
프로그래머스 2021 국민대 여름방학 인공지능 과정 7주차 Day3 TIL
노래 주제 부동의 1위 사랑에 대한 노래인지 아닌지를 분류하는...걸 해보려고 했는뎅...
개망함;_;
📌노가다 라벨링
사랑 노래에 해당하면 1 아니면 0
이게... 맞나?,,,

📌데이터셋 정제하기
데이터 불러오기
lyrics = pd.read_csv("./lyrics.csv")
df_lyric = lyrics[['lyric', 'label']]
df_lyric1. 손수 제거...
- 우우우 랄랄라 같은 후렴구??
- 같은 노래 다른 가수
# 후렴구 제거
df_lyric = df_lyric.drop([i for i in (1985, 1990)])
df_lyric = df_lyric.drop([2016, 2017, 2018])
df_lyric = df_lyric.drop([i for i in (2115, 2133)])
df_lyric = df_lyric.drop([i for i in (2110, 2114)])
df_lyric = df_lyric.drop([2462, 2463])
df_lyric = df_lyric.drop([2482, 2483])
df_lyric2. 중복 행 제거
# 중복 행 제거
df_lyric = df_lyric.drop_duplicates()손수 제거 해주고나서 해주는게 좋을 듯
3. 한 글자 씩 있는 경우 제거
# 한 글자만 있는 행 제거
for i in df_lyric['lyric']:
tmp = i.split(' ')
if len(tmp) <= 1:
df_lyric = df_lyric.drop(df_lyric[df_lyric['lyric']==i].index)
df_lyric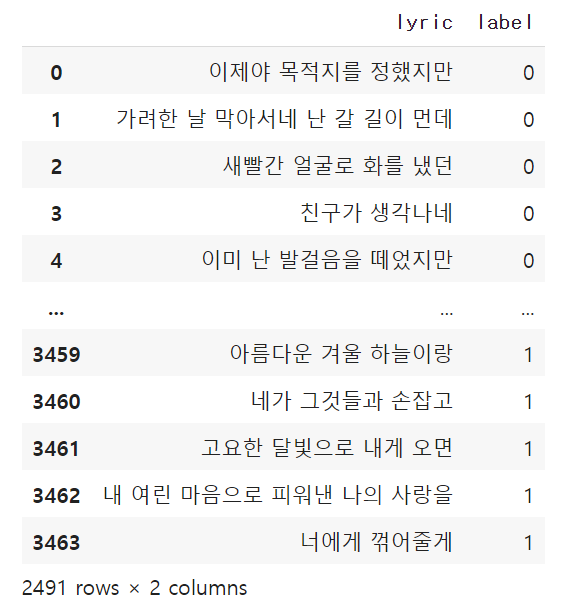
정제 잘 됐나 확인!

굿~
이게... 훈련 데이터가 되는 건가...
같은 방식으로 정제해서 시험 데이터를 만들어준당
📌토크나이징
# 토큰나이징
x_train = []
for lyric in train_data['lyric']:
tmp_x = []
tmp = tokenizer.pos(lyric)
for word, tag in tmp:
if tag in ['Noun', 'Adjective', 'Adverb', 'Verb'] and ("것" not in word) and ("수" not in word) and ("게" not in word):
tmp_x.append(word)
x_train.append(tmp_x)
x_train
시험셋도 마찬가지로~~
📌 정수 인코딩
단어 집합 만들기
# 단어 집합 만들기
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x_train)
tokenizer.word_index
# 단어 집합 크기 확인
vocab_size = len(tokenizer.word_index) 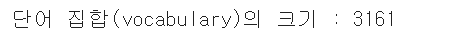
희귀 단어(?) 제외하면 6xx개 정도던데...
이걸 어쩌냐😅
정수 인코딩
텍스트 시퀀스 to 숫자 시퀀스
# text seq to int seq
tokenizer = Tokenizer(vocab_size)
tokenizer.fit_on_texts(x_train)
x_train = tokenizer.texts_to_sequences(x_train)
x_test = tokenizer.texts_to_sequences(x_test)
라벨 따로 저장
# y_train, y_test
y_train = np.array(train_data['label'])
y_test = np.array(test_data['label'])훈련, 시험 셋 csv 파일로 저장
네트워크 아키텍처 정의
model = Sequential()
model.add(Embedding(vocab_size, 128))
model.add(LSTM(128))
model.add(Dense(1, activation='sigmoid'))컴파일 후 학습
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
checkpoint_callback = ModelCheckpoint("best_model.h5",
save_best_only=True,
monitor="val_loss")
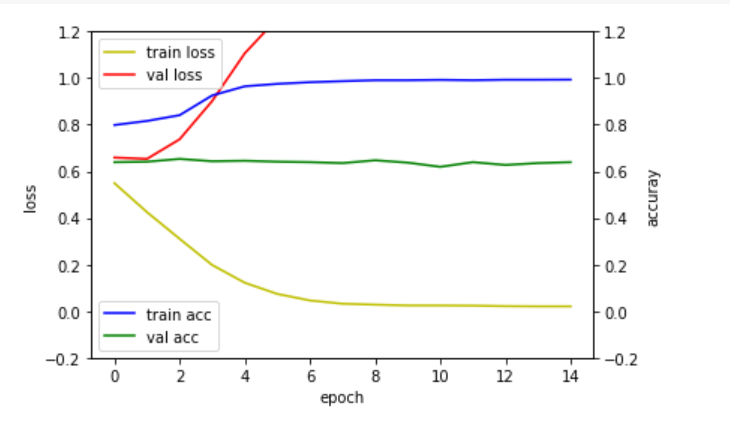
hist = model.fit(x_train, y_train, epochs=15, batch_size=64,
validation_split=0.2,
callbacks=[checkpoint_callback])시각화
테스트 정확도 측정
loaded_model = load_model('best_model.h5')
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(x_test, y_test)[1]))
그냥 허접의 끝이네,,
저장
y_pred = (model.predict(x_test) > 0.5).astype("int32")
np.savetxt('y_pred.csv', y_pred, fmt='%d')❌ 가사 한 줄 씩 했더니 완성된 문장이 아닌 경우가 훨씬 많음
❌ 라벨링이 너무 내맘대로...
❌ 시험셋에서 정제가 살짝 제대로 안 된 것 같다 왜지??
❌ 데이터가 너무.. 적음 너무너무
참고 Data Frame 행 삭제 및 추가 https://blog.naver.com/PostView.nhn?blogId=rising_n_falling&logNo=221629326893
참고 네이버 영화 리뷰 감성분석 https://wikidocs.net/44249
참고 AI factory
진짜 어떡하냐.. 거적데기..만들엇넹..
아 시도했다는게 의미있는거라고~,, 라고 스스로 위안을 해본다

진짜... 오늘만 봐준다...

