메시지 보내는쪽 → producer
메시지 받는쪽 → consumer
broker : 카프카 서버(3대이상 구현 권장)
zookeeper : 메타데이터, broker id, controller id등 저장, controller 정보저장
n개 borker중 1대는 controller 기능 수행
controller: 각 broker에게 담당 파티션 할당 수행, broker 정상동작 모니터링 관리
kafka cluster <> kafka-client application
kafak 기동
- 주키퍼실행 →zookeeper.properties
- 카프카 서버 실행→server.properties
- 토픽생성
토픽생성 → 브로커가 해당 토픽에 메시지를 보냄(producer) → consumer가 해당에 구독을 신청함 → 토픽에 변경된 내용이 있을 경우 이 토픽을 구독하고있는 consumer에게 일괄적으로 전달해줌
→ 보내는 게 누구인지 관심없이, 토픽을 기준으로 변경된 데이터 확인 → 해당토픽을 구독하고있는 consumer에게 데이터 전달
윈도우에서 카프카 실행
C:\kafka_2.13-3.0.0\kafka_2.13-3.0.0\bin\windows ⇒ 홈 디렉토리
C:\kafka_2.13-3.0.0\kafka_2.13-3.0.0\bin\windows 이위치에서(해당 로케이션으로 들어오면)
이렇게 입력
zookeeper 실행
.\zookeeper-server-start.bat ..\..\config\zookeeper.properties./bin/zookeeper-server-start.sh ./config/zookeeper.propertieskafka 서버 실행
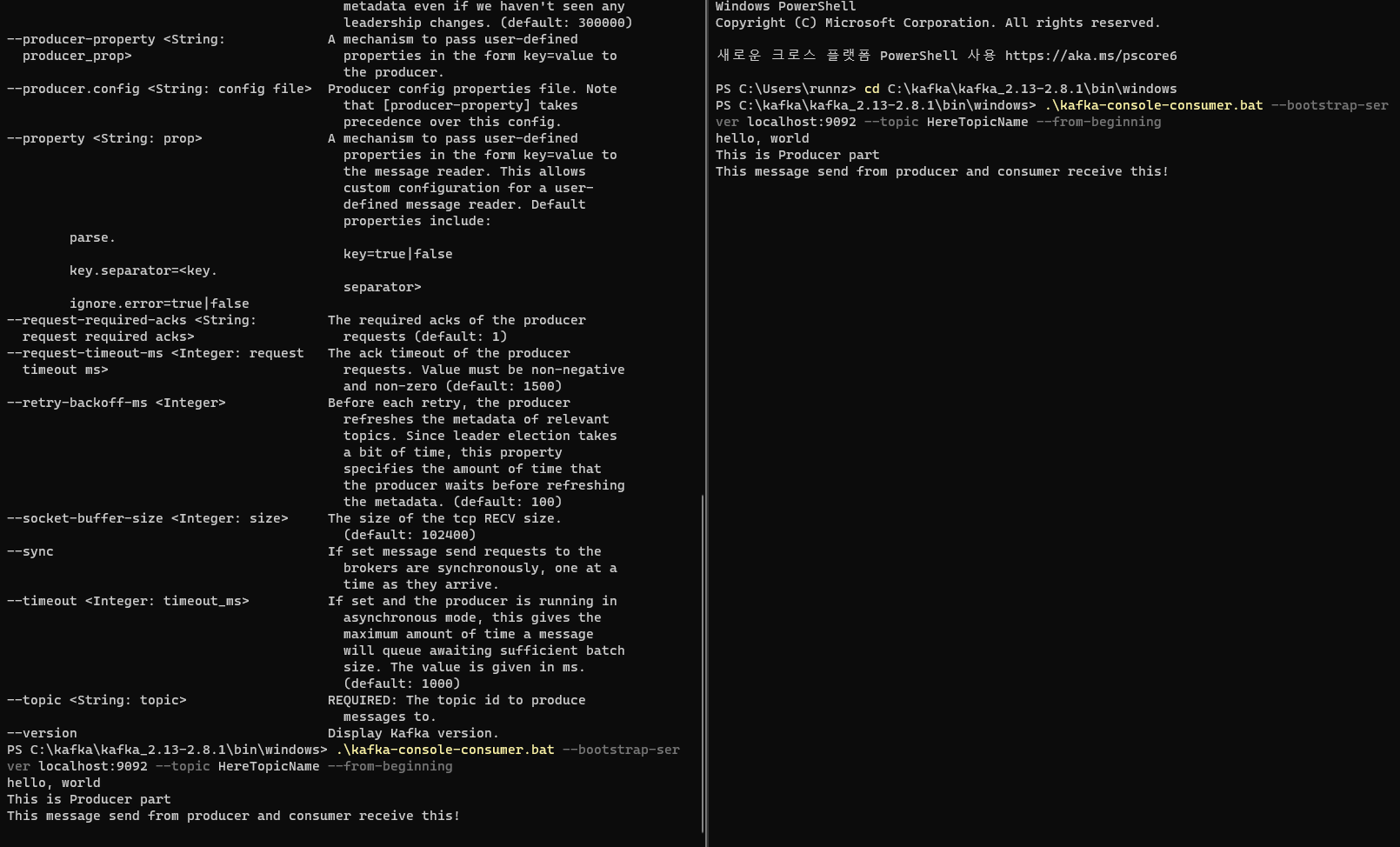
.\kafka-server-start.bat ..\..\config\server.properties./bin/kafka-server-start.sh ./config/server.properties실행중인 topic 리스트 확인
.\kafka-topics.bat --bootstrap-server localhost:9092 --list
//list 대신 --describe 토픽이름
//작성하게되면 해당 토픽에 대해 자세히 알 수 있다. 
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --listtopic 생성
.\kafka-topics.bat --bootstrap-server localhost:9092 --create --topic HereTopicName --partitions 1need argumetns 라는 에러 발생 → replication-argument 조건 추가하여 해결(뒤에 오는 숫자는 zookeeper보다 작아야됨)
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic topicname --partitions 1 --replication-f
