카프카 → FIFO구조
큐에 데이터를 보내는 것 : 프로듀서
큐에 데이터를 가져가는것 : 컨슈머
ByteArray로 통신 → 자바에서 선언가능한 모든 객체 사용 가능
상용환경에서는 최소 3대 이상의 서버(브로커)분산 운영
데이터 레이크 : 데이터가 모이는 저장공간
데이터 하우스 : 데이터 레이크와 다르게 필터링 되거나 패케지화 됨
특징
높은 처리량 : 대용량 처리
확장성 : 스케일 아웃, 인이 용이함
영속성 : 영속성은 데이터를 생성한 프로그램이 종료되어도 사라지지 않은 데이터 특성
카프카는 메모리에 저장하지 않고 파일 시스템에 저장
고가용성 : 3개 이상의 서버들로 운영됨, 하나의 브로커에저장되어도 다른 브로커에 복제 저장
데이터 레이크 아키텍처
- 람다 아키텍처
1.배치레이어
배치 데이터를 모아서 특정 시간마다 일괄처리
2.서빙레이어
가공된 데이터를 서비스 어플리케이션이 사용할 수 있도록 데이터가 저장된 공간
3.스피드레이어
서비스에서 생성되는 원천데이터를 실시간 분석
단점 : 배치 처리 레이어와 실시간 처리 레이어가 나뉨 → 각각의 레이어의 처리 로직이 따로 존재해야함, 배치 데이터와 실시간 데이터 융합 처리시 불편- 카파 아키텍처
배치레이어를 삭제하고 바로 스피드레이어에 넣음
배치 데이터를 스트림 프로세스로 처리할 수 있게된 방법 → 모든 데이터를 로그로 바라봄
로그 : 데이터마다 일정한 레코드가 붙음
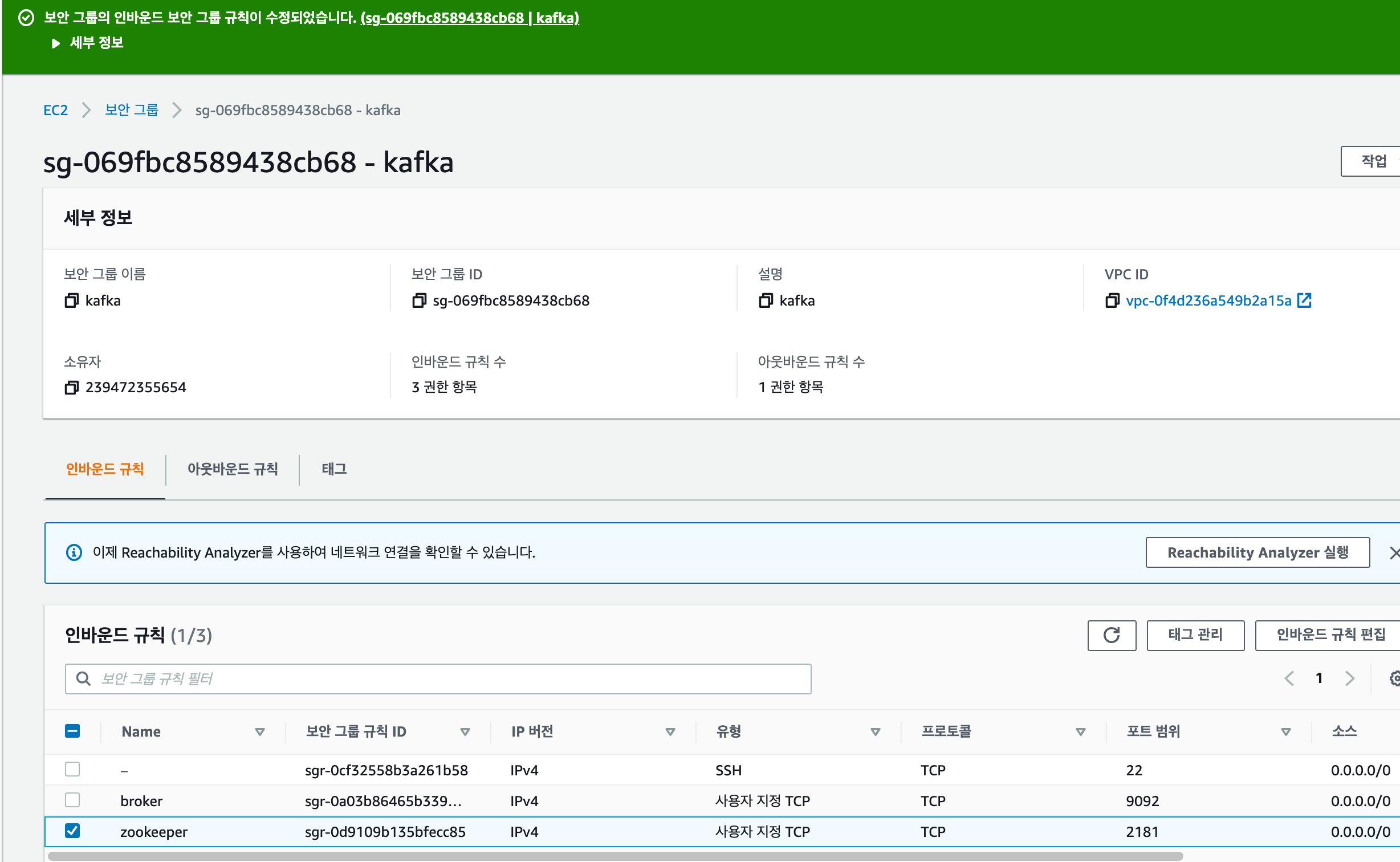
EC2 카프카 설치
2181 : zookeeper포트 오픈
9092 : broker 포트 오픈
EC2 접속후 kafka 다운로드 및 압축해제
sudo yum install -y java-1.8.0-openjdk-devel.x86_64
wget https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz
tar xvf kafka_2.12-2.5.0.tgz힙 메모리 설정
브로커는 레코드 내용은 페디지 캐시로 시스템 메모리 사용하고 나머지 객체들은 힙메모리 사용
이러한 특징으로 5기가 이상 설정하지 않음
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m"
