
CSAPP 6장 메모리 계층구조
6-1. 저장장치 기술
일반적으로 RAM은 정적인 SRAM과 동적인 DRAM으로 나뉜다.
1. SRAM
-
각 비트를 이중안정 메모리 셀에 저장한다. 각 셀은 여섯 개의 트랜지스터 회로로 구현된다.
-
이 회로는 안정적이라 전원이 공급되는 한 무한이 유지가 된다. 전압을 흔들어도 외력이 없어지면 안정된 값으로 돌아온다.
2. DRAM
-
각 비트를 전하로 캐패시터에 저장한다.
-
DRAM은 집적도를 매우 높힐 수 있다.
-
여러 원인의 누수전류로 10~100ms 사이에 전하를 상실하게 된다.(컴퓨터 성능에는 문제없다.)
3. 비휘발성 메모리
-
SRAM과 DRAM은 전원이 꺼졌을때 정보를 잃어버리기 때문에 휘발성이다.
-
다양한 비휘발성 메모리가 존제하는데, 이걸 역사적인 이유로 전부 ROM이라고 한다.
-
ROM 디바이스에 저장된 프로그램들은 '종종' 펌웨어라고 부른다.
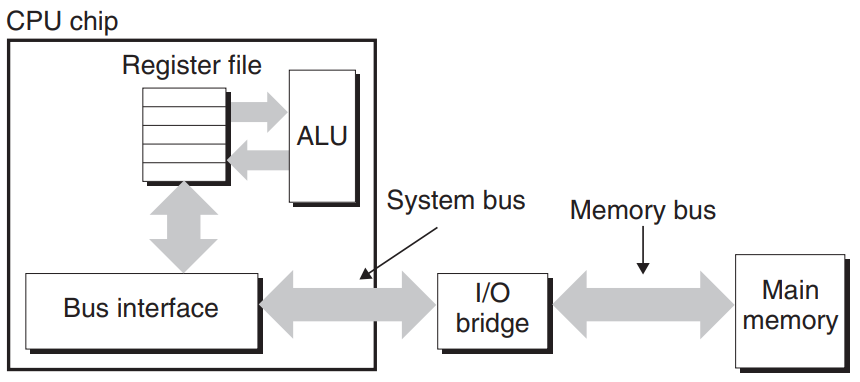
4. 메인메모리 접근하기
-
데이터는 버스를 통해 프로세서-DRAM간에 앞뒤로 교환된다.
-
CPU와 메모리 간의 매 전송은 '버스 트랜잭션'이라고 부르는 일련의 단계들을 통해서 이뤄진다.
-
다음은 적재연산에 대한 메모리 읽기 작업이다.
-
- CPU가 movq A,%rax라는 로드 연산을 할 때, CPU는 주소A를 메모리 버스에 보낸다.
-
- 이후 메인메모리는 버스에서 주소A를 읽은 후 메인메모리 내 워드X를 찾아 그걸 버스로 보낸다.
-
- CPU는 버스에서 워드x를 읽고, 그것을 레지스터%rax로 복사한다.
-
다음은 저장연산에 대한 쓰기 과정이다.
-
- CPU는 주소 A를 메모리 버스에 보낸다. 메인메모리는 이것을 읽고 데이터 워드를 기다린다.
-
- CPU는 데이터 워드 y를 버스에 보낸다.
-
- 메인메모리는 데이터 워드 y를 버스에서 읽고 이것을 주소 A에 저장한다.
