
리팩토링 끝나고 인터넷 검색을 하다가 배민 우아콘 영상을 봤다.
레퍼런스 : https://www.youtube.com/watch?v=pRpryoQphXQ

우아한 형제들 배민스토어 팀에서 WebFlux를 도입했다는 걸 발표하는건데,
갑자기 흥미가 생겼다.
- 나도 WebFlux를 활용해서 API 호출 코드를 만들었음.
- WebFlux에 대해 깊게 공부하지 않음.
- 대형 서비스사에서 사용하는데 그만한 효과가 있을까?
위와 같은 호기심으로 인해서 영상의 내용을 정리하고, WebFlux의 개념과 사용법 등을 자세하게 공부해 보자.
우아콘
작년 말에 나온 '최신기술 한방에 때려넣기'에 나온 내용에 대한 요약이다.
EDA와 아키텍쳐
EDA 도입배경
- CRUD 중 Read가 많이 있으며, 데이터 반환에 매우 많은 정보가 필요했음.
- 여러 플랫폼에 데이터가 노출할때 각각 시스템 응답에 따라 대기시간이 오래 걸리는 경우 응답시간이 길어질 수 있음.
- 그래서 배민스토어 = 느린 서비스 라는 인식을 줄 수 있음.
- 따라서 EDA를 도입하여 안정적이고, 빠른 서비스로 개편할 수 있는 계획을 함.
Event - Driven - Architecture
이벤트를 기반으로 통신하고, 서로의 동작을 야기하는 소프트웨어 설계 패턴이다.
이벤트란?
- 발생한 있는 사실 그 자체
- 변경이 불가능하다.(ex/ 상품주문, 상품을 장바구니에 넣음 등등)
EDA의 특징
- 시스템 간에 느슨하게 결합됨
- 확장성이 좋음
- 도메인에 특화된 데이터 모델을 편리하게 구성
- 아키텍쳐 구성시 난이도가 높음
이후 내용
- 이벤트를 활용하기 위해 여러방면으로 분석함
- 너무 많은 도메인들이 엮여서 어떤 방식을 사용할지 이벤트를 연동하며 확인해봄
- 이벤트가 도메인별로 크기가 다르고,각각에 특화된 데이터모델로 재정의한다.
- 따라서 RDB -> NoSQL로 전환
- 빠른 응답시간 확보 가능!
레퍼런스 : https://oliveyoung.tech/blog/2023-01-04/oliveyoung-discovery-mongodb/
올리브영 테크블로그인데, 이쪽도 빠른 응답을 위해서 MongoDB 도입을 했다고 함.
이후의 내용은 너무나 많은 이벤트들로 인해서 힘든점, 어떻게 나아질수있을까에 대한 고민.
- DLT
- 서킷브레이커
- 지속적인 최적화
라고 한다.(DLT와 서킷브레이커는 처음 듣지만 지금 알아볼 내용은 아니니 패스)
전반부 아키텍처에 대한 요약을 하면 이렇게 될 것이다.
- 플랫폼이 너무 많아서 느린 서비스가 될것이다.
- 그래서 EDA(이벤트 기반 아키텍처)를 도입함
- DB도 NoSQL로 바꿨다(DynamoDB, Redis).
여기서 이벤트 기반 아키텍처에서 사용하는 스택은 WebFlux로 보이는데(영상 후반부는 WebFlux, Kotlin 설명), WebFlux는 Non-Blocking 비동기 처리를 한다. 그렇다면 우리는 여기서 알 수 있는게
- WebFlux를 사용하면 여러 플랫폼에서 각각 작업시간이 오래 걸릴때 전체시간을 줄일 수 있다.(각 작업시간의 max()값으로 처리 가능)
- 특정 딜레이가 심해지면 이벤트가 밀리는 경우도 생각해야됨
- 특정 Key값을 가진 데이터는 NoSQL이 엄청 빠르다.(배민 개발자가 영상에서 한 말)
- 적당한 개발 기간이 필요하고 신기술이 다 좋은건 아니다.(상당히 고생하셨나봄)
- 유연하게 생각해야 한다.