actor 1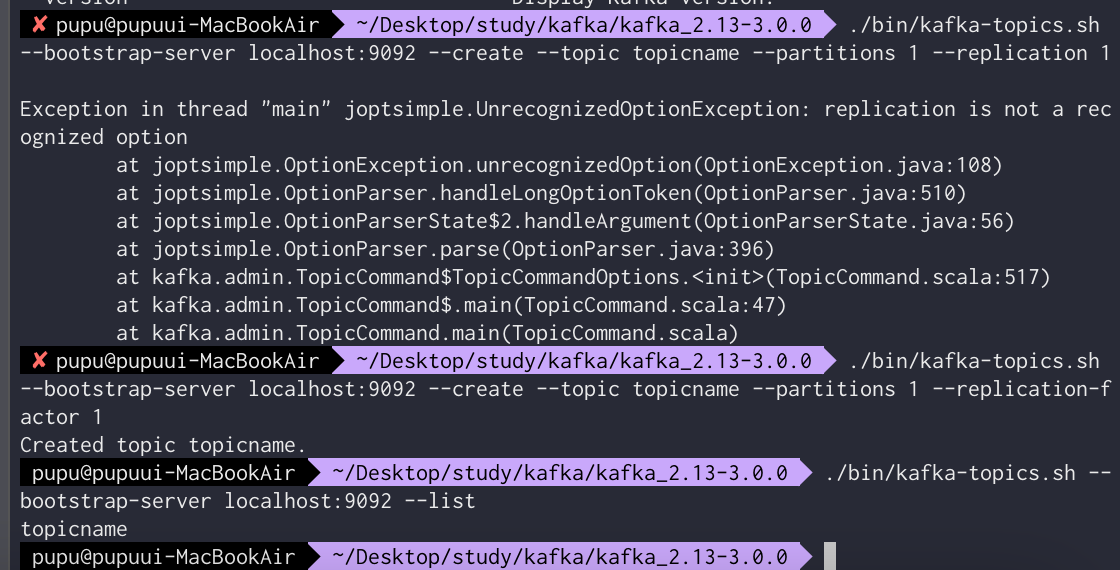

토픽 정보 자세하게
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic topicnameProducer 등록
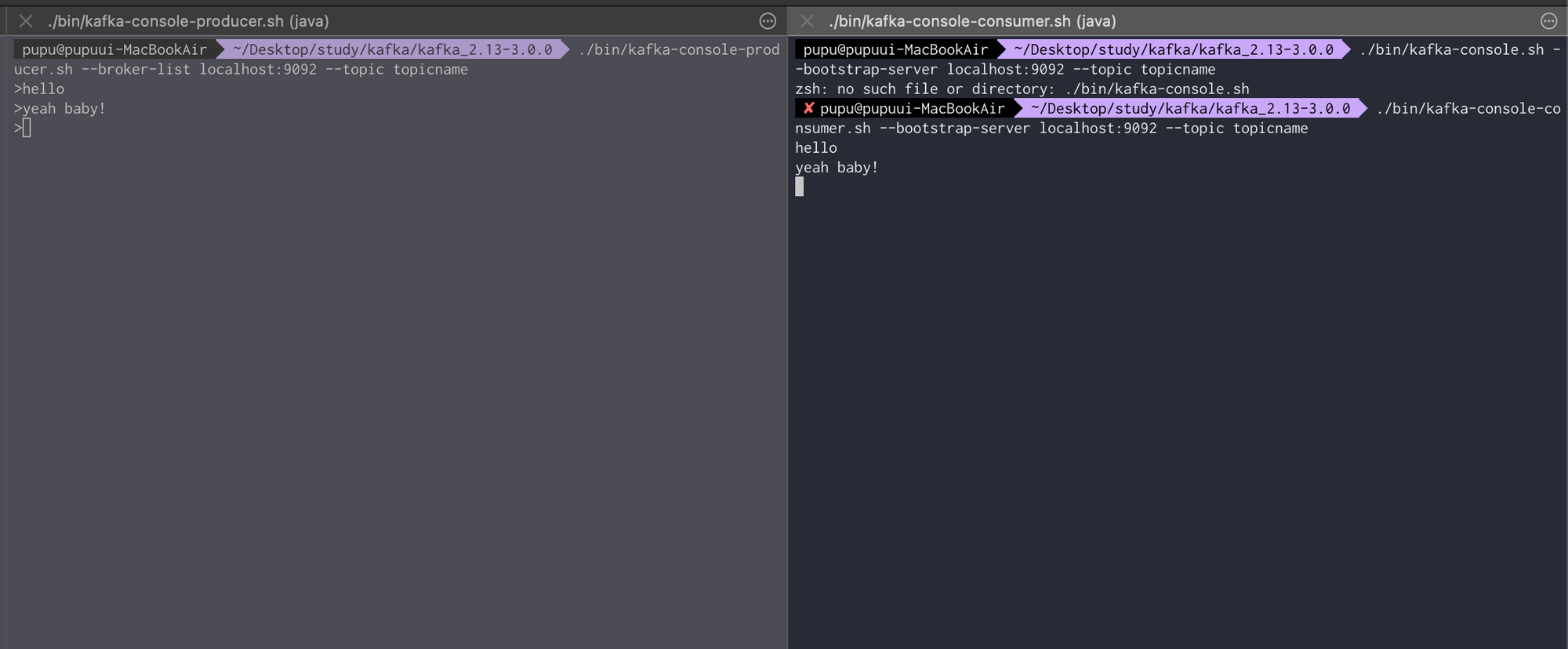
.\kafka-console-producer.bat --broker-list localhost:9092 --topic HereTopicName./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topicnameConsumer 등록
.\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic HereTopicName --from-beginning./bin/kafka-console-co
nsumer.sh --bootstrap-server localhost:9092 --topic topicname --from-beginningProducer에서 이렇게 메시지를 보내면

Consumer에서 이렇게 받을 수 있다

이렇게 오른쪽에 새로운 consumer를 등록해도 —from-beginning이라는 옵션 때문에, 처음부터 메시지를 모두 갖고와지는것을 볼 수 있다.
kafka access denied exception → version downgrade → 2.8.1(binary) 으로 다운받기
Kafka Connect
- kafka connect를 통해 data를 import/export 가능
- 코드 없이 configuration으로 데이터 이동
- standalone mode, ditribution mode 지원
- Restful api통해 지원
- Stream 또는 Batch 형태를 데이터 전송 가능
- 커스톰 Connector를 통한 다양한 plugin제공
여기서 적용되는 source system(jdbc, hive등등) → Kafka Connect Source(데이터 갖고오는 곳) → Kafka Cluster(데이터 저장되는 곳) → Kafka Connect Sink(데이터 보내는 쪽) → Target System(S3...)
MARIA DB 설치
MacOS)
MariaDB 설치
$ brew install mariadb
시작, 종료, 상태확인
$ mysql.server start, mysql.server stop, mysql.server status
접속
$ mysql –uroot
데이터베이스 생성
mysql> create database mydb;
Access denied 발생시)
$ sudo mysql –u root
mysql> use mysql;
mysql> select user, host, plugin FROM mysql.user;
mysql> set password for 'root'@'localhost'=password('test1357’);
