
TLB (Translation Lookaside Buffer)
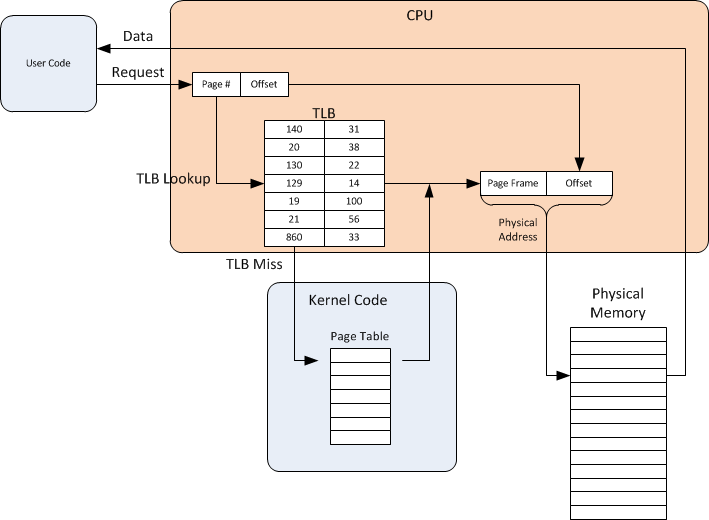
변환 색인 버파고 한다. virtual memory address를 physical memory address로 변환하는 속도를 높이기 위해서 사용되는 캐시이다.
말 그대로 주소변환용 캐시이기 때문에 cpu-cpu , cpu-main memory 등 여러 레벨의 캐시 사이에서 주소를 변환하는데 사용할 수 있다. 캐시의 캐시라고 보면 되겠다.
TLB는 페이지 테이블 , 세그멘트 테이블의 항목 중 일부를 미리 저장한다.
페이지 테이블에서는 각 항목이 virtual addres와 그의 물리주소를 , 세그멘트 테이블에서는 virtual address와 그에 해당하는 세그멘트 주소를 저장한다.
즉 , 위의 말을 종합해보면 페이지 테이블의 캐시라고 볼 수 있다.
순서는 위의 그림처럼 , 정보를 요청할때 TLB를 먼저 참고하고 , 없으면 kernel로 들어가서 page table을 검색한 후 , 이후 페이지 프레임에서 정보를 찾아 physical memory에서 데이터를 가져온다.
또한 TLB의 트랩은 시스템콜과 다르게 처리 후 다시 실행하기 때문에 히트가 된다.
Lazy Loading

정말 간단하게 말 그대로 모든 데이터를 다 로딩하는 것이 아닌 , 필요한 데이터만 로딩하고 나머지는 지연시켜서 로딩하는 것을 의미한다.
예시를 들어서 , 웹 페이지의 모든것을 다 로딩하는 것이 아닌 , 페이지에 들어갈때 보이는 부분만 미리 로딩을 하고 , 특정한 이벤트가 발생했을때 나와야 하는 이미지 , 텍스트 등은 나중에 로딩을 하는 것이다.
고양이라는 글씨를 클릭해야 이벤트가 발생하며 이미지가 사용자에게 보여지는 페이지가 있다고 하면 , 처음부터 고양이사진까지 싹다 로딩하는 것이 아닌 글씨를 클릭할때 고양이 사진을 로딩하는 것이다.
사용자가 다 사용할지도 모르는 이미지 파일들을 lazy loading 시키면서 웹 페이지의 로딩 속도를 높히고 , 불필요한 파일의 로딩 수를 감소시키면서 서버에 부하를 줄일수도 있다.
PRP
Page Replacement Policy , 즉 페이지 교체 정책이다.
다 적기에는 글자가 너무 길어 짧게 줄였다.
페이지 교체 정책은 정말 중요한 이슈이다.
앞서 csapp 읽을때도 적었지만 페이지 관리 잘못하다가는 threathing이 터져버려 cpu 사용률이 바닥을 치기 때문이다.
page replacement policy는 다음과 같다.
-
FIFO
가장 쉽고 편한 방법이다. 제일 먼저 들어온 페이지를 먼저 교체하는 방식이다. -
OPT(optimal)
앞으로 가장 오래 사용하지 않을 페이지를 교체하는 방식이다. 예측이 불가능하기 때문에 일반 OS에서는 사용이 불가능하고 , 특수 설계된 프로그램에서 사용한다. -
LRU
많이 보이는 방법이다. 가장 늦게 사용된 페이지를 교체한다. 자주 사용되는 데이터는 지역성이 높기 때문에 또 사용될 것임으로 , 자주 사용하지 않는 데이터는 지역성이 낮을것이라 예측하는 것이다. -
LFU
가장 적게 사용한 페이지를 교체하는 방법이다. 위의 LRU와 마찬가지로 지역성에 기반한 정책이며 , 성능이 뛰어나다. -
NUR(클럭 알고리즘)
LRU와 마찬가지로 가장 늦게 사용된 페이지를 교체하는 것이지만 각 페이지마다 참조비트 , 수정비트를 할당해서 (0,0) (0,1) (1,0) (1,1) 순서로 페이지를 교체한다. (0 - false / 1 - true)
추가 - TLB에서 LRU를 사용한다고 한다.
Belady의 역설 - FIFO에서 물리 페이지의 수가 늘어나면 성능이 떨어진다고 한다. 개인적인 의견이지만 백준 알고리즘 풀때 저격 테케에 걸린것처럼 모든 경우의 수 중에 FIFO에 불리한 input이 들어오는 경우도 있다고 봐야할 것 같다. 그러니 Bleday의 역설은 상황에 맞는 우선순위를 정해주지 않는다면 컴퓨터의 성능이 올라가도 별 효율을 못본다고 이해하면 될 것 같다.
