 인해 잠재적인 성능이 제한된다는 것이다.
레퍼런스 : https://www.intel.co.kr/content/www/kr/ko/gaming/resources/what-is-bottlenecking-my-pc.html
최적화에 대한 고민
가장 간편한 방법으로는 Redis를 활용하는 것이다.
캐시를 이용하는건 절대다수의 상황에서 옳다.
그리고 Redis에 대해 잘 몰라서 공부를 좀 해봤다.
레퍼런스 : https://www.cs.rochester.edu/courses/261/fall2017/termpaper/submissions/06/Paper.pdf
두번째는 No-SQL을 사용하는 것이다. 단순 조회라면 key-value 값을 사용하는 nosql이 RDB보다 훨씬 빠르다.
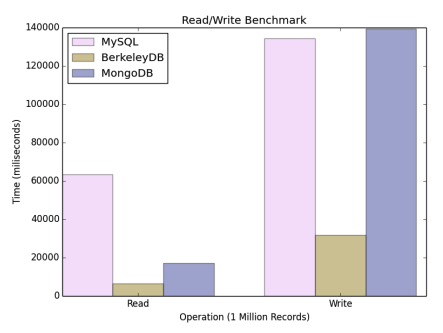
DB 성능이 어떤가 찾아보던 중 어느 블로그에서 논문을 리뷰한걸 보고 읽어봤는데, 그래프에서 MySQL보다 MongoDB가 훨씬 빠른걸 확인할 수 있다.
하지만 지금 PostgreSQL로 이미 세팅을 다 끝내놓았고, 나머지 최적화를 하고 난 이후에 후순위로 생각해야 할 문제인거 같다. 마이그레이션 하는데 비용이 상당히 들어갈 것으로 예상된다.
세번째는 커넥션 풀 조정이다.
서버의 최적화에 대해서 공부를 하던 도중, DB와의 연결에 커넥션이 필요하고, 커넥션 풀의 숫자가 서버의 CPU에 비해서 적다면 성능부족을, 과도하게 많다면 컨텍스트 스위칭에 의한 오버헤드가 커진다는것을 알게 되었다.

기본적으로 커넥션 풀이 10개로 설정되어있다고 하지만, 개수를 조절해 가며 최적화를 노려볼 수도 있다.
네번째는 연산의 최적화 이다.
하지만 지금 상황에서는 단순히 쿼리를 하나 불러올 뿐이라 연산과정이 없다.
연산의 최적화는 간단하게 생각하면 백준 알고리즘 문제 풀이와 비슷한 것이라고 생각한다.
O(n^2) 보다는 O(logn)이 훨씬 빠르지 않겠는가?
앞으로 연산이 필요한 부분을 계산할때 주의하도록 하자.
다섯번째는 인덱싱이다.
네번째와 마찬가지로 전체 값 중에 랜덤으로 값을 뽑는것이라 아직은 인덱싱이 필요하지 않다.
하지만 장기적으로 봤을때 우리 사이트는 데이터를 DB에서 프론트로 보내는 역할을 하기 때문에
중요하게 짚고 넘어갈 날이 올 것이다. 하지만 지금은 아니라고 생각한다.
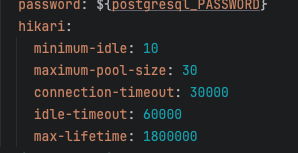
최적화 1-1 배포 커넥션풀
이중 먼저 커넥션 풀을 조절해 볼 것이다. 나머지는 redis를 설정하거나 DB를 바꾸는 짓을 해야되는데, 지금으로써는 감당이 안된다.
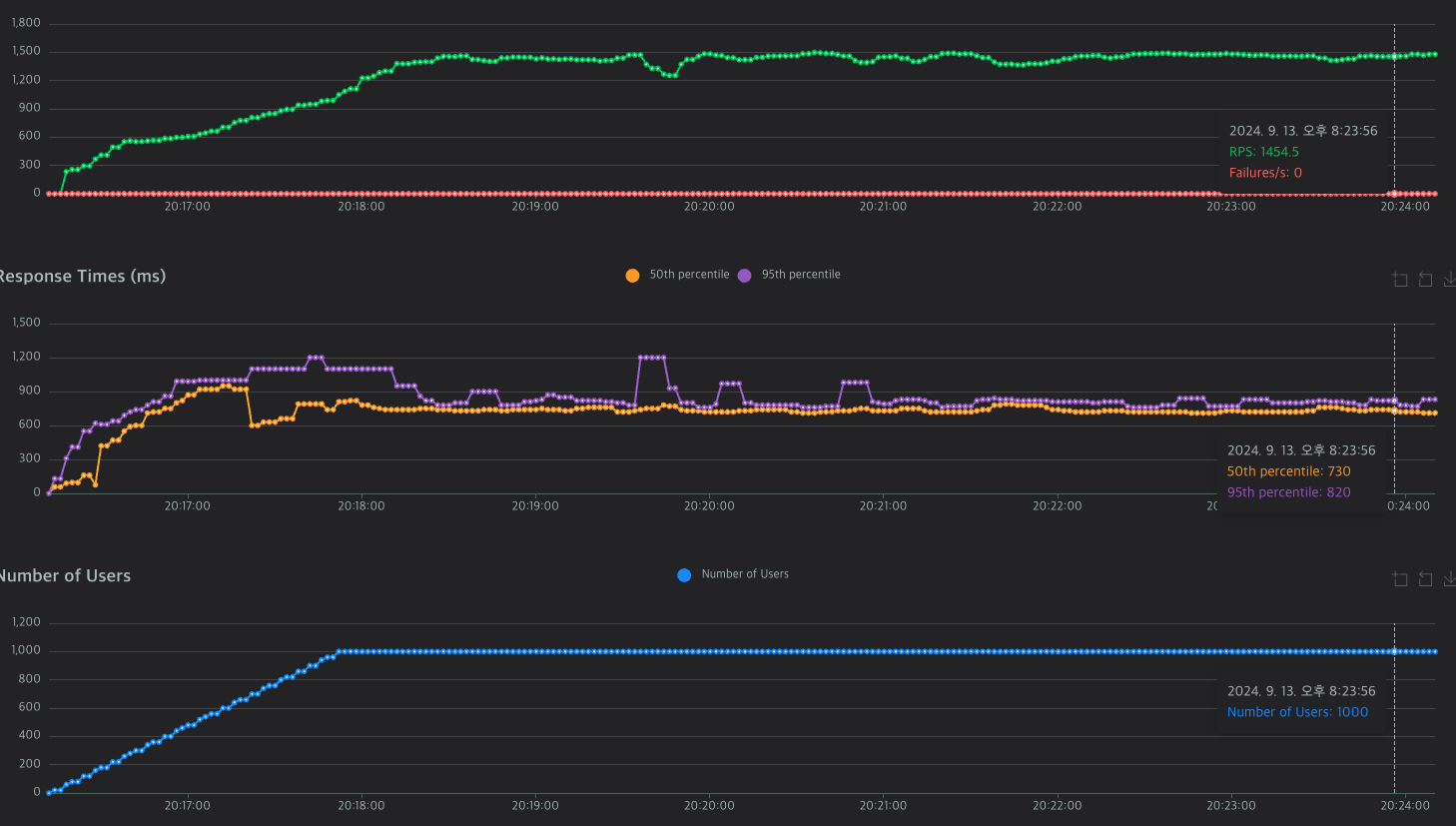
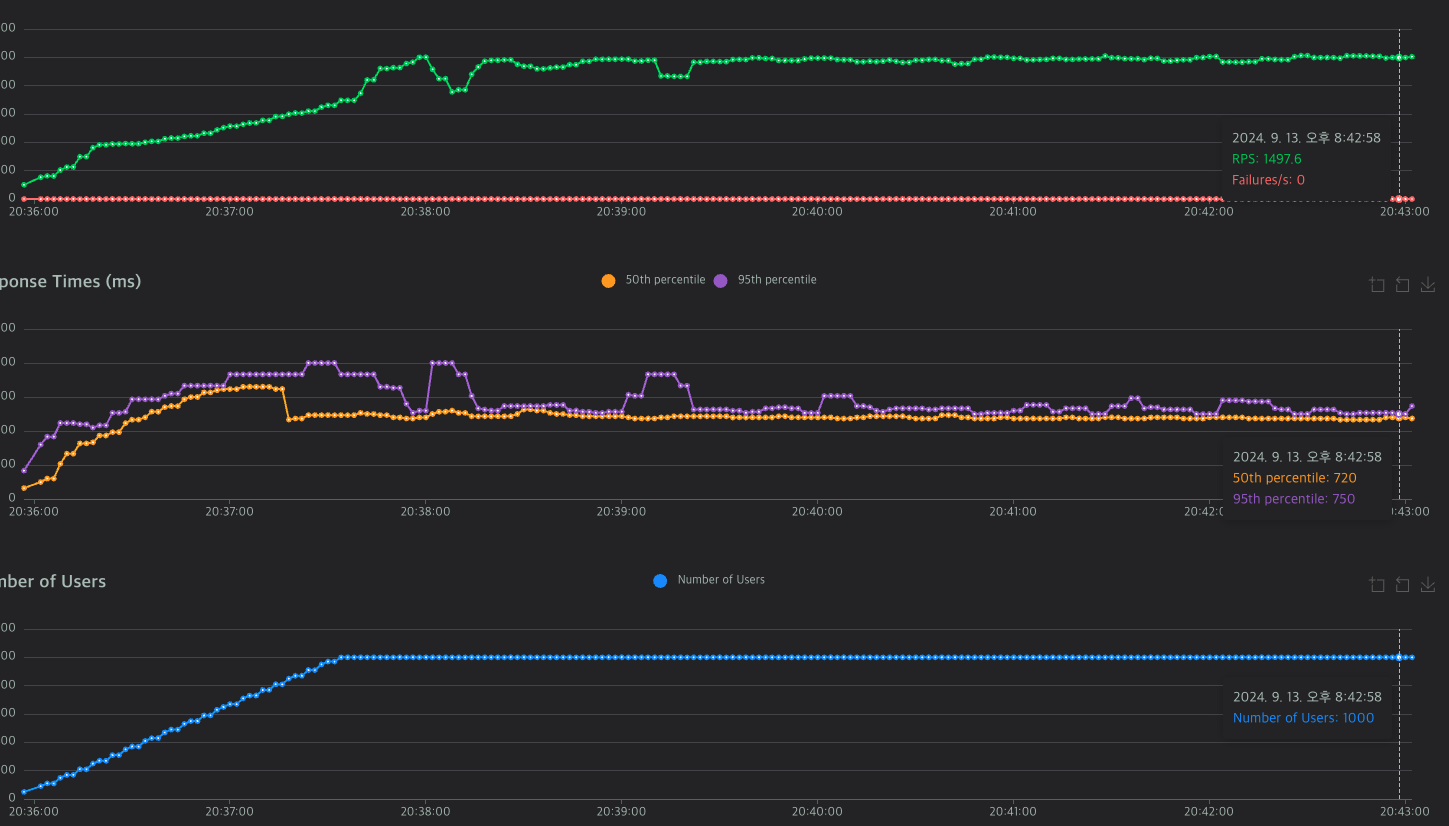
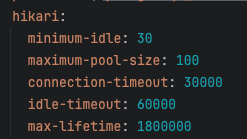
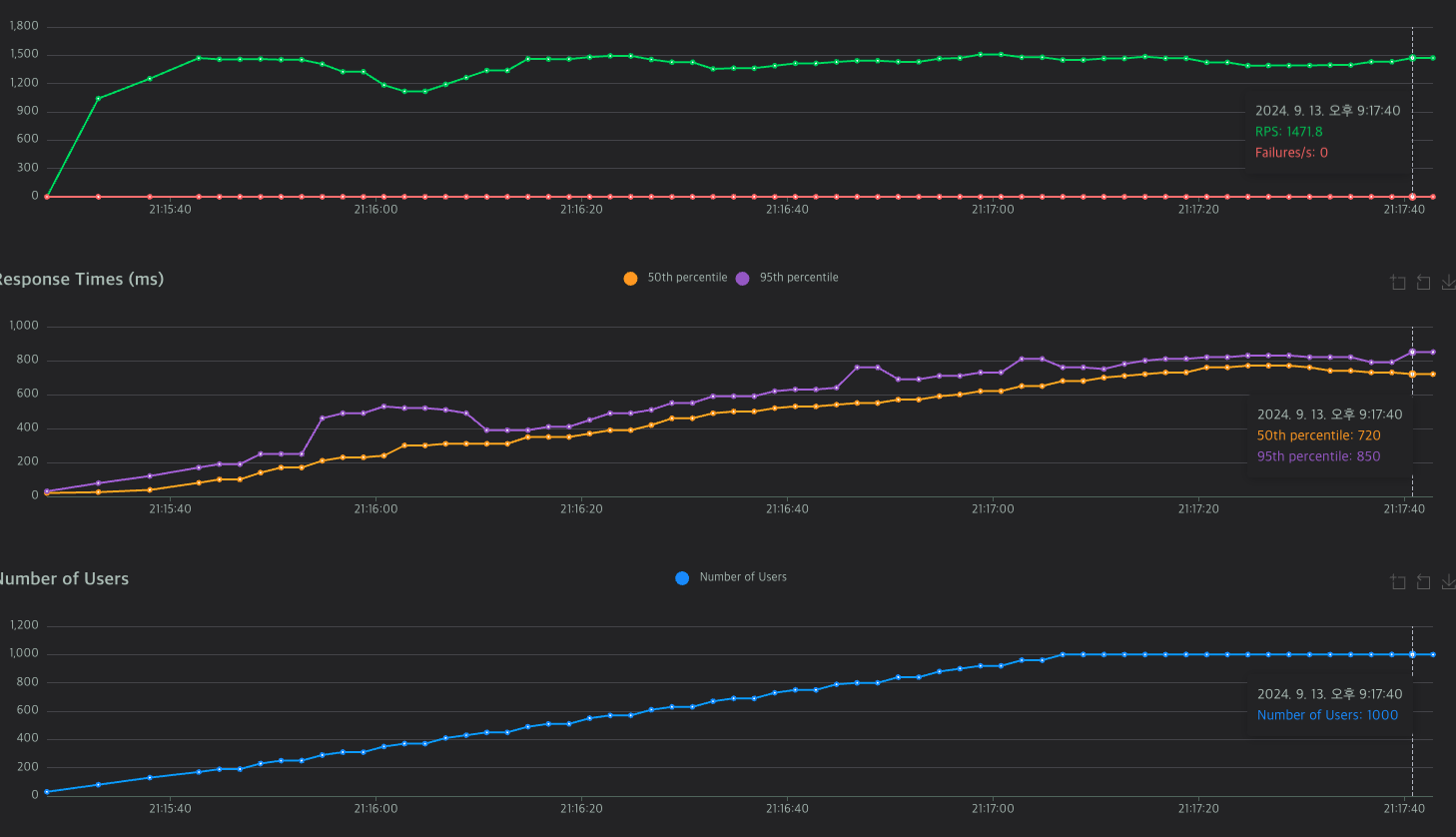
실험한 데이터 값들이다. 뭔가 이상한게 느껴지는가?
커넥션 풀을 조정했음에도 다 비슷한 값에 머무르고 있다.
그래서 한참을 고민했는데...
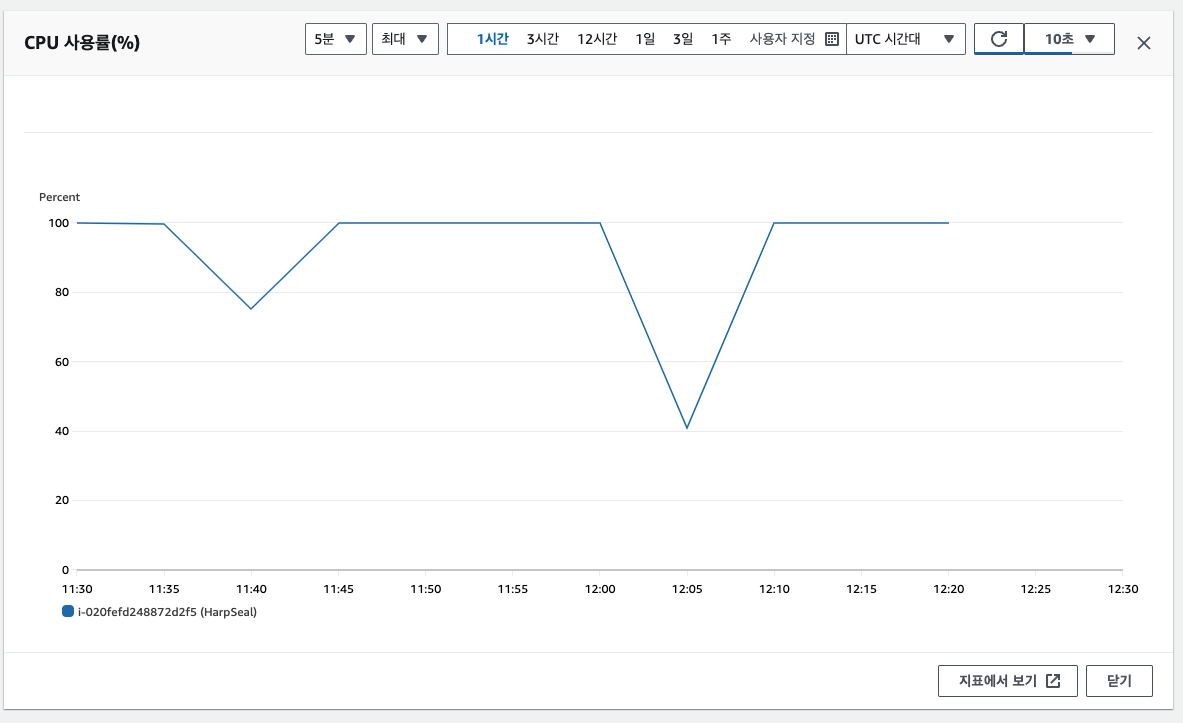
인스턴스가 죽을려고 한다.단순히 random 값을 뽑는거 RPS 1500인데 인스턴스가 감당을 못한다? 이건 쿼리에 문제가 있다고 생각했다. 이전 프로젝트에서 백엔드 팀원분이 user 수백 수천명으로 부하 테스트를 돌렸던걸로 봐서는, 지금 상황은 비정상적이라 판단했다.