mysql> flush privileges;
Windows)
다운로드
mariadb-10.5.8-winx64.zip 파일 다운로드
데이터베이스 초기화
.\bin\mariadb-install-db.exe
--datadir=C:\Work\mariadb-10.5.8-winx64\data
--service=mariaDB
--port=3306
--password=test1357
테이블 생성
create table users(
id int auto_increment primary key,
user_id varchar(20),
pwd varchar(20),
name varchar(20),
created_at datetime default NOW()
);
create table orders (
id int auto_increment primary key,
product_id varchar(20) not null,
qty int default 0,
unit_price int default 0,
total_price int default 0,
user_id varchar(50) not null,
order_id varchar(50) not null,
created_at datetime default NOW()
);ORDER-SERVICE
maria db설치
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<version>2.7.2</version>
</dependency>Maria DB실행(WSL 관리자 권한으로 실행할 것)
.\mysql -u root -p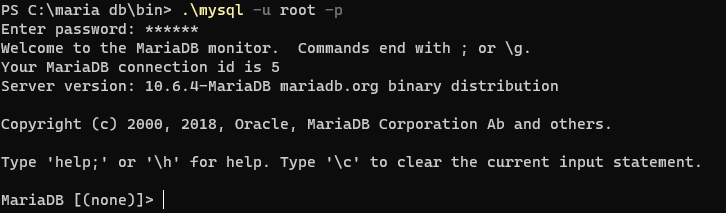
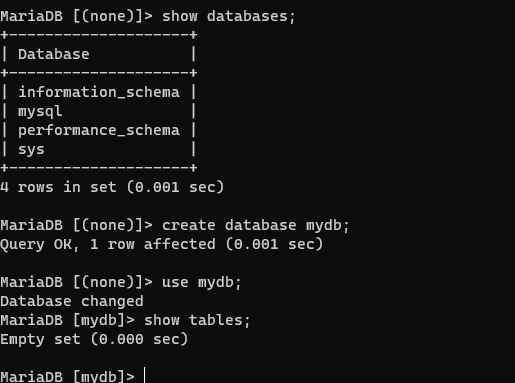
Orderservice - h2 console
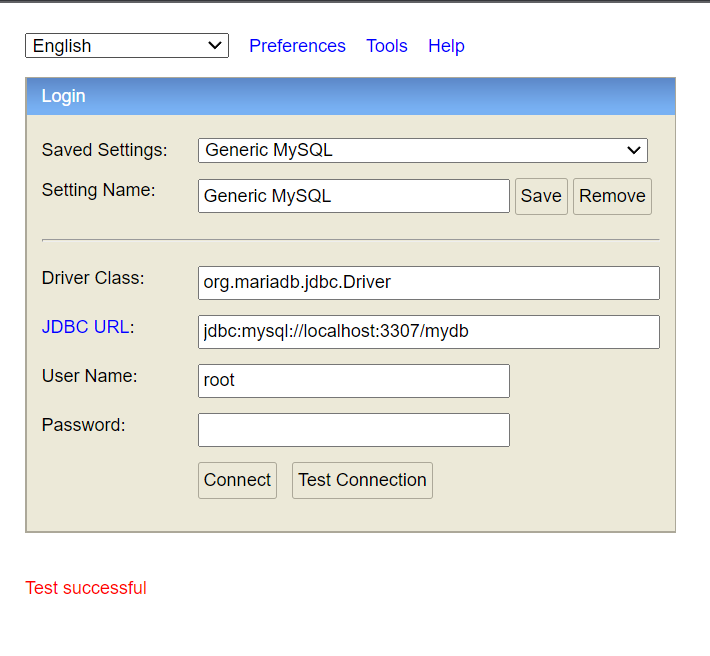
Saved settings : Generic MySql
Driver Class : org.mariadb.jdbc.Driver
jdbc URL : jdbc:mysql://localhost:3307(이걸로 설정함)/mydb(db이름)
userName : root
password : 698427Kafka Connect 설치
Kafka Connect 설치
curl -O http://packages.confluent.io/archive/5.5/confluent-community-5.5.2-2.12.tar.gz
curl -O http://packages.confluent.io/archive/6.1/confluent-community-6.1.0.tar.gz
tar xvf confluent-community-6.1.0.tar.gz
cd $KAFKA_CONNECT_HOME
Kafka Connect 실행
./bin/connect-distributed ./etc/kafka/connect-distributed.properties
