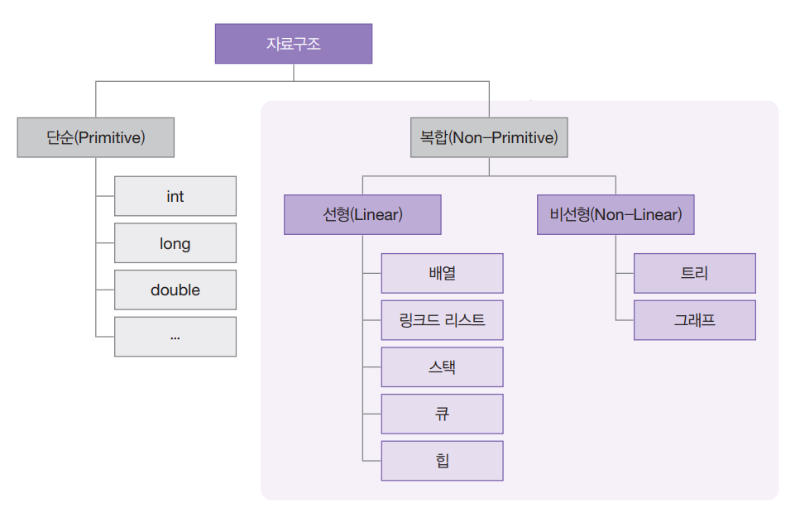
자료구조는 데이터를 효율적으로 저장하고 관리하는 방법이다.
배열
배열은 일정한 메모리 공간을 차지하는 여러 요소들이 순차적으로 나열된 자료구조이다. 배열은 인덱스를 통해 특정 요소에 접근할 때 의 시간 복잡도가 소요된다. 그러나 요소를 삽입하거나 삭제할 때에는 모든 요소들의 재정렬이 이루어져야 하기 때문에 이 때의 시간 복잡도는 만큼 소요된다.
연결 리스트
연결 리스트는 노드의 모음으로 구성된 자료구조이다. 여기서 노드란, 저장하고자 하는 데이터와 다음 노드의 위치 (메모리 상의 주소) 정보를 포함하는 연결 리스트의 구성 단위를 의미한다. 그렇기 때문에 특정 노드에 접근하면 그 다음 노드의 데이터에도 접근할 수 있다. 이렇듯 노드들이 꼬리에 꼬리를 무는 형태로 구성되어 있고, 첫 번째 노드를 헤드(head), 마지막 노드를 꼬리(tail)라고 부른다. 연결 리스트를 구성하는 노드들은 메모리 내에 순차적으로 저장되어 있을 필요가 없기 때문에, 연속적으로 구성되어 있는 데이터를 불연속적으로 저장할 때 유용하게 사용할 수 있다.
특정 요소에 접근할 때 배열과는 달리 앞에서부터 순차적으로 접근할 수 밖에 없기 때문에 의 시간 복잡도가 소요된다. 그러나 요소를 삽입하거나 삭제할 때에는 재정렬이 필요하지 않기 때문에 의 시간 복잡도가 소요된다.
싱글 연결 리스트
싱글 연결 리스트는 다음 노드의 위치 정보만 저장되어 있는, 단방향 리스트이다.
이중 연결 리스트
이중 연결 리스트는 단방향으로만 탐색이 가능한 싱글 연결 리스트의 단점을 보완하고자, 노드 내에 다음 노드의 위치 정보 뿐만 아니라 이전 노드의 위치 정보까지 포함시킨 리스트이다. 양방향 탐색이 가능하지만, 그만큼 저장 공간이 더 필요하다.
원형 연결 리스트
원형 연결 리스트는 꼬리 노드가 헤드 노드를 가리켜 노드들이 원형으로 구성된 연결 리스트이다. 모든 노드 데이터를 여러 차레 순회해야 할 때 유용하게 활용할 수 있다.
스택

스택(stack)은 한 쪽에서만 데이터의 삽입 및 삭제가 가능한 자료 구조를 말한다. stack이라는 이름에서 알 수 있듯이 물건을 쌓은 모습을 연상하면 쉬운데, 물건이 쌓여있다면 가장 마지막에 쌓은 물건은 가장 먼저 빼낼 수 있고, 처음에 둔 물건은 다른 물건들을 다 빼고 난 마지막에서야 빼낼 수 있을 것이다. 따라서 스택을 LIFO (Last In First Out; 후입선출) 구조라고도 한다.
