
이해도 잘 가지 않고 막연한 '둔기'를 해석할 때가 왔다.
이번에는 특히나 쓰레드/프로세스/추상화 개념이 이해가 잘 안되긴하는데
글을 적어보며 정리하는 시간을 갖도록 하겠다.
캐시 메모리
컴퓨터가 프로그램을 실행할때 하드디스크에서 정보를 가져와 메인 메모리에 저장 후, 프로세서로 복사가 된다. 이 과정은 너무나도 길고, 하드디스크의 속도도 느리기 때문에 '실제 작업'이 늦어진다는 단점이 있는데, 이를 보안하기 위해서 용량은 작지만 속도는 무지하게 빠른 '캐시 메모리'를 만들게 되었다.
저장장치들은 용량이 늘어나게 되면 속도가 늦어지는 단점이 생긴다. 간단하게 복도가 1km쯤 되는 창고를 생각해보자. 출입구는 1개일것고, 용량은 엄청나게 크지만 원하는 물건을 '찾는데'도 오래 걸릴 것이고, 물건을 들고 '나오는'데도 엄청나게 많은 시간이 걸릴것이다.
이와 비슷하게, 시스템 데스크는 메인 메모리보다 1000배 용량이 크지만, 속도는 천만배 오래 걸릴 수도 있다.
캐시 메모리는 레지스터, L1, L2, L3 캐시를 가지고 있다.
저장장치들의 계층 구조
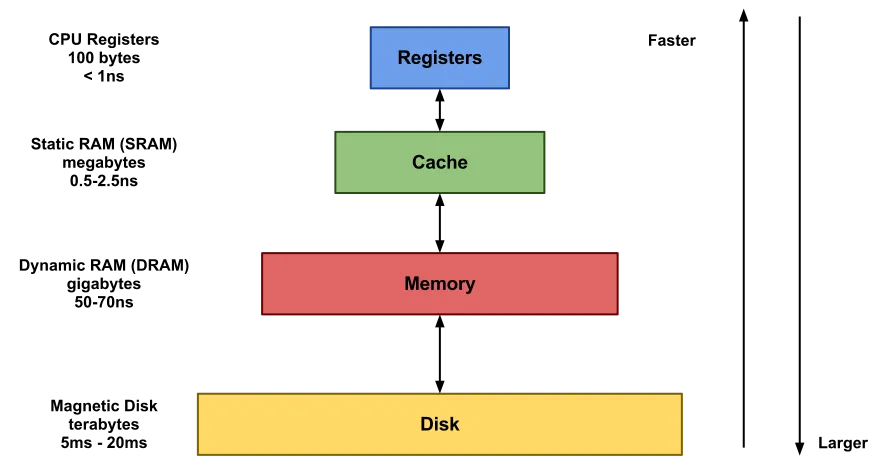
위부터 순서대로
- 레지스터
- L1,L2,L3캐시
- 메모리(DRAM)
- 디스크
하드웨어를 관리하는건 운영체제
운영체제는 두가지 주요 목적을 가지고 있다.
- 제멋대로 동작하는 운영프로그램들이 하드웨어를 잘못 사용하는 것을 막기 위해
- 응용프로그램들이 단순하고 균일한 메커니즘을 사용하여 복잡하고 다른 저수준 하드웨어 장치들을 조작 할 수 있도록 하기위해
프로세스
프로세스 = 실행 중인 프로그램에 대한 운영체제의 추상화
추상화 = 동물(추상화) - 개,고앵이,말(객체)
프로세스(추상화) - 프로그램 실행에 필요한 여러것들
프로세스의 전환
- 현제 프로세스의 컨텍스트를 저장, 새 프로세스의 컨텍스트를 복원시키는 문맥전환을 실행
- 새 프로세스는 이전에 중단했던 그 위치부터 다시 실행
쓰레드(Thread)
프로세스는 한 개의 제어흐름을 갖는 것으로 생각 할 수 있지만,
사실 Thread라고 하는 다수의 실행 유닛으로 구성되어 있다...
각각의 쓰레드는 해당 프로세스의 컨텍스트에서 실행되며 동일한 코드와 전역 데이터를 공유한다.