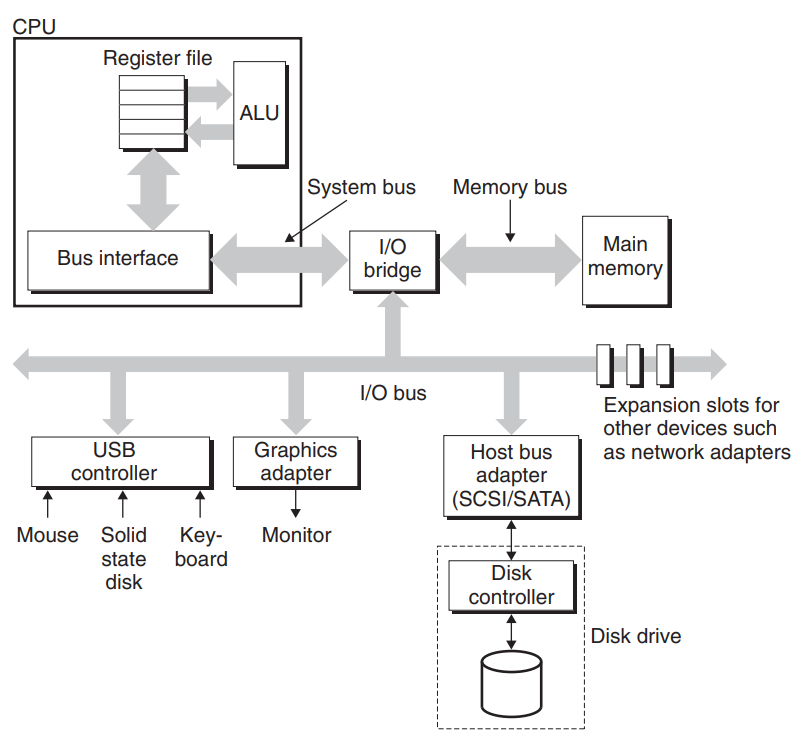
5. 다른 내용들
-
디스크에 대해서 나온다. 디스크의 구조, 용량, 동작에 대해 설명한다.
-
입출력 장치에 대해서 나온다. cpu, main memory 를 포함한 여러 장비들은 I/O bridge를 통해 서로 소통한다.
-
디스크 섹터 읽기에 대해서 나온다. 위의 메인메모리 읽기와 다른점이 있다면, 메인메모리 읽기는 메인메모리에서 워드x를 찾아 바로 버스로 보내지만, 디스크는 cpu에서 디스크를 읽은 후, 메인메모리로 DAM 전송을 수행 한 후, 디스크가 CPU에 인터럽트로 수행이 완료되었다고 알린다.
-
SSD에 대해 나온다. 블록이 노후화되면 성능 저하가 일어나기 때문에 랜덤쓰기를 통해 한쪽이 노후화가 심하게 되는것을 방지하고, 디스크와는 반대로 움직이는 부품이 없으며, 소모 전력도 적고 더 견고하다. 하지만 가격이 디스크에 비해 많이 비싸다.
6-2 지역성
-
지역성은 일반적으로 시간 지역성 , 공간 지역성 으로 나뉜다.
-
좋은 시간지역성을 가지는 프로그램의 한번 참조된 메모리 위치는 가까운 미래에 다시 여러번 참조될 가능성이 높다.
-
좋은 공간 지역성을 가지는 프로그램에서는 만일 어떤 메모리 위치가 일단 참조되면, 이 프로그램은 가까운 미래에 근처의 메모리 위치를 참조할 가능성이 높다.
+추가설명) 왜 같은 메모리 위치를 참조하는게 효율을 증가시키는가?
-> 하나의 위치에 데이터 1개만 있는 것이 아닌, 데이터의 '집합'들이 모여있는데,
같은 위치에 있는 다른 데이터를 참조할려고 할 때, 추가적인 불러오기 작업을 안해도
같은 위치의 옆 데이터를 참조할때 이미 캐시에 저장되기 때문. -
지역성이 좋고 나쁨에 따라 프로그램의 속도가 차이나기 때문에 프로그래머는 지역성의 원리를 이해하여야 한다.
-
지역성에 대한 요약을 하자면 다음과 같다.
-
- 동일한 변수들을 반복적으로 참조하는 프로그램은 좋은 시간 지역성을 누린다.
-
- stride-k 참조 패턴을 갖는 프로그램에 대해서 stride가 적으면 적을수록 공간 지역성도 좋아진다.
-
- 루프는 인스트럭션 선입에 대해 좋은 시간 및 공ㄱ간 지역성을 갖는다. 루프 본체가 작으면 작을수록 루프 반복실행의 수는 더 커지고 지역성도 더 좋다.

지역성을 이해하기 너무 좋은 예제이다.
sum += a[k][j][i] 순으로 하면 데이터가 순차적으로 쌓이고, 섞이지 않기 때문에 지역성이 좋아진다.