Swap Disk
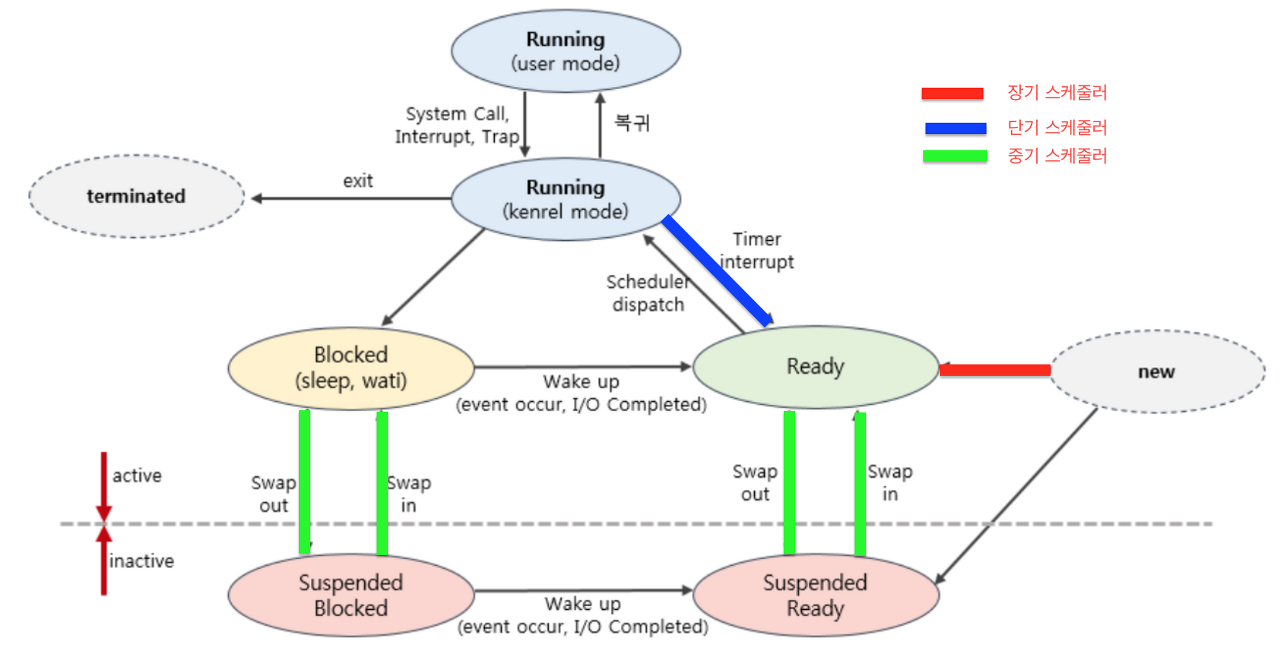
https://velog.io/@kts5927/CPU-scheduling
swap out이란 프로세스를 관리할때 RAM 용량 관리를 위해 다른 저장장치에 통째로 들어내는 것을 의미한다. 이처럼 한정된 RAM의 성능을 보조해주기 위해서는 특별한 저장공간이 새로 필요하게 되는데 이것이 Swap Disk이다.
일반적으로 Swap Disk는 HDD나 SSD에 만들기 때문에 RAM에 비해 한참 느리다. 느린것도 진짜 엄청나게 느리기 때문에 Swap Disk는 임시방편일 뿐 실질적인 문제의 해결법은 되지 않는다. 그러니 이러한 문제는 RAM의 크기를 늘리는게 좋다.
File-Backed Page
이전에 Anonymous page를 공부하다가 이상하게 이해를 했어서 이번 PintOS 프로젝트에서 참 힘들었는데, 이제야 완벽하게 이해가 된다.
우선 다음의 코드를 보자.
bool
vm_alloc_page_with_initializer (enum vm_type type, void *upage, bool writable,
vm_initializer *init, void *aux) {
ASSERT (VM_TYPE(type) != VM_UNINIT)
struct supplemental_page_table *spt = &thread_current ()->spt;
if (spt_find_page (spt, upage) == NULL) {
struct page *page = malloc(sizeof (struct page));
switch (VM_TYPE(type)) {
case VM_ANON:
uninit_new(page, pg_round_down(upage), init, type, aux, anon_initializer);
break;
case VM_FILE:
uninit_new(page, pg_round_down(upage), init, type, aux, file_backed_initializer);
break;
default:
uninit_new(page, pg_round_down(upage), init, type, aux, NULL);
break;
}
page->writable = writable;
return spt_insert_page(spt, page);
}
err:
return false;
}pintos project3에서 page initializer 핸들러의 코드이다.
우선 page를 uninit 상태로 만든 후, 이 uninit page를 ANON, File_Backed 으로 바꾸는 것이다. pintos 글에도 적어놨듯이 uninit page가 여러가지 형식으로 진화를 하는것이 꼭 포켓몬의 이브이같다.
위의 코드를 적어놓은 이유는 file_backed page가 특별한 페이지가 아닌
그냥 disk의 데이터와 1:1로 연동되는 데이터를 의미한다.
그러니까, 저 uninit을 창고처럼 더미 데이터를 쌓아놓을꺼면 ANON page로,
disk의 데이터를 불러와서 프로세스에서 처리하고 싶다면 File_Backed_Page로 만들면 된다.