그래서 기존 random과 숫자하나 랜덤으로 받아서 key값을 조회하는걸로 나눠 성능 테스트를 해봤다
각각 1000번씩 호출하는 코드이다.
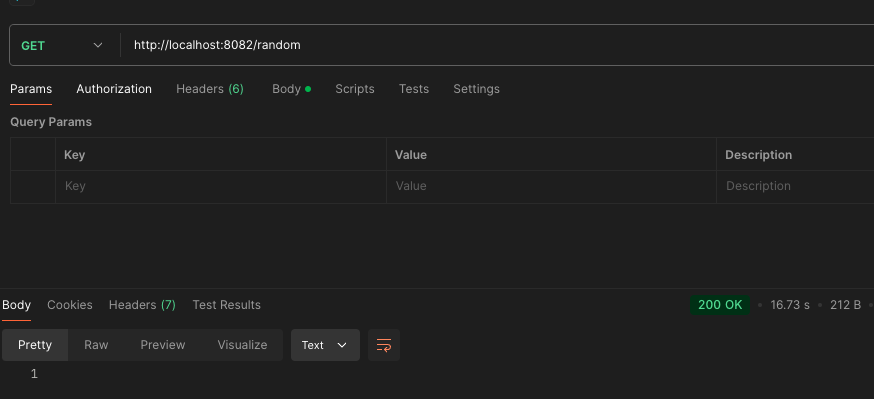
깡으로 Random 호출하는것은 16초가 걸린다. 스크린샷을 못찍었는데, 단순 select가 30초가 걸린다..
도저히 방법을 못찾고 껐다. 하지만 이로 인해서 서버 인스턴스가 얼마나 작은지, 성능이 낮은지에 대해 알 수 있었다.
이러니까 간단한 Jenkins 빌드조차 cpu가 50프로씩 먹는구나 싶었다.
인간적으로 100번 호출하는데 30초씩 걸리는건.. 너무하다.
요금 폭탄 맞을뻔한 상환
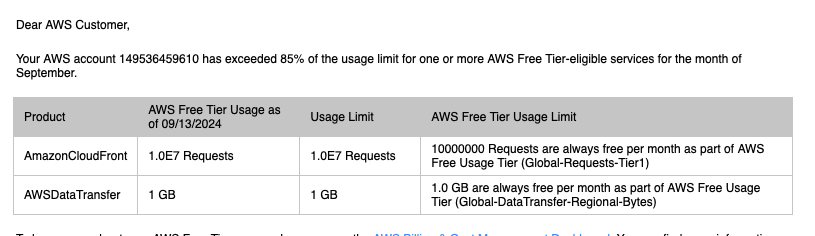
그렇게 고민을 하다가 자고 일어났는데..
CloudFront에서 free tier 기본 수치보다 훨씬 많은 요청을 했다고 연락이 왔다.
진짜 깜짝놀라서 aws 요금표를 봤고
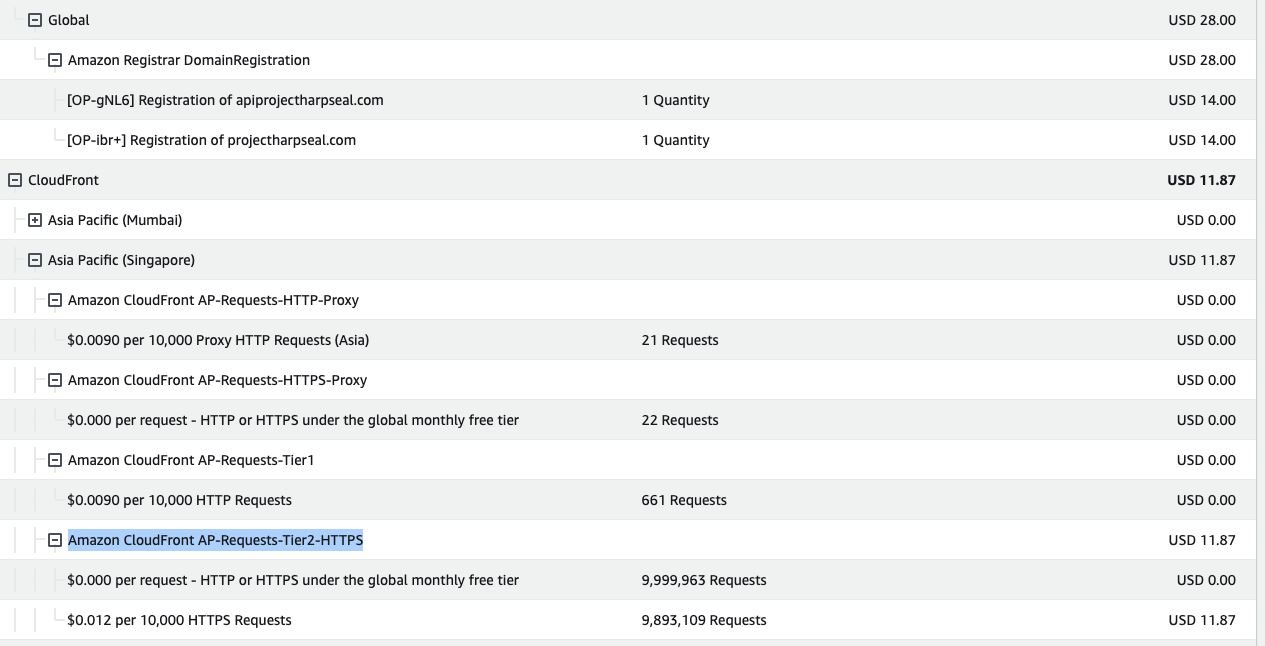

와 진짜 큰일날뻔했다
잠 잘못자고 코딩하다가 피곤해서 끊고 잤는데
계속 돌렸으면 몇십만원 단위의 요금폭탄을 맞을뻔했다...
상세 요금은 다음과 같다.
front/back의 도메인을 사는데 28달러, cloud front에 요청한 약 200만건 = 프리티어 + 약12달러
몇시간 안돌렸는데 이정도면 하루종일 돌렸으면 진짜 10만원대 까지는 요금 부과가 나왔을것이라 생각한다.
큰 교훈 하나를 얻었다. 무조건 부하 테스트는 로컬로 하자..
바로 로컬 DB 불러오고 환경변수도 편집한 후
돌리니 local 환경이라 훨씬 빠른 모습이다.
최적화 1-2 로컬 커넥션풀
자, 로컬 환경으로 돌렸으니 이제 위에서 설정했던 connection pool을 다시 실험해야 한다.
실험에 앞서, 컴퓨터의 성능을 시험해 보자.
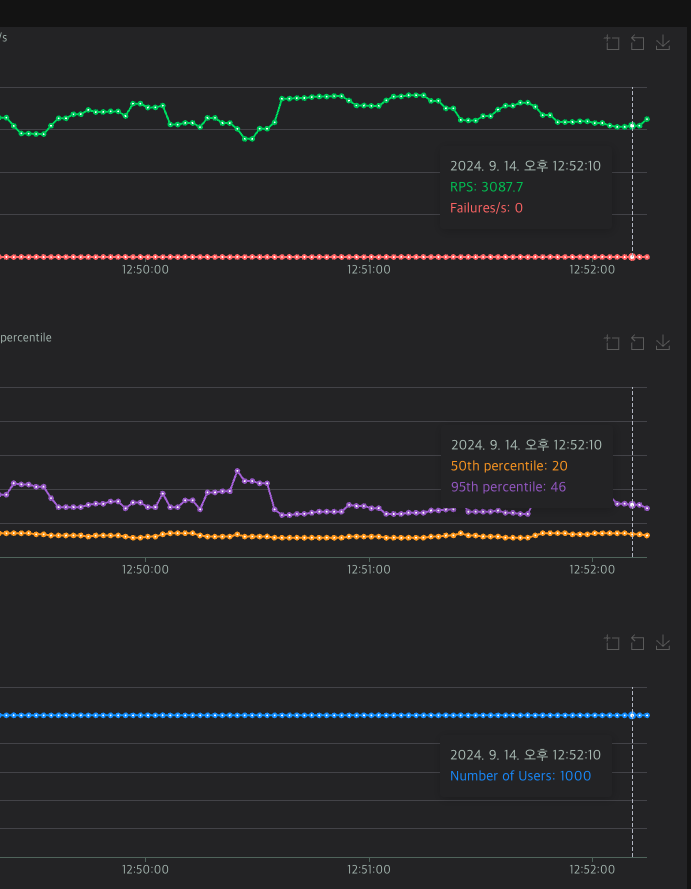
random을 1000 user로 돌렸다.
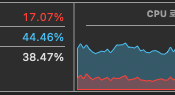
기본 cpu가 15~20프로 정도 먹음으로, cpu의 30프로정도를 먹는다고 보면 된다.
이는 프로그램에 할당된 cpu의 최대로, intellij의 %cpu가 100프로로 돌아가는걸 확인할 수 있다.
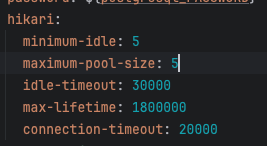
다시 등장한 커넥션 풀
기본 10개니까 5개로 해보았다.
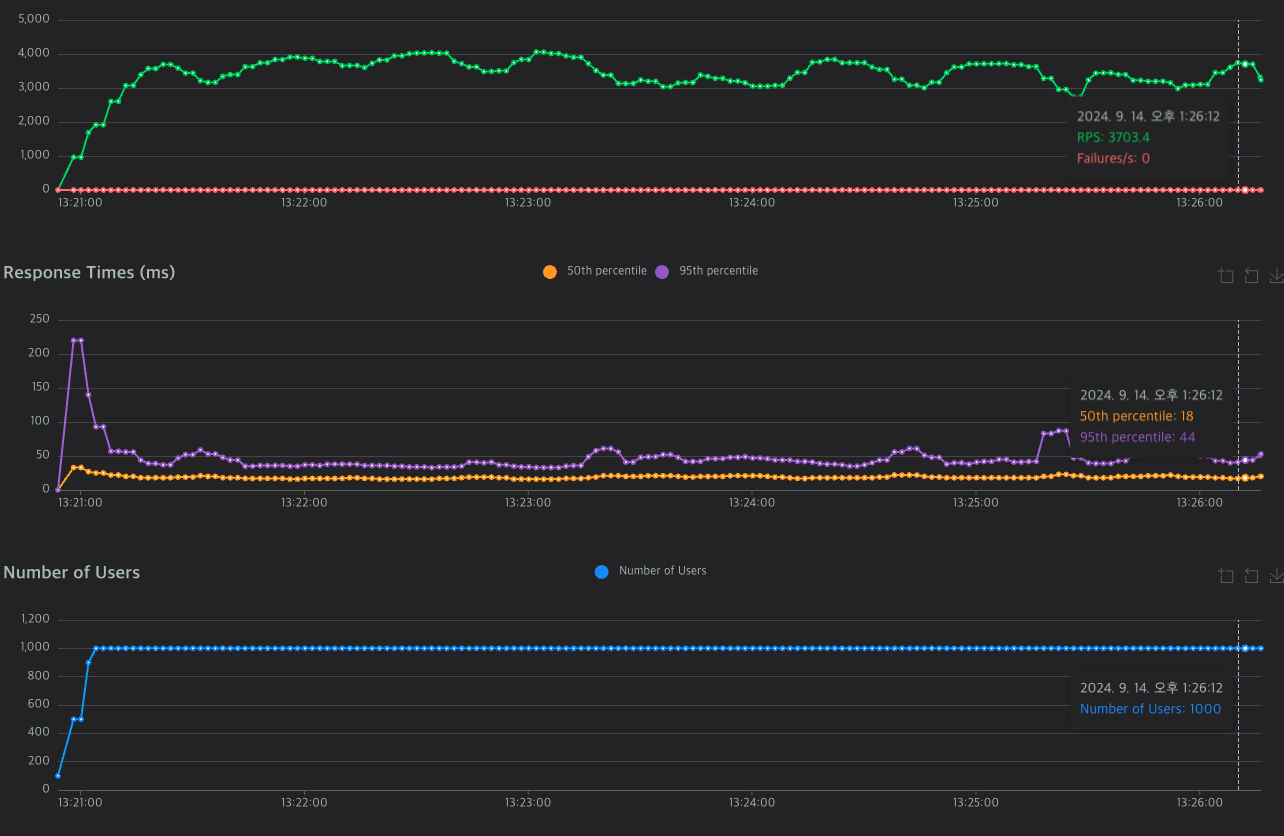
RTS는 3000~4000사이를 왔다갔다하고, 4000 이상으로 올라갈 때도 있었다.
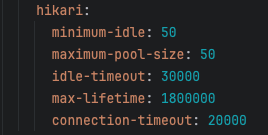
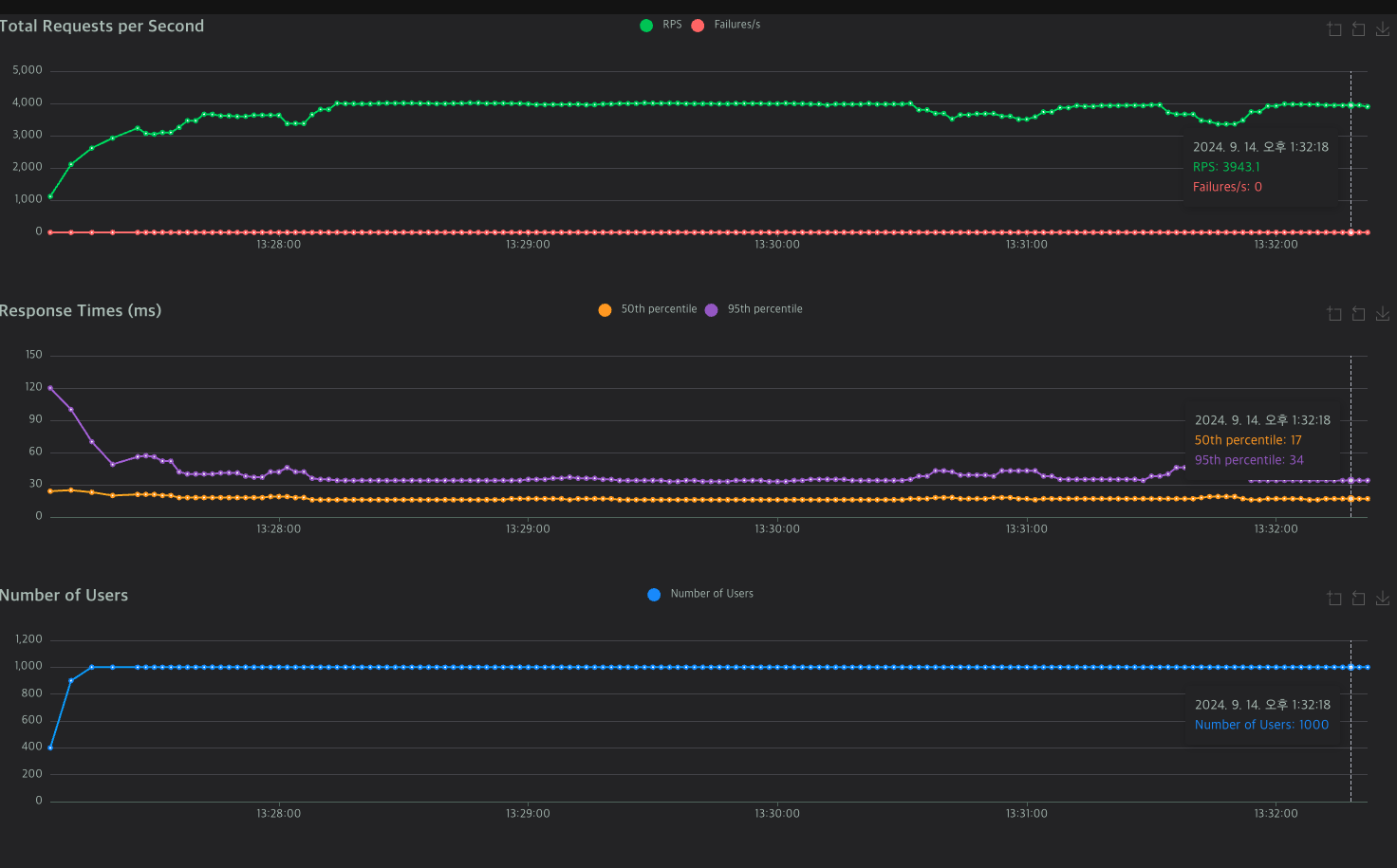

이번에는 50으로 올렸다.