JDBC Connector 설치
- https://docs.confluent.io/5.5.1/connect/kafka-connect-jdbc/index.html
- confluentinc-kafka-connect-jdbc-10.0.1.zip
etc/kafka/connect-distributed.properties 파일 마지막에 아래 plugin 정보 추가
- plugin.path=[confluentinc-kafka-connect-jdbc-10.0.1 폴더]
JdbcSourceConnector에서 MariaDB 사용하기 위해 mariadb 드라이버 복사
./share/java/kafka/ 폴더에 mariadb-java-client-2.7.2.jar 파일 복사
JDBC connector 설치
JDBC Connector (Source and Sink)
CMD에서 실행
curl -O http://packages.confluent.io/archive/5.5/confluent-community-5.5.2-2.12.tar.gz
tar xvf .\confluent-community-6.1.0.tar.gz
.\bin\windows\connect-distributed.bat \etc\kafka\connect-distributed.propertiesmac에서 kafaka-connect실행
./bin/connect-distributed ./etc/kafka/connect-distributed.properties실행 시키고 다시 실행중인 토픽 리스트 조회하면 아래와 같이 나타난다

connect-distributed-properties에 다음과 같이 추가(jdbc connector lib폴더위치)
plugin.path=\C:\\kafka_jdbc\\jdbc\\confluentinc-kafka-connect-jdbc-10.2.5\\lib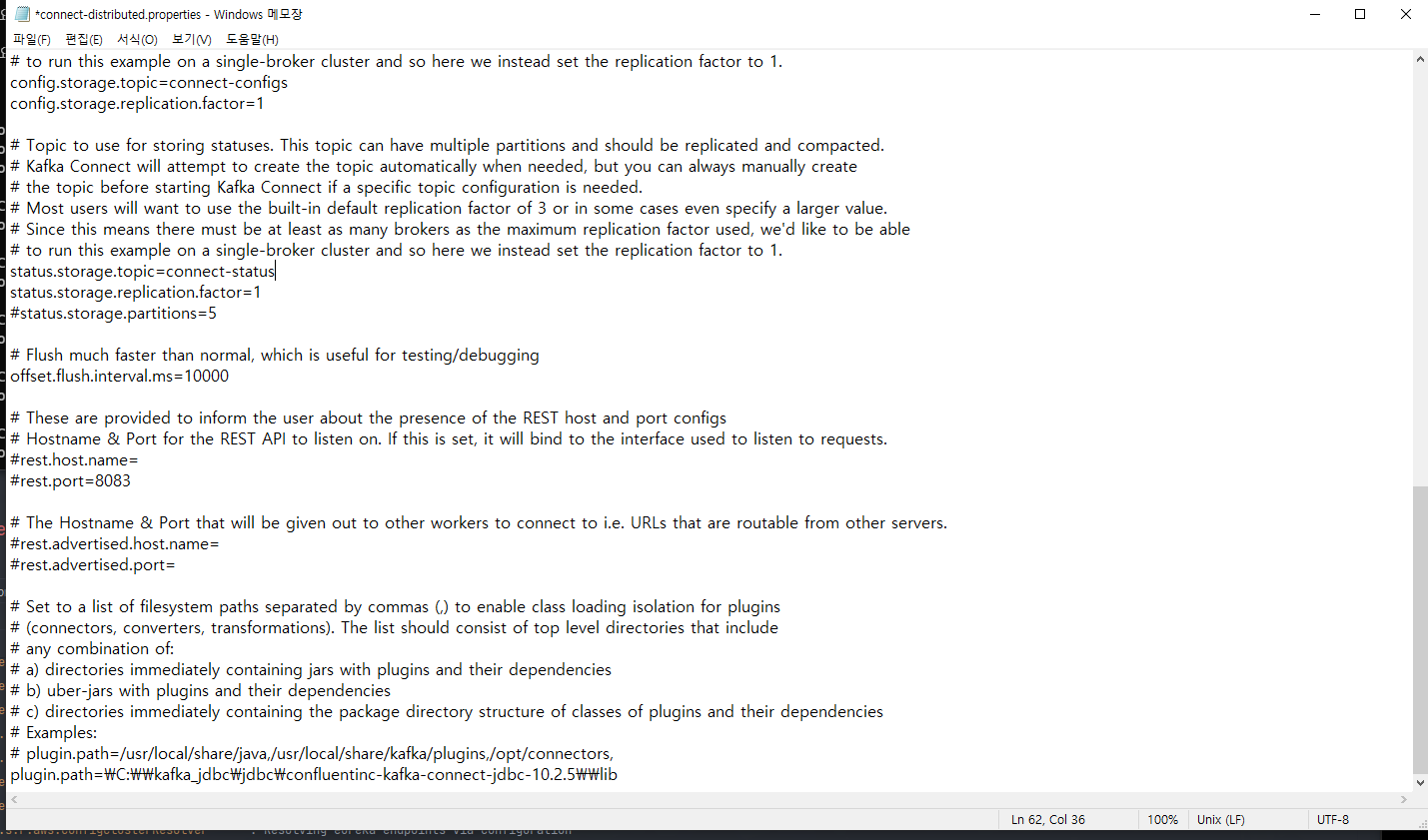
DB와 연동 시키기 위해
사용자.m2 repository/org/mariadb/jdbc/mariadb-java-client/2.72 의 mariadb-java-client-2.7.2.jar
파일을
kafka connect → share/java/kafka로 복사함

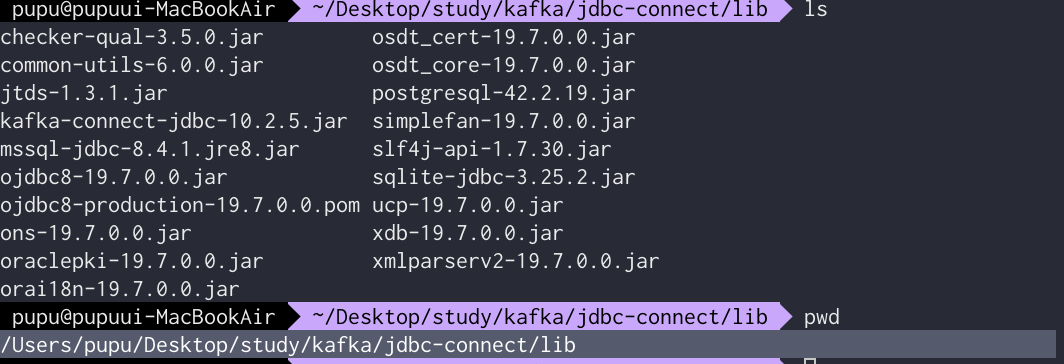
kafka-connect-jdbc-10.x .x.x.jar파일이 바로 db연동을 위해 필요한 파일임
pwd 로 현재 위치 조회후 이 path를 kafka-connect의 플러그인 패스에 추가시킴
다음 명령 실행하여 vscode로 파일 열고 위의
code ./etc/kafka/connect-distributed.properties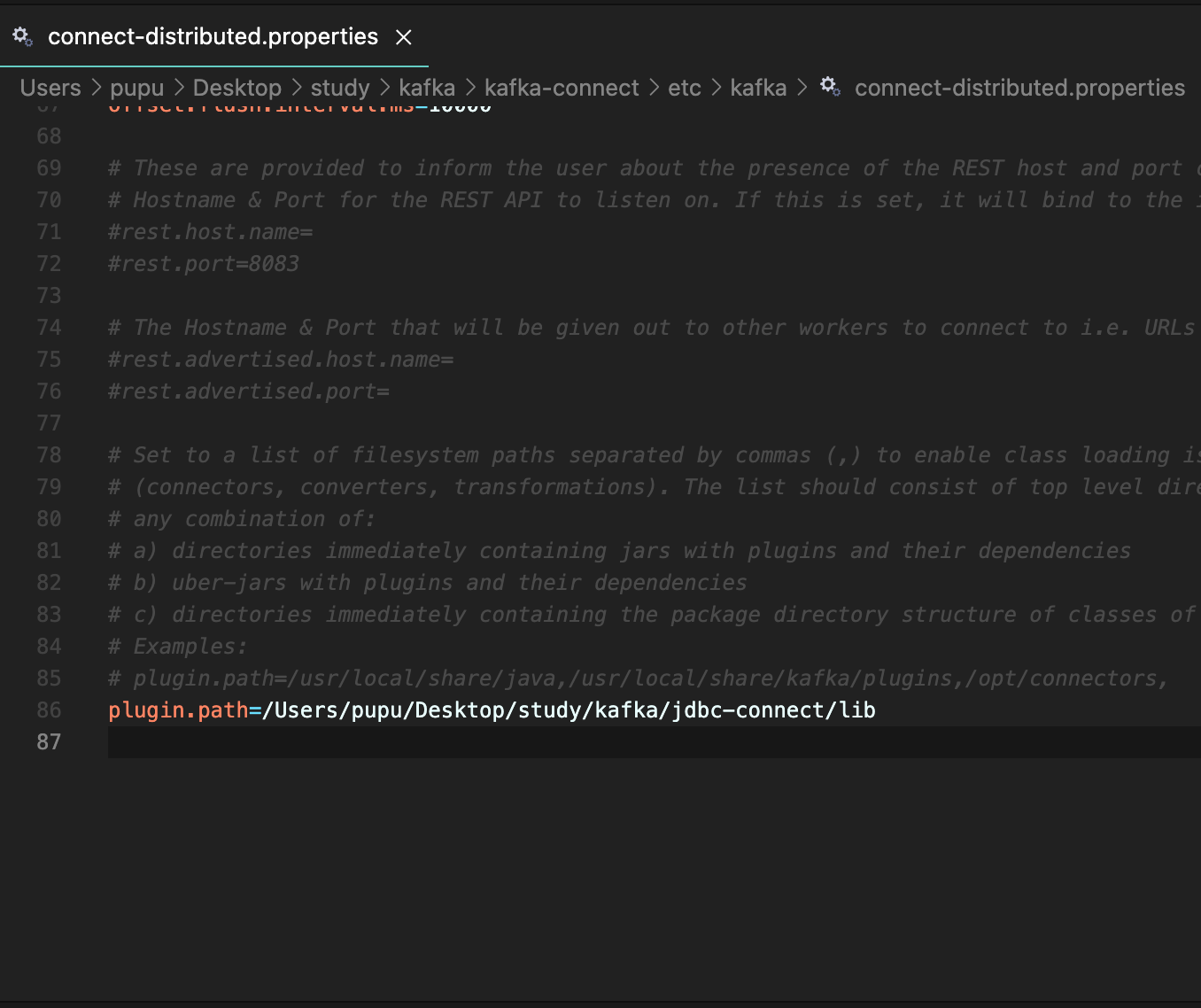
이 위치의 mariadb-java-client-2.7.2.jar파일을 kafka-connect에 복사(db연동)