스택에 데이터를 저장하는 연산은 push, 데이터를 빼내는 연산은 pop이라고 한다. 파이썬에서는 리스트를 이용해 스택을 구현할 수 있다.
stack = []
# push
stack.append(5)
stack.append(4)
stack.append(3)
# pop
stack.pop() # 가장 마지막에 넣은 3이 반환된 후 stack에서 사라진다최근에 임시 저장한 데이터를 가장 먼저 활용해야 하는 상황에서 유용하며, 예시로는 함수의 매개 변수를 저장하기 위한 상황을 들 수 있다. 함수의 호출 과정을 살펴보면, 최근에 호출된 함수의 매개 변수가 먼저 활용되고 메모리에서 가장 먼저 삭제된다. 인터넷 브라우저의 뒤로 가기 기능도 스택이 사용되는 경우라 할 수 있다. 웹사이트를 방문할 때마다 스택에 URL이 저장되고, 뒤로 가기 버튼을 누를 때 마다 가장 최근에 방문한 페이지 순으로 URL을 빼내어 이동하는 것이다.
큐

큐(queue)는 한 쪽으로 데이터를 삽입하고, 다른 한 쪽으로 데이터를 삭제할 수 있는 자료 구조이다. 따라서 먼저 넣은 데이터를 먼저 빼낼 수 있기 때문에 FIFO (First In First Out; 선입선출) 구조라고 부른다. 큐의 한쪽 끝에 데이터를 삽입하는 연산을 인큐(enqueue), 다른 한 쪽 끝으로 데이터를 빼내는 연산은 디큐(dequeue)라고 부른다.
큐는 임시 저장된 데이터를 차례로 내보내거나 꺼내와야 하는 buffer로 활용된다.
큐는 다양한 변형 형태가 있다.
원형 큐
데이터를 삽입하는 쪽과 삭제하는 쪽을 하나로 연결해 원형으로 사용하는 자료 구조
덱 (deque)
양방향 큐(double-ended queue)의 약자로, 양쪽으로 데이터를 삽입/삭제할 수 있는 큐
우선순위 큐
저장된 요소들이 선입선출로 처리되지 않고 정해진 우선순위가 높은 순서대로 처리되는 큐이다. heap이라는 자료 구조를 기반으로 구현된다. (뒤쪽에서 자세히 설명)
파이썬에서는 리스트로 구현하는 방법과, collections의 deque 모듈을 활용하여 구현할 수 있다. 전자는 모듈을 불러올 필요없이 간단하게 구현할 수 있지만, 배열에서 배웠다시피 요소를 제거하고 추가할 때 재정렬을 하면서 시간 복잡도가 이 필요하다. 하지만 deque 모듈은 내부적으로 연결 리스트 구조를 사용하기 때문에 요소를 추가하거나 제거할 때에도 으로 훨씬 효율적이다. queue 모듈을 활용해서도 구현할 수 있는데, 이 모듈은 보통 멀티스레딩을 고려하는 상황에서 주로 쓰인다고 한다.
# 1. 리스트로 구현
queue = []
queue.append(5) # enqueue
queue.append(4) # enqueue
queue.pop(0) # dequeue -> 먼저 넣은 5를 반환하고 큐에서 삭제
# 2. deque 모듈로 구현
from collections import deque
queue = deque() # queue 선언
queue.append(5) # enqueue
queue.append(4) # enqueue
queue.popleft() # dequeue -> 먼저 넣은 5를 반환하고 큐에서 삭제
# 3. queue 모듈로 규현
import queue
queue = queue.Queue() # queue 선언
queue.put(5) # enqueue
queue.put(4) # enqueue
queue.get() # dequeue -> 먼저 넣은 5를 반환하고 큐에서 삭제해시 테이블
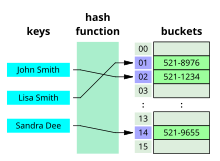
해시 테이블은 키(key)와 값(value)의 대응으로 이루어진 테이블과 같은 형태의 자료구조이다. 위의 그림을 보면 어떻게 동작하는지 보다 쉽게 이해할 수 있다. 키를 통해 얻고자 하는 데이터가 버킷에 저장되어 있다. 해시 함수는 키를 인자로 활용해 인덱스를 반환하고, 이 인덱스가 버킷 배열의 인덱스에 해당한다. 키를 해시 함수에 통과시켜 원하는 버킷에 접근하는 방식이다.
해시 함수란?
