Network layer에서 Internet protocol에 대해서 알아보자
A) IPv4 datagram format

-
버전 번호
- 4비트로 데이터그램의 IP 프로토콜 버전을 명시한다.
- 라우터는 버전 번호를 확인하여 데이터그램의 나머지 부분을 어떻게 해석할지 결정한다.
- 다른 버전의 IP는 다른 데이터그램 포맷을 사용한다.
- 4비트로 데이터그램의 IP 프로토콜 버전을 명시한다.
-
헤더 길이
- IPv4 데이터그램은 헤더에 가변 길이의 옵션을 포함하므로 이 네 비트로 IP 데이터그램에서 실제 페이로드가 시작하는 곳을 결정한다.
- 대부분의 IPv4는 옵션을 포함하지 않으므로 대체로 IPv4 데이터그램 헤더는 20바이트다.
- IPv4 데이터그램은 헤더에 가변 길이의 옵션을 포함하므로 이 네 비트로 IP 데이터그램에서 실제 페이로드가 시작하는 곳을 결정한다.
-
서비스 타입
- IPv4 헤더에 포함된 서비스 타입 비트는 각기 다른 유형의 IP 데이터그램을 구별한다.
-
Datagram 길이
- 바이트로 계산한 IP 데이터그램의 전체 길이다.
- 총 16비트를 차지하므로 IP 데이터그램의 최대 길이는 65,535 바이트이지만 1,500보다 큰 경우는 거의 없다.
-
식별자, 플래그, 단편화 오프셋
- IP 단편화와 관련이 있는 필드들이다.
- 큰 IP 데이터그램이 여러 개의 작은 IP 데이터그램으로 분할된 다음 목적지로 독립적으로 전달되며, 여기서 페이로드 데이터가 최종 호스트의 트랜스포트 계층으로 전달되기 전에 다시 모인다.
-
TTL(time to live)
- 네트워크에서 데이터그램이 무한히 순환하지 않도록 한다(Routing loop).
- 라우터가 데이터그램을 처리할 때마다 감소하고, 이 필드가 0이 되면 데이터그램을 폐기한다.
-
프로토콜
- 일반적으로 IP 데이터그램이 최종목적지에 도착했을 때만 사용된다.
- 이 필드값은 IP 데이터그램에서 데이터 부분이 전달될 목적지의 트랜스포트 계층의 특정 프로토콜(TCP, UDP)을 명시한다.
- IP 데이터그램에서 이 필드는 트랜스포트 계층에서 포트 번호 필드와 역할이 유사하다.
-
헤더 체크섬
- 헤더 체크섬은 라우터가 수신한 IP 데이터그램의 비트 오류를 탐지하는데 도움을 준다.
- 라우터는 오류 검출된 데이터그램을 폐기한다.
- TTL 필드와 옵션 필드의 값은 변경되므로 체크섬은 각 라우터에서 재계산되고 저장되어야 한다.
- 트랜스 포트 계층과 네트워크 계층에서 오류 검사를 수행하는 이유
- IP 헤더만 IP 계층에서 체크섬을 수행하지만 TCP/UDP 체크섬은 전체 TCP/UDP 세그먼트를 계산한다.
- TCP/UDP와 IP는 동일한 프로토콜 스택에 속할 필요가 없다. 원리상 TCP는 IP가 아닌 곳 위에서도 운영될 수 있다.
-
출발지와 목적지 IP 주소
- 출발지가 데이터그램을 생성할 때, 자신의 IP 주소를 출발지 IP 주소 필드에 삽입하고 목적지 IP 주소를 목적지 IP 주소 필드에 삽입한다.
-
옵션
- IP 헤더 필드를 확장한다.
- 모든 데이터그램 헤더 옵션 필드에 정보를 포함하지 않는 방법으로 오버헤드를 해결하기 위해 헤더 옵션은 거의 사용되지 않는다.
- 데이터그램 헤더가 가변 길이로 데이터 필드 시작점을 초기에 결정할 수 없어 문제를 복잡하게 만든다.
-
데이터(payload)
- 가장 중요한 마지막 필드이다.
- 대부분의 경우 목적지에 전달하기 위해 트랜스포트 계층 세그먼트를 포함한다.
IP Datagram은 총 20 byte의 헤더를 가지며, 각 datagram은 총 40 byte header (IP header + TCP header) 를 갖는다.
