

Kaist 권** 교수님의 강의를 들었다.
학부 다닐때도 우리학교 교수님들 보면 포스가 범상치 않았는데 오늘 강의를 해주신 교수님 또한 정말 대단한 분이라는걸 느꼈다.
가장 중요한 점은 강의를 진행할때 확신이 있다는 것과, 하신 말씀들을 곰곰히 생각해보면 포괄적으로 정확한 말들이라는 것을 알 수 있었다.(다른 케이스 , 다른 개념이 들어왔을때도 예외가 없다는뜻)
서론이 좀 길었는데, 짧게 정리하면
교수는 아무나 하는게 아니고 그 중에서 kaist 교수님들은 좀 더 특별한거 같다.(척척석사는 없는거같다.)
밑에 글을 읽다보면 이상하게 느껴지거나 잘못된 부분이 있을 수 있습니다. 하지만 그건 교수님의 강의가 이상해서가 아닌 , 생소한 내용 + 강의를 듣고 난 후 적는것이라 실수가 발생할 수 있습니다.
교수님은 어려운 개념들을 정말 쉽고 간단하게 설명해주셨습니다.
OS의 역할
-
하드웨어를 쓰기 위한 추상화를 디자인 하는것(app을 쓰기위해 api를 정의)
-
보호 / 독립성
- app의 비정상/악의적 행동을 관리
- OS를 app의 비정상/악의적 행동에서부터 보호
- app을 다른 app으로부터 독립시킴
-
자원 공유
- 복합적인 하드웨어의 리소스를 관리한다
OS를 처음 설계할때 했던 생각들
추상화란 무엇인가?
- 중요하지 않은 몇몇 details를 무시한, 이해하기 쉽게 만들어진 process나 doutcome이다.
-> 어떠한 개념을 설명하기 위해 정의된 개념이다.
OS 디자이너의 첫번째 생각
우리가 만들 OS의 목적은
- 프로그래밍 하기 쉬워야 하고
- 유닛 실행을 관리해야 하며
- 유닛 실행을 보호해야 한다.
-> 결론은 각각의 app들이 하나의 기계로서 작동한다는 '환상'을 심어주자.
그리고 이것을 process라고 부르자.(executed application)
어떻게 하드웨어를 사용하기 쉽게 만들까?
OS 디자이너들은 하드웨어 자원들의 추상화를 build하였으며, 이것을 process로 묶었다.
-
CPU -> Virtualizing CPU
-
Memory -> Virtual address space
-
Storage -> File
OS 디자이너들은 app들이 추상화를 사용하기 위해 API를 제공하였고,
이것을 system calls라고 부른다!
정보의 저장
user - level software에서 HDD / SSD로 정보가 옮겨지기 위해서는 다음과 같은 단계를 건너게 된다.
-
VFS - POSIX API(open , read , write , ...)
-file system(Ext4 , F2FS , NTFS , XFS...) -
Generic Block Interface (blk read , blk write)
-
Generic Block later
(A kernel component that handles the requests for all block devices in the system.) -
Specific Block Interface(protocol-specific)
-
Device Driver(SCSI , SATA)
-
Disk interrupt handler
-
HDD , SSD
아주 많은 단계를 거친 이후에야 비로소 HDD / SSD로 들어가게 된다.
하지만 잘 보아야 하는것이 , VFS , Generic Block Layer을 제외한 다른 구성요소들은 file sys , interface , driver , handler이다.
그러니까 우리는 VFS , GBL이 뭐하는 놈인지 알아보자.
VFS - POSIX API
-
vfs는 가상 파일 시스템이다.
-
application이 하드디스크의 여러 파티션에 데이터를 open , read , write를 할때 , 각각의 함수를 모두 호출하여야 함으로 매우 번거롭다.
-
그래서 이러한 작업을 하나의 프로세스에서 처리해주기 위한 번역기 같은 기능을 한다고 볼 수 있다.(진짜 번역하는건 아니고 비유가 그런거다)
결론 : app이 접근하는 파일이 파일시스템과 상관없이 일관된 POSIX 표준 인터페이스를 사용해 파일에 접근하는걸 가능하게 만듬.
GBI
찾아도 정보를 얻을 수 없어서 gpt를 통해 정보를 얻었다.
Generic Block Interface(GBI)는 컴퓨터 시스템에서 데이터를 전송하기 위한 표준 인터페이스입니다. 이는 하드웨어 장치들이 서로 통신할 수 있도록 돕는 역할을 합니다. GBI는 주로 저장 장치와 프로세서 사이의 데이터 전송을 관리하는 데 사용됩니다.