- 설명 추가
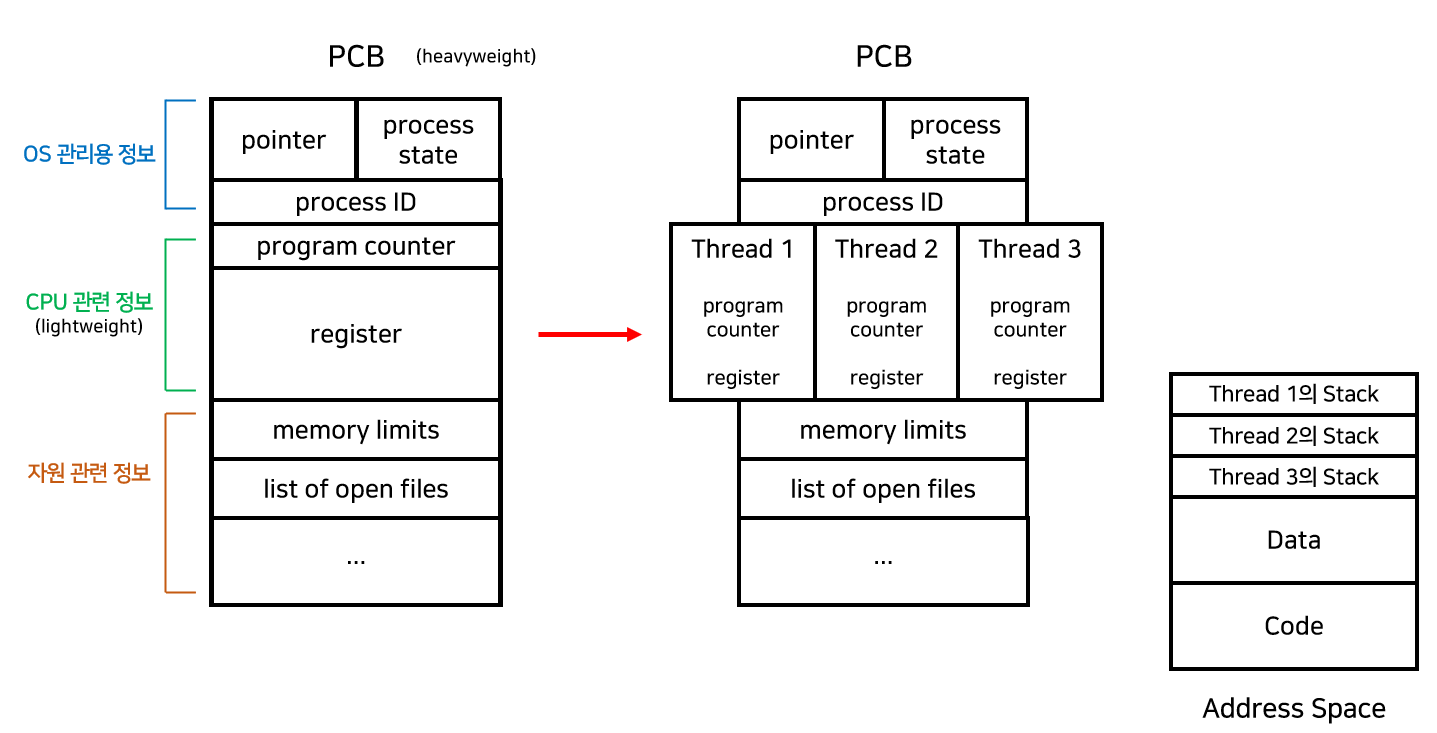
계속 이 쓰레드라는놈이 뭐하는놈인가.. 계속 고민하고 있었는데 다행이도 멀티쓰레드를 공부할 때 감을 잡았다.
쓰레드는 다음과 같은 특성을 가지고 있다.
-
자신만이 쓰는 레지스터/스택을 배정받는다.
-
다른 쓰레드와 힙 및 다른 데이터를 공유한다.
-
그럼으로 쓰레드는 프로세스 에서 연산을 하는 주체라고 생각하는게 편하다.(물론 엄밀하게 말하면 다른 소리긴 하지만 쓰레드의 개념을 파악하기에는 좋다.
프로세스는 운영체제로부터 자원을 할당받는 단위이고,
스레드는 프로세스가 할당받은 자원을 실행하는 단위이다.
라고 이해하면 된다.
그리고 일반적으로는 멀티프로세스가 컨택스트 스위칭이 없어서 속도가 빠르지만
공유해야할 메모리가 많다면 프로세스들은 공유를 할 수 없기 때문에,
자원을 공유하는 멀티쓰레드의 속도가 빠르다.
*설명 또 추가
나아아중에 pintos쯤 가면 스레드가 만들어지고 지워지는 과정을 통해서 함수를 돌리는 과정이 나온다.