와 진짜 놀랐다. 4000대 안정적으로 뽑히고 RT도 줄어들었다.
이때 최적의 커넥션풀을 어덯게 구하는지 궁금해서 공부를 해 보았다.
레퍼런스 : https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing

유효 스핀들 카운터가 무엇인지 모르겠다.
하지만 뒤따라 나오는 설명에 하드디스크당 1개를 추가하라는것을 보아, 하드디스크 개수를 의미하는거 같다.

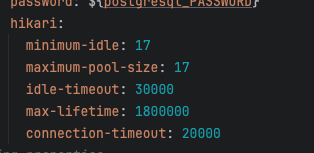
현재 사용하고 있는 컴퓨터는 맥북M2, 코어는 8개 이다.
따라서 8*2 + 1 = 17개가 적절한 스래드풀 개수라는것이 된다!
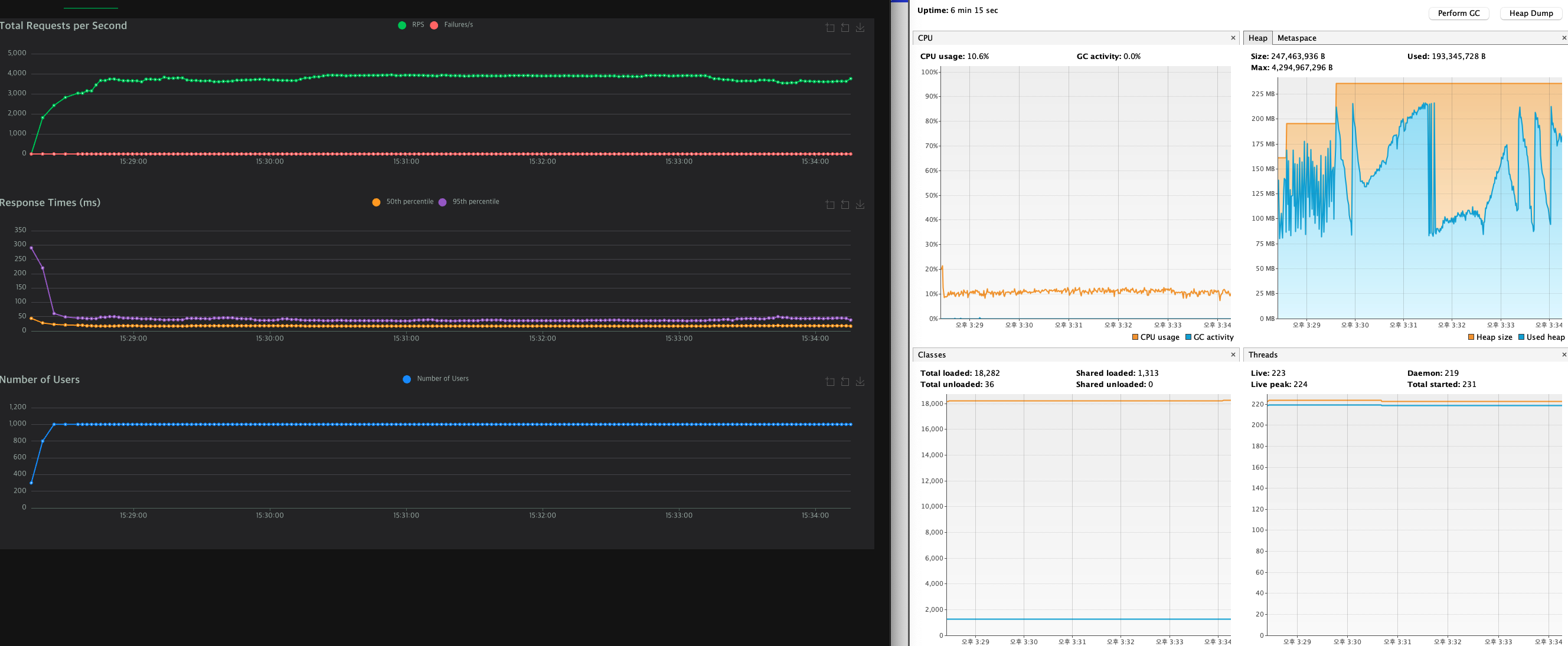
와 진짜 테스트 하다가 감탄해서 찍었다.
(오른쪽의 툴은 다음 챕터에서 설명할것이다.)
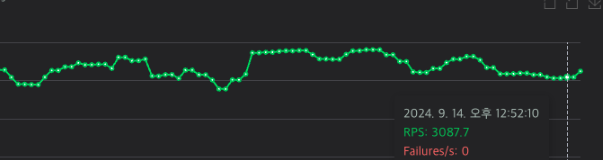
이건 처음 아무런 설정을 하지 않았을때 RPS 그래프 이다.
커넥션 풀 최적화를 했다고 이렇게까지 안정적인 성적이 나올줄 몰랐다.
기존 10개, 테스트 할때의 5개는 커넥션풀이 부족해서 편차가 커지고,
50개는 너무 많아서 오버헤드가 발생했다고 해석할 수 있겠다.
그럼 여기서 꼭 말해야 할 것이 있다.
왜 배포 환경에서는 커넥션 풀이 성능에 영향을 끼치지 못했나?
일단 생각을 해 보자.
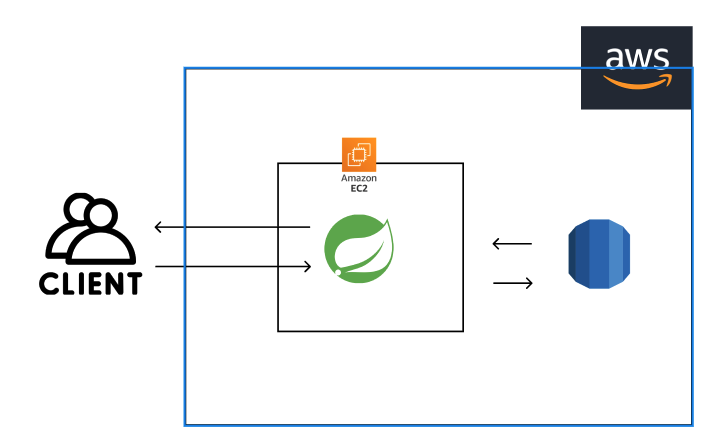
지금 배포된 서버와 통신하는 구조이다.
백엔드 서버는 AWS EC2에, DB도 AWS RDS에 배포되어 있는 상황이다.
CDN을 통해 프론트가 배포되어 통신속도가 빨라졌다고는 해도, 백엔드에 접근하려면
VPC와 로드밸런서 등 여러가지에 의해 막혀 속도가 빨라질 수가 없다.
또한 CPU의 성능이 처참하기 때문에 일정이상의 처리량은 기대할 수가 없을 것이다.
따라서, 병목현상이 일어나는 구간이 낮은 CPU성능과 느린 인터넷 속도라고 생각해 볼 수 있다.
로컬 영역에서는 테스트를 돌리고도 CPU의 성능이 한참 남고, 로컬환경의 통신속도도 엄청나게 빠르다.
따라서 CPU가 노는 시간 없이 100프로 자기 일을 할 수 있게 커넥션 풀을 늘리는 것이 실제로 도움이 되었고,
RT 감소와 높은 RPS유지에 도움이 되었다고 생각한다.
최적화 2-1 메모리 누수

테스트를 한참 돌리면서 검색을 하던 도중, Visual VM이라는 GUI 툴을 발견했다.
자바를 사용할때 자원, 특정 클래스의 자원 사용량 등을 모니터링 할수 있다고 한다.
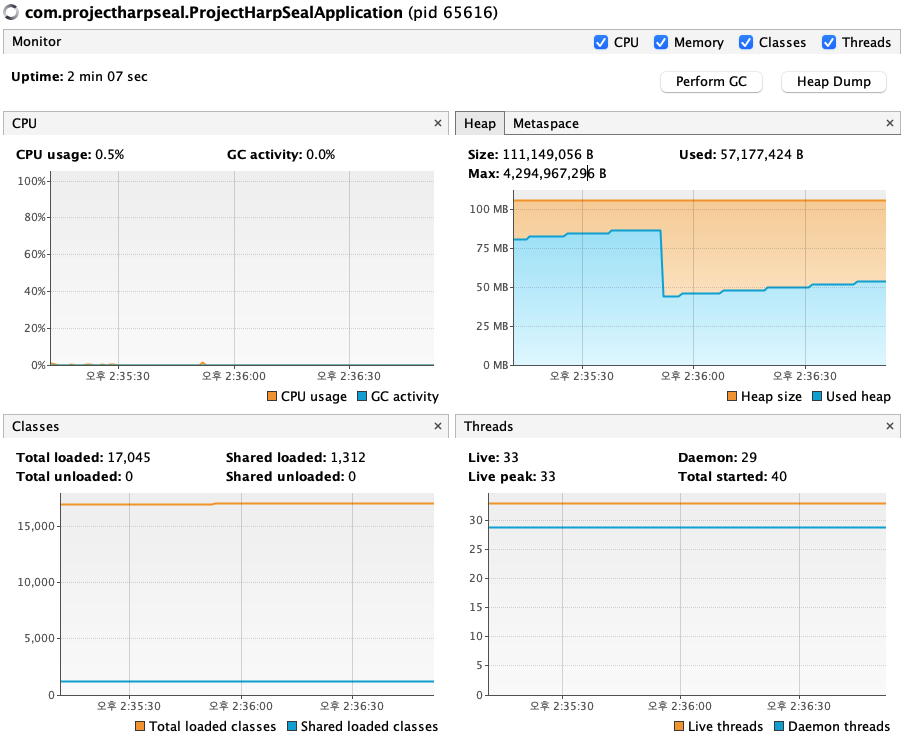
현재 Live Thread 개수는 33개, 데몬쓰레드는 29개 이다.
Locust로 테스트를 돌리게 되면
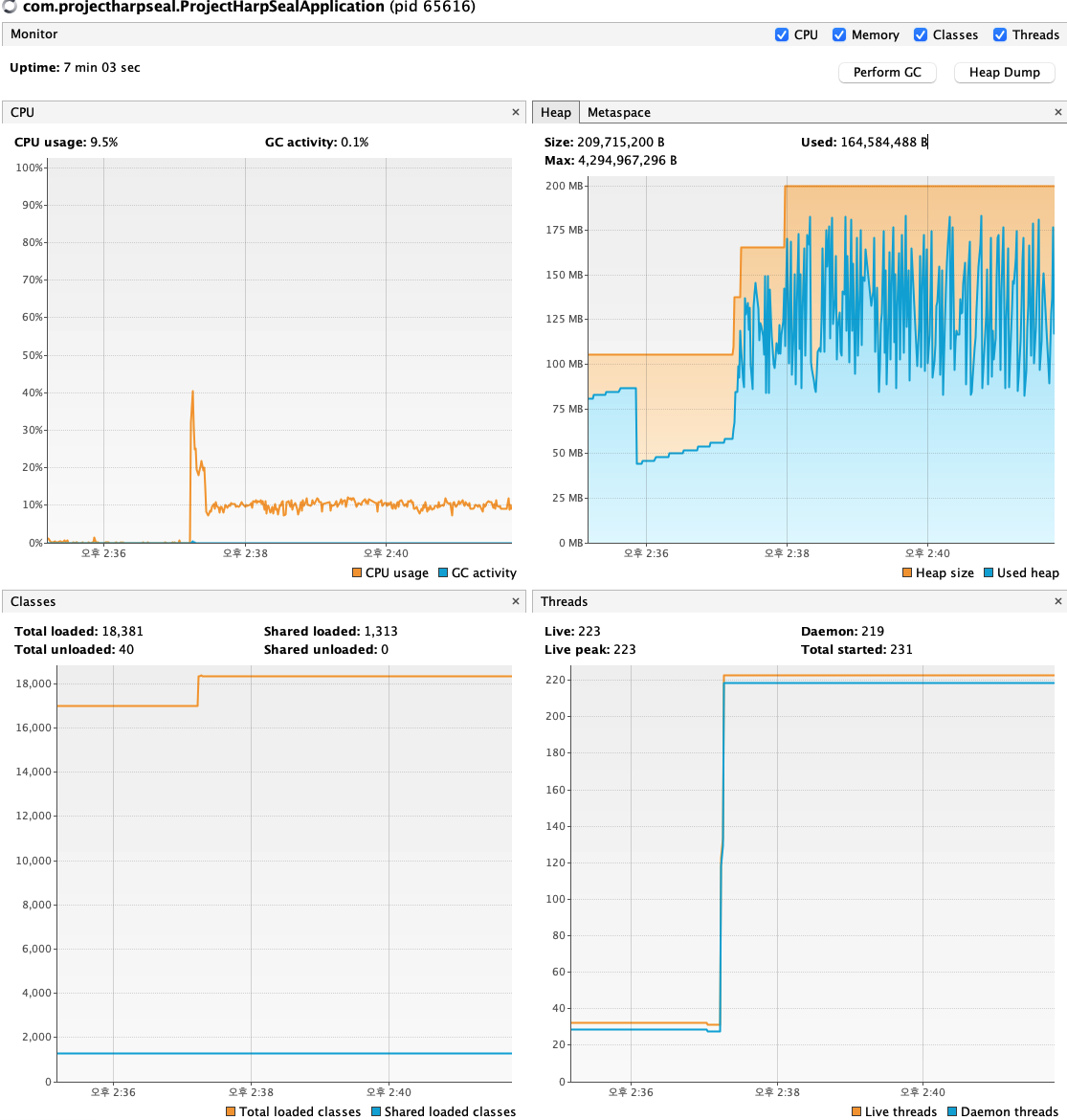
(승천하는 스래드 개수..)
Live, Daemon 스레드의 개수가 확 뛰어 버린다.
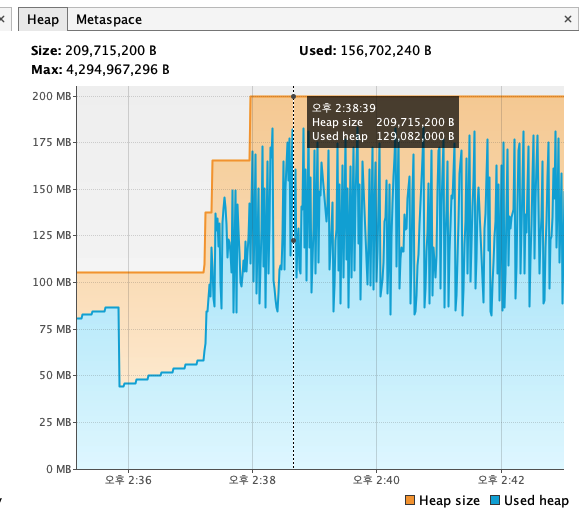
그리고 intellij의 모니터를 확인을 했는데, 좀 거슬리는 부분이 있다.
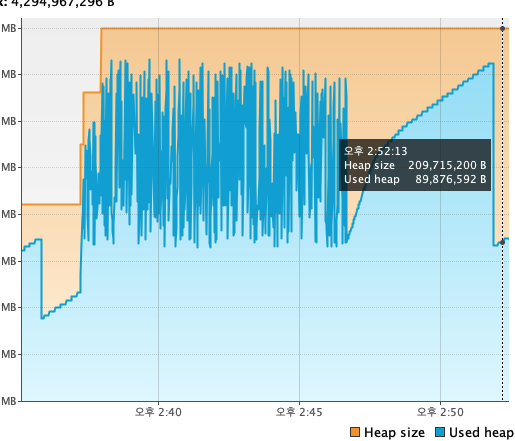
그것은 바로 메타스페이스의 Heap의 변동폭이다.
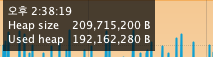
Heap이 고점을 찍었을때가 약 1.9억 B, 약 200메가바이트 정도 된다.
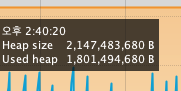
intellij에서는 약 2KB정도 된다.
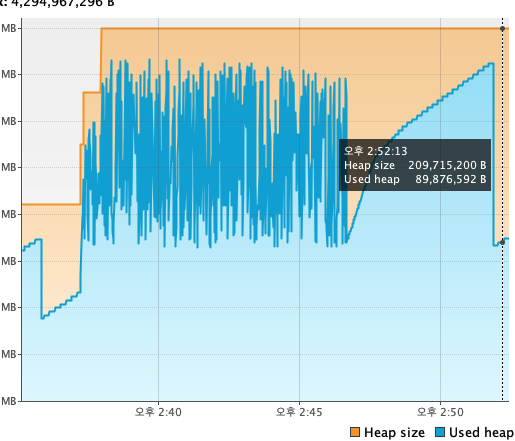
테스트가 끝나니 다시 메모리 정리를 하는 모습.
그리고 이 그림이 다시 나온다.
위의 힙메모리 그래프들은 사실 커넥션풀을 설정하지 않았을때의 값들이고
밑의 안정적인 그래프는 커넥션풀을 설정했을때의 값이다.
커넥션풀 최적화를 했음에도 불구하고 RPS가 3600까지 떨어지는 결과가 나왔다.