가 되겠다.
여기까지 왔을때의 내 생각은
피크시간대에 사람이 얼마나 몰리고, 각 요청의 복잡도는 어느정도가 되며, 이벤트 큐가 어느정도의 요청을 감당할 수 있는지를 알아내는게 정말 중요하다는 것이다. 괜히 모든 공고마다 '대규모 트래픽 처리 경험'을 써붙이는지 절실하게 알 수 있었다.

여기서 머리가 좀 아파지는게 뭐냐면 이때까지의 프로젝트는 기능 구현보다는 각 스택이 어떻게 작동하고, 왜 내가 이걸 공부해야되는지에 맞춰져서 코딩보다는 공부에 가까운 느낌이었다.
또한 알고리즘이니 뭐니 다른것도 병행하면서 프로젝트의 진행속도가 많이 느리다고 생각했는데, 그 증거로 6월 중순에 시작한 프로젝트가 이제와서 API 호출메서드 하나 만들었으니 말이다.
근데 그렇다고 코딩에만 집중할 수도 없는 노릇이, 개발자로서 제일 기피해야 할 것이 그냥 좋아보여서 썼다 라고 생각한다. 적어도 그 프레임워크가 어떻게 작동하는지, 왜 이렇게 쓰이는지 알아야 하는데 그런것들을 공부하다 보면 프로젝트 진행이 느려지고.. 악순환의 반복이다.
그리고 코딩을 했다고 치더라도 대규모 트래픽을 내가 얻을 수 없다는것 또한 문제이다.
이전에 팀원이 말했던게 생각난다.
'Local과 배포환경은 다르고, Locust 같은 툴을 사용하는것과 실제 Client가 몰리는거랑은 상황이 또 다르다.'
그렇다면 내가 사이트를 만든다고 하더라도, 테스트 툴을 돌린다고 하더라도
면접에 가서 이러한 역량이 있다고 어필할 수 있을까? 에 대한 의문점도 남는다.
레퍼런스 : https://www.youtube.com/watch?v=b4Ro_2cK9V8
위 영상의 경우는 실전경험을 중요하게 보는거 같다고 한다.
결국 신입은 어치피 못하는걸 알기 때문에 문제해결에 대한 역량을 본다는 것이다.
이 외 다른 영상들을 보면 대용량은 상관없고 본인만의 서버를 만들어라는 영상도 있다.
아키텍처에 대한 영상을 보니 기술적인 부분보다는 이런 고민거리가 늘어나는거 같다. 어떻게든 효율적인 코드를 짜야하고, 튼튼한 시스템을 짜야 하니까.
참 골치아픈 주제이다. 각 메서드마다 지연 1초씩 걸어놓고, 그 메서드들을 비동기 처리로 빠르게 끝냈다고 해서, '대규모 처리와 비슷한 환경에서 성능을 최적화하였습니다' 와 같은 양심없는 말을 할 자신은 없다.
아직은 코딩과 프레임워크 공부 중에서 어느것을 우선시 해야할지 감을 못잡겠다..
WebFlux
진입장벽
- 패러다임을 바꿔야 한다.
- Project Reactor의 러닝커브가 높다.
기존 MVC 패턴과 많이 다른 기술이고, 연산자의 조합을 어떻게 해야할지 많은 고민이 필요했다. 그래서 점진적으로 도입해야되나? 했지만 전시 API쪽을 일단 도입했음.(부분 도입)
도입을 잘 했는지에 대한 질문
성능/효율성에서 이득을 봤나?
- 눈에 보이는 성과는 있음.(레이턴시 감소)
- 병렬 호출도 가능해짐.
- 하지만 변인이 통제된 데이터를 못만들고, 많은 개선요소를 한꺼번에 적용할 수 밖에 없었고, 테스트할 시간이 없었음.
비즈니스 로직을 손쉽게 작성할 수 있었나?