B) IPv4 Addressing Scheme
Interface: Host / Router와 물리적 링크 사이의 경계
- Host는 보통 하나의 Interface만을 가진다.
- Router는 연결된 링크 당 하나씩 여러개의 Interface를 가질 수 있다.
모든 Host / Router는 IP Datagram을 송수신할 수 있으므로 각 Host와 Router Interface는 IP 주소를 가져야한다.
IP Address
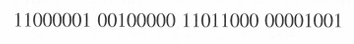
- dotted-decimal notation: 32 bit (4 byte)로 각 byte마다 .으로 구분한다.
- 위 주소는 193.32.216.9 와 같다.
Q) IP 주소는 어떻게 결정되는가?
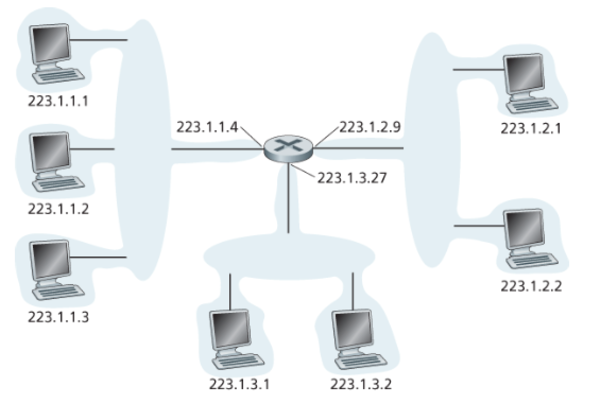
- 위 사진의 왼쪽 Interface는 모두 223.1.1.xxx 형식의 IP 주소를 갖는다.
- 4개의 Interface가 중계하는 Router없이 하나의 네트워크에 서로 연결되어 있다.
- 이 네트워크는 subnet을 구성한다고 할 수 있다.
- IP Addressing Scheme는 이 subnet에 223.1.1.0/24라는 주소를 할당한다.
- subnet mask: /24에 해당하며, 32 bit 주소의 첫 24 bit가 subnet address라는 것을 의미한다.
-
subnet IP의 정의는 여러 호스트를 라우터 인터페이스에 연결하는 이더넷 세그먼트만을 의미하는 것은 아니다.
-
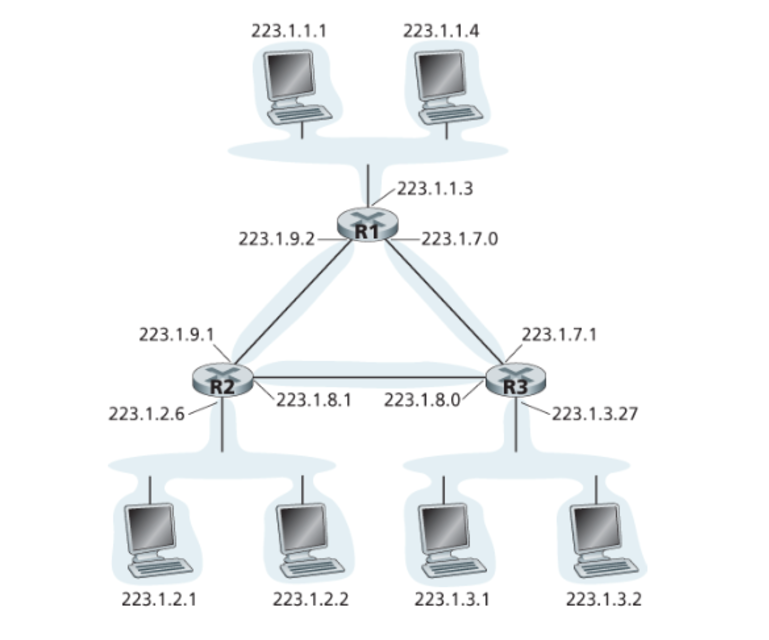
위 그림을 보면 3개의 라우터도 점대점으로 연결되어있는 것을 볼 수 있다.
-
여기서는 호스트와 라우터의 연결 뿐만 아니라 라우터 간의 연결에서도 서브넷을 볼 수 있다.
-
총 6개의 서브넷을 찾을 수 있다.
subnet definition
서브넷을 결정하려면 먼저 호스트나 라우터에서 각 인터페이스를 분리하고 고립된 네트워크를 만든다. 이 고립된 네트워크의 종단점은 인터페이스의 끝이 된다. 이렇게 고립된 네트워크 각각을 서브넷이라고 부른다.