그런데 그때 상황을 잘 살펴보니
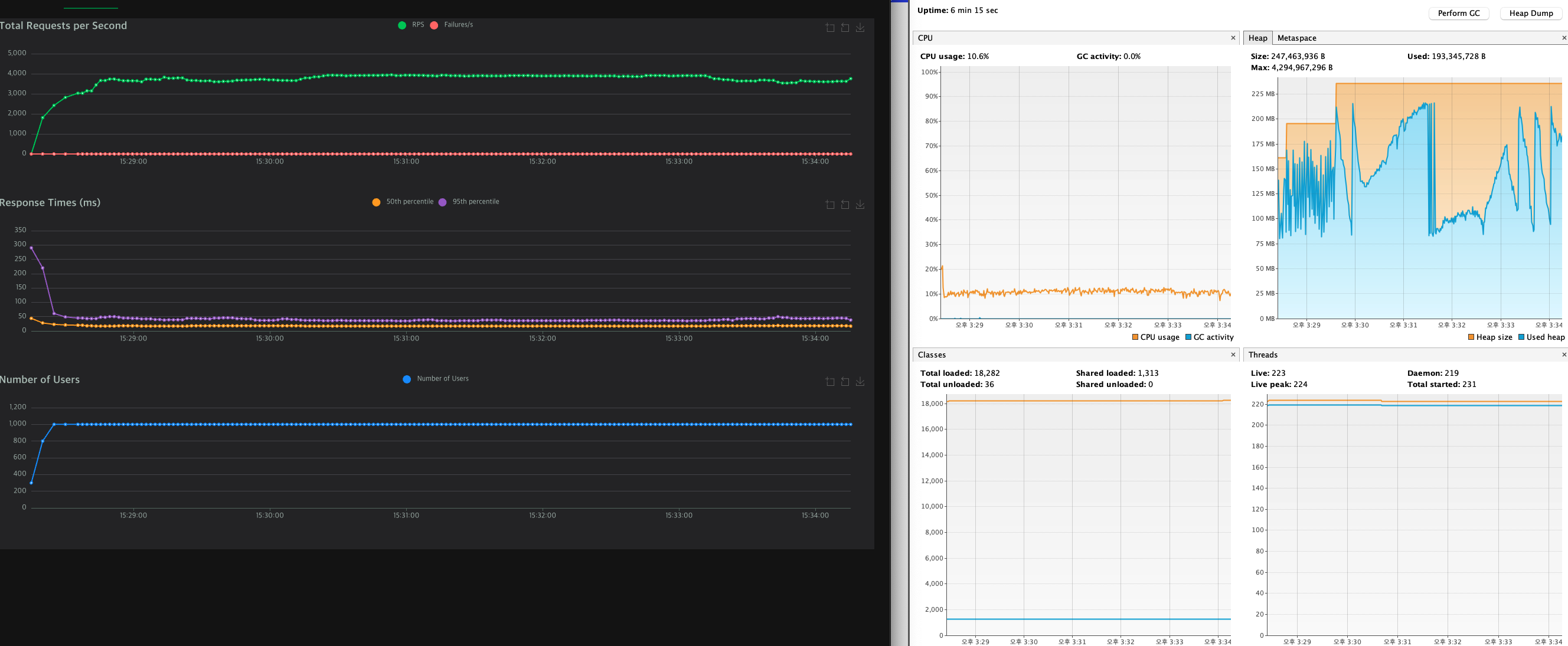
힙메모리가 쌓여 GC가 정리를 하고, 최저점에 도달하자마자 갑자기 Heap 메모리가 순간적으로 위로 튀는 현상이 발생했다.
여기서 최저점과 고점의 차이는 1프레임밖에 나지 않는다.
이러한 현상이 발생할때, 서버의 성능 저하가 발생했다.
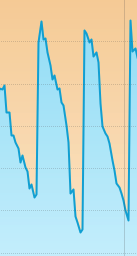
일반적으로 성능 고점이 뽑혔을때의 힙메모리 그래프는 위와 같았다.
그래서 다시한번 프로젝트를 돌려봤는데
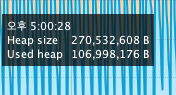
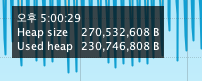
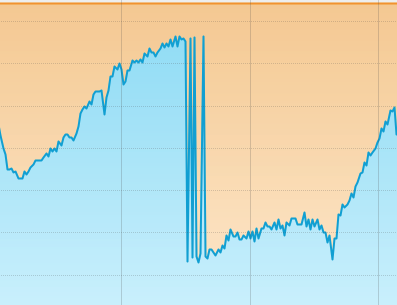
다시 똑같은 일이 반복되고 있다.
위의 시간은 5:00:28이지만, 성능 저하가 일어나는 16:52:00 구간에도 계속 저러고 있다.
그럼 왜 이런 현상이 발생할까?
가장 먼저 할일은 log를 찍어보는것이다.

근데.. 로그를 어떻게 찍지?
라고 궁금해 하면서 검색해보니 Heap Dump라는게 있다.
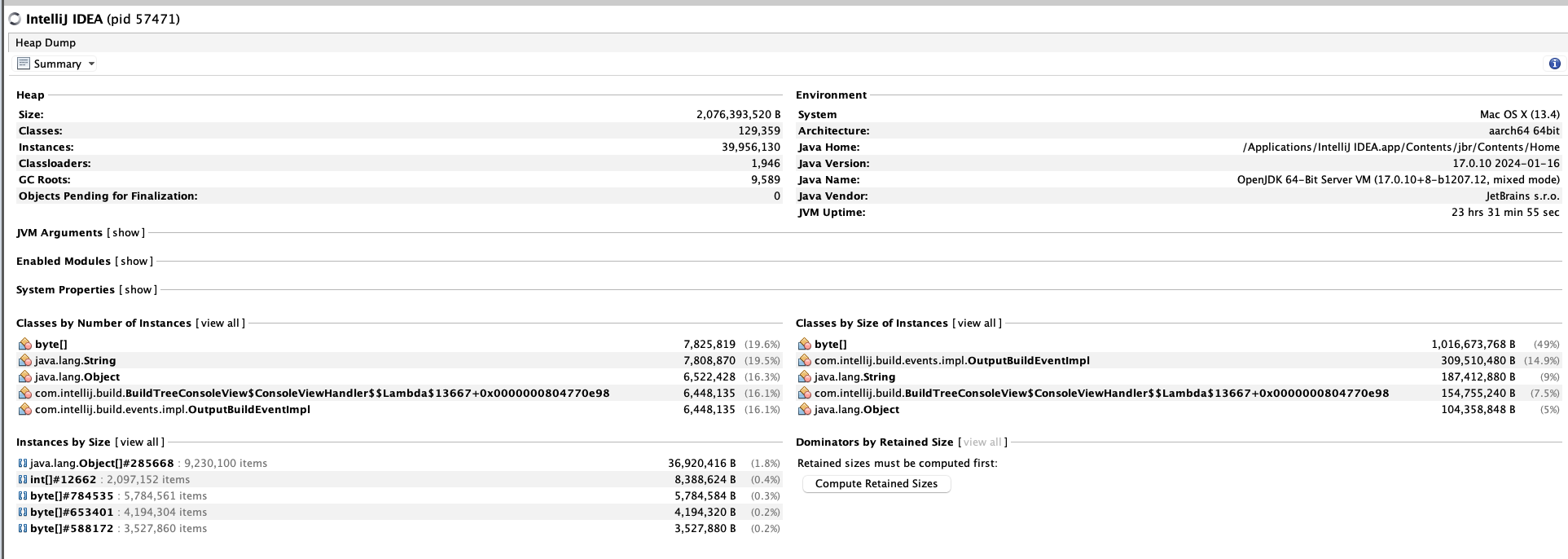
대충 이렇게 생긴놈이고
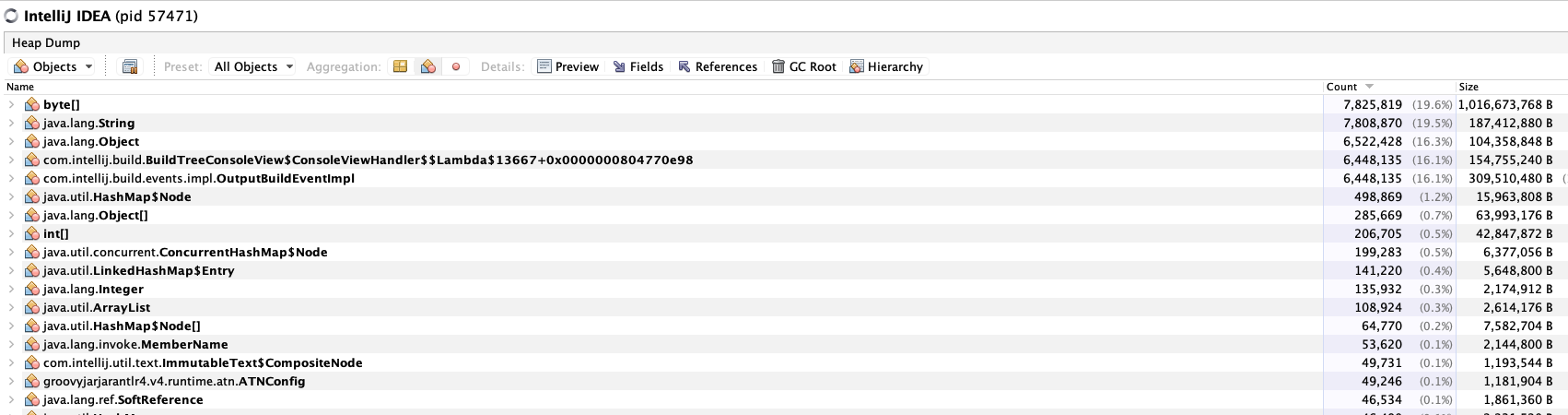
이렇게 객체들이 뭔놈이 있나까지 싹다 훑어볼수 있는 스냅샷이다.
문제는 뭐냐고?
위에서 봤다시피 고슴도치마냥 뾰족하기 때문에 계속 스냅샷을 찍을수가 없다는 것이다.
버튼 띡 누르면 1초만에 결과물이 나오는게 아니라, 생각보다 작업량이 많아서 한참걸린다.
1초마다 왔다갔다 하는데 그걸 어떻게찍냐는 것이다.
그래서 생각한게 뭐냐면
힙메모리 겁나 늘려가지고 가비지 컬렉터가 가끔 일하면되지않을까? 였다.
아니 그렇지 않은가? 너무 빨리 변해서 문제라면 가끔 변하게 만들면 된다고 생각했다.
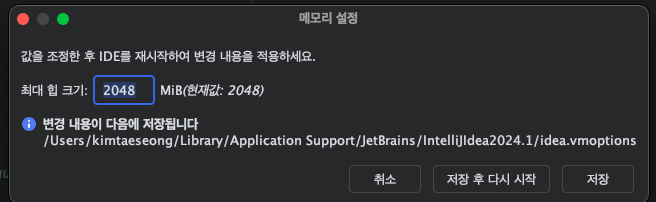
intellij의 힙크기 설정이다.
이걸 2배로 만들어준다.
그리고 테스트를 진행했는데.. 진짜 소름이 돋았다.
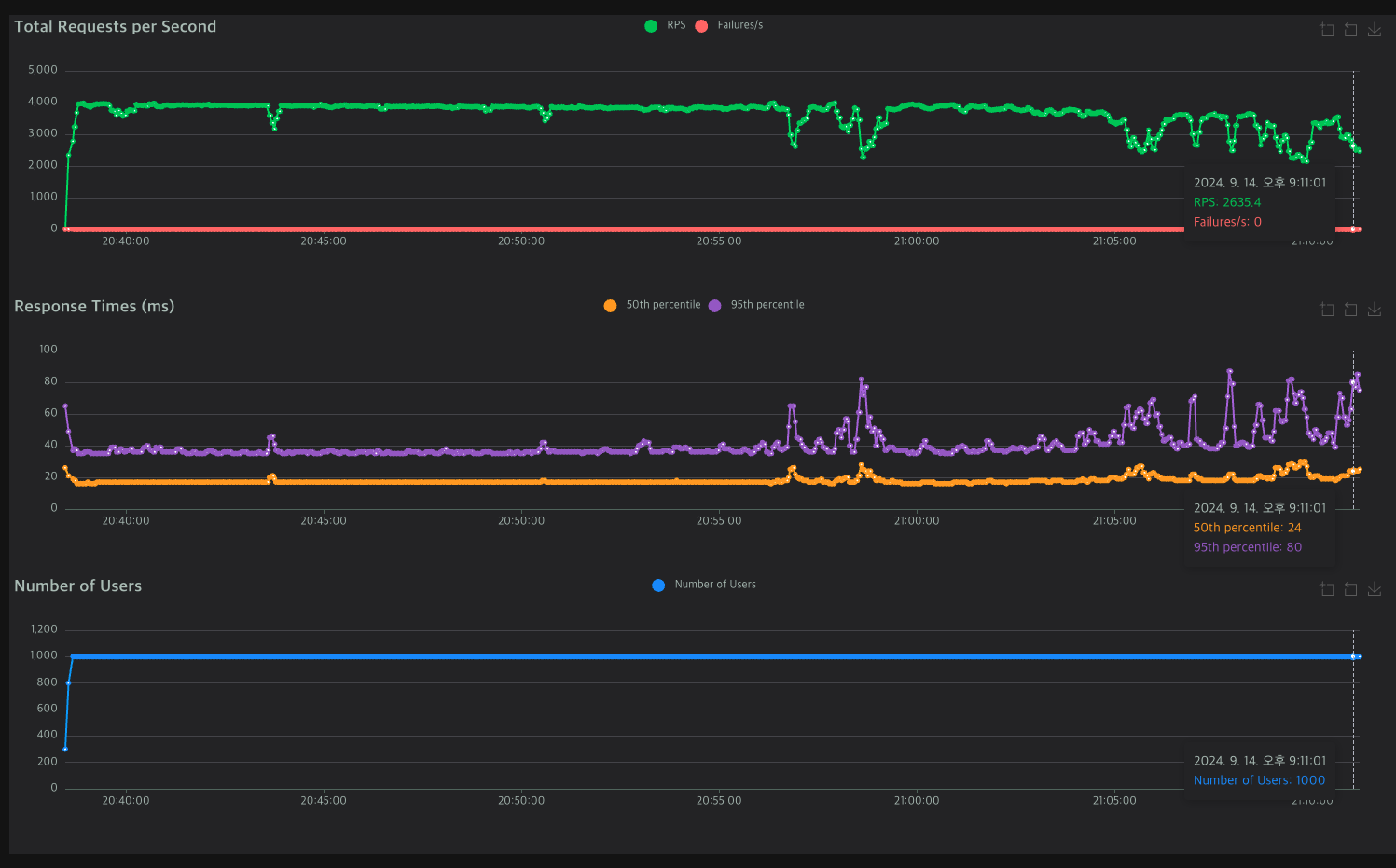
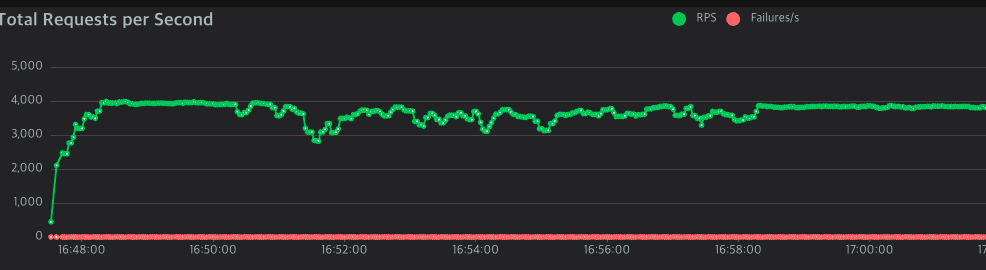
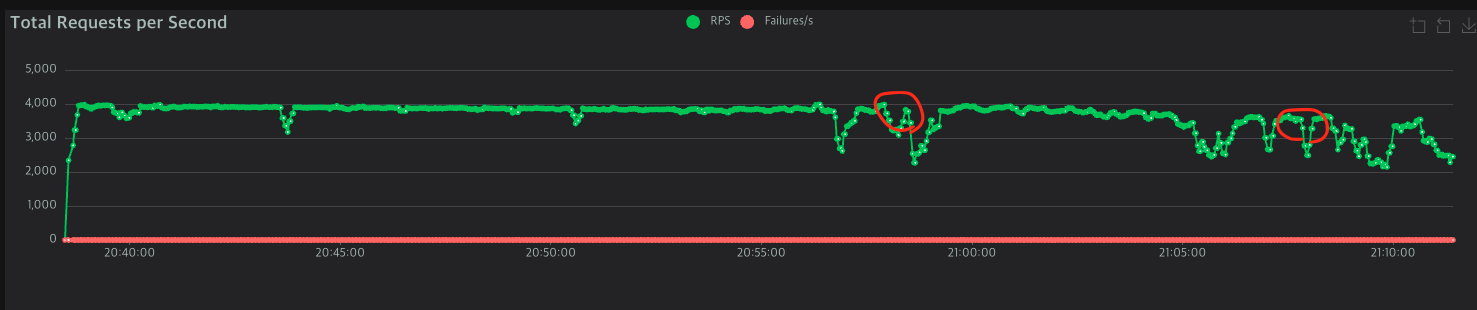
먼저 Locust 데이터이다.
처음 시작 38분부터 57분까지 거의 20분동안 최대 퍼포먼스를 냈다.
이후 8:56:43, 8:58:34에 크게 성능이 떨어지고 그 뒤에는 한참 좋은 퍼포먼스를 낸다.