- Batch성 로직은 그렇다
- API로직은 모르겠다
러닝커브가 심했나?
- 충분히 고민할만한 여유가 없었음.
- 코드의 품질도 많이 떨어졌다. 공부해도 기간이 짧아서 어쩔수없음.
이후 Kotlin에 대해서도 말하다 이후 방향성을 말함.
결론
- 신기술을 한꺼번에 도입하는것? 좋긴한데 많은 사항을 고려하라.
- 그렇다고 점진적 도입 또한 무조건 좋은게 아니다. 서로의 장단점이 있다.
전체적으로 공감도 가고(러닝커브 등), 배울점도 많았다.
항상 나오는 말은 많은 사항을 고려하라는 것이었고,
어떤점이 좋아졌는지, 어떤점은 나쁜지 확인하기 힘든 부분도 있다는 것이다.
레퍼런스 : https://en.wikipedia.org/wiki/Batch_processing
Batch란 무엇인가를 보면
- Computerized batch processing is a method of running software programs called jobs in batches automatically
이라고 나와있다.
소프트웨어의 실행이 원자적으로 일괄처리한다는 것을 말하는데,
- 사진 업로드시 워터마크 박아넣기
- 일정시간마다 모델을 업데이트 하는것
등의 예시가 있다고 한다.
그러니까 내가 넣으려는 기능 중 하나인
- 매주 상품 정보 업데이트
- 작년의 전기요금 업데이트
등의 작업이 Batch 작업이라 할 수 있겠다.
레퍼런스 : https://techblog.woowahan.com/2667/
이와 관련된 것이 배민 기술블로그에 정리되어 있다.
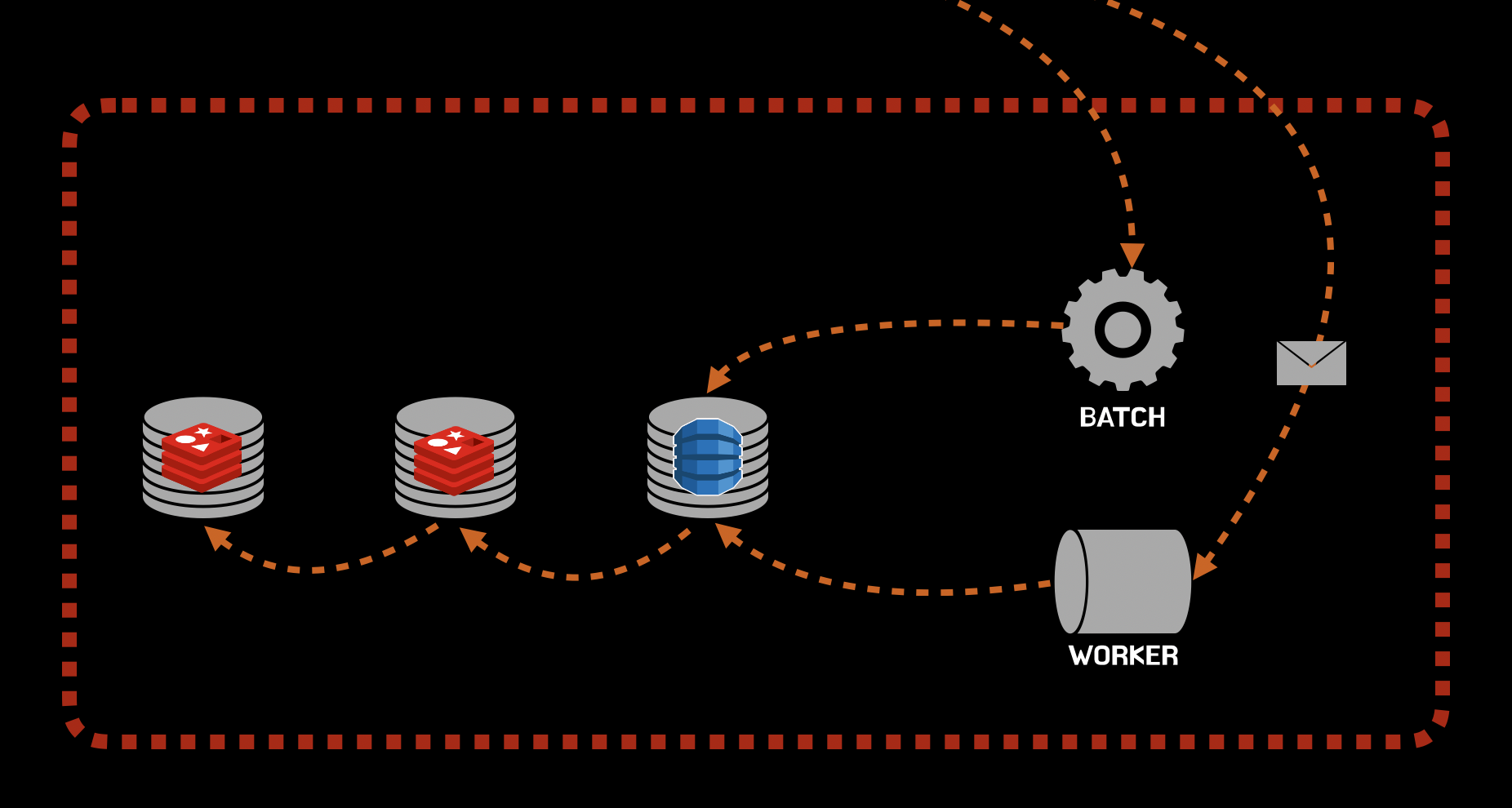
기업의 정보를 오픈할 수 없으니 상당히 추상적으로 설명을 했다.
우선 데이터 갱신을 할때, Batch 혹은 Worker에 업데이트를 한다.
위에서 알아봤던 내용 등을 고려했을때
- 특정 시간대나
- 특정량의 데이터가 쌓이거나
- 아니면 데이터가 업데이트 되었을때
Batch 혹은 Worker에 데이터가 업데이트 되고, 캐싱이 되는걸 짐작할 수 있다.
