
프로그래머스 2021 국민대 여름방학 인공지능 과정 7주차 Day1 TIL
이라고 하겠습니다. 근데 🐶삽질을 곁들인...
📌Melon 웹 페이지 크롤링
먼저 셀레니움이랑 beautifulsoup을 설치했다
pip install selenium
pip install beautifulsoup4크롬 드라이버를 다운 받아 작업하는 파이썬 파일과 같은 위치에 두고 드라이버 연결!
딴 데 두면 경로 설정해줘야 함
import time
import re
import pandas
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 크롬 드라이버 연결
driver = webdriver.Chrome()멜론 페이지 접근
다음 코드로 넘어가기 전에 텀을 좀 놨다 나도 눈으로 봐야하니까
# 멜론 웹 페이지 접근
driver.get('https://www.melon.com/chart/index.htm')
time.sleep(3)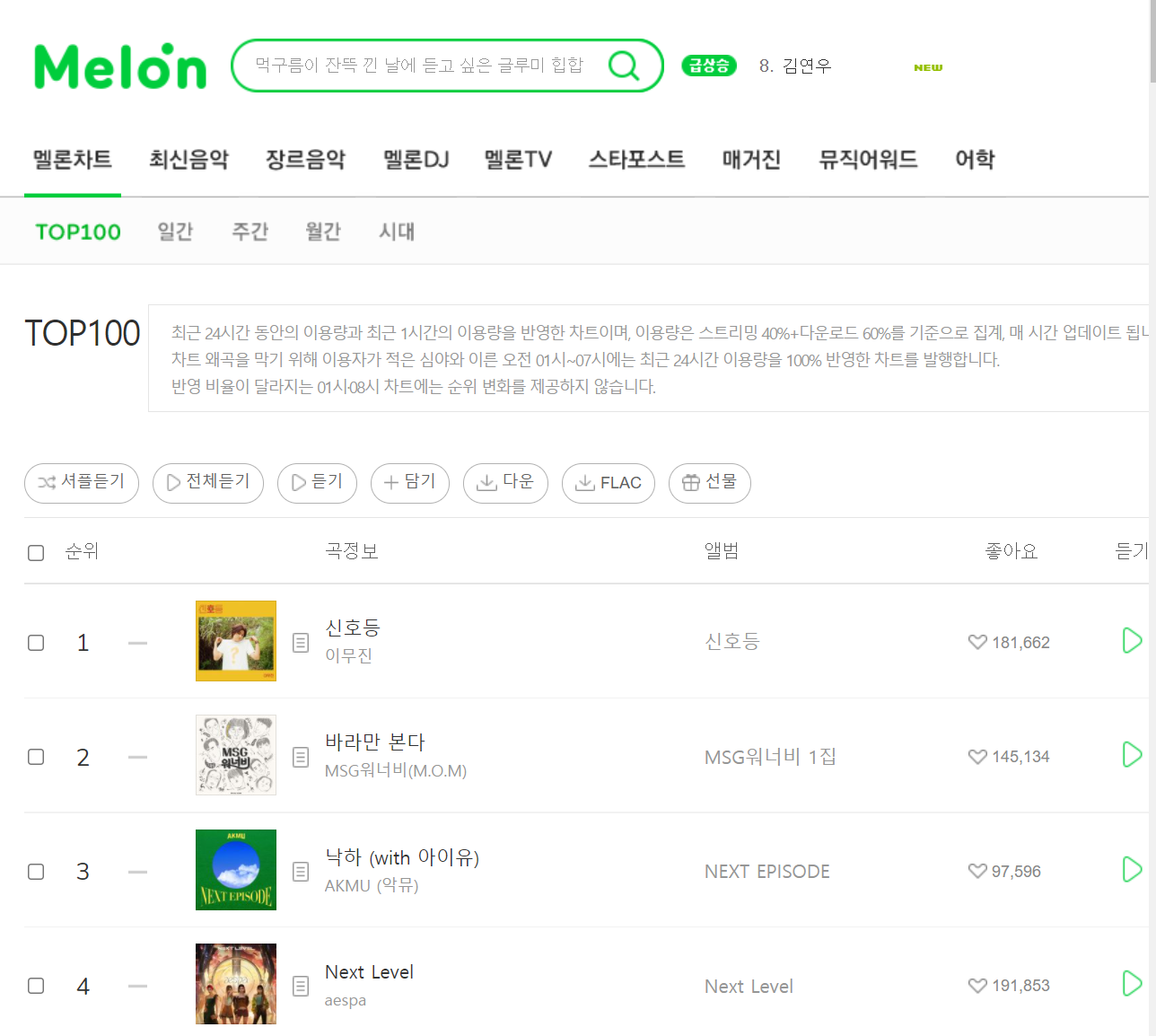
✅ 하나하나 버튼 눌러서 상세페이지 들어가는 것만 생각했는데, url로 상세페이에 바로 접근하는 법이 있음을 뒤늦게 깨달았다😅
태그를 살펴보면 data-song-no 속성이 있다.

