개요
- 논문리뷰를 진행하게 되면서, 논문 하나에 대한 리뷰를 작성할 때마다 목차를 작성하는 과정이 번거롭다고 느끼게 되었다.
- 이에 목차를 리뷰 시작 전 목차를 미리 작성한 뒤, 이를 리뷰작성에 형식으로 자동으로 변환하는 코드를 작성하게 되었다.
- velog의 경우 오른쪽에 인덱스 기능을 제공하지만, '#'을 강조기능으로 사용할 경우 인덱스가 깔끔하지 않게 생성되는 문제가 있어 아래와 같은 방법을 구상하게 되었습니다.
- 링크: https://github.com/LeeKunHa/Paper_study/blob/main/Index%20Generator.ipynb
1. generate_anchor_link
- 목차-마크다운 제목 연결
(코드)
 (결과)
(결과)
2. generate_markdown_headers
- 마크다운 제목 생성
(코드)
 (결과)
(결과)
3. 적용 결과
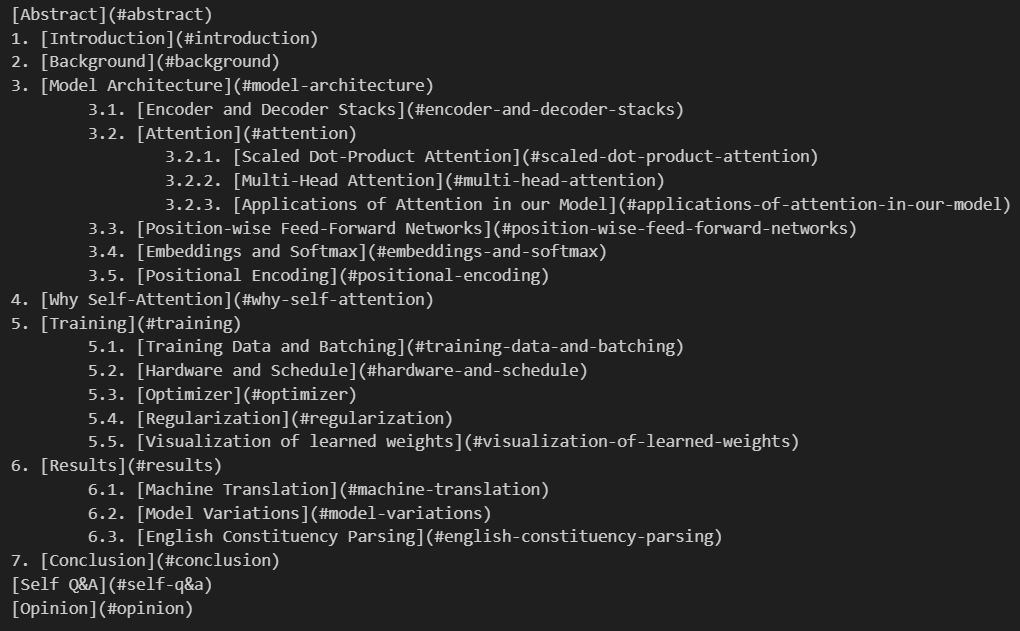
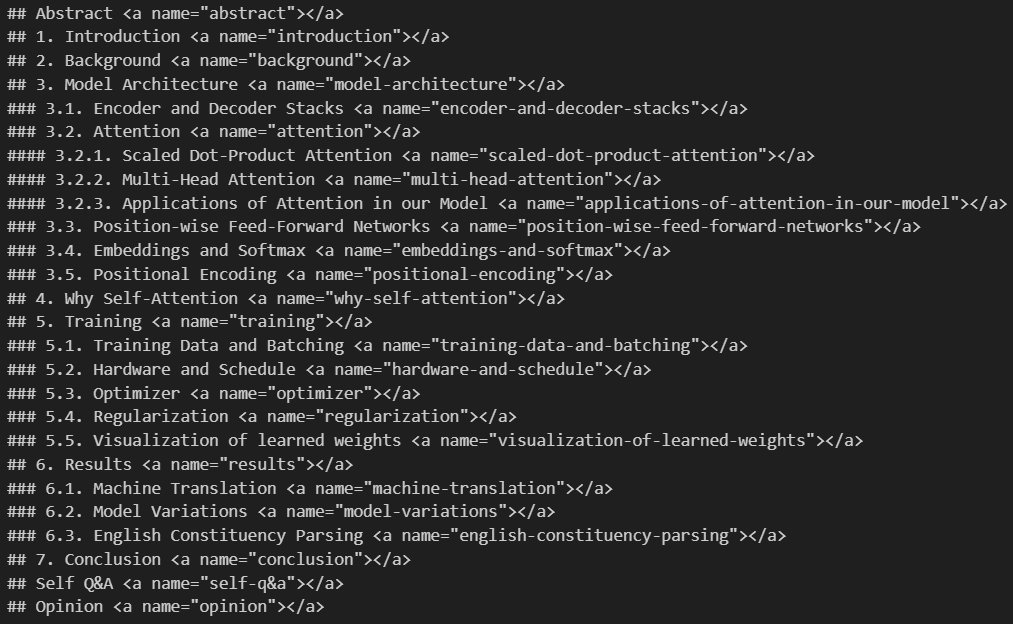
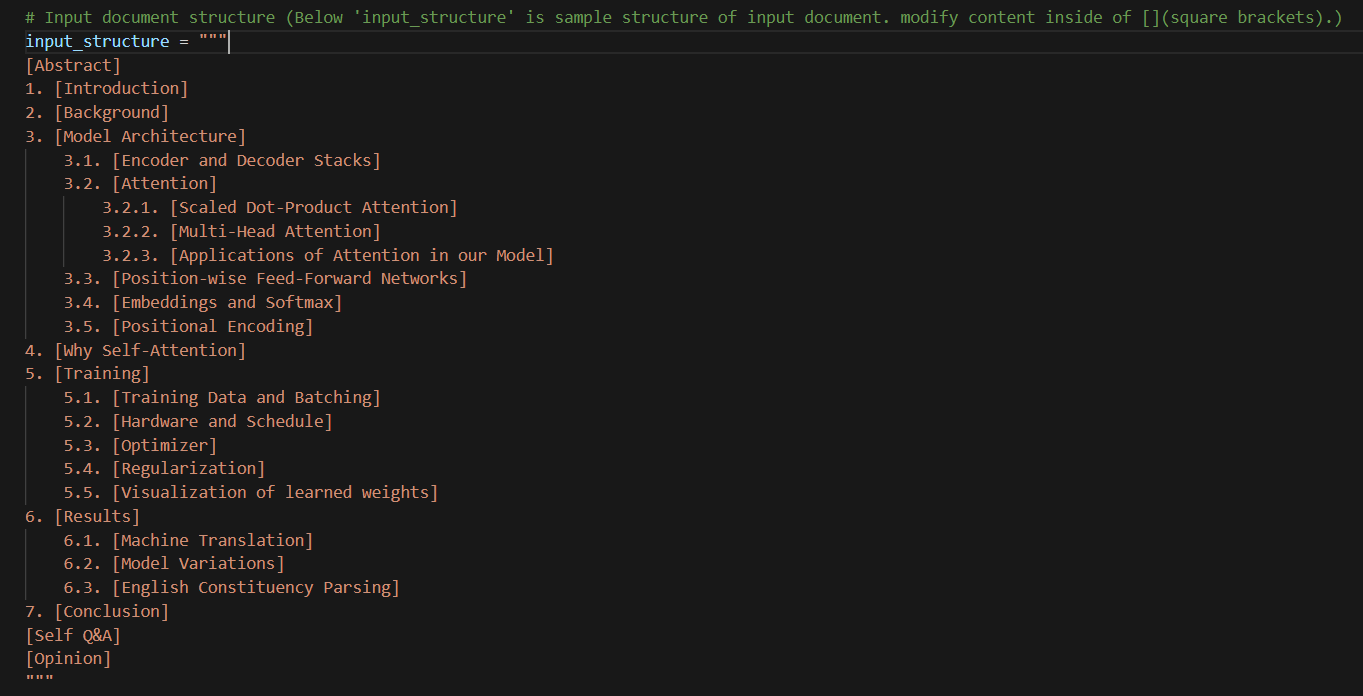
3.1 입력(input) 형태 - 예시: "Attention is all you need"
- ('[]' 안의 텍스트를 수정해서 사용)
- (단계에 따른 \t(들여쓰기) 적용)
3.2 출력(output) 결과
Abstract
1. Introduction
2. Background
3. Model Architecture
3.1. Encoder and Decoder Stacks
3.2. Attention
3.2.1. Scaled Dot-Product Attention
3.2.2. Multi-Head Attention
3.2.3. Applications of Attention in our Model
3.3. Position-wise Feed-Forward Networks
3.4. Embeddings and Softmax
3.5. Positional Encoding
4. Why Self-Attention
5. Training
5.1. Training Data and Batching
5.2. Hardware and Schedule
5.3. Optimizer
5.4. Regularization
5.5. Visualization of learned weights
6. Results
6.1. Machine Translation
6.2. Model Variations
6.3. English Constituency Parsing
7. Conclusion
Self Q&A
Opinion