즉, a[k][0][0] , k = 0 ~ N 데이터가 메모리에 기록되고 난 후,
a[k][1][0] 데이터가 메모리에 쌓이고...
이렇게 된다는 뜻이다.
6-3 메모리 계층구조
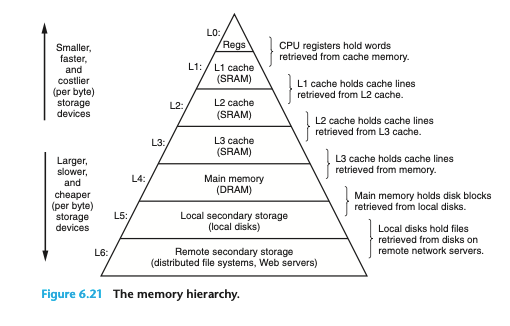
이전에 봤던 memory hierarchy 이다.
-
일방적으로 캐시라고 하면 L1,L2,L3 cache를 많이 생각하지만, k + 1레벨의 저장장치를 위해 k 레벨의 저장장치가 캐시 서비스를 제공한다. local disk를 위해 DRAM이 캐시 서비스를 제공한다는 뜻이다.
-
k+1로부터 특정한 데이터를 필요로 할때, 일단 k레벨에 저장된 블록들 중 하나에서 데이터를 찾는다. 이때 데이터가 있다면 '캐시적중'이라고 하고, k+1레벨에서 데이터를 읽어오는것보다 훨씬 빠르다.
-
만약에 데이터가 k레벨에서 캐시되지 않는것을 '캐시미스'라고 한다. k+1에서 데이터를 받아오며, k레벨 캐시가 꽉 찼다면 기존의 데이터를 덮어씌우기도 한다.
-
캐시미스도 여러 종류가 있는데, 비어있는 캐시를 cold cache, 데이터 배치 전략 때문에 발생하는 미스를 충돌미스(conflict miss)를 유도하게 된다.
위의 내용을 요약하면, 캐싱에 기반을 둔 메모리 계층구조는 보다 느린 저장장치가 더 빠른 저장장치보다 값이 더 싸고, 지역성을 갖는 경향이 있기 때문에 프로그램들은 다음과 같이 작동한다.
-