/Users/pupu/.m2/repository/org/mariadb/jdbc/mariadb-java-client/2.7.2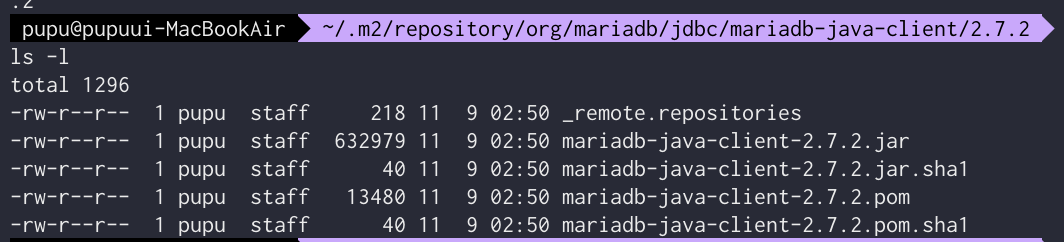
/Users/pupu/Desktop/study/kafka/kafka-connect/share/java/kafka다음 명령 실행하여 복사(.m2폴더에서)
cp ./mariadb-java-client-2.7.2.jar /Users/pupu/Desktop/study/kafka/kafka-connect/share/java/kafkakafka connect share, java/kafka에서 해당 파일이 복사되었는지 확인
ls -l mariadb*
kafka source connect
echo '
{
"name" : "my-source-connect",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://localhost:3306/mydb",
"connection.user":"root",
"connection.password":"698427",
"mode": "incrementing", # 자동으로 증가 시킬것이다(설정)
"incrementing.column.name" : "id",# 이값이 자동으로 증가됨
"table.whitelist":"users", # (whitelist) db에서 특정한 값을 저장(insert)함 -> 'user'테이블의 데이터값이 변경되면 감지해서 갖고옴
"topic.prefix" : "my_topic_", # 위에서 변경감지된 데이터 값을 저장할 곳을 작성해놓음
"tasks.max" : "1"
}
}
#8083이 현재 kafka connect가 사용하는 엔드포인트
#위의 값을 connectors로 보냄
' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"
Kafka Source Connect 관련해서 최낙원님이 공유해 주신 내용도 참고해 주시기 바랍니다. 감사합니다.
https://www.inflearn.com/questions/199173다음과 같이 보내본다 (kafka-connect는 실행되어있어야함)
아래와 같이 응답이 온다
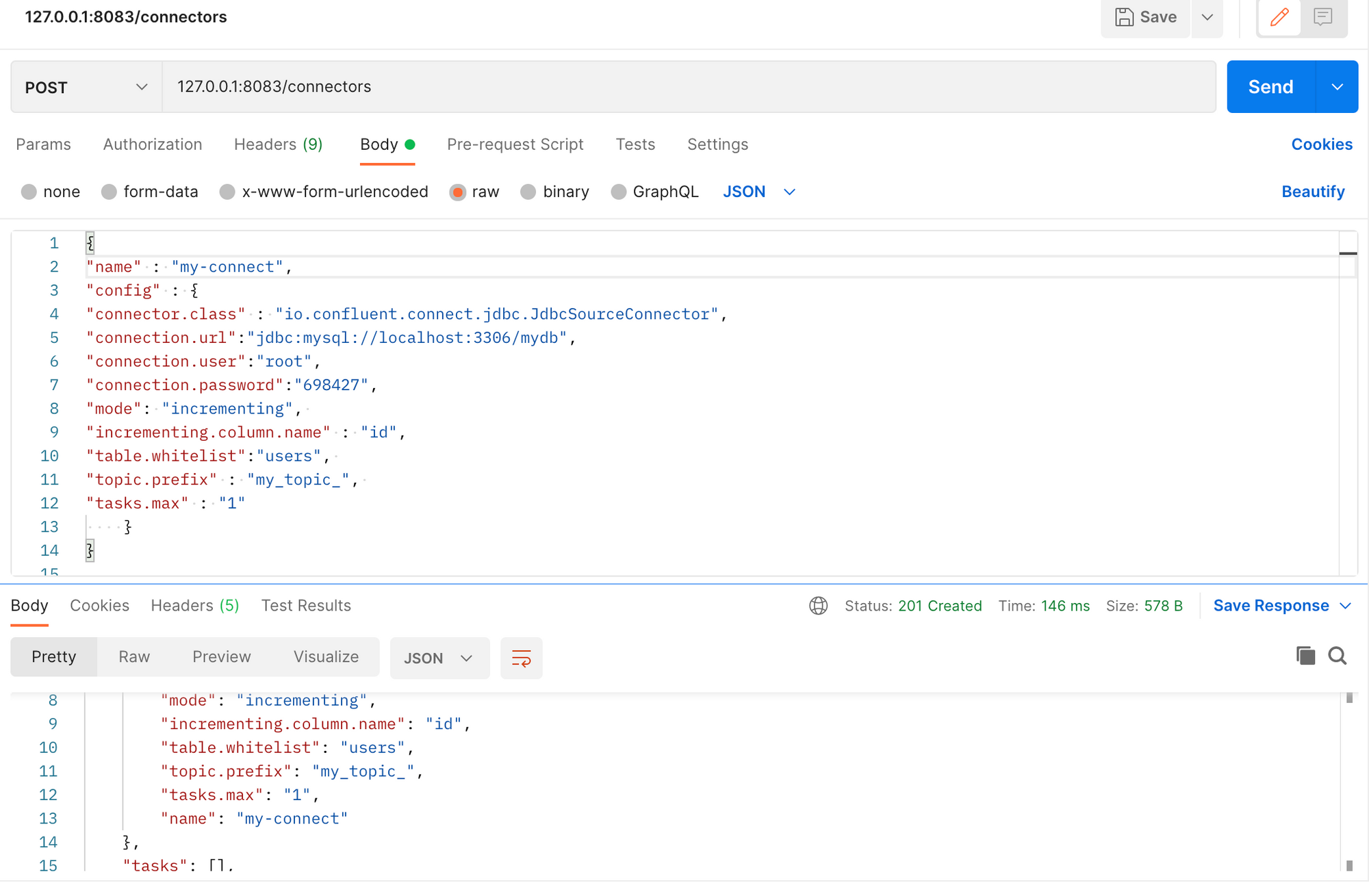
get방식으로 조회하면 응답옴
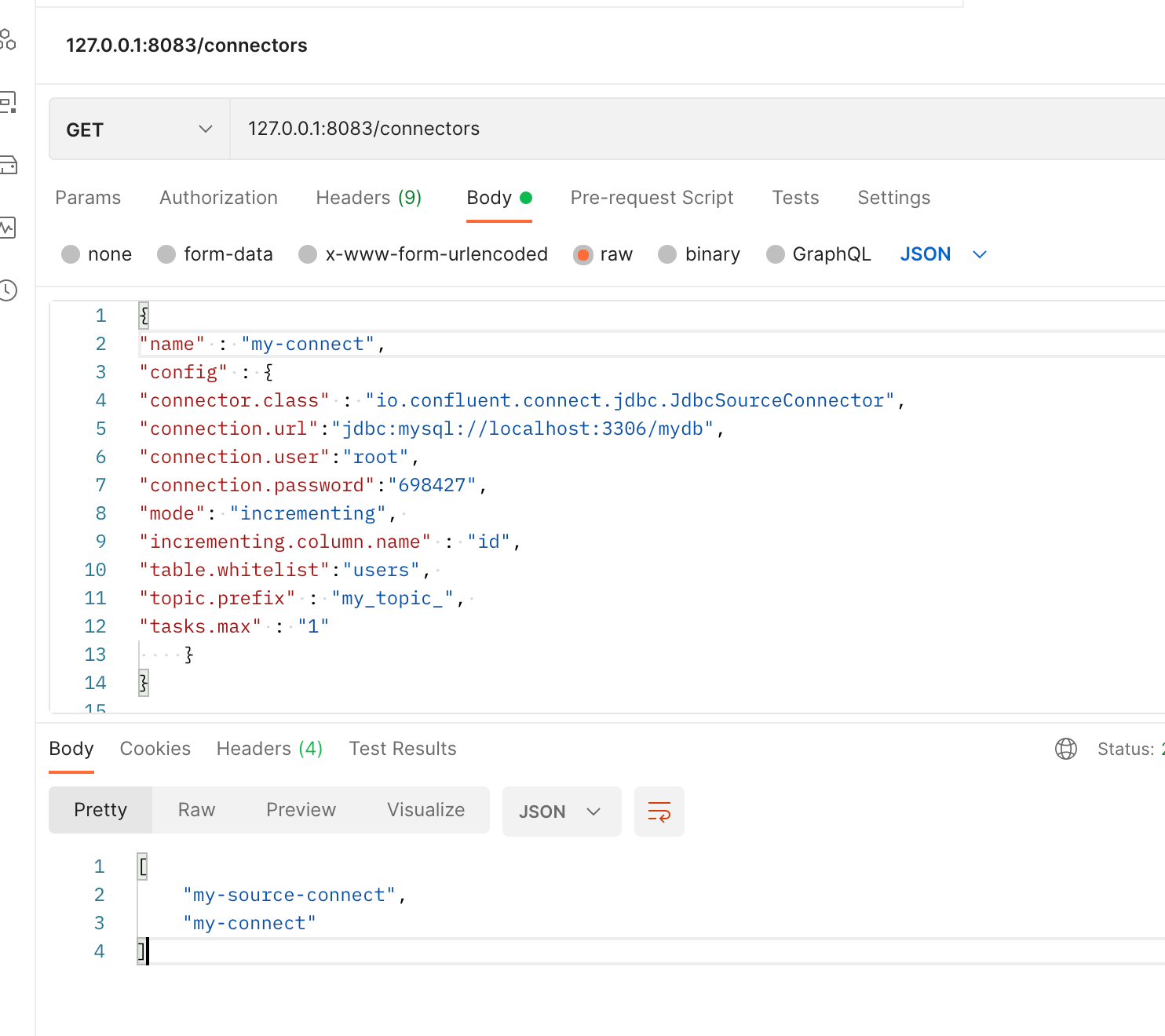
자세히 조회
GEt // 127.0.0.1:8083/connectors/my-connect/status(name / statsu)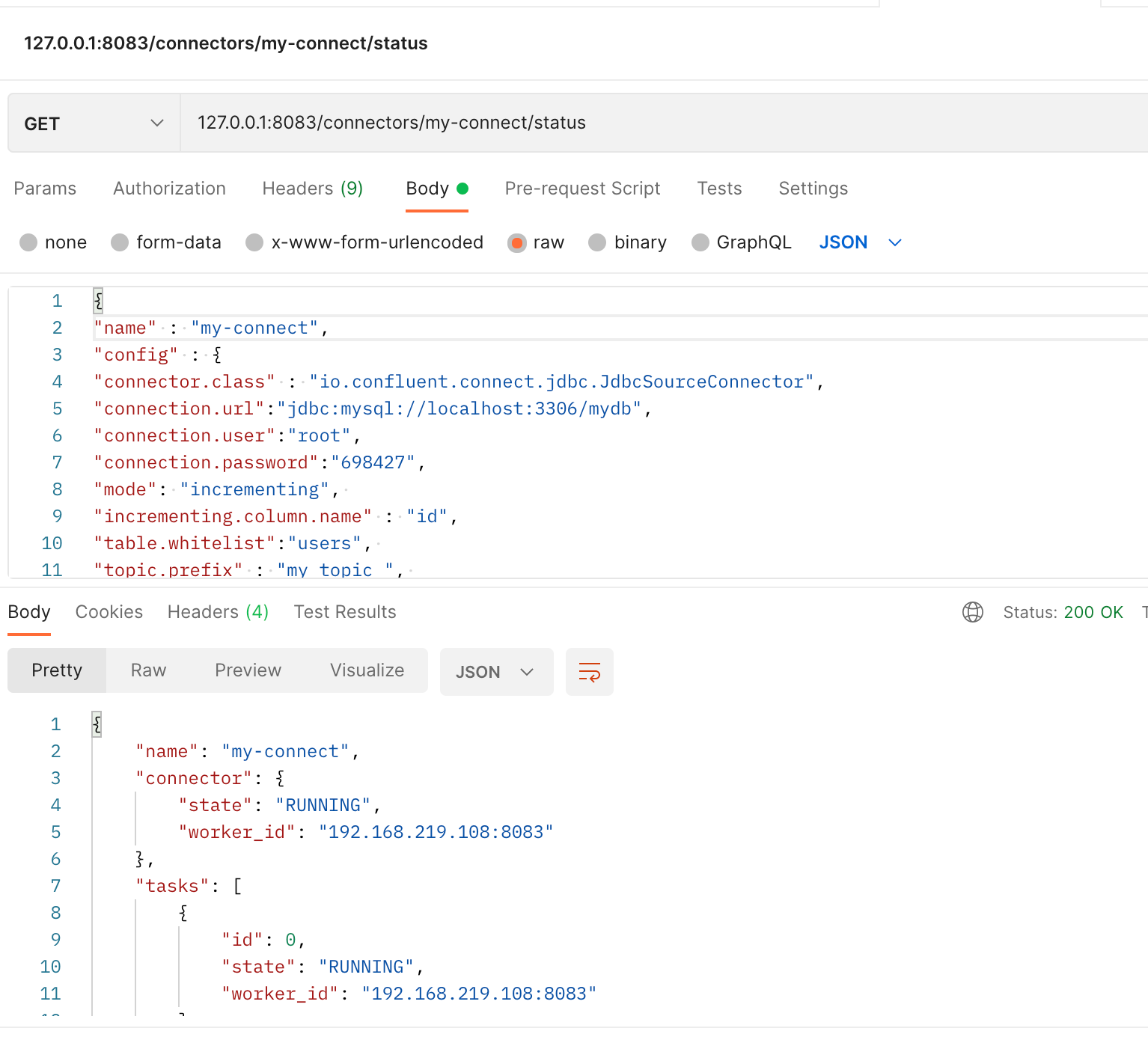
Users 테이블의 데이터 삽입시 변경확인을 위해 다음과 같이 데이터 삽입


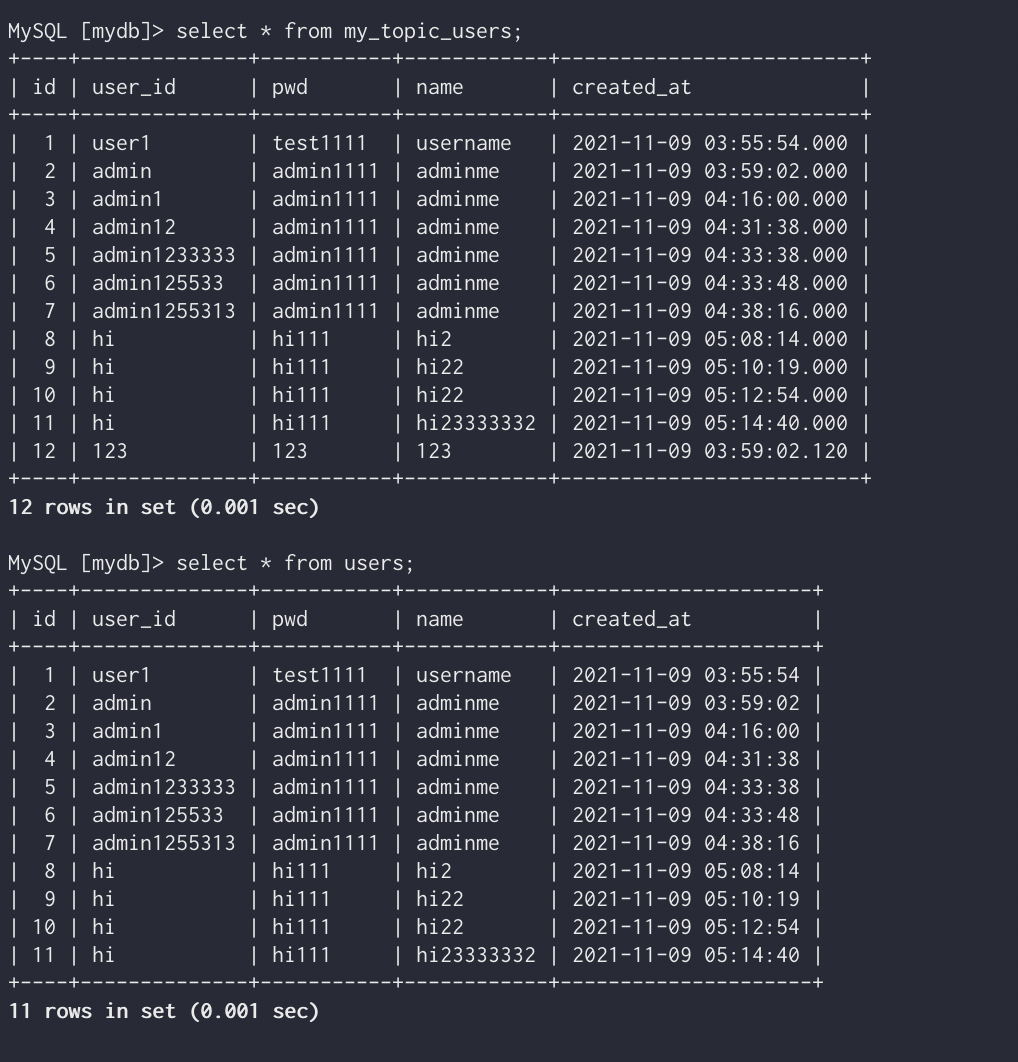
아래와 같이 my_topic_users라는 토픽이 새로 생긴것을 볼 수 있다.