echo $KAFKA_HEAP_OPTS~/.bashrc 설정
vi ~/.bashrc
----------------
"~/.bashrc" 11L, 231C 1,1 모두
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER=
# User specific aliases and functions
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m"
---------------
source ~/.bashrc
echo $KFAK_HEAP_OPTSvi config/server.properties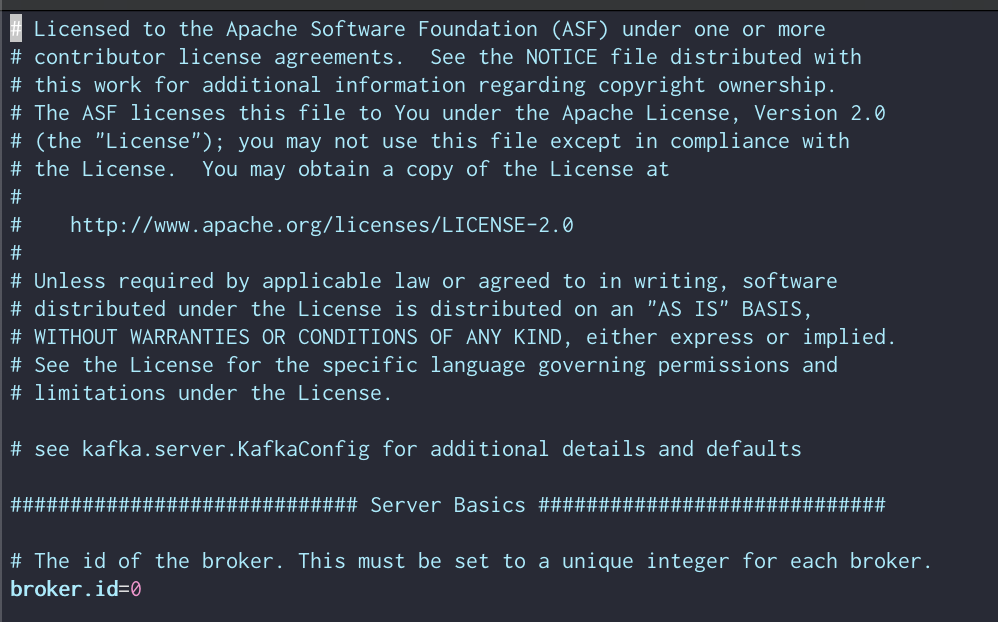
broker 유일 아이디 설정

통신 포트 설정

카프카 클라이언트 또는 카프카 라인툴에서 접속할 때 사용하는 정보 작성 여기서는 ec2ip v4 넣어야 함

통신을 통해 갖고온 파일 저장 위치

브로커 가 저장한 파일 삭제되기까지 걸리는 시간 설정 -1로 설정하면 영원히 삭제되지 않음

주키퍼와 실행 아이피 지정 → ec2에서 같이 실행 시킬것임으로 여기로 설정
주키퍼 실행
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
#jvm프로세서 보는 상태 명령어, -v : 전달된 인자, -m : 메인 메소드에 전달된 인자
jps -vm
카프카 실행
bin/kafka-server-start.sh -daemon config/server.properties
jps -m
tail -f logs/server.logEC2카프카 정보 확인을 위해 위해 로컬 카프카 폴더에서 실행(bin)
kafka-broker-api-versions --bootstrap-server 13.125.223.247:9092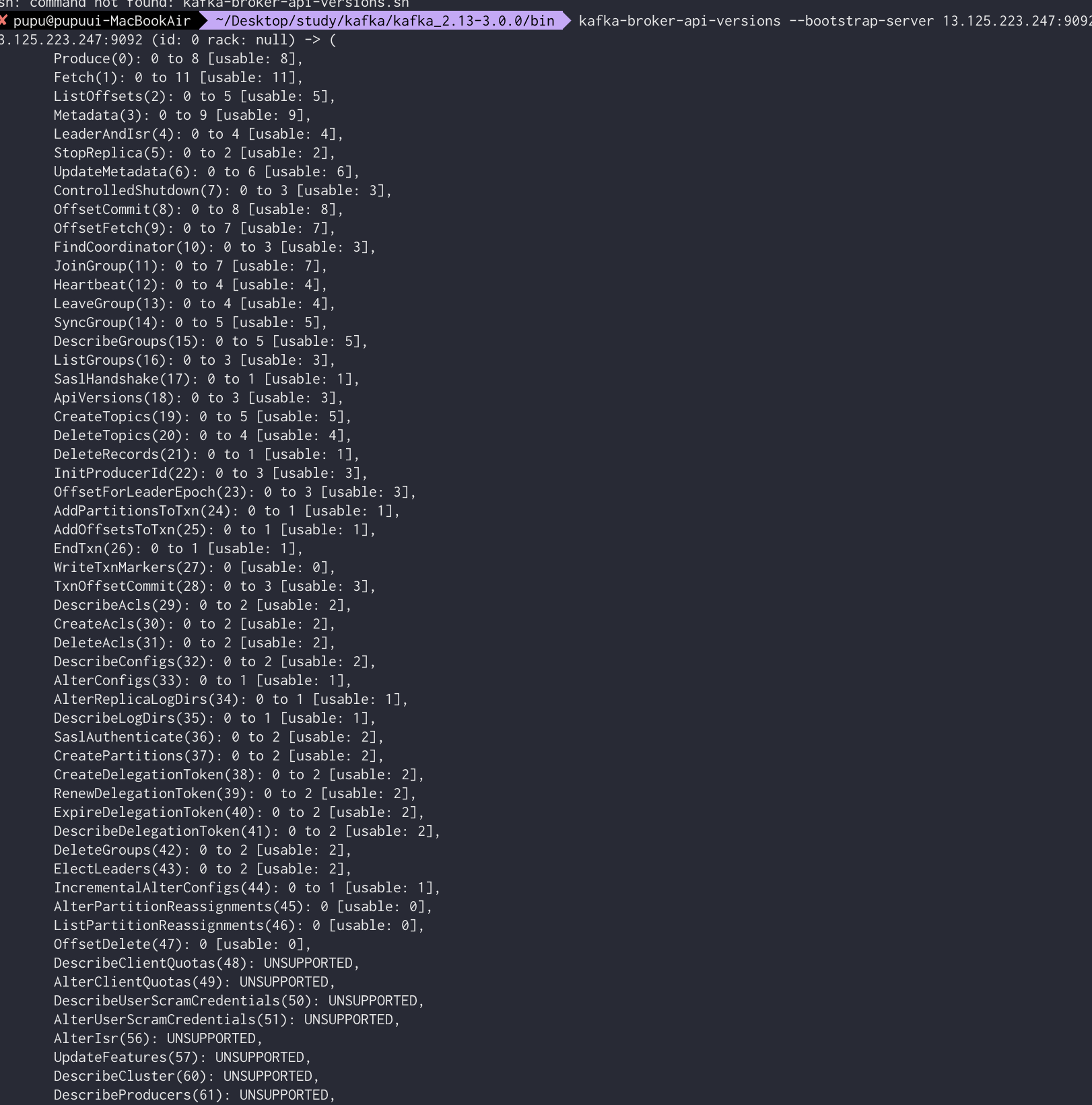
쉬운 접속을 위한 편의 hosts 설정
vi /etc/hosts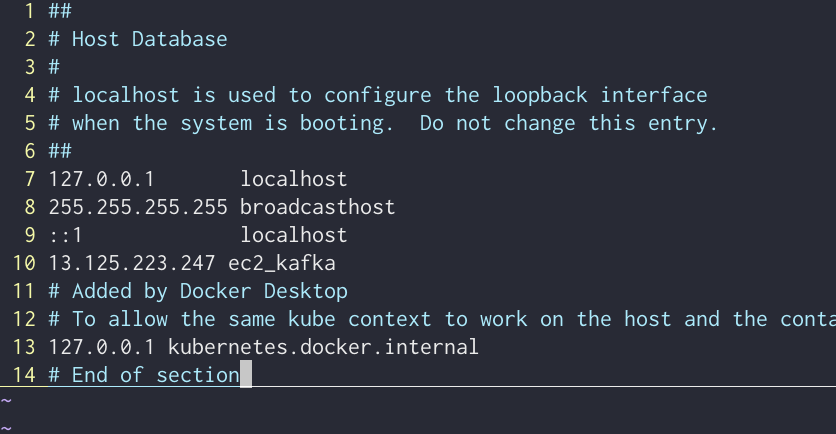
$ cp {pem키 위치} ~/.ssh/
$ chmod 600 ~/ssh/{pem 키}
$ vim ~/.ssh/config
# myServiceName용 접근 설정
Host myServiceName