@Bean(STEP_NAME + "Writer")
@StepScope
public ItemWriter<CompositeProcessorResult<HistoryMeta<ShopResponse>, Shop>> dataItemWriter() {
return results -> {
List<Shop> items = results.stream()
.map(CompositeProcessorResult::getResult)
.collect(Collectors.toList());
try {
shopDataCommandService.batchUpdate(items)
.doOnError(throwable -> log.error("Shop Update 실패", throwable))
.block(); //here
} catch (Exception e) {
throw new IllegalStateException(e);
}
};
}
또한 코드에서도 기껏 Non-Block 스택을 씀에도 불구하고
.block()를 사용한다고 한다.
이를 지난 Nest.js와 PintOS 에서의 경험을 통해 이유를 짐작해보면
- 처리되지 않은 이벤트가 쌓이는걸 방지 및 데이터 병목지점 추적
- Error 발생유무 확인 후 catch 구문으로 넘어가도록
- 오류가 발생했는데 확인하지 못하고 다른 요청을 보내는것을 방지
등이 되겠다.
Blocking의 필요성과 코드 하나로 수많은 작업을 가능하게 하는 노련함을 엿볼 수 있었다.
과연 나중에 내가 Batch를 사용한다면, 오버헤드와 효율성을 테스트 할 수 있을까?
결론
우아콘 영상에서 내가 느낀 개발자들의 고민은 다음과 같다.
- 기술을 도입할때 오버헤드를 고려하였는가
- 프로젝트에 대해 얼마나 이해를 잘 하고있는가
- 기술 도입시 효율성을 어떻게 측정할 것인가
- 코드를 최대한 효율적이고 간결하게 짤려고 노력하였는가
과연 나는 좋은 개발자가 되기 위한 방향성을 정확하게 잡고있는지 고민하게 되었다.