시간 지역성 활용하기 : 동일한 데이터 객체는 시간 지역성 때문에 여러번 재사용될 가능성이 있다. 일단 어떤 데이터 객체에 첫 미스가 발생하고 난 후, 이 객체로 다수의 hit를 기대할 수 있다.
-
공간 지역성 활용하기 : 미스가 발생한 후에 하나의 블록을 복사하는 비용은 차후에 이 블록 내의 다른 객체들을 참조하기 때문에 줄어든다.
6-4 캐시 메모리
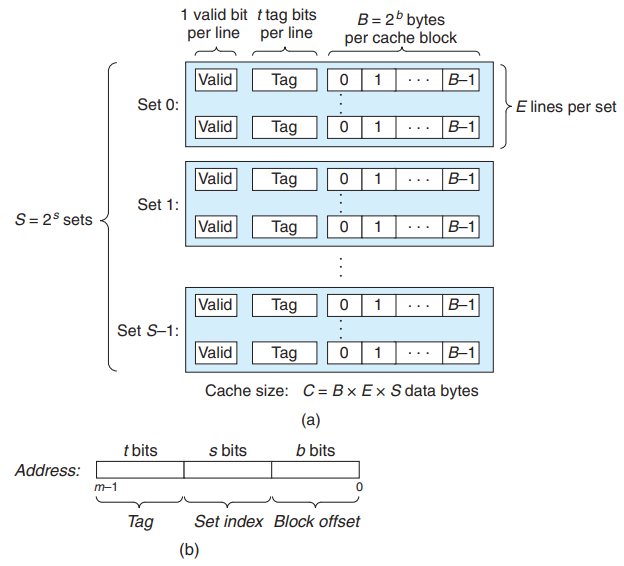
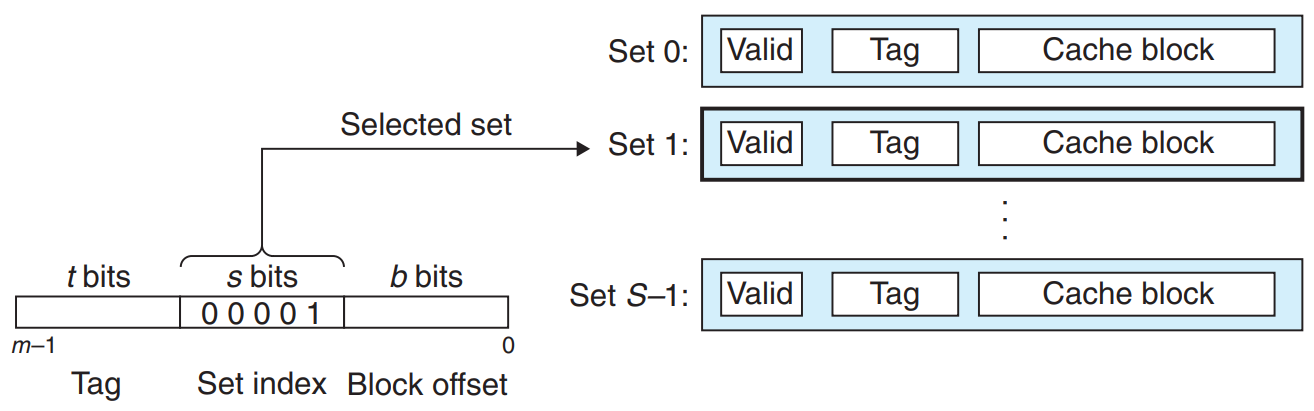
기본 캐시 메모리 구조
위 그림과 같이, 캐시 메모리는 2^s개의 set을 가지고 있고, 각 set은 E개의 라인을 가지고 있으며, 각 메모리 주소가 M = 2^m개의 고유 주소를 구성하는 m비트를 갖는 컴퓨터 시스템이다.
그래서 캐시의 구성은 순서쌍(S,E,B,m)으로 규정할 수 있다.
1. 직접매핑 캐시
캐시는 E의 값에 따라(한 set에 포함된 라인의 수에 따라) 종류가 달라진다.
E = 1 일때, 즉 하나의 set이 하나의 라인만 가지는 것을 직접매핑 캐시라고 한다.
직접매핑 캐시에서 요청한 w를 뽑아내는 작업은 세 단계로 이루어 진다.
-
집합 선택 : w의 주소로 s의 위치를 찾는다.
위 그림에서는 00001은 10진수로 1을 의미하는 것이니까, set1을 찾는 것이다. -
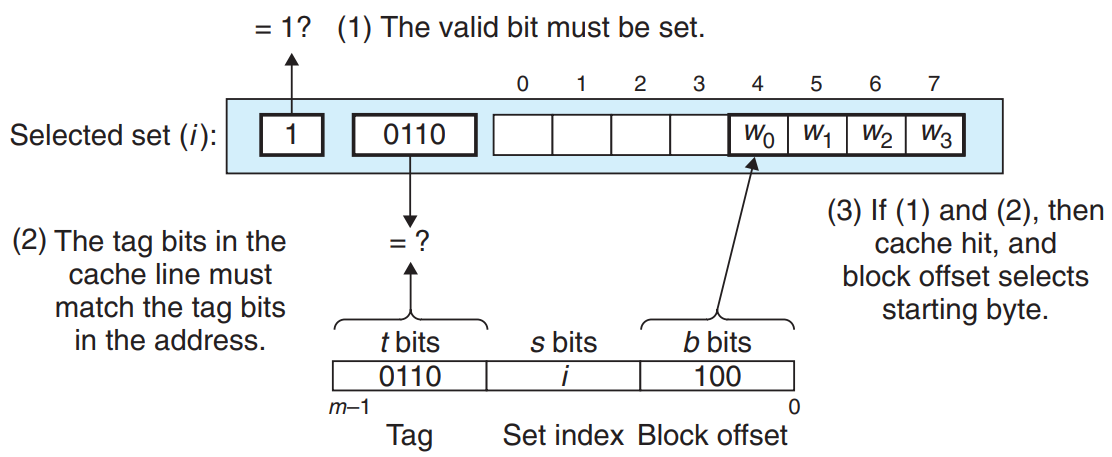
라인 매칭 : 전 단계에서 set을 찾았으니, 이번에는 찾는 Tag가 있는지 확인한다.
