
CQS란 (Command Query Seperation)
JPA로 DB에 명령을 보낼 때, 명령의 유형은 두가지로 나뉩니다.
- 조회문
- 생성, 삭제, 업데이트문
조회문은 query문이라고 부르고,
생성, 삭제, 업데이트문은 Command문이라고 부릅니다.
이 두가지 명령은 명확하게 구분되어 있기 때문에,
만약 update문을
Auction auction = auctionService.updateAuction();이렇게 날릴 경우,
Command와 Query를 둘 다 사용하는 것으로 볼 수 있습니다.
이는 CQS 원칙에 위배되는 것입니다.
CQRS란 (command query responsible seperation)
CQRS는 CQS 원칙을 구현해낸 것으로
읽기의 DB와 쓰기의 DB를 분리하는 것입니다.
대부분의 서비스는 Read가 Write보다 많은 부하가 걸립니다.
그렇기때문에 읽기 전용 DB와 쓰기 전용 DB를 분리한다면, 부하를 줄일 수 있게 됩니다.
그럼 쓰기 DB와 읽기 DB의 데이터가 일치하지 않는것 아닌가?
라는 의문이 생길 수 있습니다.
하지만 계속해서 쓰기 DB에서 읽기DB에 replication을 생성하기 때문에 그런 걱정은 안해도 됩니다.
AuroraDB
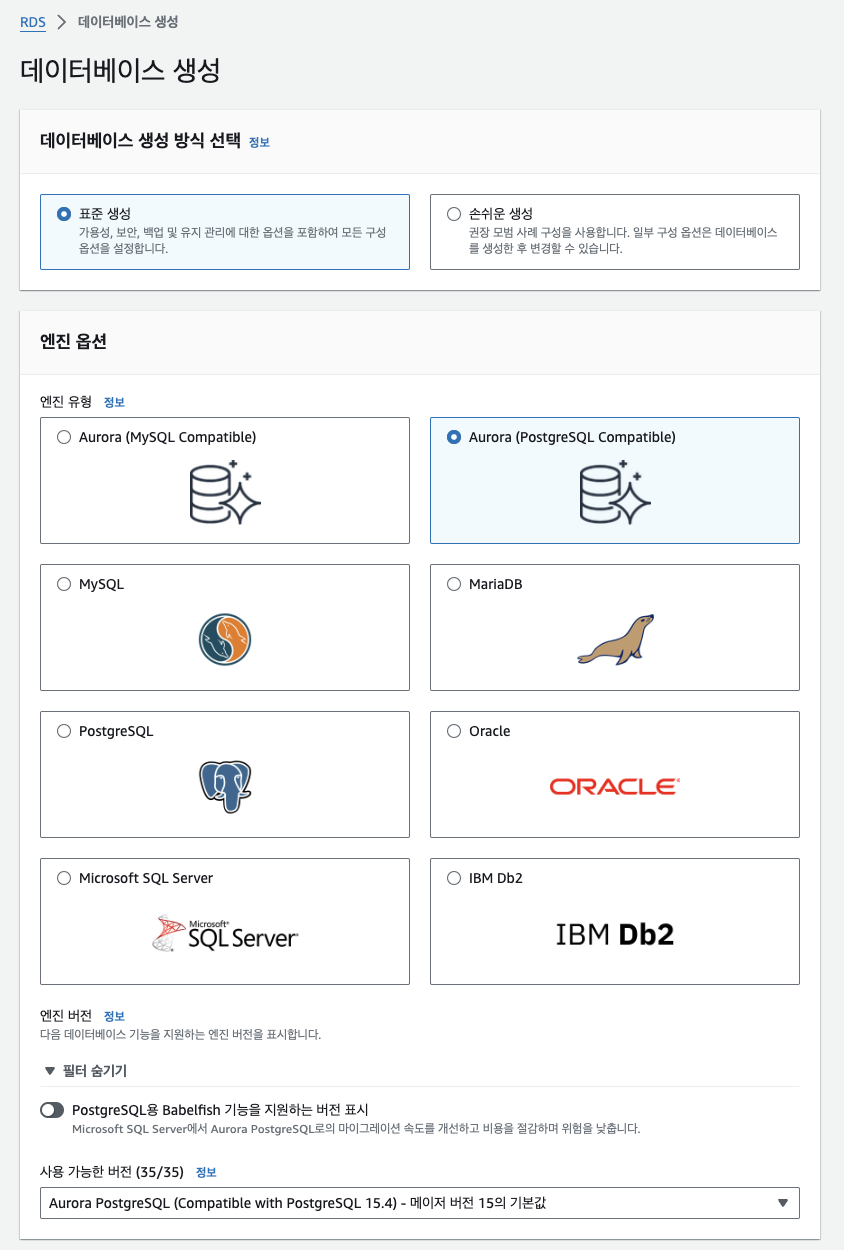
AuroraDB는 AWS RDS에서 지원해주는 데이터베이스로,
Serverless이기 때문에 확장성에 용이하고,
CQRS가 자동으로 구현됩니다.
