프로그래머스 SQL 고득점 KIT 내 SUM,MAX,MIN
Level 2. 연도별 대장균 크기의 편차 구하기
분화된 연도(YEAR), 분화된 연도별 대장균 크기의 편차(YEAR_DEV), 대장균 개체의 ID(ID) 를 출력하는 SQL 문을 작성해주세요. 분화된 연도별 대장균 크기의 편차는 분화된 연도별 가장 큰 대장균의 크기 - 각 대장균의 크기로 구하며 결과는 연도에 대해 오름차순으로 정렬하고 같은 연도에 대해서는 대장균 크기의 편차에 대해 오름차순으로 정렬해주세요.
문제 끊어 읽기
SELECT
분화된 연도 YEAR,
분화된 연도별 대장균 크기의 편차 YEAR_DEV,
ID 출력
FROM
ECOLI_DATA
ORDER BY
YEAR, YEAR_DEV
조건
1. 분화된 연도 YEAR
DIFFERENTIATION_DATA 에서 연도 추출
2. 분화된 연도별 대장균 크기의 편차 AS YEAR_DEV
DIFFERENTIATION_DATA 연도 추출 - 연도별
MAX 가장 큰 SIZE_OF_COLONY
각 대장균의 크기 SIZE_OF_COLONY
WHEN절 사용?
GORUP BY 사용?
서브쿼리 사용?
윈도우함수사용?
어떤 함수를 써야하는지 판단하는 요령
1. 내가 원하는 데이터는 개별행인가? 그룹데이터인가?
-
개별행 데이터 =
윈도우함수 (OVER()) -
그룹별로만 요약된 한줄 데이터 =
GROUP BY -
다른 테이블 OR 같은 테이블의 특정값 갖고오기 =
JOINWHERE
2. 어떤 계산이 필요한가?
-
같은 그룹 내 각 행마다 비교 또는 계산
윈도우함수 (OVER()): 개별행이 유지된 채, 같은 그룹의 다른 값과 비교한다.
EX. 각 행마다 연도별 최대값과 비교 -
단순 그룹별 요약값이 필요
GROUP BY:SUM()COUNT()AVG()MAX()등 집계함수로 집계하고, 개별행이 필요 없는 경우.
EX. 연도별 대장균의 평균 크기 -
어떤 값을 찾기 위해 테이블을 한번 더 조회하는 경우.
서브쿼리 (JOIN OR WHERE)
EX. 이 개체의 부모 크기 갖고오기
3. 문제에서 핵심적으로 비교하는 값은?
3-1. 같은 그룹 내의 값과 비교하는가? = OVER(PATITION BY())
- 각 행마다 같은 연도의 최대값과 비교해야한다.
(연도별 최대 크기 / 개별 크기)
3-2. 특정한 그룹끼리 합산 = GROUP BY
- 연도별 개체수를 세어라. ->
COUNT(*) GROUP BY YEAR
3-3. 다른 행에서 특정 값을 가져옴 = 서브쿼리 - JOIN
- 이 개체의 부모 개체의 크기를 찾아라. ->
JOIN또는WHERE(SELECT...)서브쿼리
4. 조건이 WHERE에 들어가나, HAVING에 들어가나?
-
각 행을 기준으로 조건을 건다 -
WHERE
EX. SIZE_OF_COLONY가 50 이상인 개체만 출력해라. -
집계된 값(그룹별 최댓값, 합계 등)에 조건을 건다 -
HAVING
EX. 연도별 개체수가 10개 이상인 연도만 출력해라.
다시 문제 함수 선택하기.
[각 행마다 연도별 최대값과 비교해야함]
SELECT
분화된 연도 YEAR,
분화된 연도별 대장균 크기의 편차 YEAR_DEV,
ID 출력
FROM
ECOLI_DATA
ORDER BY
YEAR, YEAR_DEV
적용
1. 연도별 가장 큰 대장균 크기 - 개별 대장균 크기 구하기
- 개별행 유지 =
윈도우 함수 OVER - 각 연도별 최대 크기 비교 =
OVER(PARTITION BY()) - 연도별 최대 크기 =
MAX(SIZE_OF_COLONY) OVER(PARTITON BY)
정답
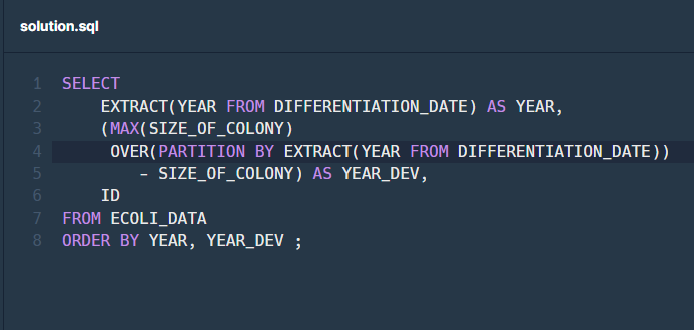
SELECT EXTRACT(YEAR FROM DIFFERENTIATION_DATE) AS YEAR, (MAX(SIZE_OF_COLONY) OVER(PARTITION BY EXTRACT(YEAR FROM DIFFERENTIATION_DATE)) - SIZE_OF_COLONY) AS YEAR_DEV, ID FROM ECOLI_DATA ORDER BY YEAR, YEAR_DEV ;
추가로 GROUP BY, 서브쿼리 JOIN 비교
- 연도별로 개체의 평균 크기 구하기.
SELECT EXTRACT(YEAR FROM DIFFERENTIATION_DATE) AS YEAR,
AVG(SIZE_OF_COLONY) AS AVG_SIZE
FROM ECOLI_DATA
GROUP BY EXTRACT(YEAR FROM DIFFERENTIATION_DATE);#그룹별 집계가 필요 = GROUP BY
- 각 개체의 부모 개체의 크기와 비교해서 얼마나 큰지 작은지 비교해서 출력하기.
SELECT
E1.ID,
E1.SIZE_OF_COLONY,
E2.SIZE_OF_COLONY AS PARENT_SIZE,
CASE
WHEN E1.SIZE_OF_COLONY > E2.SIZE_OF_COLONY THEN 'LARGER'
ELSE 'SMALLER'
END AS SIZE_COMPARE
FROM ECOLI_DATA E1
JOIN ECOLI_DATA E2
ON E1.PARENT_ID = E2.ID;#다른 행에서 데이터를 가져옴 = JOIN