HostName {public Ip 주소}
User ec2-user
IdentityFile ~/.ssh/myServiceName.pem
$ chmod 700 ~/.ssh/config
$ chmod 700 ~/.ssh/config <- 접속법Kafka-topics.sh
토픽내에 파티션이 존재, 이 파티션을 통해 한번에 처리할 수 있는 데이터를 조절할 수 있음
ec2에서 카프카 실행된 상태에서 다음과 같은 명령어를 치게되면
vi /etc/host에 지정해 놓은 ec2 ip 에 해당 카프카 토픽을 생성한다는 뜻
로컬
kafka-topics --create --bootstrap-server ec2_kafka:9092 --topic hello.kafka추가 옵션 주고 생성
kafka-topics --create --bootstrap-server ec2_kafka:9092 --partitions 3 --replication-factor 1 --config retention.ms=172800000 --topic hello.kafka.2— partitions : 파티션 개수 지정
— replication-factor : 토픽 파티션 복제할 복제 개수 작성
1은 복제하지 않고 사용한다는 의미, 2개 이상부터 복제본을 사용하겠다는 뜻 (최소 1, 최대 브로커 갯수)
—retiontion.ms : 데이터 최대 유지 일
목록 조회
kafka-topics --bootstrap-server ec2_kafka:9092 --list상세조회
kafka-topics --bootstrap-server ec2_kafka:9092 --describe --topic h
ello.kafka.2카프카 옵션 변경
kafka-topics --bootstrap-server ec2_kafka:9092 --topic hello.kafka
--alter --partitions 4
//확인
kafka-topics --bootstrap-server ec2_kafka:9092 --topic hello.kafka
--describe파티션 갯수 늘리기(늘릴수는 있지만 줄일 수는 없다)
kafka-configs --bootstrap-server ec2_kafka:9092 --entity-type topic