GBI는 일반적으로 다음과 같은 기능을 포함합니다:
데이터 전송: 주변장치(예: 하드 드라이브)와 프로세서 간의 데이터 전송을 위한 인터페이스를 제공합니다.
에러 처리: 데이터 전송 중 발생하는 에러를 처리하고 복구하는 기능을 제공합니다.
속도 조절: 데이터 전송 속도를 조절하고 최적화하는 기능을 제공합니다.
GBI의 예로는 SATA(Serial ATA) 및 SCSI(Small Computer System Interface)가 있습니다. 이러한 인터페이스들은 다양한 하드웨어 장치들 간의 표준화된 통신을 가능하게 하여 시스템의 호환성과 유연성을 향상시킵니다.
그러니까 호환성과 유연성을 향상시킨다는 뜻이다.
page cache
정보를 저장하는것 또한 엄청 중요하다.
DRAM에 저장된 메모리는 곧 사라지고 말기 때문에 Persist(영속성)을 부여해줘야 하는데 , 쉽게 말해서 Storage device(ssd 같은거)에 저장을 해 줘야 한다. 그런데 데이터를 저장 할 때에도 주의를 기울여야 한다. 바로 Atomicity와 Durability이다.
-
Atomicity : 메모리의 데이터가 storage device에 원자적으로 저장되어야 한다.
원자성이라는 말은 어려우니 따로 검색하도록 하자. -
Durability : 데이터는 영속적으로 저장되어야 한다. 저장해놨는데 1시간 뒤에 사라지고 하면 곤란하다는 뜻.
여기서 , Non - atomic update라는 것이 나온다.
데이터를 저장할려고 하는데 atomic하지 않아서 저장하는데 파일이 깨지는 경우가 생긴다는 것이다. 우리는 어떠한 작업을 실행할때 성공/실패 2가지 결과값만 받아야 되며 , 이외의 다른 결과값을 받게되면 안되는 것이다.
그래서 그 과정은 다음과 같다.
- creat(/a/log)
- write(/a/log, “Foo”)
- fsync(/a/log)
- fsync(/a/)
- write(/a/file, “Bar”)
- fsync(/a/file)
- unlink(/a/log)
위의 과정들은 처음 들어보는것이기도 하고 교수님께서 정말 빠르게 설명하고 넘어가셔서 정확하게는 이해하지 못했지만 , 핵심은 다음과 같다.
Atomic하게 진행이 되려면 진행 과정 중에 예외가 발생해서는 안되고 , 확실하게 성공 / 실패만 나와야 한다. 즉 실패를 해도 되돌릴 수 있어야 하고 성공이 된다면 온전한 결과값을 얻어야 한다.
보호 / 독립성
OS는 각각의 app들이 다른 영역을 침범해서 데이터를 마음대로 변형하는 것을 막아야 한다. 또한 OS는 kernel들의 충돌을 막아야 한다.
우리는 이러한 기능을 구현하기 위해 다음 기능들을 가진다.
-
Privileged instruction : app들이 중요한 instructions를 실행하는것을 막는다.
-
Memory protection : 다른 app의 메모리를 읽는걸 막는것.
-
(Timer) interrupt : app으로 부터 통제권을 가지는것
Separation of privilege
-
OS는 app보다 높은 '특권'을 가진다.
-
HW는 SW보다 높은 특권을 가진다.
-
HW가 OS에 높은 특권을 부여한다.
- OS는 특권을 가진 instructions를 실행할 수 있다.- OS는 OS코드와 데이터에 접근하는 app을 막기 위해 특권을 가진 메모리를 가질 수 있다.
이런것을 보면 kernel 영역에서 어떻게 권한을 독차지 해서 사용할 수 있는지에 대한 것을 이해할 수 있다.
protection mechanism

위 사진은 protection ring이라는 것이다.
쉽게 말해서 kernel에 가장 가까운 Ring0는 가장 큰 권한을 가지고 , kernel에서 가장 먼 Ring3는 권한이 가장 적다.
-
Dual mode operation (kernel mode / user mode)
- mode bit는 HW에서부터 제공받는다.
-
privilege I/O instructions
-
Memory protection mechanism(나중에 나옴)
이후 MMU에 대해서 나온다.
