
1.Terraform Provisioner
보통 Terraform 하면 Provider를 통해 매핑되는 자원을 코드로 작성하고 배포하는 작업을 하게된다.
하지만 어떤 경우는 인프라작업 뿐 만 아니라, 배포된 인스턴스 내부에서의 파일 이동 작업, 커맨드, 스크립트 실행, 플러그인 설치 등의 작업이 필요한 경우가 있다.
이 때 사용하는 것이 Provisioner이다.
variable "sensitive_content" {
default = "secret"
#sensitive = true
}
resource "local_file" "foo" {
content = upper(var.sensitive_content)
filename = "${path.module}/foo.bar"
provisioner "local-exec" {
command = "echo The content is ${self.content}"
}
provisioner "local-exec" {
command = "abc"
on_failure = continue
}
provisioner "local-exec" {
when = destroy
command = "echo The deleting filename is ${self.filename}"
}
}
Provisioner는 위와 같이 provisioner로 선언하여 사용하게된다. resource와 다르게, Provisioner로 실행된 결과는 terraform state 파일과 동기화 되지 않으므로 주의해야 한다.
local-exec
terraform이 실행되는 환경에서 수행할 커맨드를 정의
resource "null_resource" "example1" {
provisioner "local-exec" {
command = <<EOF
echo Hello!! > file.txt
echo $ENV >> file.txt
EOF
interpreter = [ "bash" , "-c" ]
working_dir = "/tmp"
environment = {
ENV = "world!!"
}
}
}remote-exec
원격지에서 작업할 내용들을 정의
resource "aws_instance" "web" {
# ...
# Establishes connection to be used by all
# generic remote provisioners (i.e. file/remote-exec)
connection {
type = "ssh"
user = "root"
password = var.root_password
host = self.public_ip
}
provisioner "file" {
source = "script.sh"
destination = "/tmp/script.sh"
}
provisioner "remote-exec" {
inline = [
"chmod +x /tmp/script.sh",
"/tmp/script.sh args",
]
}
}file
file 또는 directory 복사작업에 사용
resource "null_resource" "foo" {
# myapp.conf 파일이 /etc/myapp.conf 로 업로드
provisioner "file" {
source = "conf/myapp.conf"
destination = "/etc/myapp.conf"
}
# content의 내용이 /tmp/file.log 파일로 생성
provisioner "file" {
content = "ami used: ${self.ami}"
destination = "/tmp/file.log"
}
# configs.d 디렉터리가 /etc/configs.d 로 업로드
provisioner "file" {
source = "conf/configs.d"
destination = "/etc"
}
# apps/app1 디렉터리 내의 파일들만 D:/IIS/webapp1 디렉터리 내에 업로드
provisioner "file" {
source = "apps/app1/"
destination = "D:/IIS/webapp1"
}
}2. null_resoure & terraform data
null_resource
아무 작업도 수행하지 않는 리소스 구현할 때 사용한다. 다양한 경우가 있겠지만, K8S를 설치한다고 가정했을 때, resource로 정의되지 않는 작업이나, 데이터 가공, 특정 명령어 수행에 사용된다.
예를 들면 AKS 프로비저닝 시 workload identity를 세팅해줄 때 federation을 생성하는 절차가 있는데, terraform resource에서 지원해주지 않는다.
이럴 때 null_resource를 통해 az aks 커맨드를 날리는 때 사용하기도 했었다.
# Define a null_resource block to run federation configuration scripts
resource "null_resource" "federation" {
triggers = {
aks_cluster_id = azurerm_kubernetes_cluster.example.id
}
provisioner "local-exec" {
command = <<EOT
# Run your federation configuration script here
# Example: kubectl apply -f federation-config.yaml
echo "Running federation configuration..."
EOT
}
}null_resource는 정의된 속성이 id밖에 없다. 따라서 trigger를 통해 뭔가 특정 구성이 변경된 경우 null_resource에 정의된 내용을 강제로 실행할 수 있다.
각 상황에 맞게 trigger 세팅이 필요하다.
terraform_data
1.4 버전부터 null_resource를 대체하는 terraform_data라는게 생겼다. (https://developer.hashicorp.com/terraform/language/resources/terraform-data)
The terraform_data implements the standard resource lifecycle, but does not directly take any other actions. You can use the terraform_data resource without requiring or configuring a provider.