s --entity-name hello.kafka --alter --add-config retention.ms=864000000
//확인
kafka-configs --bootstrap-server ec2_kafka:9092 --entity-type topic
s --entity-name hello.kafka --describeconfig파일 수정하여 파일 저장 기간 수정
카프카 스트링 메시지 보내기
키 구분자 없이 단순 메세지 전송
kafka-console-producer --bootstrap-server ec2_kafka:9092 --topic he
llo.kafkaUTF-8 기반으로 Byte 변환 ByteArraySerilaizer로만 직렬화 따라서 String 타입으로만 직렬화 가능!!!
키 구분자 있게 메시지 전송
kafka-console-producer --bootstrap-server ec2_kafka:9092 --topic hello.kafka --property "parse.key=true" --property "key.separator=:"parse.key = true : 키값을 준다는 뜻 따로 설정 없으면 tab으로 구분
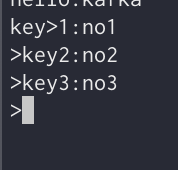
kafka-console-consumer --bootstrap-server ec2_kafka:9092 --topic hello.kafka --from-beginningec2_kafka 토픽에 쌓인 데이터를 확인함
메세지 key값도 같이 출력
kafka-console-consumer --bootstrap-server ec2_kafka:9092 --topic
hello.kafka --property print.key=true --property key.seperator="-" --group hello-group --from-beginning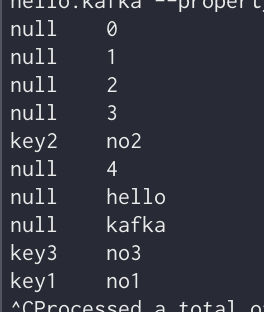
—property 옵션을 주고
—print.key = true로 설정,
—key.sparator 설정,
—group옵션으로 컨슈머 그룹 지정
이 컨슈머 그룹을 통해 가져간 토픽 메시지는 가져간 메시지에 대한 커밋을 함.
