
1.뷰(VIEW) 란?
- SQL에서 view는 SQL 쿼리의 결과 셋을 기반으로 만들어진 일종의 가상 테이블이다.
- 뷰는 접근 단순화 & 보안을 높이는 데 필요하다.
2.뷰 사용 목적 및 특징
- DB에서 선택적으로 데이터를 보여줌으로써 DB접근 제한 가능
- 복잡한 질의로부터 결과를 검색하기 위한 단순한 질의를 만들수 있음
- 조인을 한것처럼 여러 테이블에 대한 테이터를 뷰를 통해 볼 수 있음
3.뷰 작성
-- sys -- GRANT CREATE VIEW TO scott; -- scott -- CREATE VIEW emp_view AS SELECT empno, ename, sal, hiredate FROM emp WHERE empno = 10;
작성한 뷰 확인
SELECT view_name FROM user_views;
뷰를 수정하려면 CREATE OR REPLACE 사용
CREATE OR REPLACE VIEW emp_view AS SELECT e.empno, e.ename, d.dname, d.deptno FROM emp e JOIN dept d ON e.deptno = e.deptno WHERE e.deptno = 20;
뷰에서 함수 사용 시 반드시 결과값에 별칭을 부여해야 함
CREATE VIEW emp_view4 AS SELECT deptno, SUM(sal) 총합 -- 함수 사용 시 반드시 결과값에 별칭을 부여 FROM emp GROUP BY deptno;
뷰에서 DML을 사용하면 원본 테이블에도 적용됨
DELETE FROM emp_view5 WHERE deptno = 20;
뷰 제거
DROP VIEW dept_view;
2.시퀀스(SEQUENCE) 란?
- 시퀀스(SEQUENCE): 여러 사용자들이 공유하는 DB객체로서, 호출될 때마다 중복되지 않은 고유한 숫자를 리턴함
- 기본키 컬럼에 사용할 값을 발생시키는 데 주로 사용함
시퀀스 작성
CREATE SEQUENCE emp_seq INCREMENT BY 1 START WITH 100 MAXVALUE 9999 NOCACHE NOCYCLE; SELECT sequence_name FROM user_sequences; -- 만든 시퀀스 확인
시퀀스 사용
-
NEXTVAL: 지정된 시퀀스에서 순차적인 시퀀스 번호 추출
- 시퀀스명.NEXTVAL
-
CURRVAL: 방금 추출한 시퀀스 번호 참조
- 시퀀스명.CURRVAL
- 반드시 NEXTVAL로 번호를 추출한 후에 사용해야 함
SELECT emp_seq.NEXTVAL, emp_seq.CURRVAL FROM dual;
테이블에 시퀀스 사용
CREATE TABLE dept06 (deptno NUMBER(4) PRIMARY KEY, dname VARCHAR2(15), loc VARCHAR2(15)); CREATE SEQUENCE dept_deptno_seq4 START WITH 10 INCREMENT BY 10 NOCACHE; INSERT INTO dept06 VALUES (dept_deptno_seq4.NEXTVAL, '개발', '서울'); INSERT INTO dept06 VALUES (dept_deptno_seq4.NEXTVAL, '인사', '경기'); SELECT * FROM dept06; -- 10 개발 서울 -- 20 인사 경기
시퀀스 삭제
DROP SEQUENCE dept_deptno_seq4;3.인덱스(INDEX) 란?
-
인덱스는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
-
SELECT 구문을 통해 데이터를 조회하려는 테이블이 너무 거대한 경우, 정렬되지 않은 모든 데이터를 순차적으로 검색(Full Scan)하면 조회 결과를 구하기까지 오랜 시간이 걸립니다.
-
어떤 데이터가 어디에 위치해있는지에 대한 정보를 책의 목차처럼 인덱스라는 것으로 저장해 검색 시에 활용하면 검색 성능을 높일 수 있습니다.
