
프로그래머스 2021 국민대 여름방학 인공지능 과정 4주차 Day5 TIL
🔍오버피팅
훈련셋을 가지고 훈련을 너무 많이 할 경우, 훈련셋에 대해서는 오차가 매우 작아지지만 다른 데이터셋에 대해서는 오차가 커지는 현상 과대적합
✅ 오차가 클 수록 손실값이 커진다
오버피팅을 알아내기 위해서 검증하는 과정이 필요하다!
훈련셋으로 훈련을 하고 검증셋으로 검증을 한다.
훈련을 할 때는 가중치를 가지고 학습을 하는 과정이 일어나지만
검증에서는 학습하는 과정이 일어나지 않음! 정말 검증만 함
validation_split을 설정해주어 훈련셋 중 일부(0.2 = 20%)를 검증셋으로 지정할 수 있음.hist = model.fit(x_train, y_train, validation_split=0.2, batch_size=32, epochs=100)
검증셋으로 학습 중단 시점을 결정할 수 있다.
검증셋의 손실값이 최솟값일 때 학습을 중단해야 오버피팅되지 않은 모델을 구할 수 있다.
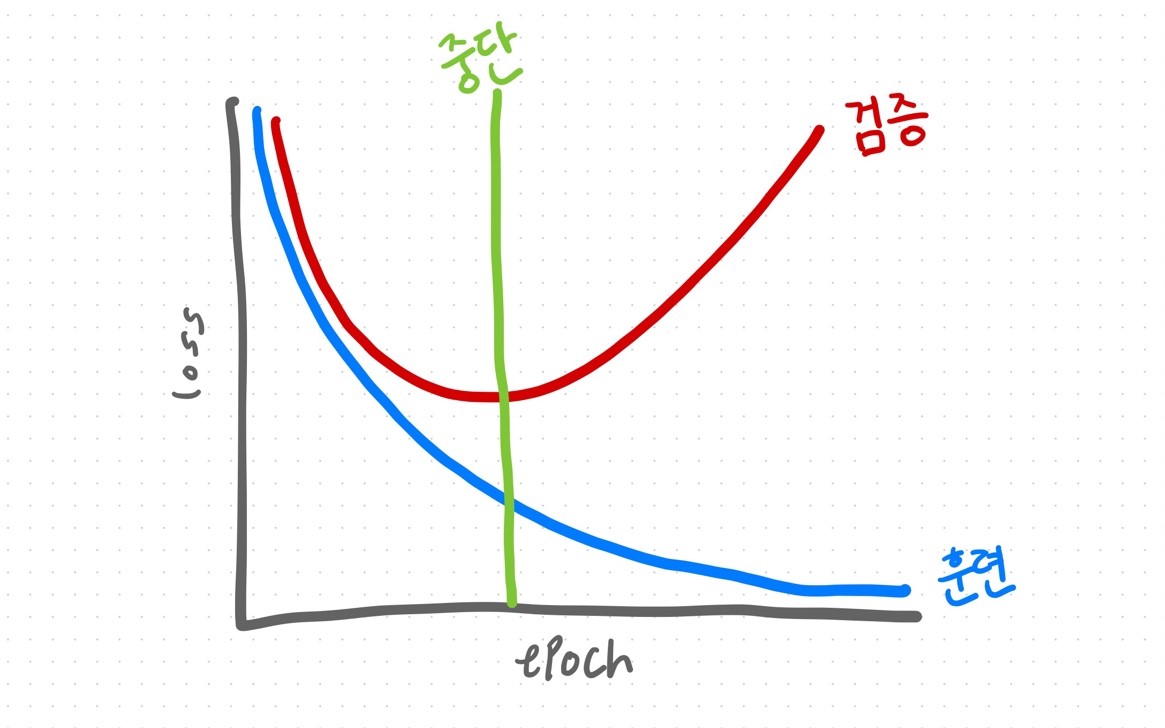
오버피팅되지 않은 모델을 구하는 방법
-
오버피팅이 일어나는 것을 확인 후, 오버피팅이 일어나기 전 에포크만큼 처음부터 다시 모델을 학습시킴
✅ 과정을 두 번 해야 함. -
오버피팅을 감지(콜백함수)하면 학습을 중단시킴
✅ 학습을 더 할 수 있는데 중단되어버릴 수 있음. -
매 에포크마다 검증셋의 손실값을 체크(콜백함수)하고 이전 검증셋의 손실값보다 적은 경우에 저장함
3번째 방법 -> 손실값이 가장 적은 모델을 파일로 저장하는 콜백함수 지정
checkpoint_callback = ModelCheckpoint("best_model.h5", save_best_only=True, monitor="val_loss")
hist = model.fit(x_train, y_train, validation_split=0.2, batch_size=32, epochs=100, callbacks=[checkpoint_callback])
✅ 이러한 오버피팅은 훈련셋의 수가 충분하지 않은 경우에 잘 일어나므로 많은 데이터를 수집해야 한다
✅ 정확성과 손실값이 반비례관계는 아님
코드 AI factory
학습을 반복적으로 너무 많이 했을 때 오버피팅이 되는 그래프를 보면서 내가 수능공부를 할때 모의고사에 오버피팅해가지고 그렇게....그렇게..그랬던건가...라는 생각을 잠.깐.했다.ㅋㅋㅋㅠㅠㅋㅋㅋㅠㅋㅋㅋㅋㅋ
뭐 클론코딩만 계속...하면 발전없는것도 같은 맥락 아닌가라는...
훈련시키는 만큼 똑똑해지는 줄 알았는데 그건 아니라니 신기했당.
정확성과 손실값이 반비례할거라고 생각했는데 그래프보니까 그건 또 아니다. 흠
아무 사이도 아니..?ㄹ수있나?... 이건 몰겠다. 찾아봐야지