커밋이란 컨슈머가 특정 레코드까지 처리를 완료 했다고 레코드 오프셋 번호를 카프카 브로커에 저장하는 것
__consumer_offsets 이름의 내부 토픽에 저장됨
kafka group 하기
kafka-consumer-groups --bootstrap-server ec2_kafka:9092 --list hello-group해당 그룹 상세 정보 조회
kafka-consumer-groups --bootstrap-server ec2_kafka:9092 --group hel
lo-group --describe
최상단 = 가장 최신순
hello group의 그룹안에서 hello.kafka 토픽안에 3번 파티션이 가장 마지막으로 커밋했으며, 현재 가장 최신 오프셋은 5이다(데이터 들어올 떄마다 1씩 증가)
랙 : 컨슈머 그룹이 토픽의 파티션에 있는 데이터를 가져가는데 얼마나 지연이 발생했는지 알려줌
이와 같은 상세정보 파악으로 인가된 사람에게 사용중인지 ip등으로 확인 가능
평균 처리량을 알아 볼 수 있는 kafka-verfiable-producer(test사용용도)
kafka-verifiable-producer --bootstrap-server ec2_kafka:9092 --max-m
essage 10 --topic verify-test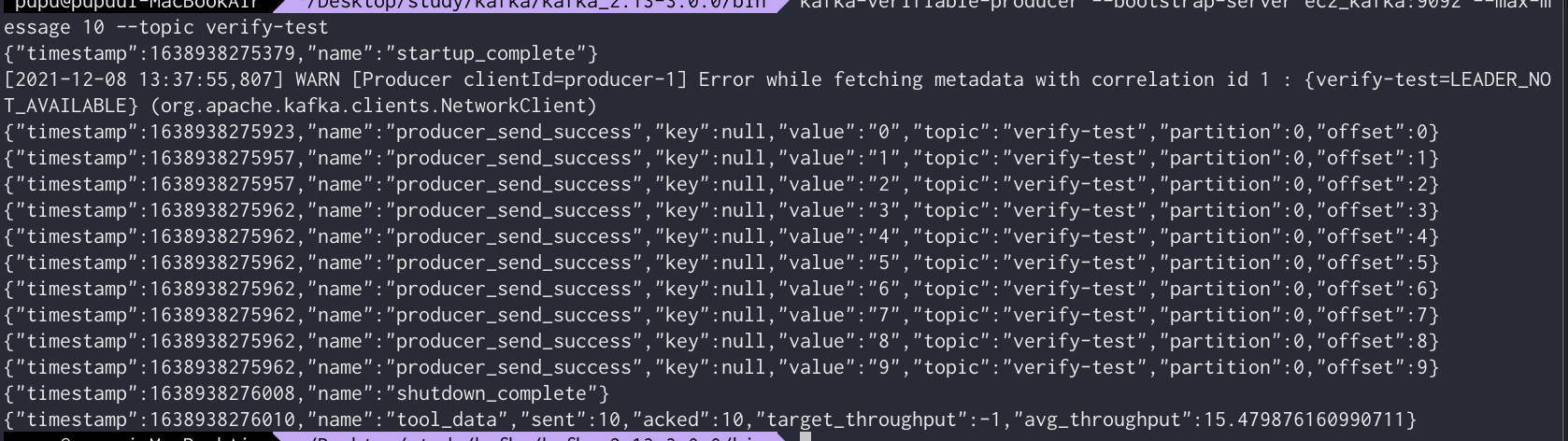
—topic 뒤에 메시지를 보낼 목적지 입력
적재된 토픽 데이터 지우기
vi delete-topic.json -> 삭제하고자 하는 데이터에 대한 정보를 파일로 저장하기 위해 json 타입으로 생성
"partitons":[{"topic":"test", "partition":0,"offset":50}],"version":1}
#삭제 파일 실행
kafka-delete-records --bootstrap-server ec2_kafka:9092 --offset-json-file delete-topic.json
결과 출력