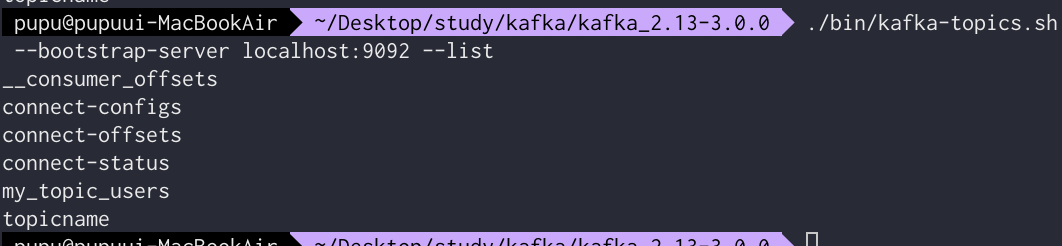
consumer를 통해 데이터를 확인해보기 위해 다음과 같이 명령어 입력
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_topic_users --from-beginning다음과 같이 새로 생성된 데이터를 확인해볼 수 있다.
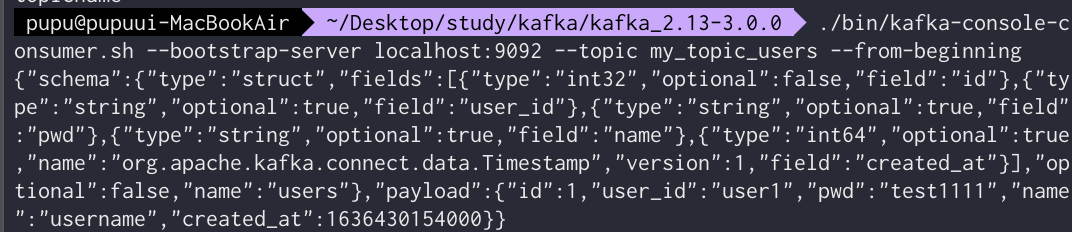
새로운 쿼리 입력시(데이터 확인되면)다음과 같이 consumer가 자동으로 감지하여 파악한다.
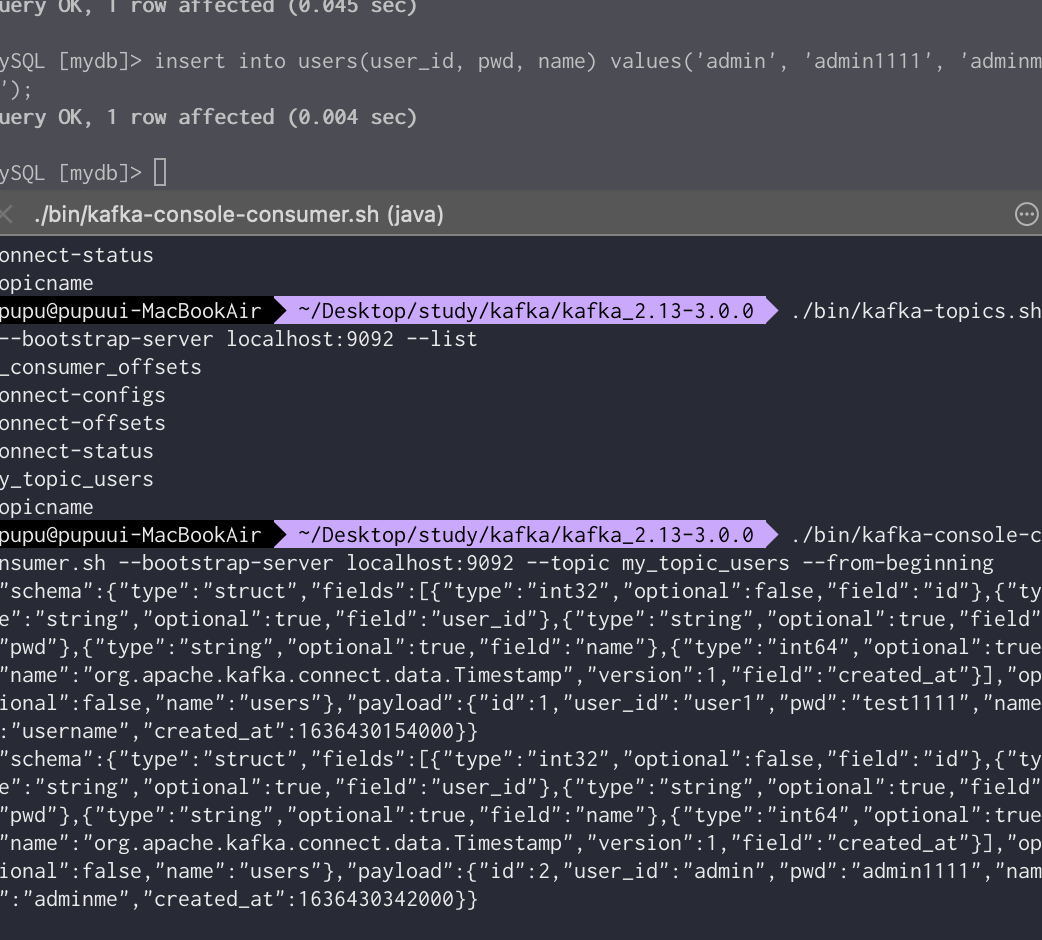
정렬된 데이터는 다음과 같다
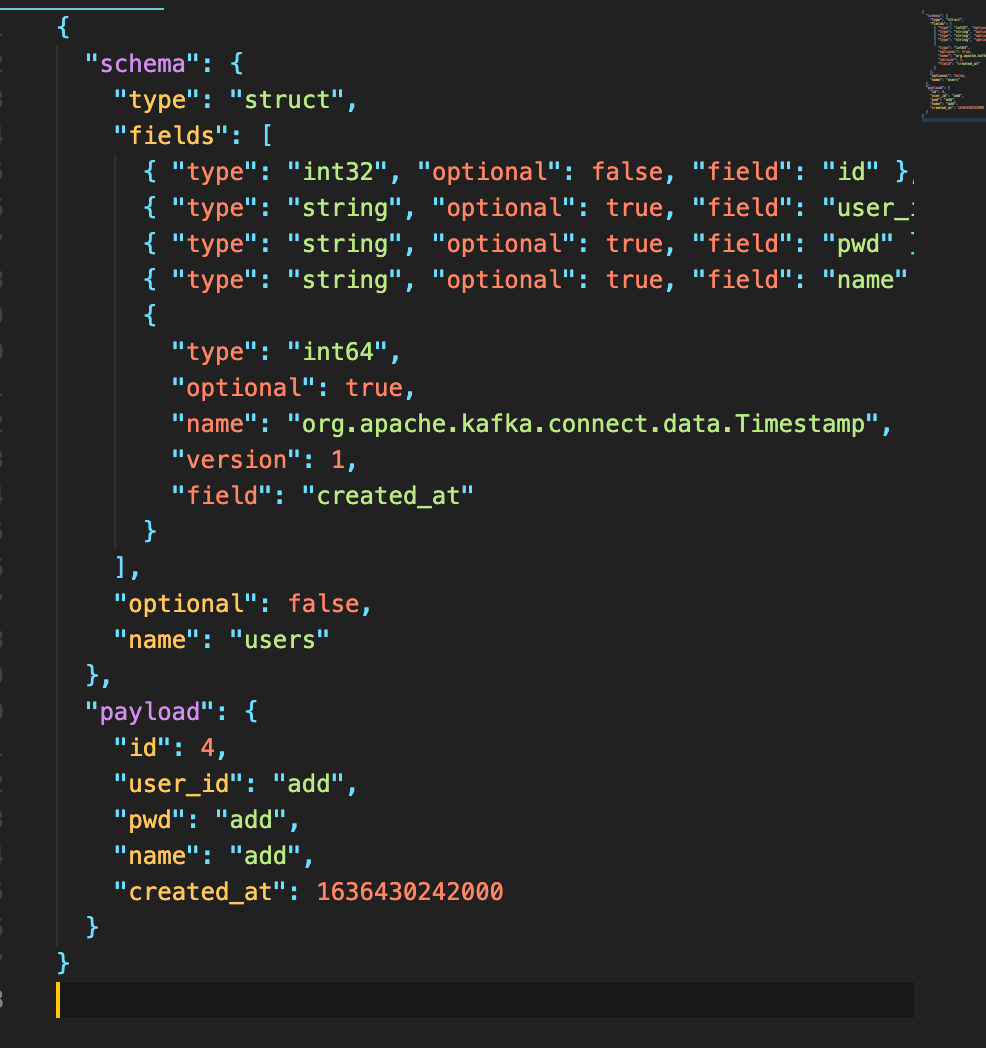
{
"schema": {
"type": "struct",
"fields": [
{ "type": "int32", "optional": false, "field": "id" },
{ "type": "string", "optional": true, "field": "user_id" },
{ "type": "string", "optional": true, "field": "pwd" },
{ "type": "string", "optional": true, "field": "name" },
{
"type": "int64",
"optional": true,
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"field": "created_at"
}
],
"optional": false,
"name": "users"
},
"payload": {
"id": 2,
"user_id": "admin",
"pwd": "admin1111",
"name": "adminme",
"created_at": 1636430342000
}
}kafka sink connector설정(토픽에 저장된 내용을 사용하는 곳으로 전달)
목적
kafka-conosole-producer 에서 데이터 전송 → topic에 추가 → maria db에 추가