직접매핑 캐시는 라인이 하나이기 때문에 매우 간단하다.
-
워드 선택 : 캐시 적중이 발생했을때, block offset에 있는 주소를 통해 w의 위치를 확인한다.
위의 그림에서 100 = 4 임으로, 4번부터 원하는 정보가 있다는 것을 알 수 있다. -
미스 발생시 라인의 교체 : 캐시가 미스했을때, 다음 계층의 캐시에서 정보를 받아온다.
여기서 다음 계층이라는 것은 6-3의 내용에서 k+1 계층이라고 생각하면 된다. -
요약
-
- Tag, Set index, Block offset을 통해 데이터 위치를 특정시킬 수 있다..
-
- 모두 8개의 메모리 블록이 있지만, 4개의 캐시 집합만 존재하므로 여러 블록이 동일한 캐시 집합에 대응된다.
-
- 동일한 캐시 집합에 대응되는 블록들은 태그를 사용해서 구별가능하다.
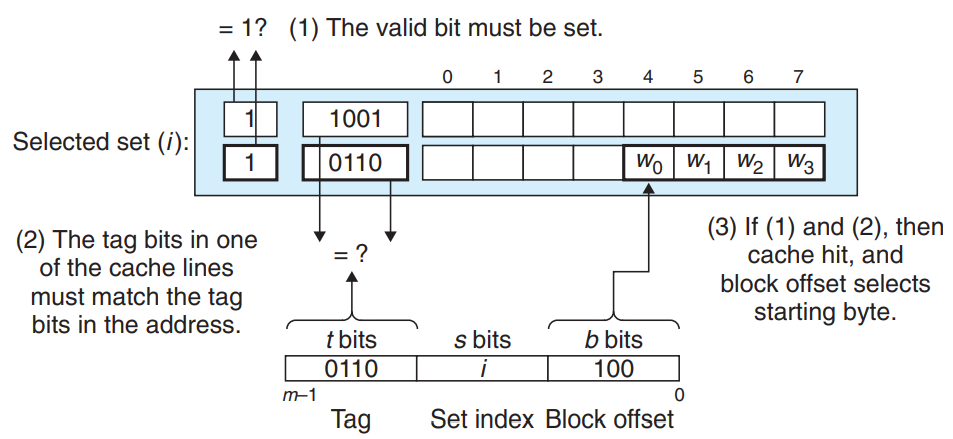
2. 집합결합성 캐시
집합결합성 캐시는 1 < E < C/B인 캐시를 의미한다.
-
집합의 선택 : 직접매핑 캐시와 동일한다.
-
라인 매칭과 워드 선택 : 라인 하나만 검사하면 되는 직접매핑 캐시와는달리, 집합결합성 캐시는 set 안에 있는 모든 라인들을 검사해야 한다.
-
미스 발생시 라인의 교체 : 직접매핑 캐시처럼 데이터 미스가 발생했을때 k+1캐시로 부터 데이터를 받아온다. 데이터를 선입할 때 비어있는 라인이 있다면 비어있는 라인에, 비어있는 라인이 없다면 다른 라인의 데이터를 교체한다.
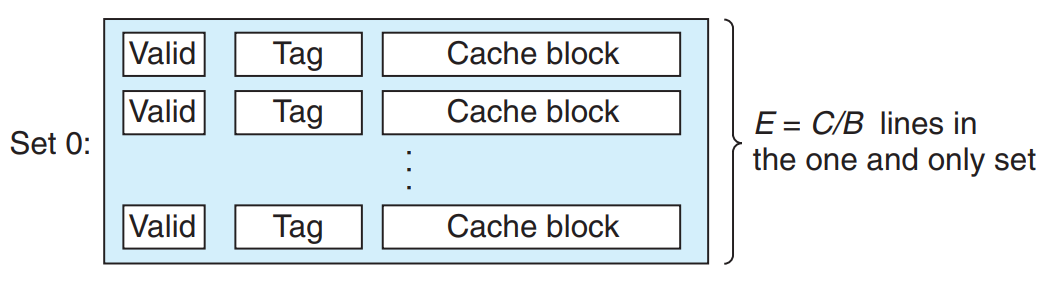
3. 완전결합성 캐시
E = C/B인 캐시를 말한다.