결국 여기까지 와서 얻게되는 결론은
-
프로세스는 자원을 할당받아 돌리는 주체이고 , 스레드는 그러한 작동의 단위이다.
-
또한 더 중요한것은 프로세스가 스레드를 만드는데 , 그 스레드가 프로세스를 실행하는 스레드가 되면 별도의 프로세스가 만들어져 그놈도 스레드를 독립적으로 돌린다.
즉 예시를들면
-
프로세스A는 메인스레드 A'와 스레드 a , b , c를 실행시킨다.
-
스레드 a는 프로세스 P를 실행시킨다.
-
작동된 프로세스P는 메인스레드 P'와 스레드 Q , W , E를 각각 가진다.
-
결국 프로세스A에서 파생되었지만 프로세스A , 프로세스P 둘다 자신만의 메인 스레드를 가지고, 또한 각각 스레드를 가진다.
그러니까 프로그램은 수많은 프로세스와 메인스레드 , 그리고 스레드를 많이 , 그리고 동시에 실행시킬수 있다.
가상메모리
각 프로세스들이 메인 메모리 전체를 독점적으로 사용하고 있는 것 같은 환상을 제공하는 추상화..
말로 하면 더럽게 어려운데
그냥 메모리에서 여기저기에 있는 빈 메모리들을 긁어와서 하나의 큰 메모리처럼 보여준다는 소리다.
더쉽게 말하면 수십개의 물컵에 나눠져있는 물을 큰 물병 하나에 있는것'처럼' 하나로 보여준다는소리
이거 이상의 설명은 책을 오해할 수 있음으로 여기까지...
파일
그냥 연속된 바이트 덩어리이다. 우리가 아는 그 파일
시스템은 네트워크를 사용하여 다른 시스템과 통신한다.
-> 말 그대로 컴퓨터 간의 정보교환을 위해 인터넷이 만들어졌다는 소리
Amdahl의 법칙

인도 아저씨같은 이름인데 광기서린 눈을 가진 할아버지가 나왔다.
대충 한줄로 표현하자면
'시스템 실행에 대부분을 차지하는 프로그램을 아무리 최적화 잘해봤자 별로 효과없다' 이거다.
암달의 법칙은 간략하게 적으면
S = 1/(1-a) (S = 속도 개선율/a = 전체에서 몇퍼센트의 시간을 잡아먹는지)
인데,
글로적어서 힘들지 풀어서 적으면
시스템에서 60퍼센트의 시간을 잡아먹는 놈을 0에 가까운 시간으로 최적화를 시켜봤자
1/(1-0.6), 즉 2.5배의 속도개선율밖에 안나온다는 소리다.
그러니까 성능 최적화는 미친듯이 해봤자 돈이 별로 안되니까 열심히 해봐라는 소리다.
동시성과 병렬성
컴퓨터는 역사를 통해 두개의 요구가 지속적으로 성능개선을 주도해왔다.
동시성은 더 많은 일을 해주기를
병렬성은 더 빨리 실행되기를 바라는 것이다.
동시성
- 저글링하면서 공을 여러개 던지는것과 같은 원리
- 원래의 uniprocessor system에서는 다른 일을 하러면 이거 하다 저거하다 해야했음
- multiprocessor system에서 multicore, hyperthreading 등
-
chip이 4개의 cpu 코어를 가질때 l1,l2 캐시를 가지고 있고
l1캐시는 다시 두 부분으로 쪼개진다.