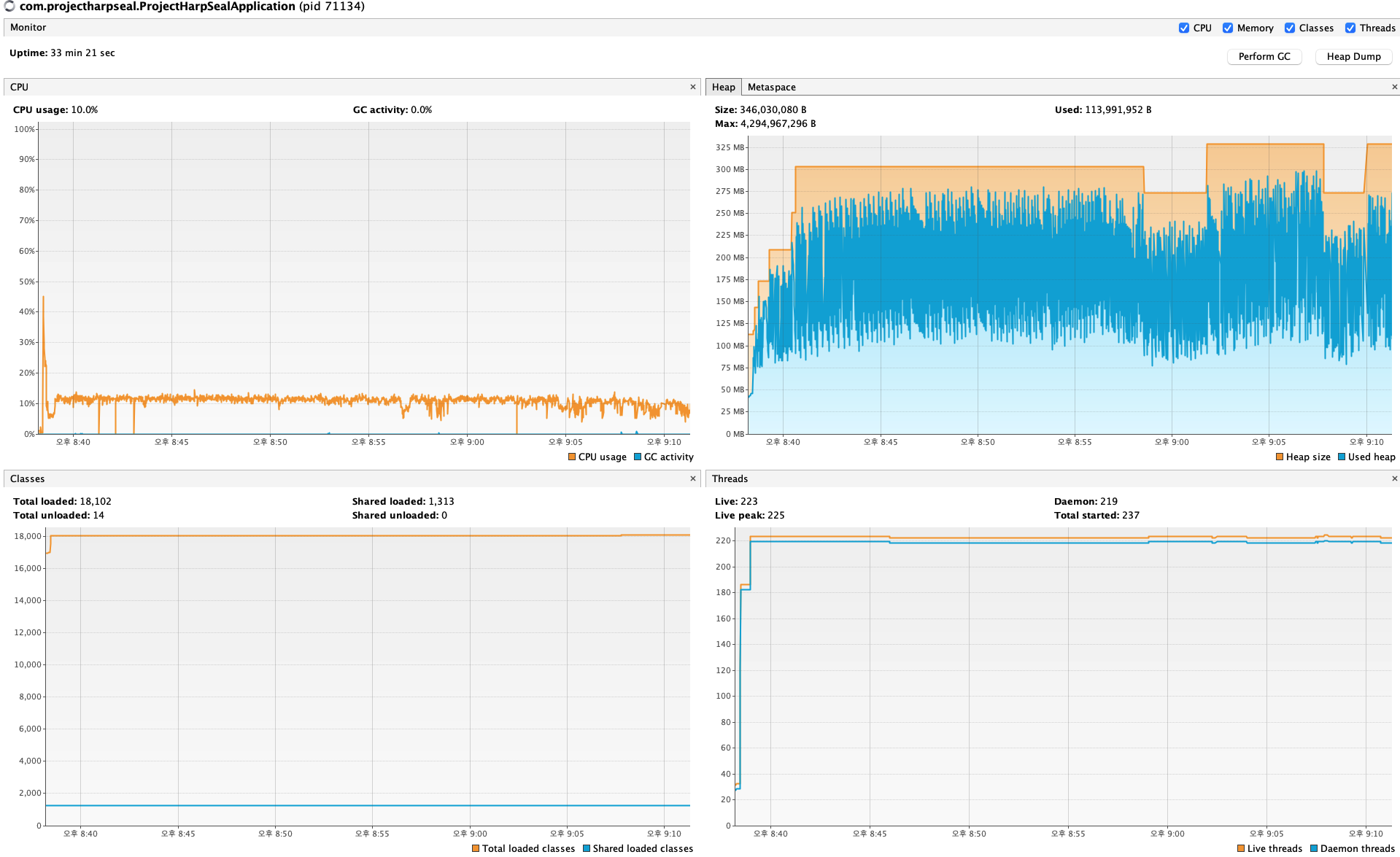
이것은 Visual VM으로 측정한 Heap 메모리 데이터이다.
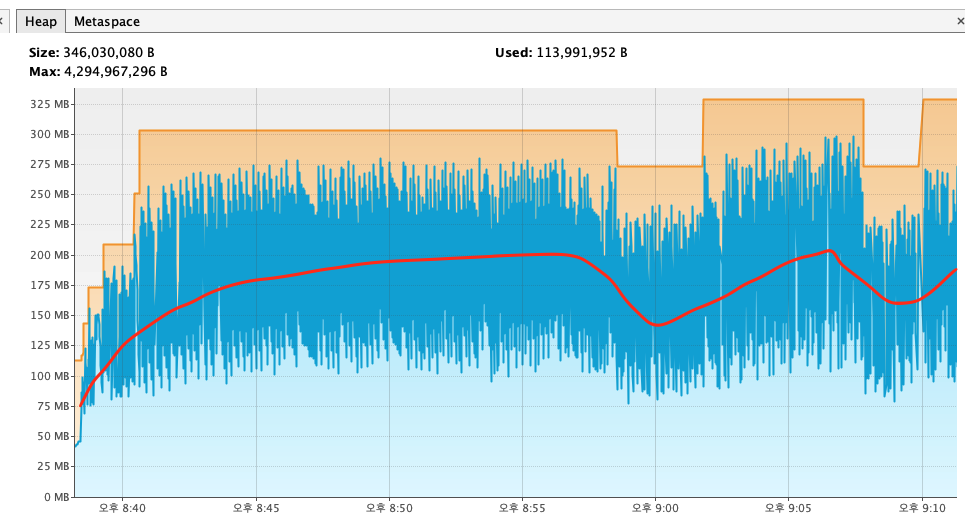
자세히 보면, Heap 메모리의 평균이 증가했다 줄었다 하는것을 볼 수 있다.
2군데 줄어든 구간이 있는데, 8:58:34, 9:07:50에 가비지 컬렉터를 강제로 실행시켰다.
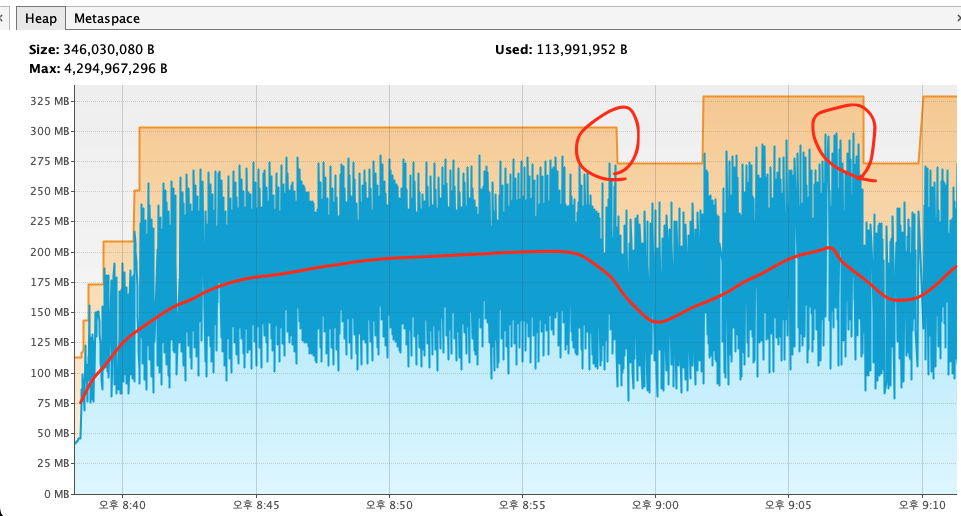
그 두 구간이 빨간 동그라미를 친 두구간이다.
그리고 빨간 동그라미 친 이 두구간이다.
첫번째 구간에서는 가비지컬렉터가 일을 한다고 스레드를 데려가서 순간적으로 퍼포먼스가 떨어지지만,
그래도 이후 일정한 성능을 보인다. 하지만 서서히 빌빌거리다 퍼포먼스가 작살나버리고,
가비지컬렉터로 두번째 청소를 했음에도 RPS가 박살나는 모습을 보인다.
이때 재밌는것을 발견했는데,
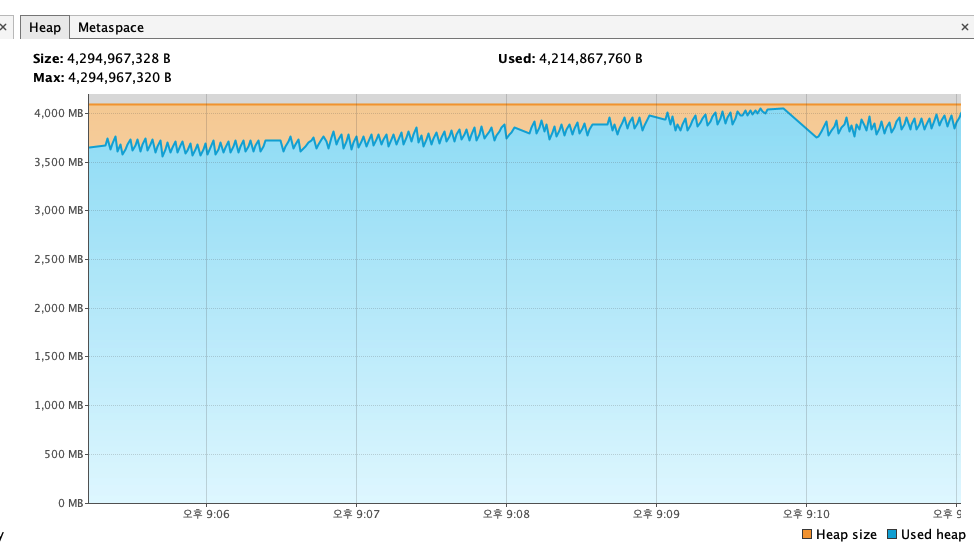
이건 intellij의 heap메모리 사용량이다.
서버를 껐다 다시 켰을때는 메모리가 부족하니 heap 용량을 늘리라는 말까지 나왔으며
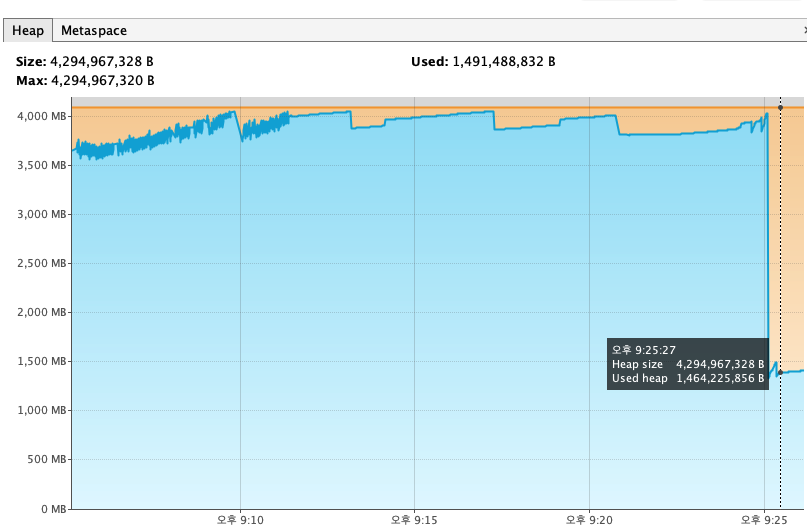
이게 처음 시작할때의 intellij의 heap 메모리 이다.
즉, 어디선가 메모리가 질질 새서 누수가 발생한다는 것이다.
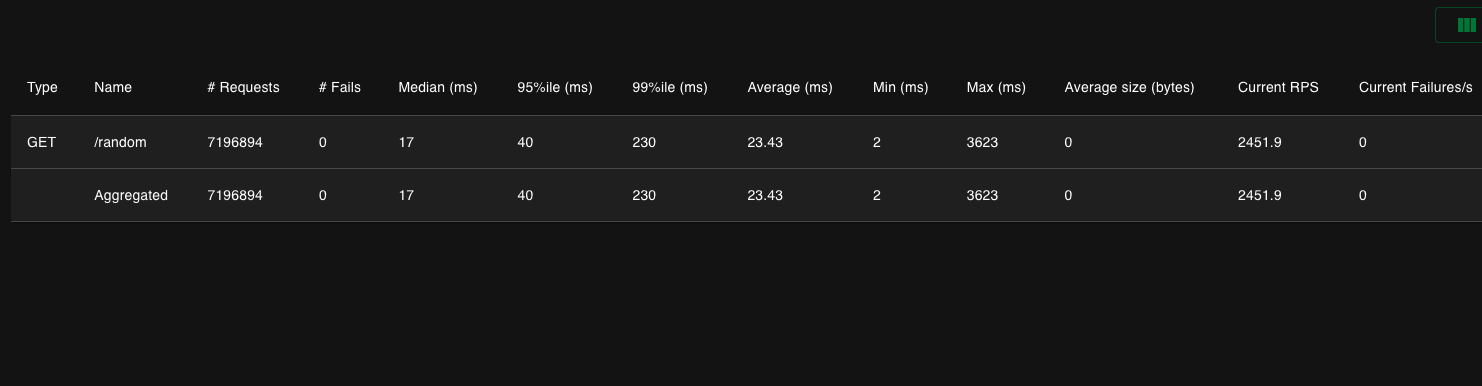
이것은 Locust의 테스트 결과이다.
총 약 720만번의 Request를 보냈으며, 평균 23ms의 반응을, 중위 17ms의 반응을 보였다는 것이다.

Max 수치는 후반으로 갈수록 반응속도가 개판이 나서 하위 반응이 개판났는데, 이러한 결과값은 위의 데이터와 함께 생각하면 쉽게 답을 낼 수 있다. Heap 메모리가 계속 쌓여 요청을 재때 처리하지 못하는 것이다. 자세한 이유는.. 조금 더 공부해야 겠지만 스레드가 heap에 데이터를 쌓지 못하고, 가비지 컬렉터가 메모리를 확보하기 위해 많은 자원을 끌어다 쓴다던가 등등의 다양한 이유가 있을 것이다.
그렇다면 왜 heap 메모리가 계속 증가하는 것일까?
이 heap 메모리가 어떤것인지 정확하게 파악하기 위해, VisualGC plugin을 인스톨했다.