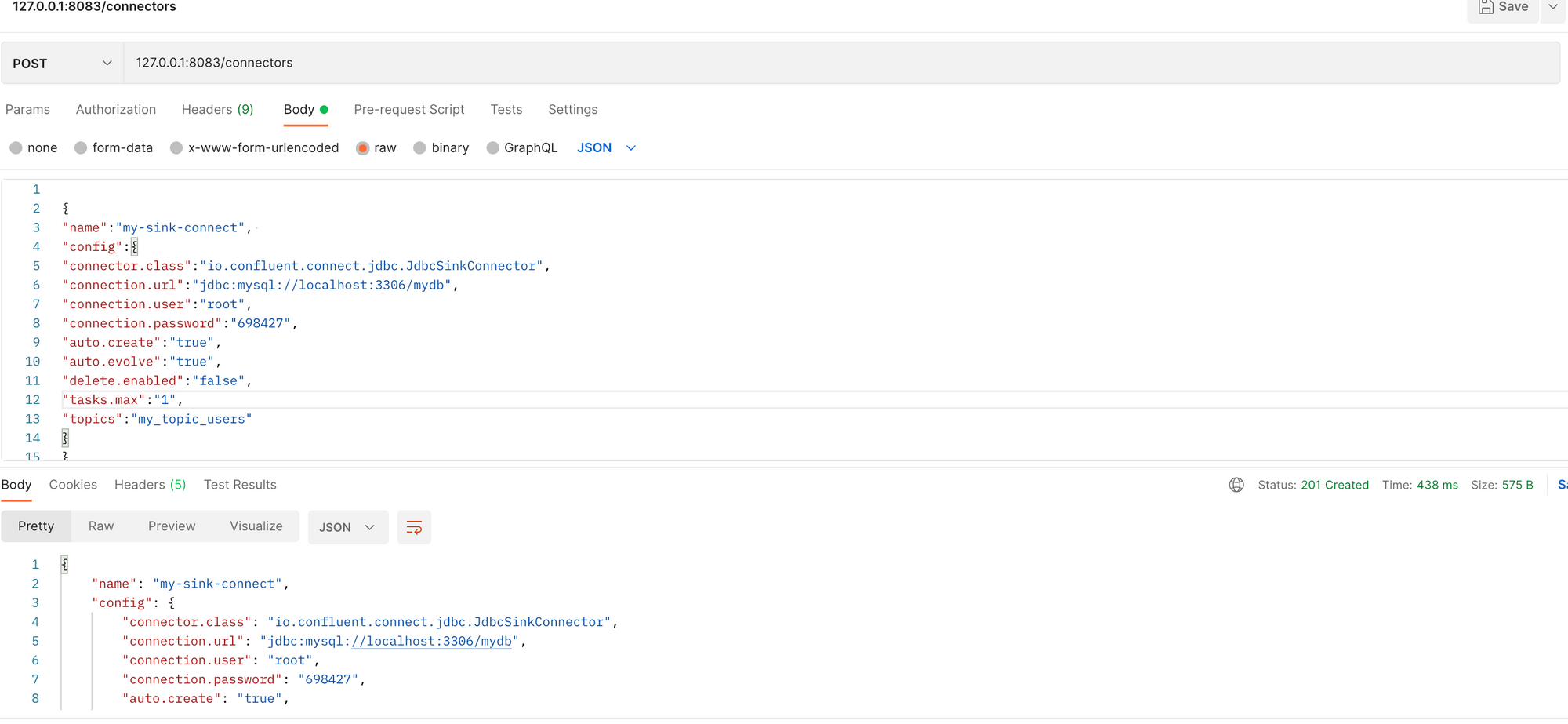
echo '
{
"name":"my-sink-connect", #이 이름으로 sink 컨넥터가 생성
"config":{
#우리가 사용하고있는 db
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://localhost:3306/mydb",
"connection.user":"root",
"connection.password":"698427",
#토픽과 같은 이름의 테이블을 생성해주겠다는 옵션
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
#현재 존재하고있는 토픽의 데이터를 갖고옴(이 토픽에 있는 데이터를)
"topics":"my_topic_users"
}
}
'| curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"현재 띄어져 있는 서버
zookeeper server
kafka server
kafka console consumer
kafka connect
{
"name":"my-sink-connect",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://localhost:3306/mydb",
"connection.user":"root",
"connection.password":"698427",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"my_topic_users"
}
}다음과 같이 입력
get 방식으로 sink connector 확인
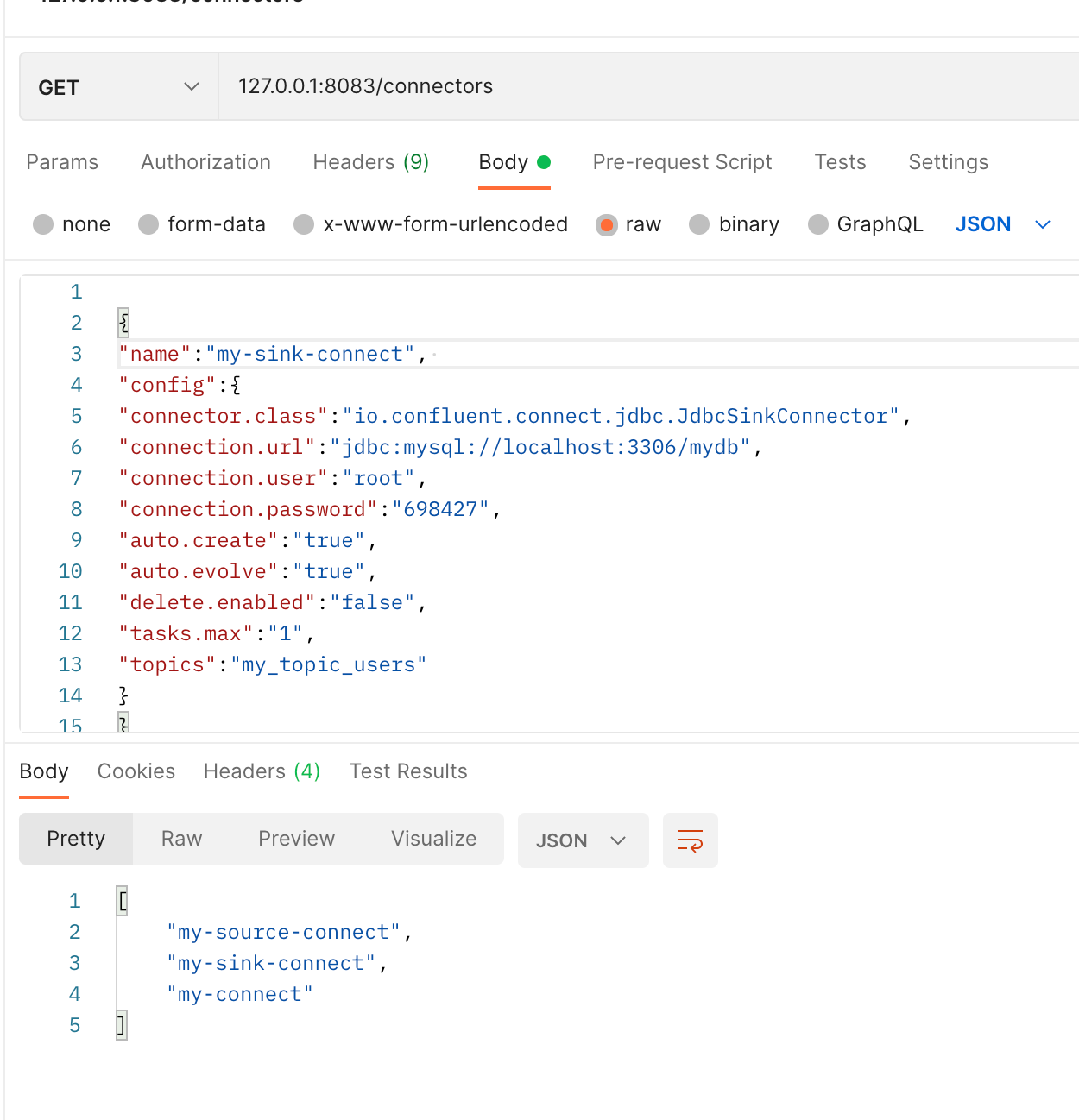
이렇게 sink connector가 생성되었다는 것은 topic의 이름과 같은 이름의 테이블이 생성되었다는 뜻이다
즉 insert문장으로 작동을 한번 시키고 테이블을 조회해보면
다음과 같이 my_topic_users라는 새로운 테이블이 생성되어있음을 알 수 있다.