해시 함수는 임의의 길이를 지닌 데이터를 고정된 길이의 데이터로 변환하는 단방향 함수이다. 예를 들어, "apple"이라는 문자열을 해시 함수에 입력하면 3a7bd3e2360a3d29eea436fcfb7e44c735d11와 같은 데이터를 반환한다. 단방향이기 때문에 해시 값으로 어떤 데이터가 입력되었는지 역으로 추적하는 것은 어렵다. 따라서 정보를 송수신하는 과정에서 전송 당시의 해시 값과 수신된 데이터에 대한 해시 값을 비교해서 전송이 올바로 되었는지 확인하는데 쓰이거나, 홈페이지에서 비밀번호를 입력할 때 이러한 암호화 특성을 이용해서 저장한다. 해시 함수의 연산 방법을 해시 알고리즘이라고 하며 대표적으로 MD5, SHA-1, SHA-256, SHA-512, SHA3, HMAC 등이 있다. 해시 함수의 개념이 잘 와 닿지 않는다면 백준의 Hashing 문제를 풀어보면 좀 더 익숙해질 것이다.
해시 테이블은 검색, 삽입, 삭제 연산의 시간 복잡도가 로 아주 빠르다. 하지만 상대적으로 메모리 공간이 많이 소모된다. 또한, 해시 충돌 문제가 발생할 우려가 있는데 서로 다른 키에 같은 해시 값이 대응된 상황이다. 마치 열차표 예매 시스템에 문제가 생겨 한 자리에 두 사람의 예매 정보가 입력된 상황으로 비유할 수 있는데, 두 사람은 서로 "여기는 내 자리요!" 하고 충돌하게 될 것이다.
파이썬에서는 딕셔너리가 해시 테이블을 내부적으로 사용하는 자료형이다.
트리
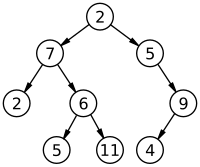
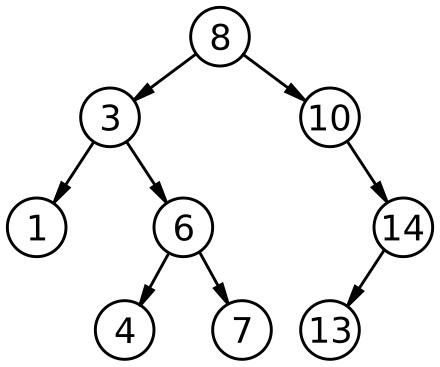
트리는 주로 계층적인 구조를 표현하기 위한 자료구조이다. 각 숫자가 쓰인 개체를 노드, 노드와 노드를 연결하는 간선으로 구성되어 있다. 이웃한 노드 간에 형성된 상하 관계에서 상위에 위치한 노드를 부모 노드, 하위에 위치한 노드를 자식 노드라고 한다. 같은 부모 노드를 공유하는 노드는 형제 노드, 최상단에 있는 노드는 루트 노드, 최하단에 있는 노드는 리프 노드라고 한다.
트리는 마치 연결 리스트처럼 하나의 노드를 "데이터를 저장할 공간"과 "자식 노드의 위치 정보 (메모리 상의 주소)"를 저장할 공간의 모음으로써 구현할 수 있다.
관련 용어
- 차수 (degree) : 각 노드가 가지는 자식 노드의 수를 의미한다. 리프 노드의 차수는 항상 0이다.
- 레벨 (level) : 루트 노드에서 시작해 특정 노드에 이르기까지 거치게 되는 간선의 수를 의미한다. 예를 들어 위의 그림에서 6 노드의 레벨은 2이다.
- 높이 (height) : 루트 노드에서 리프 노드까지 거치게 되는 간선의 수를 의미한다. 위의 그림에서 트리의 높이는 3이다.
트리의 순회
트리의 순회는 모든 노드를 한 번씩 방문하는 것을 말한다. 순회에는 전위 순회, 중위 순회, 후위 순회가 있다.
- 전위 순회 : 루트 노드 → 왼쪽 자식 → 오른쪽 자식 순으로 방문
- 중위 순회 : 왼쪽 자식 → 루트 노드 → 오른쪽 자식 순으로 방문
- 후위 순회 : 왼쪽 자식 → 오른쪽 자식 → 루트 노드 순으로 방문
이외에도 낮은 레벨의 노드부터 높은 레벨의 노드로 차례대로 순회하는 레벨 순서 순회도 있다.
이 순회를 구현하는 것은 백준의 트리 순회 문제를 풀면서 익숙해지도록 하자.