하나는 instruction, 한놈은 데이터를 들고
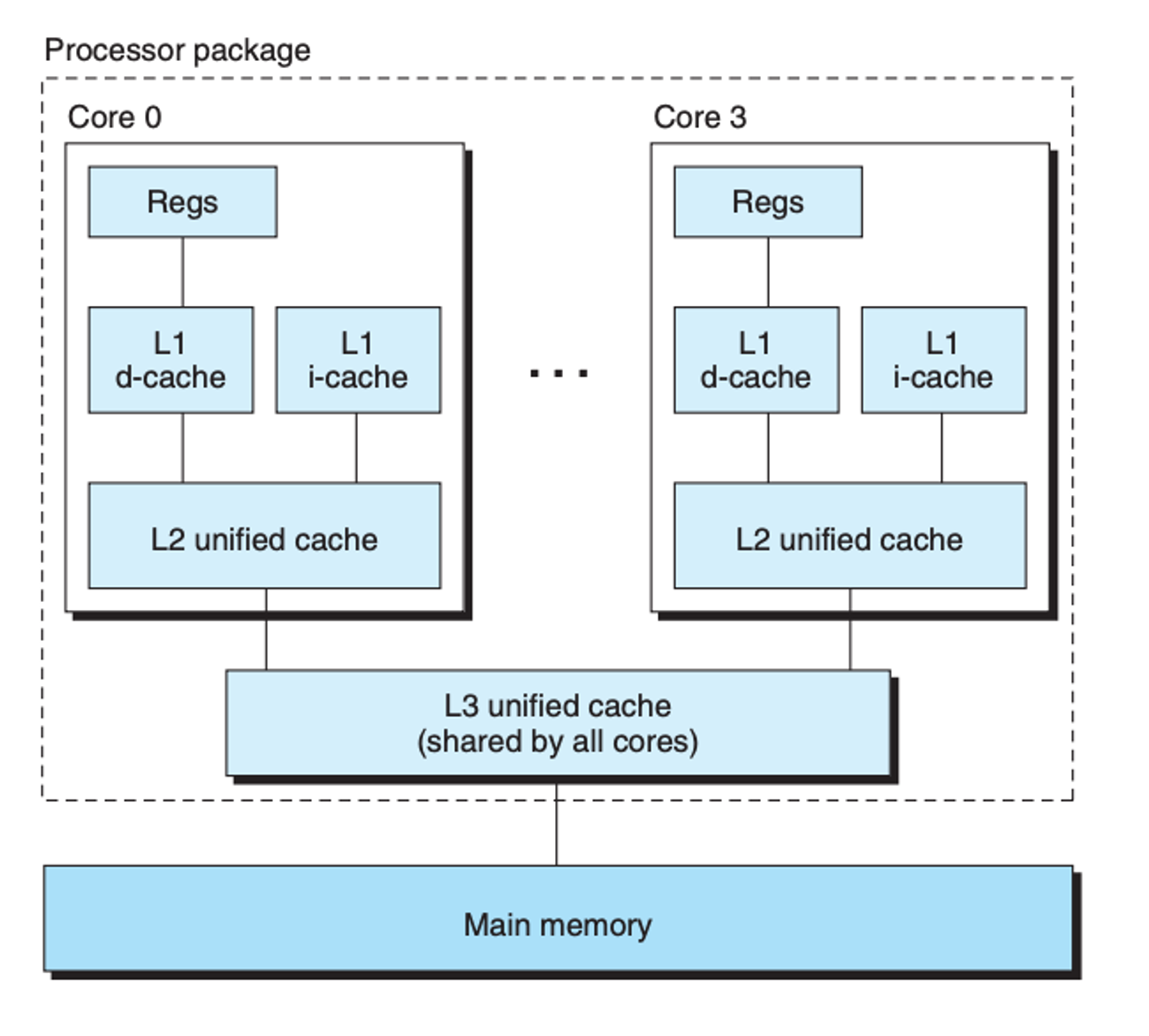
-
l3등 높은레벨 캐시에 대해서는 공유한다.
하이퍼쓰레딩
원래 쓰레드를 바꿀려면 2만 싸이클이 필요했지만, 하이퍼쓰레딩은 사이클 단위로 어디에서 실행될지 결정해버림. intel-i7의 경우, 4개의 코어가 각각 2개의 쓰레드를 실행시킬 수 있기 때문에 8개의 쓰레드가 병렬로 작동 가능
인스트럭션 수준의 병럴성
최근 프로세서들은 훨씬 낮은 수준에서의 추상화로 여러 개의 인스트럭션을 한번에 실행 가능함. 이러한 특성을 인스트럭션 수준 병렬성이라고 한다.
사이클당 한 개 이상의 인스트럭션을 실행 할 수 있는 프로세서를 슈퍼스케일러라고 함.
싱글 인스트럭션, 다중 데이터 병렬성(SIMD)
최신 프로세서들은 한개의 인스트럭션이 병렬로 다수의 연산을 수행 할 수 있는 특수 하드웨어를 가지고 있음.
암드의 최신 세대 프로세서들은 8쌍의 단일정밀도 부동소수(float형) 간의 덧셈 연산을 병렬로 실행 가능함/
일부 컴파일러들이 자동으로 c프로그램에서 simd 병렬성을 추출할려는 시도를 하고 있지만, 보다 안정적인 방법은 gcc같은 컴파일러에서 지원하는 데이터형을 사용하여 프로그램을 작성하는 것.