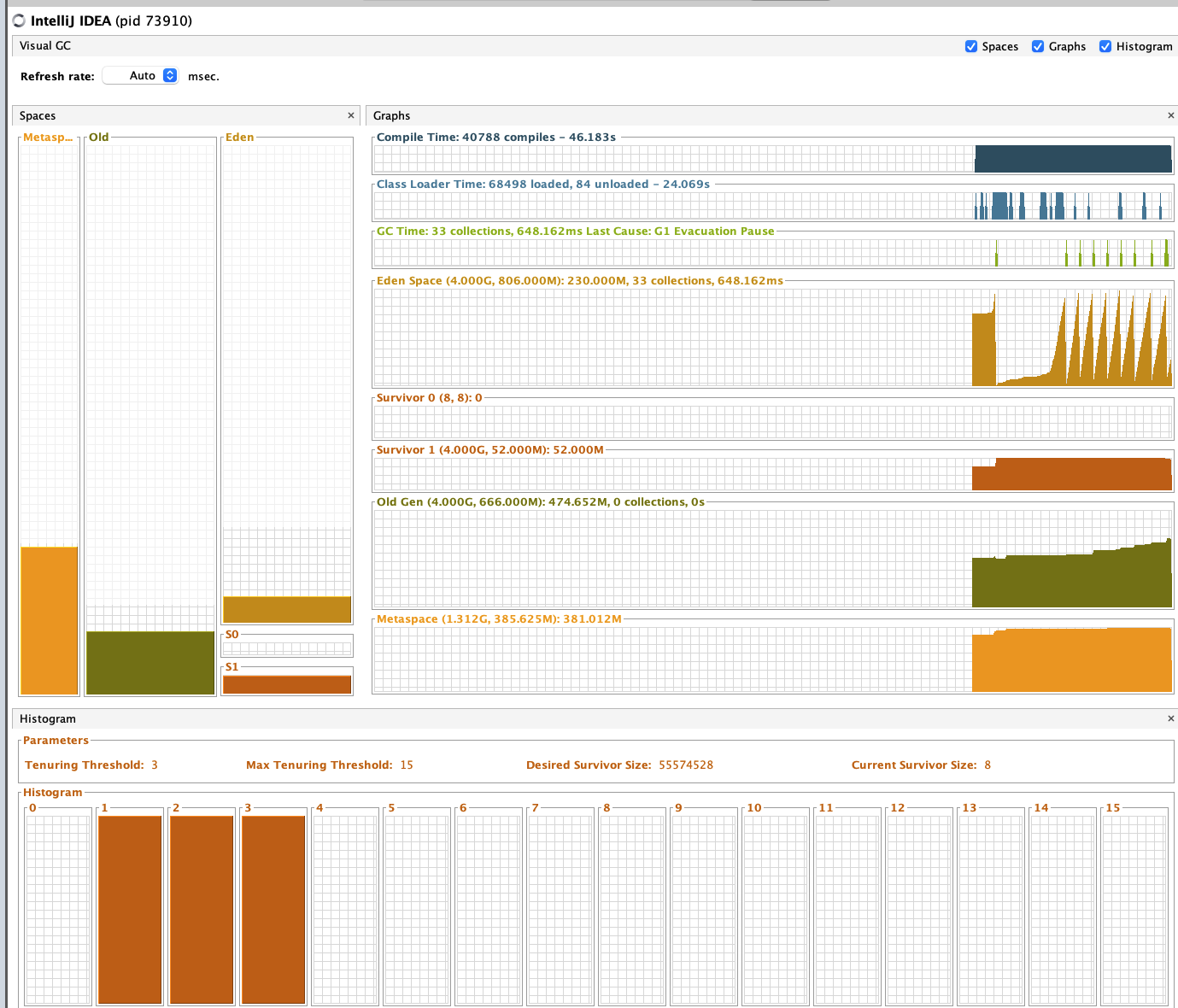
초기 intellij GC
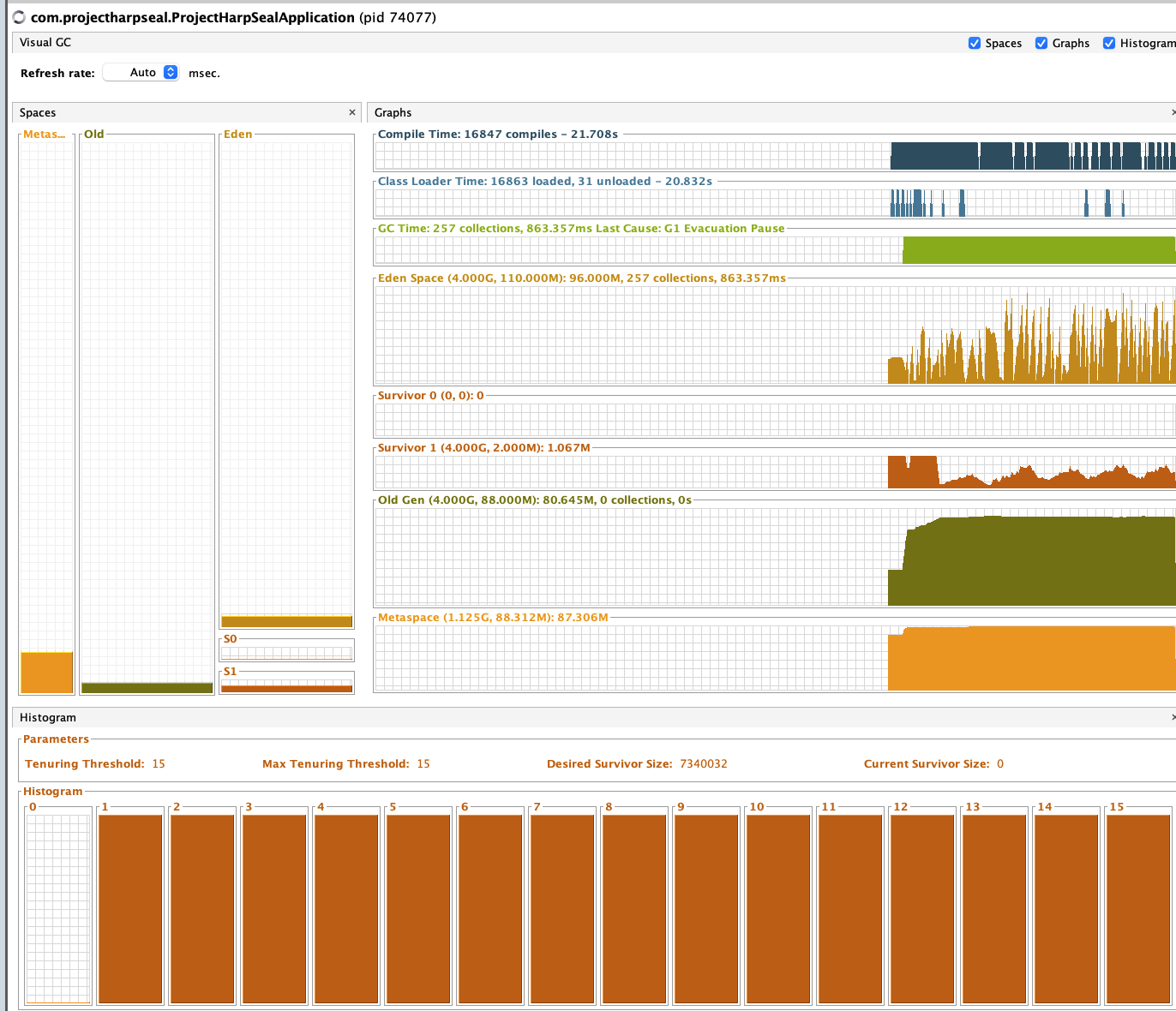
초기 Project Gc
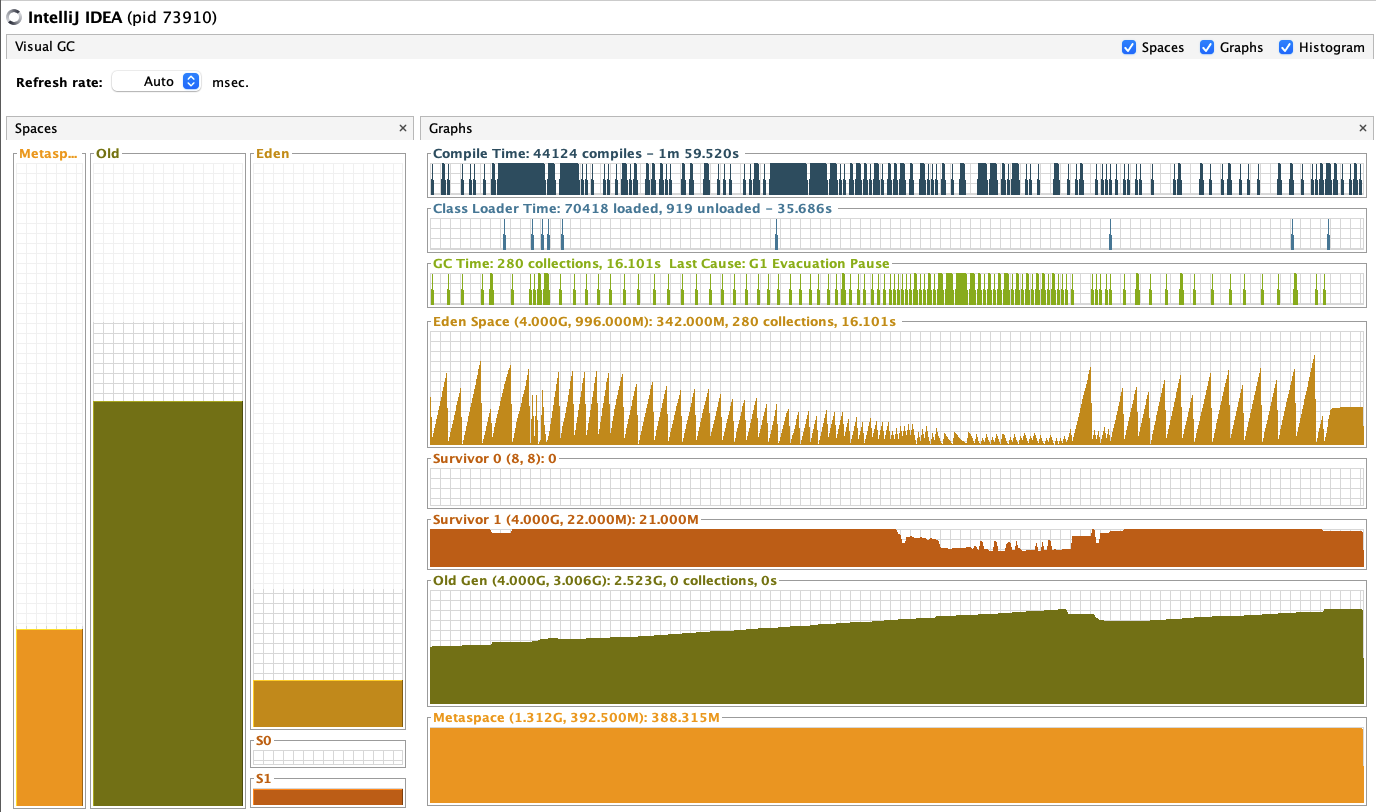
테스트 후 intellij GC
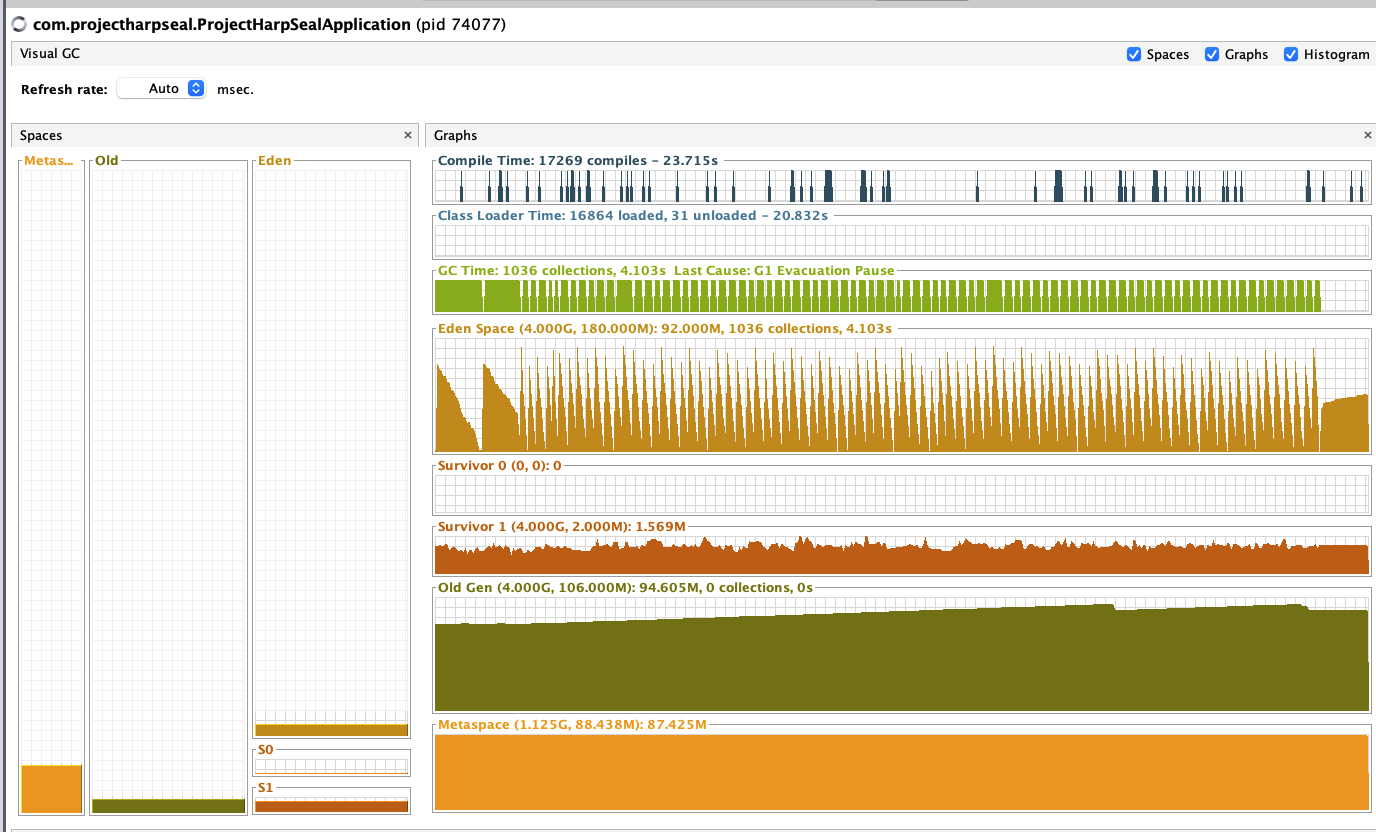
테스트 후 Project GC
프로젝트는 heap이 안쌓였는데, intellij에 old gen이 감당안될만큼 쌓이는걸 확인할 수 있다.
그래서, 여기에 테스트를 한번 더 해볼것이다.
정말 로직때문에 Heap메모리가 쌓이는것일까?
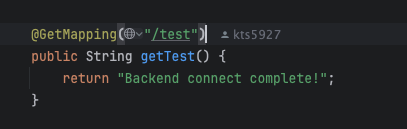
따라서 어떠한 로직도 없이 단순히 String값만 리턴하는 API를 통해 테스트를 해볼 것이다.
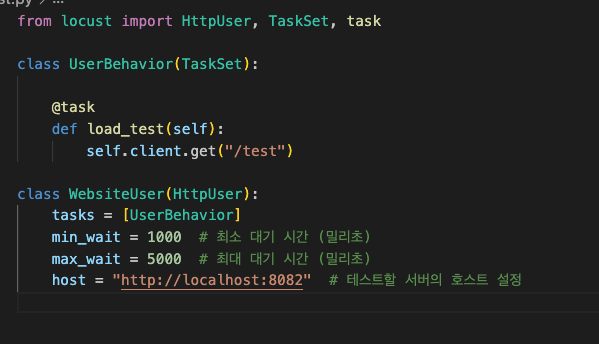
url을 바꾸고 user1000으로 동일한 환경에서 테스트를 진행하였다.
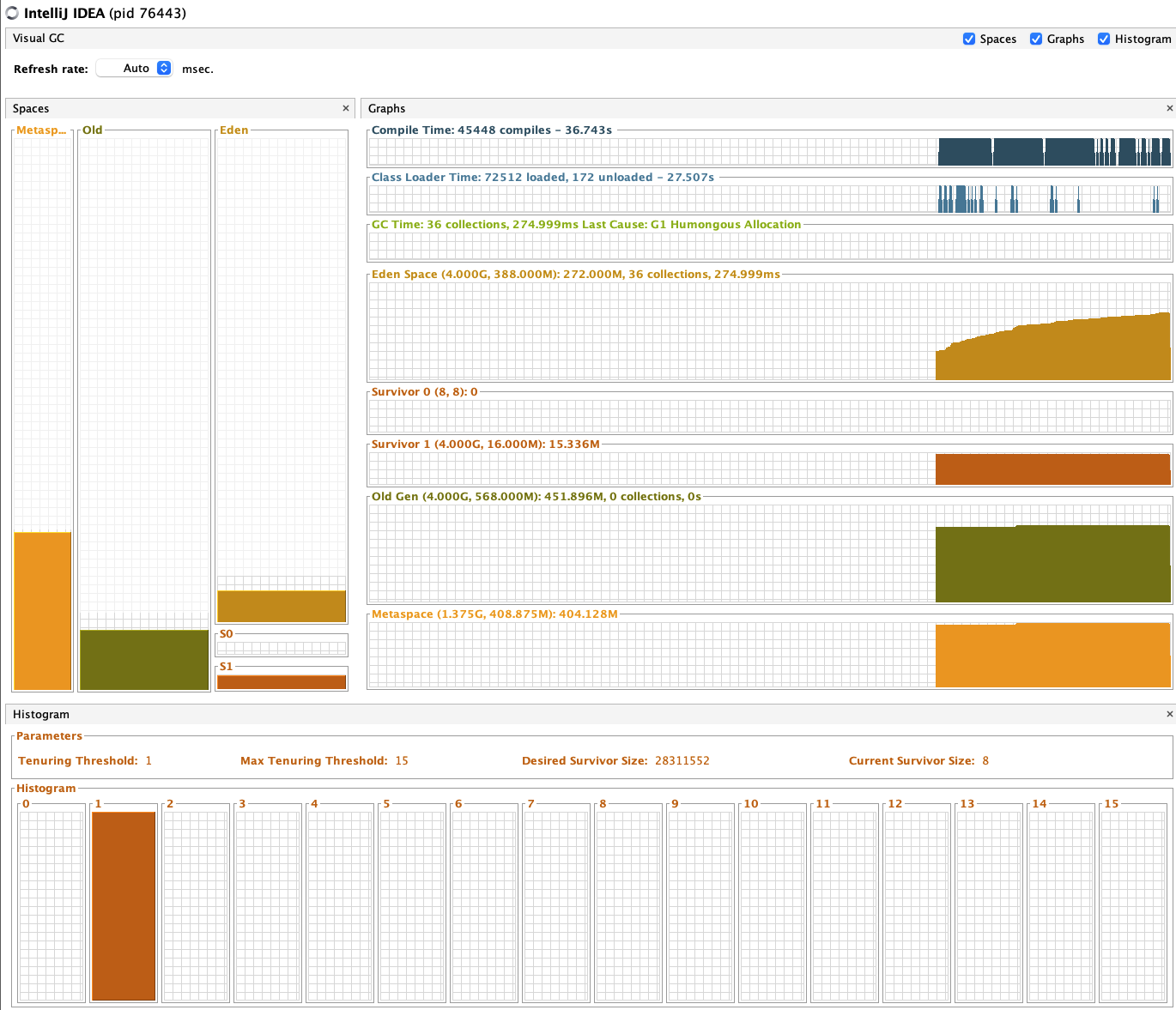

RPS는 4500을 넘었지만, 여전히 Old Heap은 증가하지 않는 상황.
따라서 로직을 통과하는 도중 메모리 누수가 발생한다는 결론을 내릴 수 있다.

Heap 메모리를 한참 모니터링 한 끝에, 이 JPA 구문이 메모리 누수를 일으킨다는것을 알아냈다.
이때 객체의 영속성이니 뭐니 하는 글을 봤어서 .clean()을 사용해봤지만 소용없었다.(알고쓰자 좀!)
그래서 Visual VM에서 HeapDump라는걸 찍어봤다.(있는지도 몰랐는데 우연히 알게되었음..)