트리의 종류
- 이진 트리 : 자식 노드의 개수가 2개 이하인 트리
- 정 이진 트리 : 자식 노드의 개수가 0개 또는 2개인 이진 트리
- 포화 이진 트리 : 리프 노드를 제외한 모든 노드들이 자식 노드를 2개씩 가지고 있고, 모든 리프 노드의 레벨이 동일한 이진 트리
- 완전 이진 트리 : 마지막 레벨을 제외한 모든 레벨이 2개의 자식 노드를 가지고 있으며, 마지막 레벨의 모든 노드들이 왼쪽부터 존재하는 이진 트리
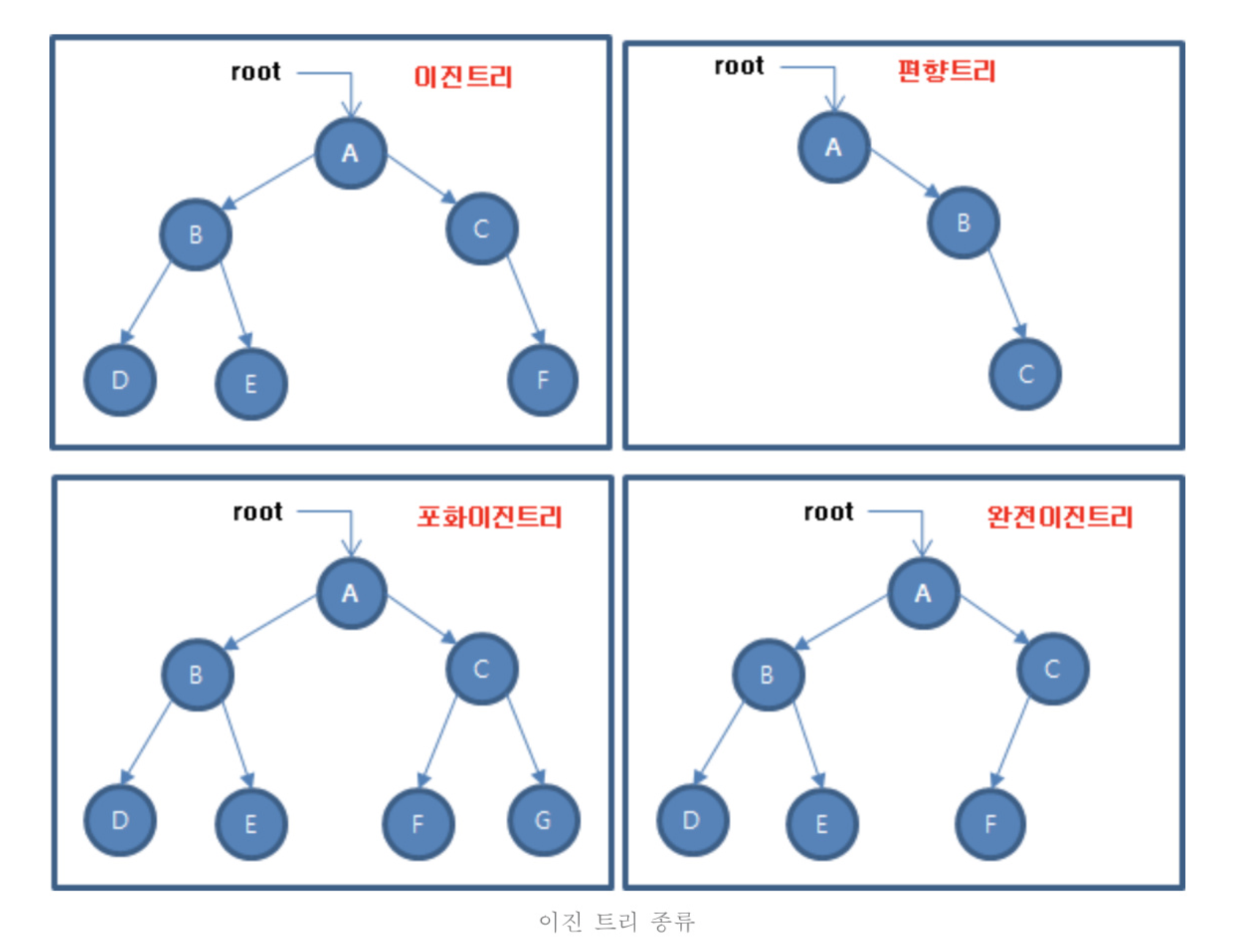
- 이진 탐색 트리 : 특정 노드의 왼쪽 서브트리에는 해당 노드보다 작은 값을 지닌 노드들이 있고, 오른쪽 서브트리에는 해당 노드보다 큰 값을 지닌 노드가 있는 구조의 이진 트리. 의 시간 복잡도로 원하는 값을 탐색할 수 있다. 단, 한쪽으로 편향된 이진 트리의 경우 탐색 속도가 이다.
References
https://www.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS8073601837
https://ko.wikipedia.org/wiki/%EC%8A%A4%ED%83%9D
https://ko.wikipedia.org/wiki/%ED%81%90_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%85%8C%EC%9D%B4%EB%B8%94
https://ko.wikipedia.org/wiki/%ED%8A%B8%EB%A6%AC_%EA%B5%AC%EC%A1%B0
https://80000coding.oopy.io/a9f714f9-4f76-4592-8c38-51913c3a885f