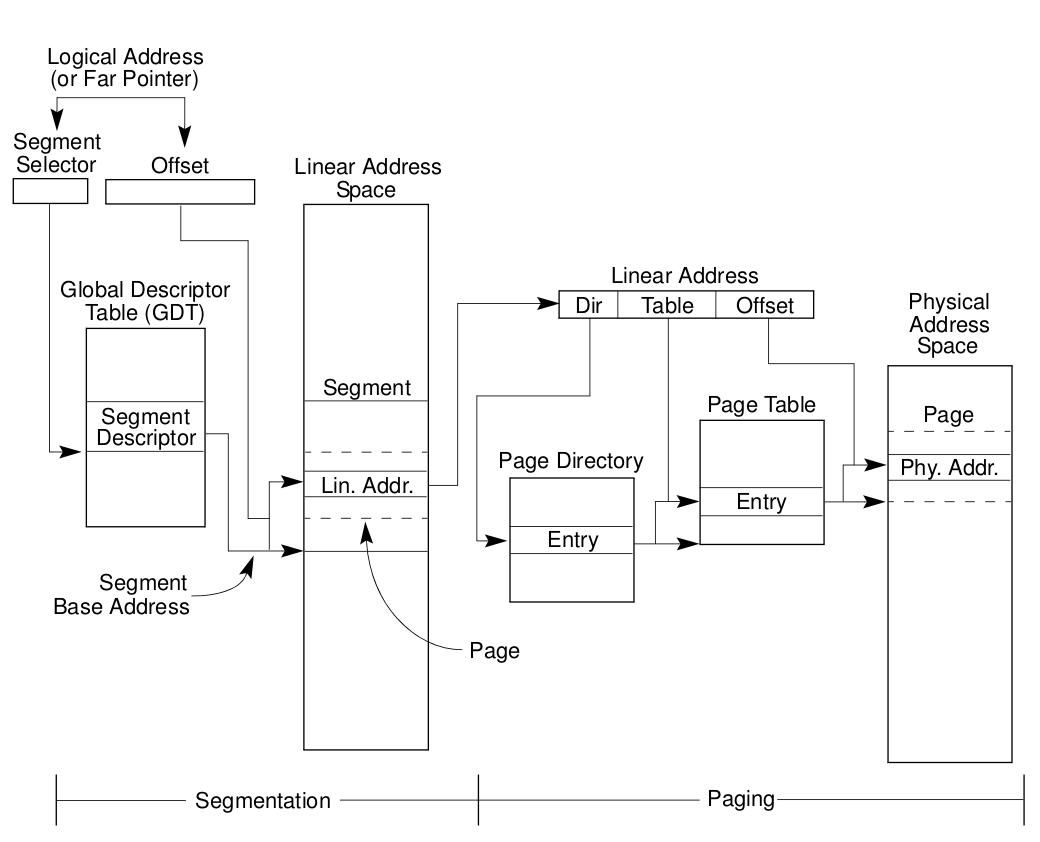
위 내용을 더 자세하게 알려면 segmentation mmu paging 등을 잘 읽어보자.
결국 하고싶은말은 segment descriptor에는 DPL이라는 descriptor privilege level(0:kernel/memory , 3:user/memory)라는게 나온다는거고 , Page table에는 User/Supervisor을 나타내는 1바이트 크기의 항목이 있다는 것이다.
그러니까 데이터를 관리할때도 protection mechanism이 쓰인다는 것이다.
그 다음은 kernel mode 이다.
여기는 복잡하게 설명하지만 정말 간단하게 요약은 가능하다.
과하다 싶을정도로 App과 APP , Kernel을 분리시켜 데이터의 변질을 철저하게 막는 것이다.
(개인 공부)
- Access control method
• DAC and MAC
• Capability-based access control - Authentication of user and system (mutually distrust)
- Protected communication between the protection boundary
• IPC (pipe)
Sharing resource
Time , Space sharing
-
time sharing : CPU , Archived bt scheduling
-
Space sharing : Memory , Archived bt virtual memory + space reclamation(page replacement) -> optimal , LRU , Clock , Belady's anomaly
이후
-
monolithic kernel
-
micro kernel
-
exo kernel
3가지 키워드를 주고 ppt가 끝난다.
결론
우리가 OS를 보면서 정리한 순서는 다음과 같다.
1. 추상화
2. 정보의 저장 - FS , Atomicity
3. 보호 / 독립성 - Privilege
4. 공유 자원 - Time , Space sharing
간단하게 4가지 분류로 보면 위와 같지만...
segmentation - mmu - paging - physical address space 부분만 봐도 하나하나 키워드가 엄청난 양의 정보를 가지고 있다...
하지만 큰 관점에서 OS가 왜 중요한지 , 주요하게 어떠한 역할을 하는지 , 또 어떤 부분을 공부해야 하는지에 대한 마일스톤을 얻은 느낌이다.