이게 상세페이지의 파라미터로 들어감!!

50위까지의 리스트랑 100위까지의 리스트랑 id가 나눠져 있으므로 따로 lst50, lst100 변수에 담아와준다.
get_attribute함수를 이용해 data-song-no에 해당하는 속성값을 추출
# data-song-no를 모으는 리스트
song_num = []
lst50 = driver.find_elements_by_id('lst50')
lst100 = driver.find_elements_by_id('lst100')
for i in lst50:
song_num.append(i.get_attribute('data-song-no'))
for i in lst100:
song_num.append(i.get_attribute('data-song-no'))for문 돌리면서 위에서 모은 data-song-no를 가지고 상세페이지에 직접 접근한다.
craw_lyrics() 함수는 아래에 적을 예정
for i in range(100):
driver.get('https://www.melon.com/song/detail.htm?songId={song_num}'.format(song_num=song_num[i]))
craw_lyrics()
good!
중간 중간에 공백도 제거
# 공백 제거
lyrics = list(filter(None, lyrics))영어 가사도 뺌
upper한거랑 lower한거랑 다르면 영어겠지...!
# 영어 제거
lyrics = list(filter(lambda i: i.upper() == i.lower(), lyrics))✅remove는 첫 번째 값만 삭제한다.ㅎㅎ...,,,,😅
문장 단위로 리스트에 저장하는 함수
implicitly_wait(10) 페이지 로딩을 10초까지 기다려줌
# 가사정보 크롤링 함수
def craw_lyrics():
lyric = driver.find_elements_by_class_name('lyric')
driver.implicitly_wait(10)
lyrics = []
lyrics = lyric[0].text.split('\n')
# 공백 제거
lyrics = list(filter(None, lyrics))
# 영어 제거
lyrics = list(filter(lambda i: i.upper() == i.lower(), lyrics))
for i in lyrics:
all_lyrics.append(i)
print(all_lyrics)데이터 프레임 생성
라벨값은 일단 0으로~,~
df = pd.DataFrame({"lyric": all_lyrics, "label": 0})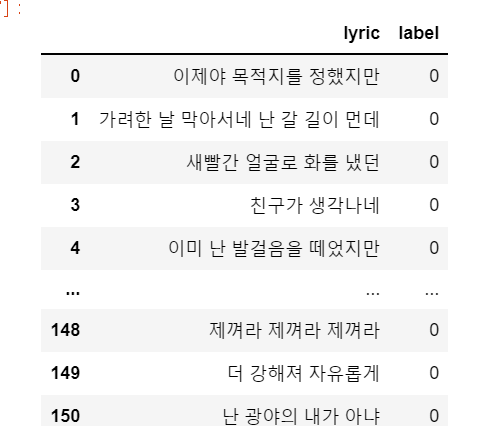
csv 파일로 저장했다.
# csv 파일로 저장
df.to_csv("crawling_melon.csv", encoding='utf-8-sig')
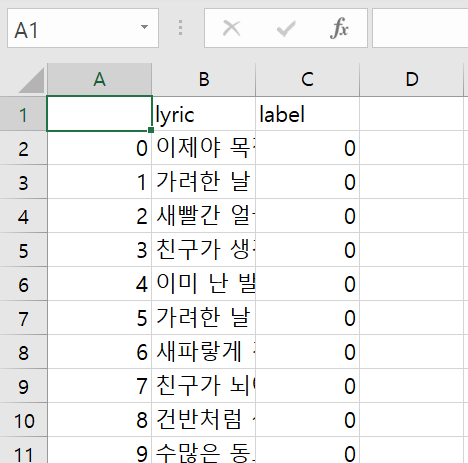
크롤링 첨 해보는데 먼가 신기하긴 한데
엑시던트가 엄청 많았다
사이트도 바이브 -> 멜론 -> 플로 -> 멜론 이렇게 갈아탐ㅎ..