-
집합의 선택 : 단 하나의 집합만 있기 때문에 매우 간단하다. 주소에는 집합 인덱스 비트가 없고, 주소가 태그와 블록 오프셋으로만 나누어진다.
-
라인의 매칭과 워드 선택 : 워드 선택은 집합결합성 캐시와 동일하게 작동한다. 규모에서 차이점이 발생하는데, 캐시 회로가 많은 수의 태그를 병렬로 검색해야 하므로 크고 빠른 결합성 캐시를 만드는 것이 어렵고 비용이 많이 든다.
4. 실제 캐시 계층구조의 해부
-
사실 캐시는 데이터 뿐만 아니라 인스트럭션들도 저장할수 있다!
-
1장에서 다뤘다시피 intel core i7의 core 안에는 l1,l2 캐시가 포함되어 있다.
5. 캐시 매개변수의 성능에 대한 효과
-
미스 비율 : 미스하는 메모리를 참조하는 비율
-
적중 비율 : 적중한 메모리를 참조하는 비율, 1-missrate로 계싼된다.
-
적중 시간 : 캐시의 워드를 cpu로 전달하는데 걸리는 시간. L1의 경우 클럭 단위를 가진다.
-
미스 비용 : 미스로 인해서 추가적으로 요구되는 시간. 캐시의 단계가 높아질수록(k의 크기가 커질수록) 미스 비용이 급격하게 증가하게 된다.
6. 캐시 크기의 영향
- 큰 캐시는 적중 비율을 높혀주지만 속도는 느려준다. 그래서 큰 캐시는 적중시간이 길어진다.
7. 블록 크기의 영향
-
블록의 크기가 커지게 되면 적중 비율이 높아진다.(많은 데이터를 로드 했으니까)
-
하지만 너무 커지면 미스 비용이 커지고 로딩시간이 길어진다.(미스했을때 많은 데이터를 가져와야 하니까)
결합도의 영향
-
E가 미치는 영향이다. E가 커지면 충돌미스로 인한 쓰레싱 위험성을 감소시킨다.
-> 쓰레싱 = 캐시 충돌 미스로 인한 급격한 페이징 요구의 증가. 용량 부족이다. -
단점으로는 구현이 비싸고 어렵다는 것이다.
-
또한 추가적인 로직으로 인해 적중시간이 길어지고 미스 비용도 증가한다.
6-5 캐시 친화적 코드 작성
기본적으로 2가지 접근법이 있다.
1. 공통 부분을 빠르게 동작하게 만들어라.
2. 각 내부 루프의 캐시 미스 수를 최소화 시켜라.
즉,
for (i = 0; i < M; i++)
for(j = 0; j < N; j++)
sum += a[i][j]; // i와 j의 순서가 바뀌면 효율이 크게 떨어진다.
return sum;이런 방식으로 만들라는 소리다. 이것에 대한 더욱 자세하고 많은 예시들이 나와있다.