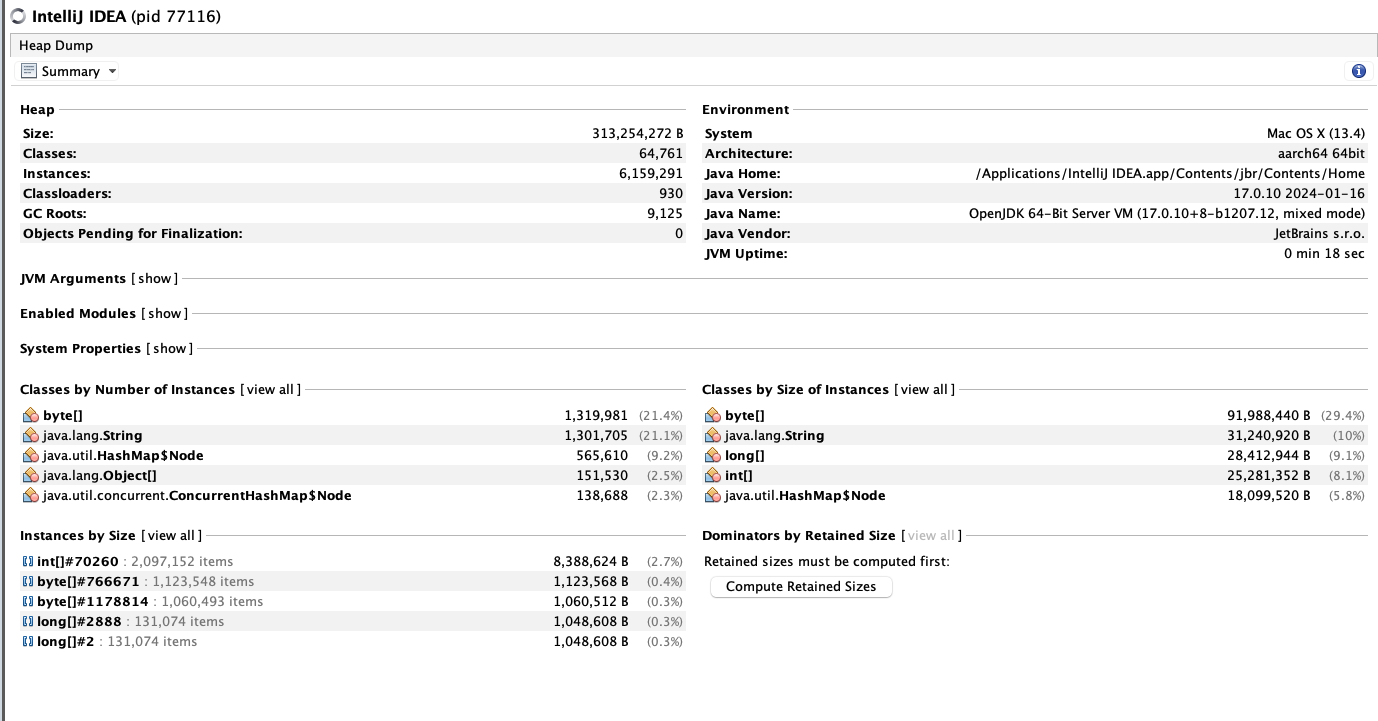
이건 시작할때의 Heap이고
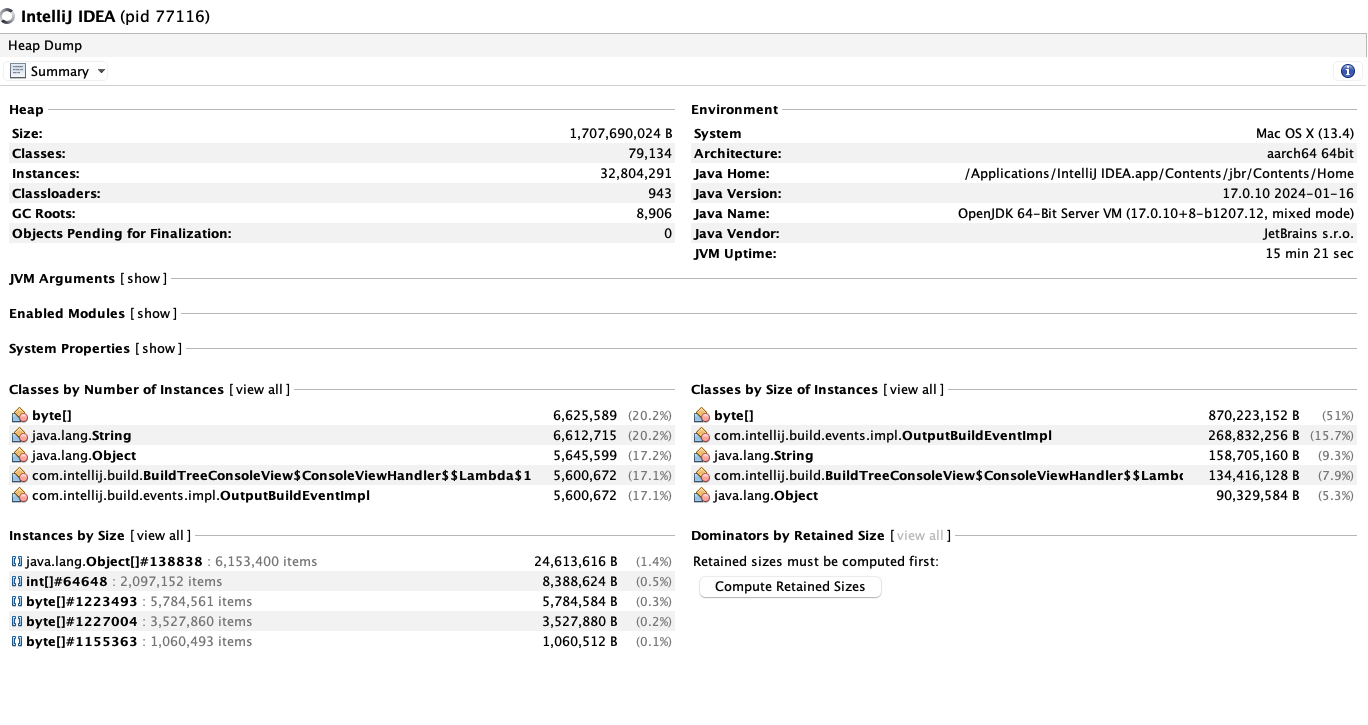
이건 터지기 직전의 메모리 이다.
잘 보면 Byte, String, Object, BuildTree 등 다양한 인스턴스들의 숫자가 늘었고,
인스턴스 크기들이 엄청나게 크고, java.lang.Object[]#138838 인스턴스의 크기가 장난아니게 커진걸 볼 수 있다.
아니 근데 인스턴스의 이름을 보니 무슨 build event Impl, view handler, string 등등
내가 쓰지도 않은것들의 이름이 잔뜩 나와있다.

진짜 이표정으로 하루종일 검색하면서 고민했다.
그러다가 갑자기 내 눈에 들어온게 있었는데..
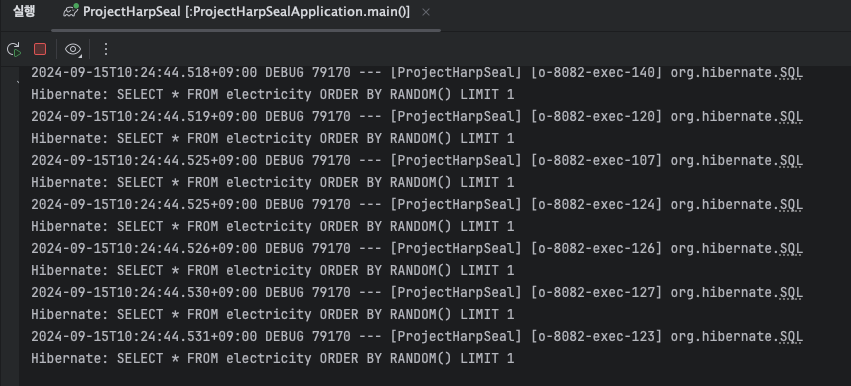
바로 미친듯이 올라가는 로그였다.
로그를 보면서 멍때리다가 순간적으로 든 생각은
이놈들 다 서버에 기록되고있는거아님? 이었다.
Intellij 같은 IDEA에는 유저가 적은 명령어를 저장하는 기능이 있다.
하지만 만약에
Hibernate에서 뜨는 로그가 저장되는게 Limit이없다면? 이라는 생각이 들었다.
그런데 이 로그들을 제한없이 서버에 쌓이게 놔두는게 맞나 싶었는데
다시한번 생각을 잘 해보니
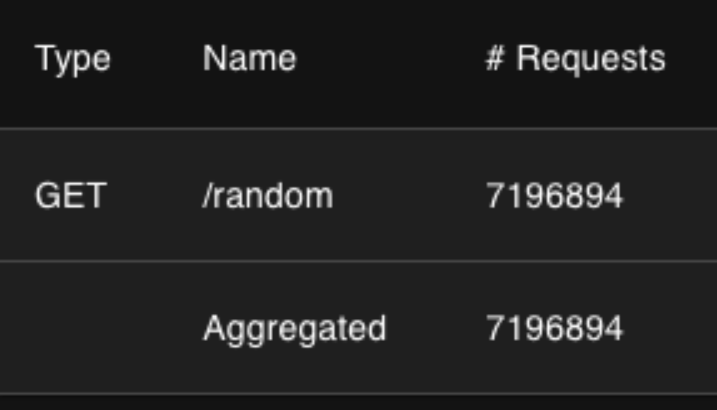
개인용 맥북으로 Request를 1000만번 단위로 보내는 미친짓을 왜 하겠는가?
그래서 내 파일의 Properties를 확인해봤고
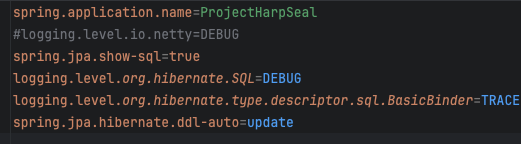
뭣도모르고 디버깅하겠다고 다 찍어놓았다.
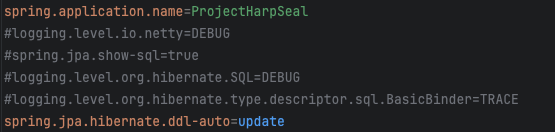
이제 이걸로 테스트를 해봤다.
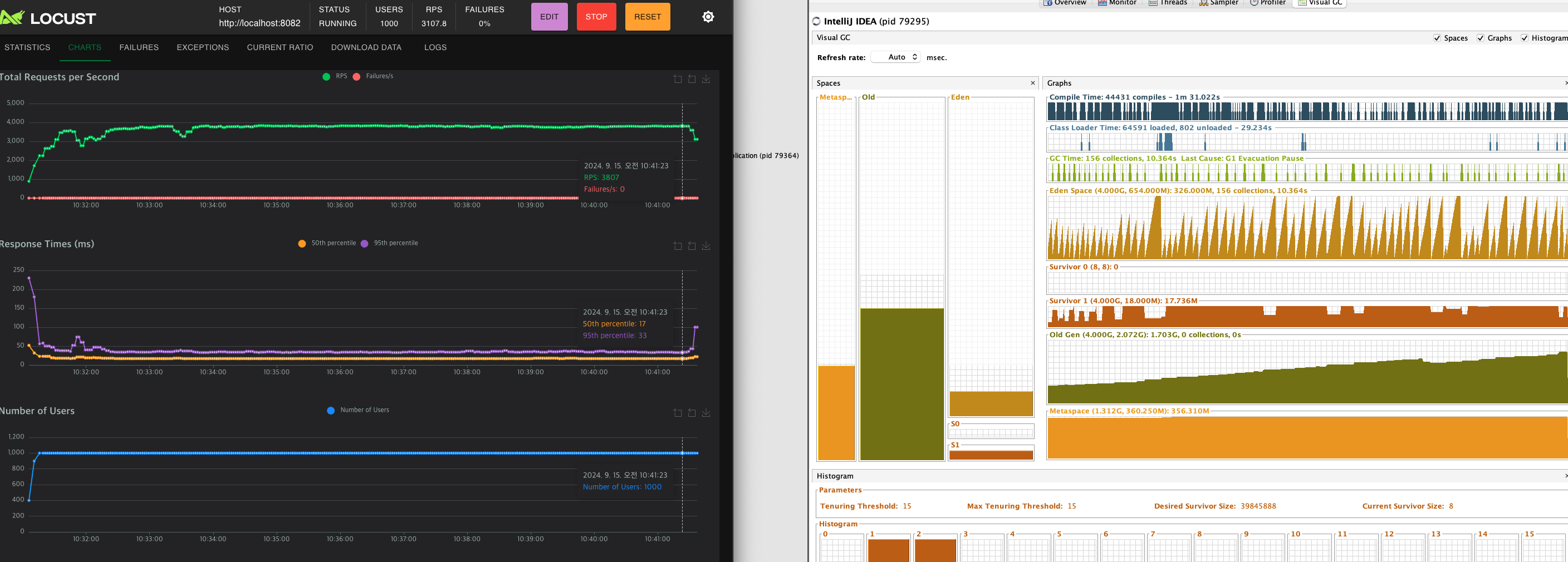
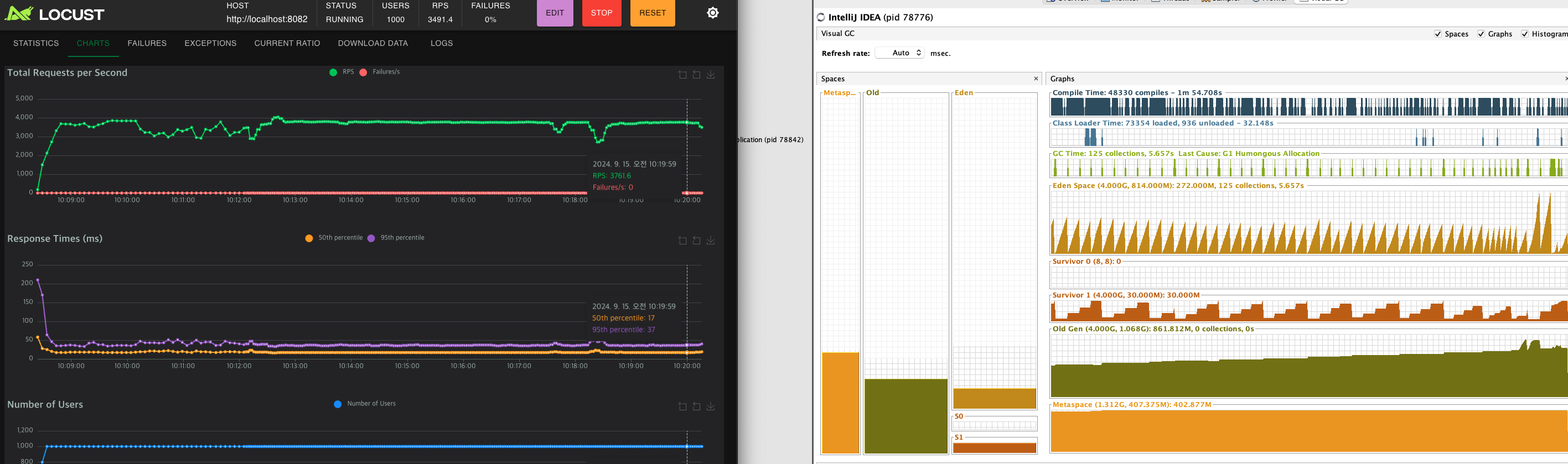
(테스트 돌리다 다른짓 하면 RPS가 흔들린다..)
비슷한 시간동안 테스트를 돌렸고,
위는 디버깅 로그를 전부 찍었을때,
아래는 디버깅 로그를 전부 뺐을때의 Heap 메모리 용량이다.
이로써 결론이 나왔다.
Hibernate의 로그들은 지워지지 않고 전부 서버에 남는다.