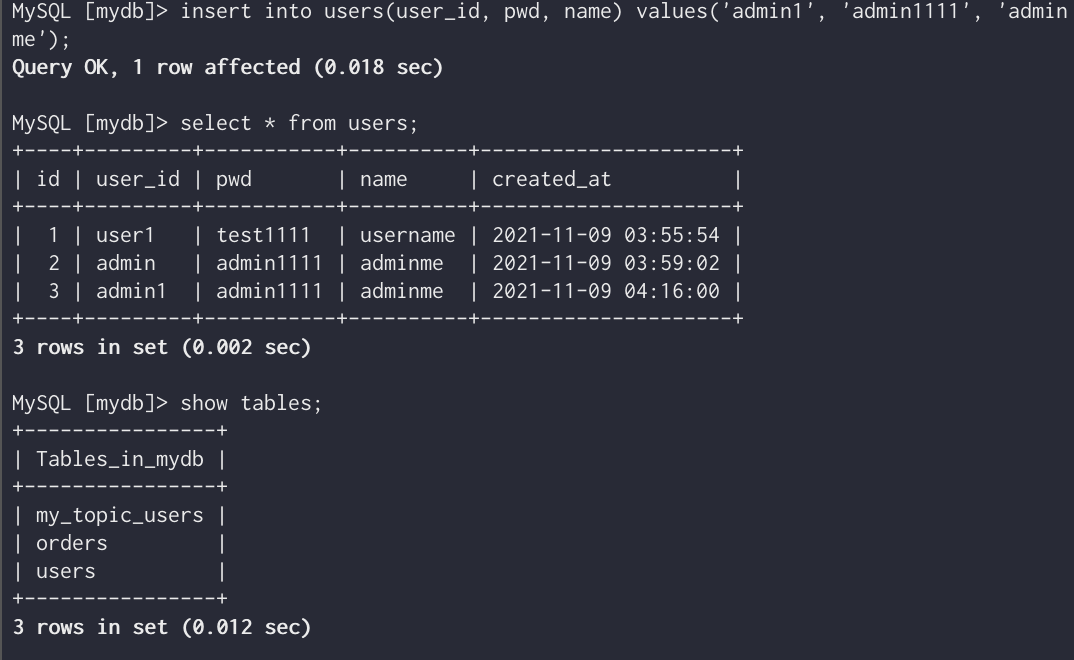
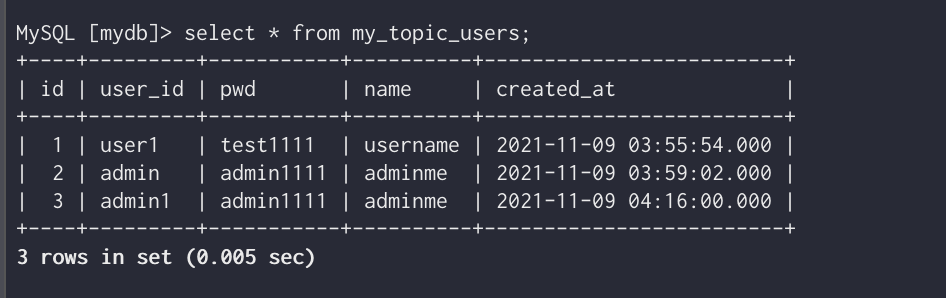
이렇게 users 테이블의 값과 같음을 볼 수 있다.
데이터 ETL(데이터 이관 기술 export, transfer, load )
저장될 수있는 타입으로 보내보자 (sink connector가 알 수 있는 데이터 타입으로 보내야한다!!)
새로운 터미널을 실행
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my_topic_users다음과 같에 데이터를 수정해본다(이 데이터는 기존의 보냈던 데이터를 복사하여 수정한것)
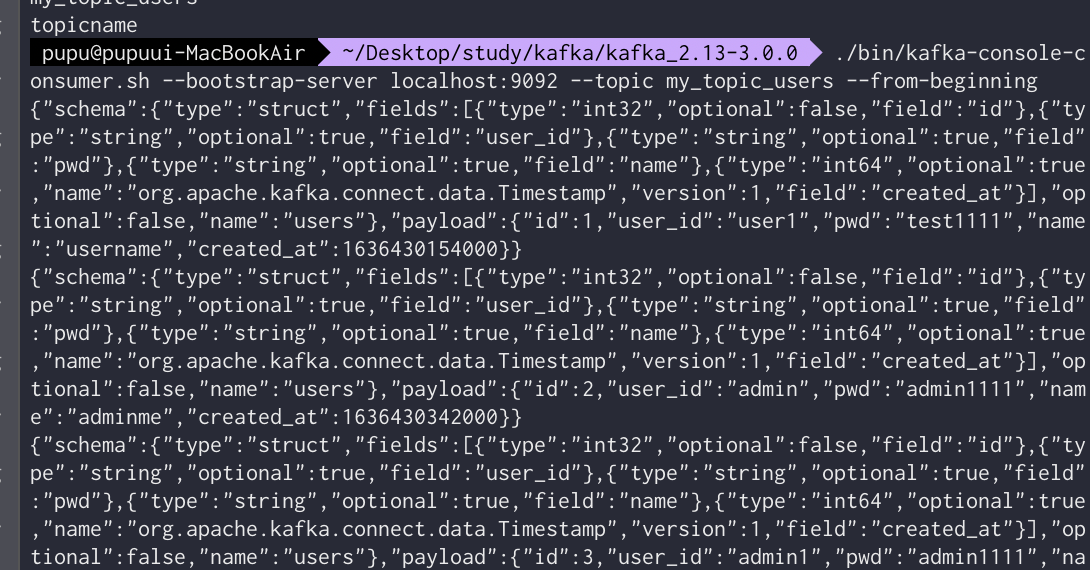
그럼 컨슈머에서 다음과 같이 보내짐을 확인
이렇게 보내야됨

아래처럼 보내면 안됨
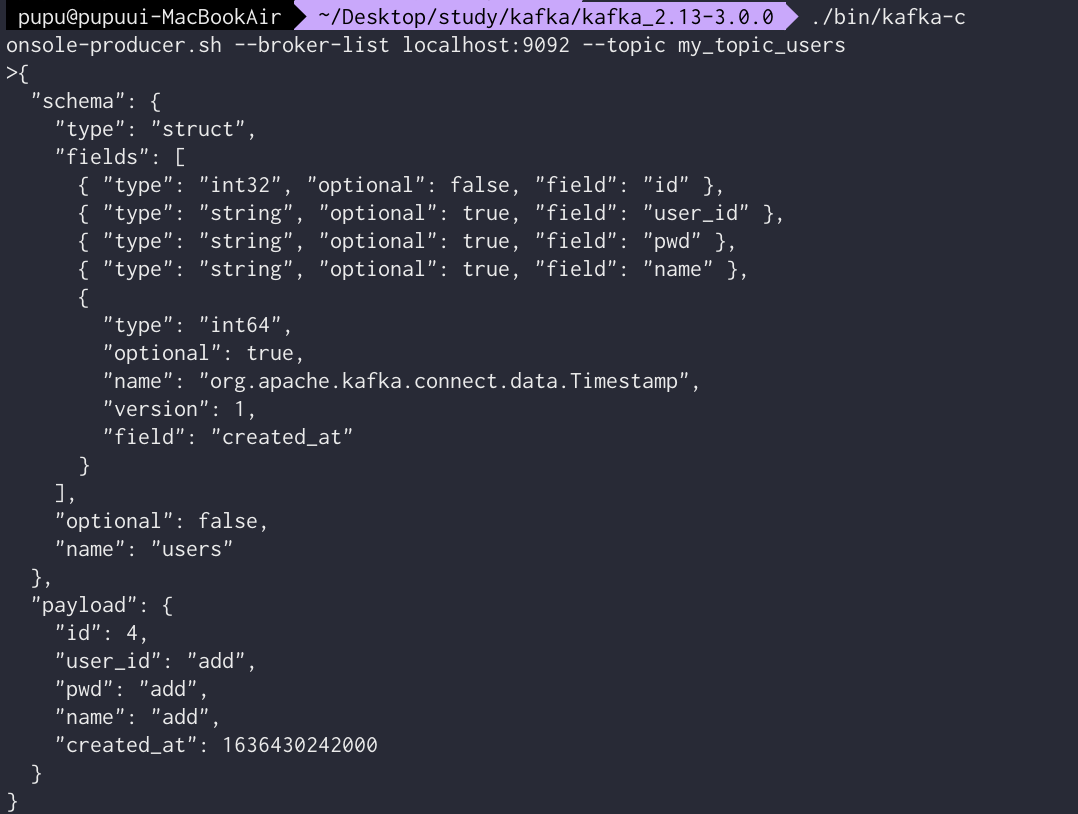
DB조회시 다음과 같이 조회됨을 알 수 있다
Users table은 데이터 변경이 없지만, my_topci_users는 데이터가 변경됨을 확인할 수 있다.
users table은 자신의 데이터를 토픽에 밀어 넣는 개념이기 때문에 producer가 집어 넣었던 데이터는 없다. 하지만 sink connector와 연결된 my_topic_users테이블의 경우 변경된 데이터가 반영됨을 알 수있다.