6-6 종합 : 프로그램 성능에 대한 캐시의 영향
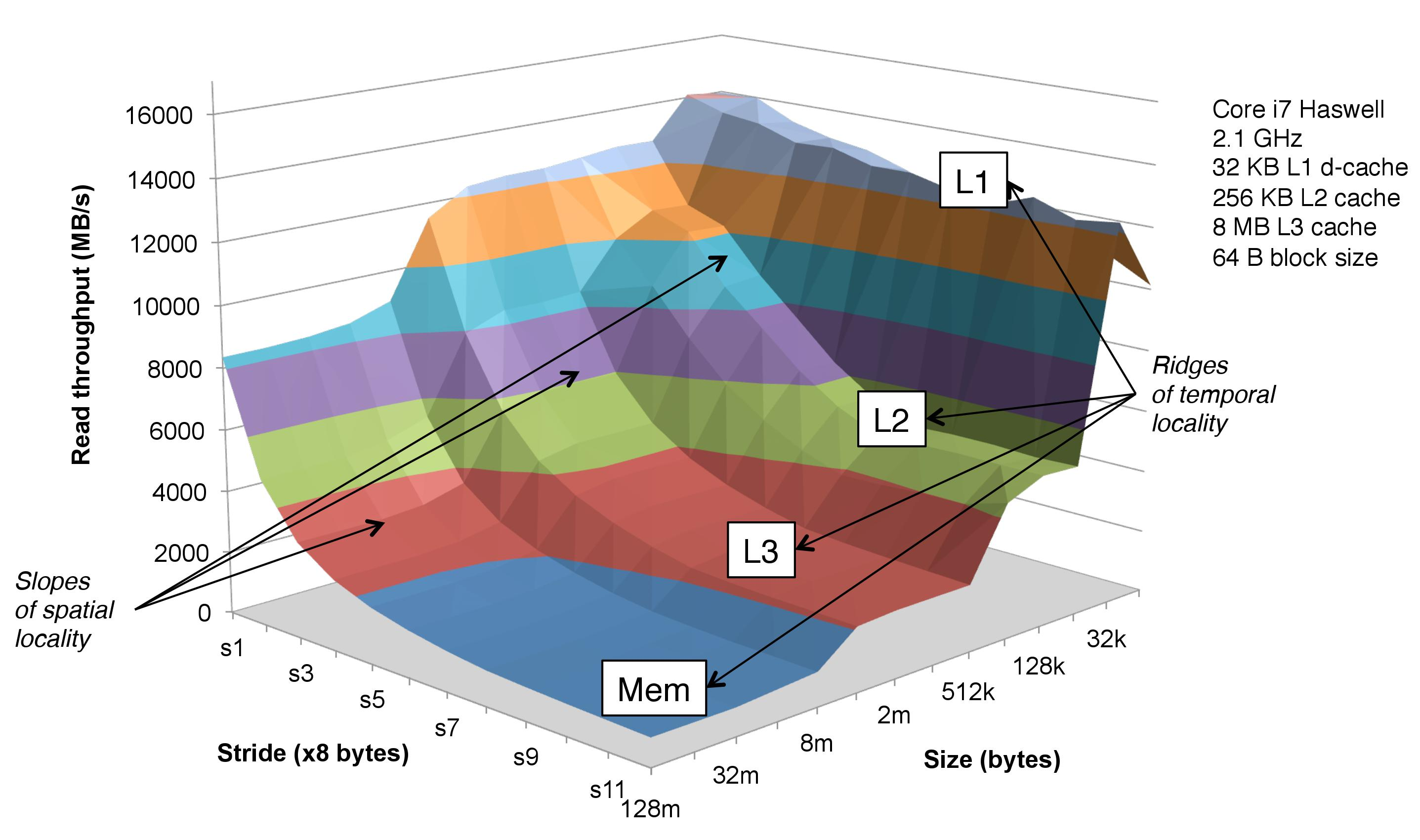
이 그림은 memory mountain에 관한 그림이다.
x축은 stride가, y축은 데이터의 크기, z축은 읽기 속도에 대응된다.
csapp 614쪽의 함수를 실행하면 위와 같은 그림이 나오는데, 이것으로 메모리의 성능을 측정할 수 있다.
위 그림에서 급한 경사가 있는 부분, 즉 size : 32k, 256k, 2m 부근에서 급격한 성능 저하가 발생하는데, 이 부분들이 각각 L1 , L2 , L3 , Mem의 용량 크기인 것이다.
6-7 요약
기본적으로 저장장치 기술들은 RAM , ROM , 디스크가 있다.
RAM은 두가지로 나뉘는데, SRAM은 더 빠르고 비싸고, 캐시 메모리로 사용된다.
DRAM은 느리고 덜 비싸며, 메인메모리와 그래픽 프레임 버퍼로 이용된다.
ROM은 전원이 꺼진 경우에도 자신의 정보를 유지하며, 펌웨어를 저장하는데 사용된다.
디스크는 기계적인 비휘발성 저장장치로 적은 단가로 엄청난 양의 데이터를 저장하지만, 많이 느리다.
SSD는 회전디스크의 대체품으로 사용되고 있다.