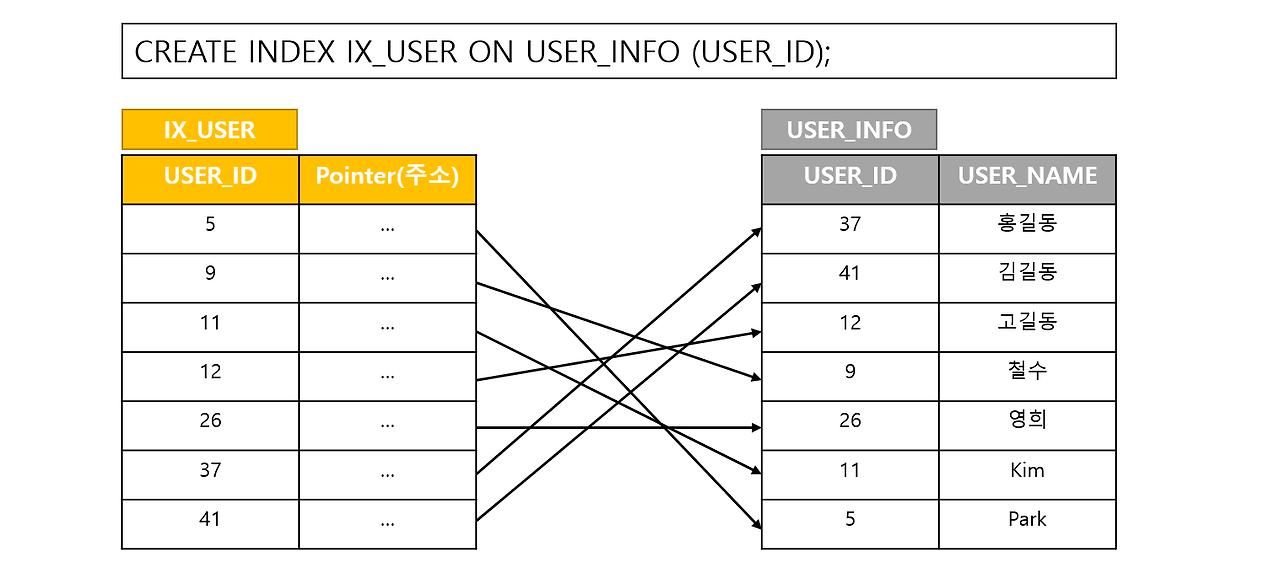
인덱스의 장점
- 테이블의 조회 속도를 향상시킬 수 있습니다.
- 전반적인 시스템의 부하를 줄일 수 있습니다.
인덱스의 단점
-
인덱스를 저장하기 위해 DB의 약 10%에 해당하는 저장공간을 사용해야 합니다.
-
수정이 빈번한 속성에 인덱스를 사용할 경우 성능이 오히려 저하될 수 있습니다.
-
인덱스를 관리하기 위한 추가 작업이 필요합니다.
-
인덱스는 항상 데이터를 빠르게 검색하기 위해 가장 최근 버전 데이터들이 정렬된 상태로 유지되어야 합니다. 즉, 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELTE가 수행된다면 원본 테이블 뿐만 아니라 인덱스에도 다음과 같이 추가 작업을 수행해줘야 합니다.
- INSERT: 새로운 데이터를 인덱스에 추가합니다.
- DELETE: 삭제할 데이터의 인덱스를 사용하지 않는다고 처리합니다.
- UPDATE: 기존 인덱스를 사용하지 않는다고 처리하고, 갱신된 데이터에 대한 인덱스를 추가합니다.
인덱스를 작성할 필요가 없는경우
- 테이블이 작을때
- 쿼리문의 조건에 자주 사용되지 않는 컬럼
- 테이블이 자주 변경될때
- 대부분의 쿼리문이 전체 데이터의 2~4% 이상을 검색하는 경우
- 인덱스가 작성된 컬럼이 조건의 표현식(함수, not 등)에 포함된 경우
그렇다면 인덱스를 사용하기 좋은 컬럼은?
1. INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
2. JOIN, WHERE, ORDER BY에 자주 사용되는 컬럼
3. 데이터의 중복도가 낮은 컬럼
4. 전체 데이터 중 10 ~ 15% 이하의 데이터를 처리하는 경우
인덱스가 자동 생성되는 경우
- PRIMARY KEY, UNIQUE 제약조건 지정 시 UNIQUE INDEX가 자동 생성됨
- 수동 생성: non-unique 인덱스/ unique 인덱스
- 한 개의 컬럼이나 여러 컬럼(복합 인덱스)을 이용해 인덱스 생성 가능
인덱스 예제
SELECT * FROM emp WHERE ename = 'SMITH'; -- 0.055초
CREATE INDEX emp_ename_idx ON emp(ename);
SELECT * FROM emp WHERE ename = 'SMITH'; -- 0.025초