정의를 보면, provider 세팅이 필요없이 built-in provider로 사용이 가능하다고 한다.
null_resource과 terraform_data 차이점을 보면,
null_resource를 코드에 작성 후 terraform init을 하면 아래와 같이 null provider가 생성이되고,
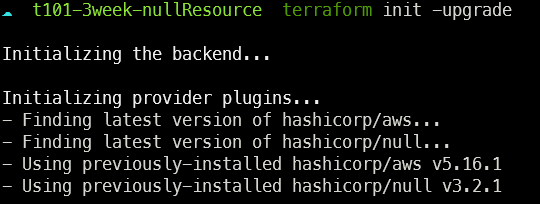
terraform_data 코드 사용 시
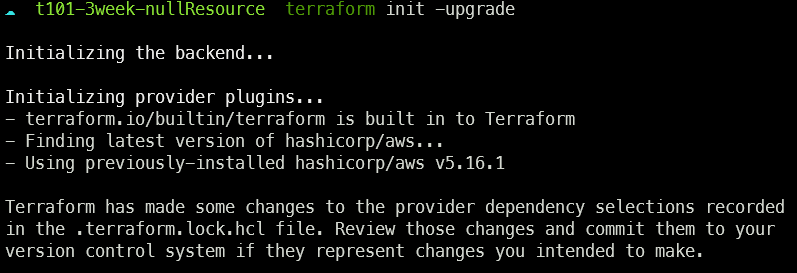
built-in provider를 사용하므로 따로 provider 설치가 안된다. provider 설치 유무에 따라 어떤 성능차이나 이점이 있는지는 정확히 모르겠다..
resource "terraform_data" "foo" {
triggers_replace = [
aws_instance.foo.id,
aws_instance.bar.id
]
input = "world"
}
output "terraform_data_output" {
value = terraform_data.foo.output # 출력 결과는 "world"
}다만 null_resource와 마찬가지로, 상황에 맞게 trigger 세팅을 해줘야 할 필요는 있는데(선택사항), 형식이 trigggers_replace와 같이 조금 다르므로 참고하자.
3. Provider
Terraform 사용 시 보통 AWS, Azure와 같은 CSP에 리소스 배포를 하기위해 쓸텐데, 이때 필요한 것이 각 CSP에 맞는 Provider 이다.
# region 1
provider "aws" {
region = "ap-southeast-1"
}
# region 2
provider "aws" {
alias = "seoul"
region = "ap-northeast-2"
}
resource "aws_instance" "app_server1" {
ami = "ami-06b79cf2aee0d5c92"
instance_type = "t2.micro"
}
resource "aws_instance" "app_server2" {
provider = aws.seoul
ami = "ami-0ea4d4b8dc1e46212"
instance_type = "t2.micro"
}선언은 위와 같이 provider로 선언해주고, 위 예시처럼 region 별로 alias를 통해 지정도 가능한 부분이다.
코드에 선언을 해주면, terraform init 커맨드 수행 시 자동적으로 설치가 된다. 이밖에도 provider 에코시스템이라고 하여, CI/CI, 로깅 모니터링, 자산관리 등의 기능을 제공한다.
개인적으로는 terraform으로 구현된 코드의 비용을 산정해주는 infracost 기능을 사용해보고 싶은데, Run Tasks로 제공되므로 Terraform Cloud/Enterprise에서만 사용 가능한게 조금 아쉽다.
실습예제
Kubernetes Provider 활용
main.tf
terraform {
required_providers {
kubernetes = {
source = "hashicorp/kubernetes"
}
}
}
provider "kubernetes" {
config_path = "~/.kube/config"
}kubernetes.tf
예제코드와 같이, Kubernetes로 provider를 사용하여 관리가 가능하다. 위 예제는 기존에 설치된 Kubernetes의 config 파일을 세팅하고, deplyment, service 자원을 생성하는 예제이다.
resource "kubernetes_deployment" "nginx" {
metadata {
name = "nginx-example"
labels = {
App = "t101-nginx"
}
}
spec {
replicas = 2
selector {
match_labels = {
App = "t101-nginx"
}
}
template {
metadata {
labels = {
App = "t101-nginx"
}
}
spec {
container {
image = "nginx:1.7.8"
name = "example"
port {
container_port = 80
}
}
}
}
}
}
resource "kubernetes_service" "nginx" {
metadata {
name = "nginx-example"
}
spec {
selector = {
App = kubernetes_deployment.nginx.spec.0.template.0.metadata[0].labels.App
}
port {
node_port = 30080
port = 80
target_port = 80
}
type = "NodePort"
}
}보통 Cloud 환경에서는 AKS, EKS를 배포할 때 terraform을 통해 배포하는데, 규모가 어느정도 있는 클러스터의 경우, 네트워크, 보안 등 신경쓸 부분이 많아 Kuberntes 배포용 terraform 코드만 해도 꽤 복잡한 경우가 많다.
개인적인 생각으로 Kubernetes의 경우, 다수의 helm 차트나, yaml 파일 등을 사용하게 되는데, 이와 같이 terraform 코드를 사용하게 되면 유연성에 있어서 조금 문제가 되는 상황이 벌어질 수 있을 것 같다.
Kubernetes 관리자의 경우 yaml, helm chart 형식의 코드에 익숙할텐데, kubernetes, helm provider를 사용하여 관리하게 될 경우, 오히려 난이도가 올라 갈 수 있을 것 같다.
코드를 통한 인프라 관리를 통해 안정성, 인적실수 등을 줄이려면, 보편화된 방법인 ArgoCD를 통한 GitOps 방식이 더 적절해 보인다. (GitOps도 무조건적으로 쓰는 건 좋지 않지만^^)