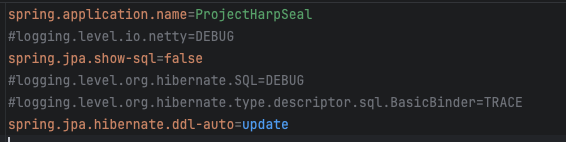
그래서 log를 false로 설정하고
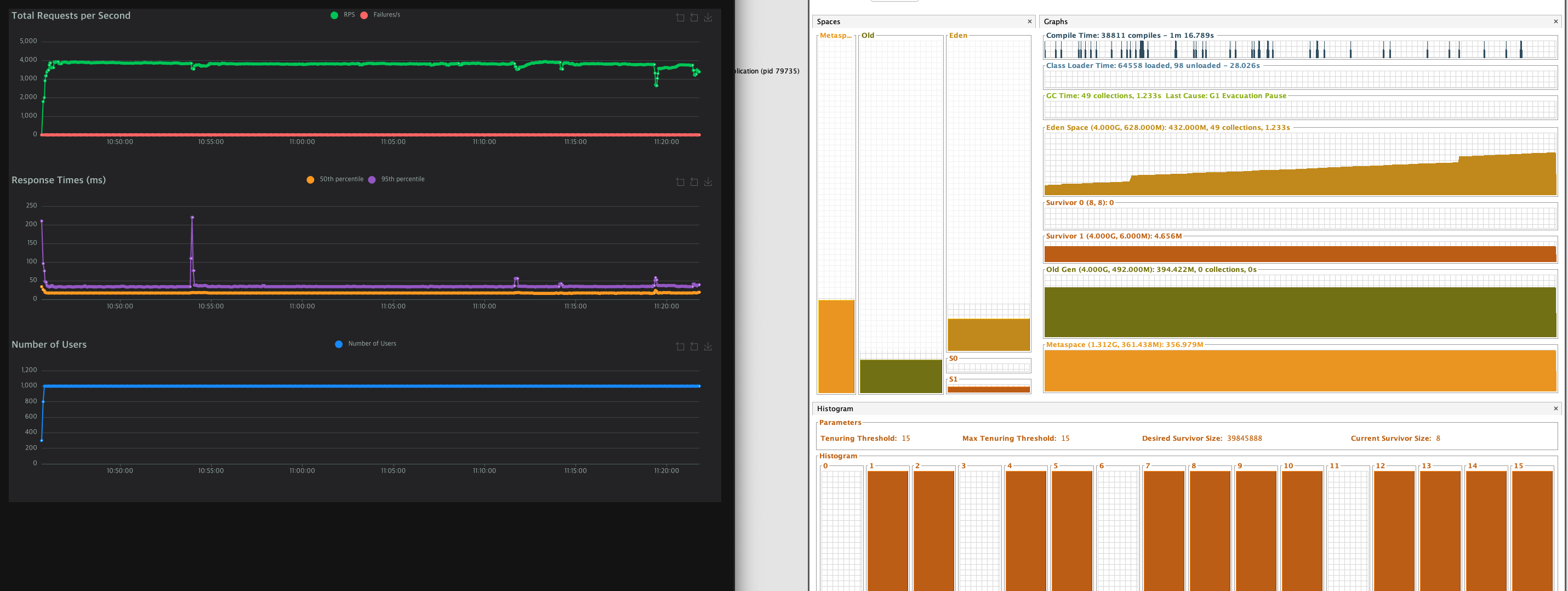
약 30분간 테스트를 했음에도 Old Heap이 증가하지 않는다.
비로소 메모리를 잡을수 있게 되었다..!
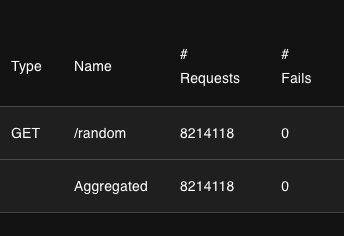
820만건의 데이터 요청을 보냈음에도, 서버가 잘 작동하는 모습이다.
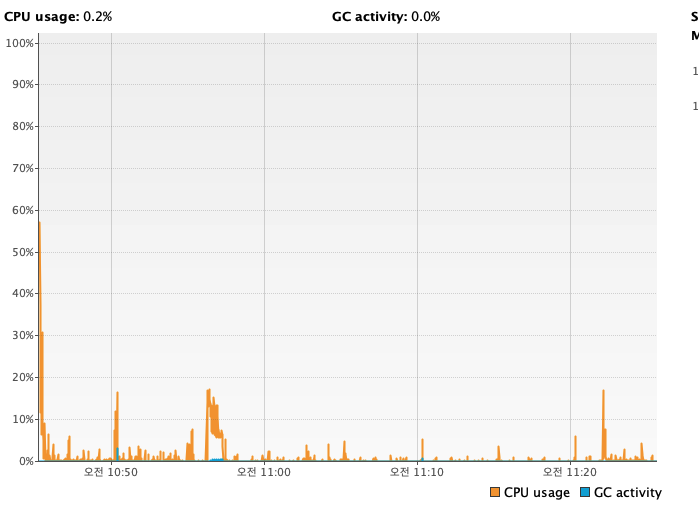
그리고 서버 성능도 눈에 띄게 올라간 모습이 보인다!
최적화 2-2 로그 기록경로 설정
근데 한가지 문제가 발생한다.

님 그럼 log는 그냥 기록안하시게요?
올바른 말이다.
서버를 장기간 운영하려면 어디에서 뭘 했고, 서버를 운영할때 Client에게 문제가 발생하면
그 문제 상황을 정확하게 파악하기 위해 Log는 꼭 필요하다.
그래서 어떻게 할거냐면
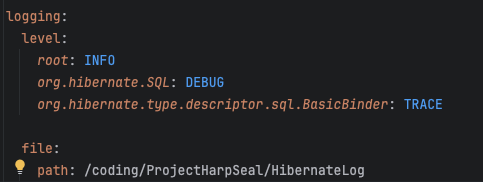
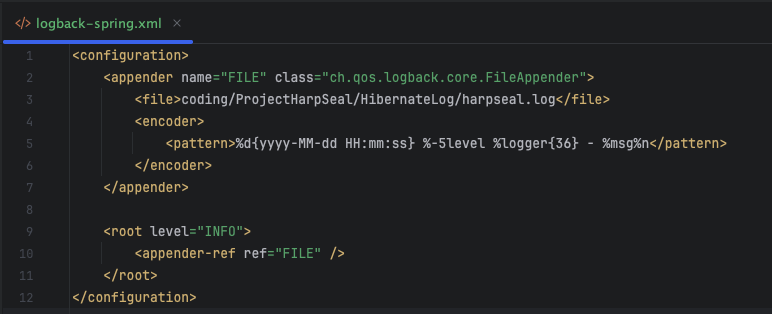
(자세한건 logback을 검색하자)
resource에 xml파일과 yml 설정을 해준다.
이는 서버의 로그들이 특정 경로에 text 파일로 저장되도록 도와준다.
이후 실행하면 위와 같은 오류가 발생하는데,
종속성 겹친다고 주의주는 것이다.
build.grale에 위와 같은 설정을 추가해주면 없어진다.
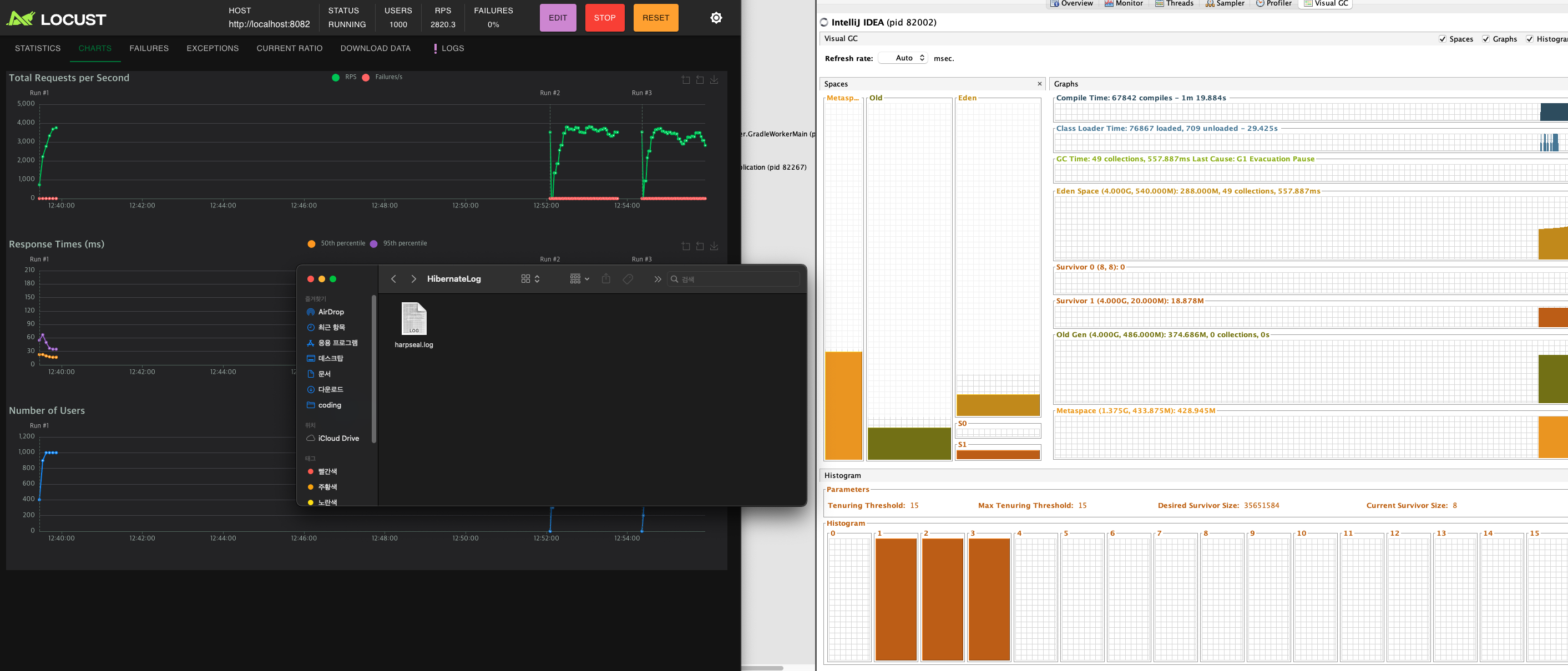
이제 로그는 찍히지 않고, 외부 text 파일에 기록된다!
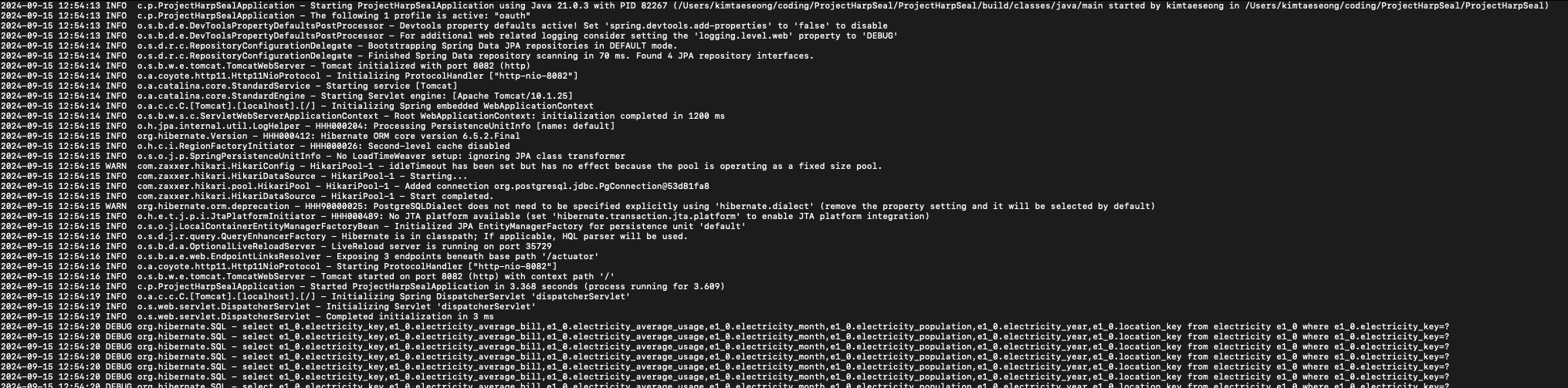
서버 실행시 발생하는 로그까지 싹다 적혀있는 모습.
엄청난 데이터를 보면 세삼 내가 얼마나 과부하를 주고 있는지 체감하게 된다.
최적화 성과
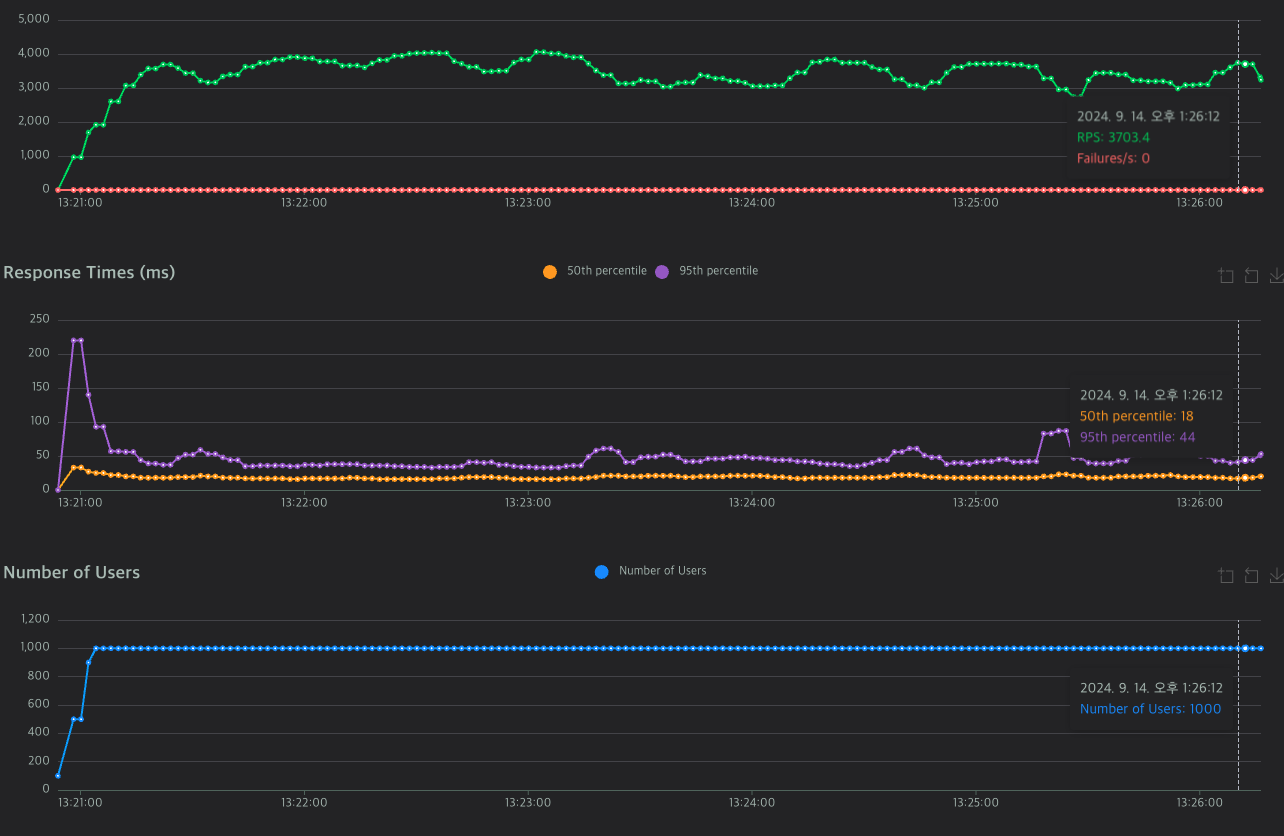
이랬던거를
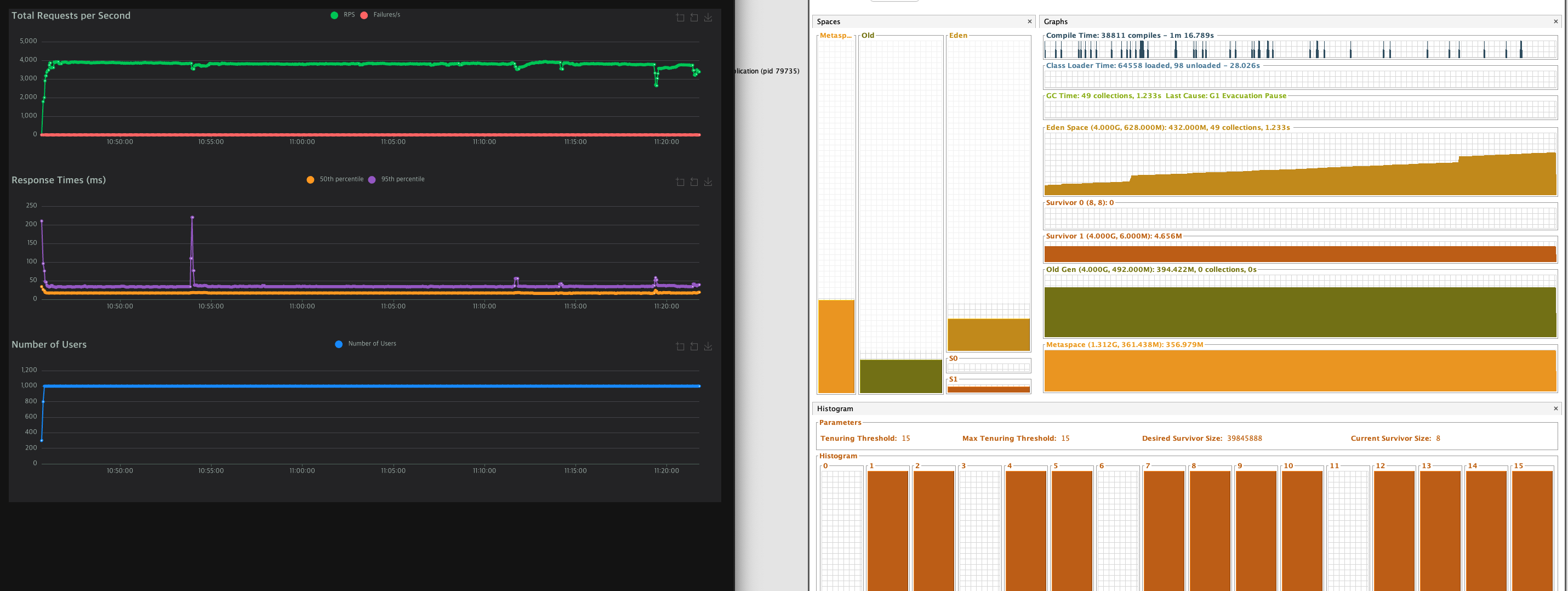
이렇게 최적화 시켰다.