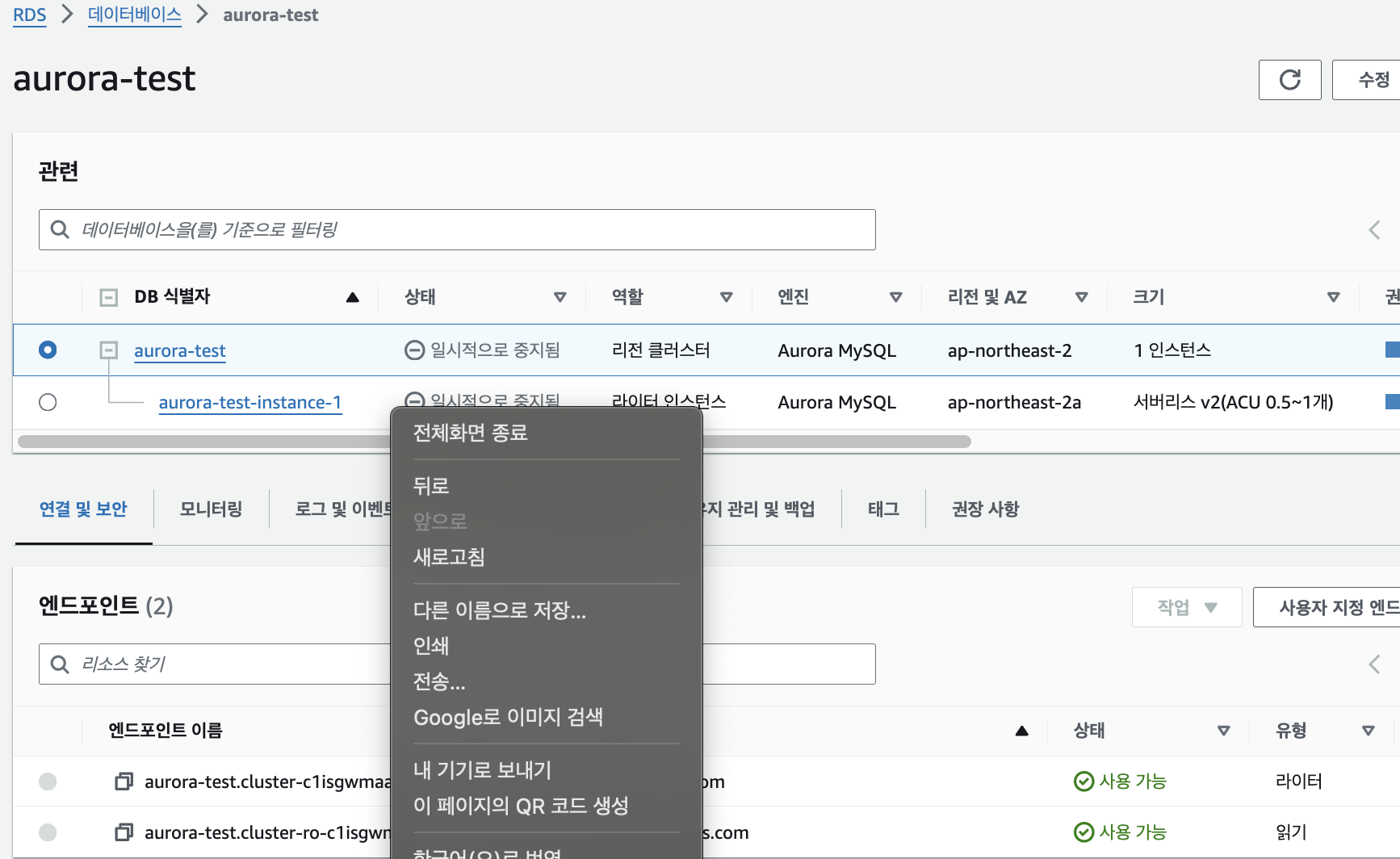
엔드 포인트를 보시면 자동으로 구현된 것을 볼 수 있습니다.
코드 구현
그럼 실제 코드에서는 어떻게 구현될까?
Service layer에서 command service, query service를 분리해서
각자 다른 DB를 참조해도 된다.
하지만 우리는 Transactional ReadOnly 어노테이션이 달린 메소드는 ReadDB에 쿼리를 보내는 방식으로 어노테이션을 구분해서 적용하겠다.
상수 선언
public class AppConstant {
public static final String PRIMARY = "PRIMARY";
public static final String SECONDARY = "SECONDARY";
}primary는 쓰기 DB
secondary는 읽기 DB로 구분해야 하니,
상수로 선언은 해줘서 일치불일치에 사용합니다.
나중에는 이 상수를 enum으로 바꿔줄 계획입니다.
command인지 query인지 구분 class
@Slf4j
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {
@Override
protected String determineCurrentLookupKey() {
String dataSourceName = isCurrentTransactionReadOnly() ? SECONDARY : PRIMARY;
log.info(">>>>>> current data source : {}", dataSourceName);
return dataSourceName;
}
}앞서 말씀드린대로, Transactional이 readonly일 경우, secondary가 datasource가 되게 됩니다.
Config class
@Configuration
@Slf4j
public class DataSourceConfig {
@ConfigurationProperties(prefix = "spring.datasource.hikari.primary")
@Bean
public DataSource primaryDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@ConfigurationProperties(prefix = "spring.datasource.hikari.secondary")
@Bean
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@DependsOn({"primaryDataSource", "secondaryDataSource"})
@Bean
public DataSource routingDataSource(
@Qualifier("primaryDataSource") DataSource primary,
@Qualifier("secondaryDataSource") DataSource secondary
) {
DynamicRoutingDataSource routingDataSource = new DynamicRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(PRIMARY, primary);
dataSourceMap.put(SECONDARY, secondary);
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(primary);
return routingDataSource;
}
@DependsOn({"routingDataSource"})
@Primary
@Bean
public DataSource dataSource(DataSource routingDataSource) {
log.info(">>>>>>>>>>>>>>>???");
return new LazyConnectionDataSourceProxy(routingDataSource);
}
@Bean
public PlatformTransactionManager transactionManager(
EntityManagerFactory entityManagerFactory) {
JpaTransactionManager jpaTransactionManager = new JpaTransactionManager();
jpaTransactionManager.setEntityManagerFactory(entityManagerFactory);
return jpaTransactionManager;
}
}우선 DataSource를 primary와 secondary 두개를 생성해줍니다.
그리고 RoutingDataSource라는 bean에서 map으로 primary와 secondary를 키로 설정해주고,
각 메소드가 자동으로 routing되게 해줍니다.