플로 유전데 플로 화나서 멜론으로 갈아탈 뻔~
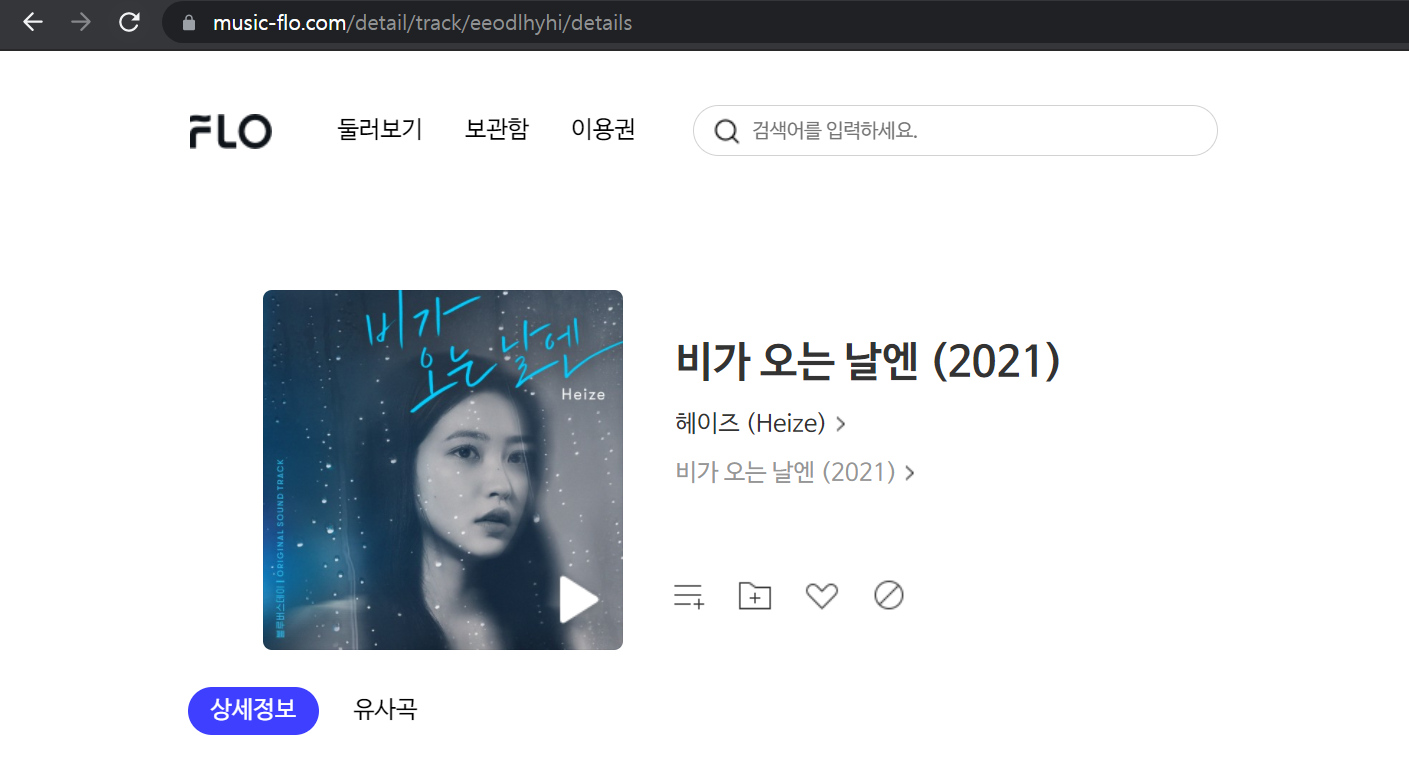
🔽플로
trackId가 key인 줄 알았는데
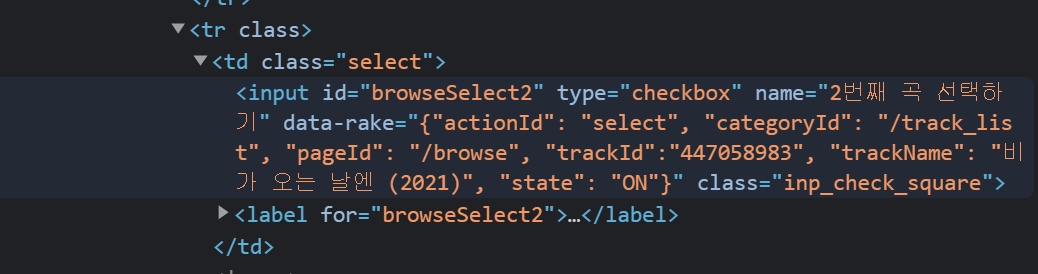
상세페이지 url에는 eeodlhyhi 이런... 알 수 없는 파라미터가 들어가 있었다
도대체 어디서 나온거임?ㅠㅠㅠ
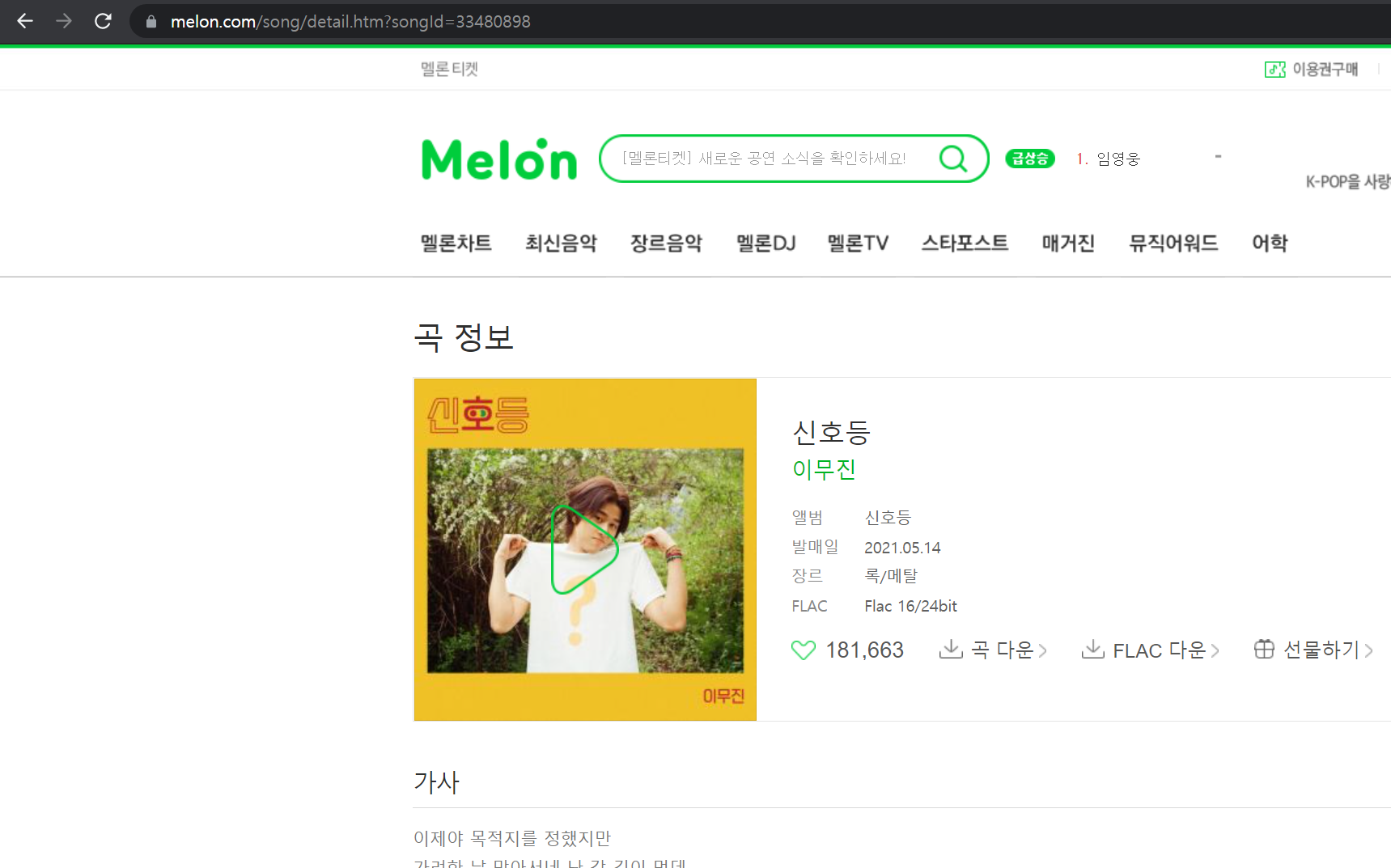
🔽멜론

멜론은 data-song-no가 상세페이지 url 파라미터로 들어가있는데
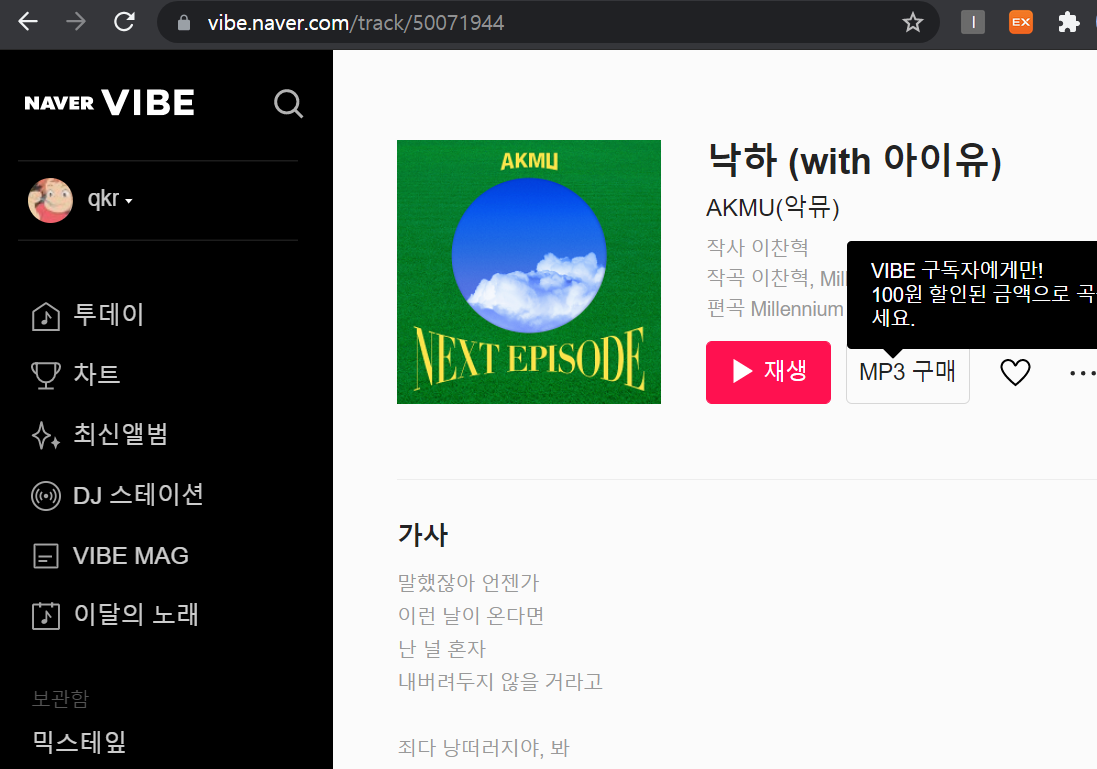
🔽바이브

바이브도 머 Id는 아니더라도 태그에서 url을 발견할 수 있긴하다...
그리고 플로할 때 time.sleep을 지정 안 해주면 로딩이 못 따라간다그래야되나... 암튼 엘리먼트가 생성되기 전에 엘리먼트를 찾으려고해서 에러가 자꾸 났었다,,
결론 가사 크롤링할라면 그냥 멜론..해야겠다... 젤 편한 듯...
플로로 삽질 겁나하다가 멜론으로 갈아타니까 넘 ez하게 돼서 눈물을..ㅎ.ㅡㄹㄹㅆ다..
참고 멜론 차트 크롤링 https://m.blog.naver.com/dh3508/221816555132
참고 정규표현식 데이터 전처리 https://codingspooning.tistory.com/138
참고 Implicitly wait https://codechacha.com/ko/selenium-explicit-implicit-wait/
참고 빈 문자열인 요소 제거 https://jinmay.github.io/2019/06/30/python/python-how-to-delete-empty-string-in-list/
참고 파이썬 필터함수 https://www.daleseo.com/python-filter/
참고 How to read CSV File into Python using Pandas https://towardsdatascience.com/how-to-read-csv-file-using-pandas-ab1f5e7e7b58