CIDR (Classless InterDomain Routing)
Subnet addressing Scheme를 일반화 한다.
- Subnet addressing Scheme: a.b.c.d/x
- x: 주소 첫 부분의 비트 수이다.
- x는 Most significant bit (MSB) 를 의미하고 IP 주소의 네트워크 부분을 구성한다.
- address prefix 또는 network prefix 라고 부른다.
- Forwarding table의 크기를 줄여준다.
- 나머지 32-x bit: subnet 내부에서의 구별에 사용된다.
- Subnet 내부에서의 packet 전달에 사용될 수 있다.
- Subnet 내에 또 다른 subnet이 있을 수 있다.
Classful addressing
IP 주소의 네트워크 부분을 정확히 1, 2, 3 byte로 제한하고, subnet을 각각 A, B, C class network로 분류하는 주소 체계
- 많은 subnet을 커버할 수 없다는 단점이 존재한다.
- CIDR이 채택되기 전에 사용되던 주소 체계
Broadcasting address
255.255.255.255로 같은 subnet에 존재하는 모든 Host에 전달된다.
Address Block 획득
기관의 subnet에서 사용하기 위한 IP address block을 얻기 위해, 네트워크 관리자는 먼저 이미 할당받은 주소의 큰 block에서 주소를 제공하는 ISP와 접촉해야 한다.

- 위 예시에서 처럼 ISP는 Address block을 작은 Address block으로 나누고, 여러 subnet을 지원할 수 있다.
- ISP는 ICANN으로 부터 Address block을 할당받는다.
Host address 획득: Dynamic Host Configuration Protocol
ISP와 기관 거쳐 얻은 subnet Address block에서, Host가 배정되는 IP address를 자동으로 얻을 수 있도록 하는 것
- 네트워크 관리자는 해당 Host가 네트워크에 접속하고자 할 때마다 동일한 IP 받게 할 수 있다.
- 네트워크 관리자는 해당 Host가 네트워크에 접속하고자 할 때마다 다른 임시 IP 주소를 할당 할 수 있다.
- 추가로, Host가 서브넷 마스크, 첫 번째 홉 라우터 주소나 로컬 DNS 서버 주소 같은 추가 정보를 얻게 해준다.
네트워크에서 자동으로 Host와 연결해주기 때문에 Plug and play protocol 또는 Zero-configuration protocol 이라고도 한다.
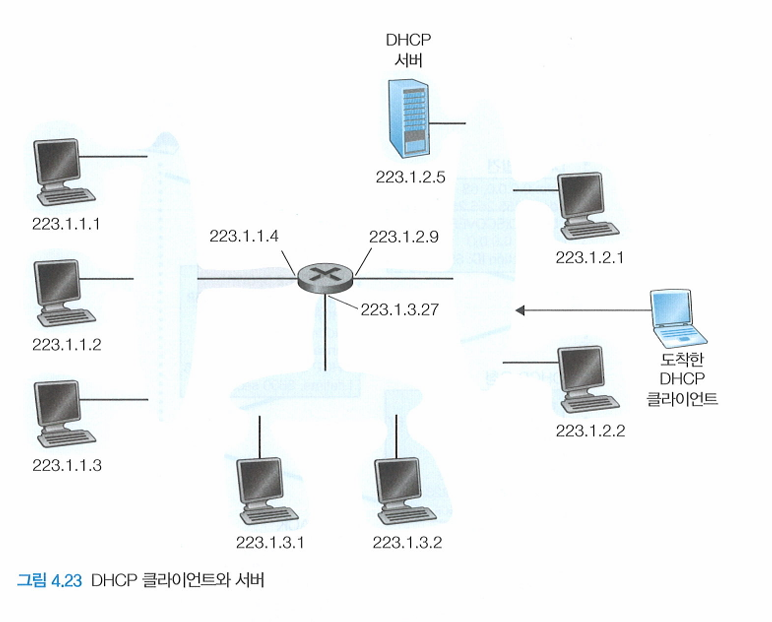
- DHCP는 Server - client protocol 이다.
- 각 subnet은 DHCP sever를 가진다.
- 만약 DHCP server가 존재하지 않는다면, DHCP sever address를 알려줄 DHCP connection agent가 필요하다.
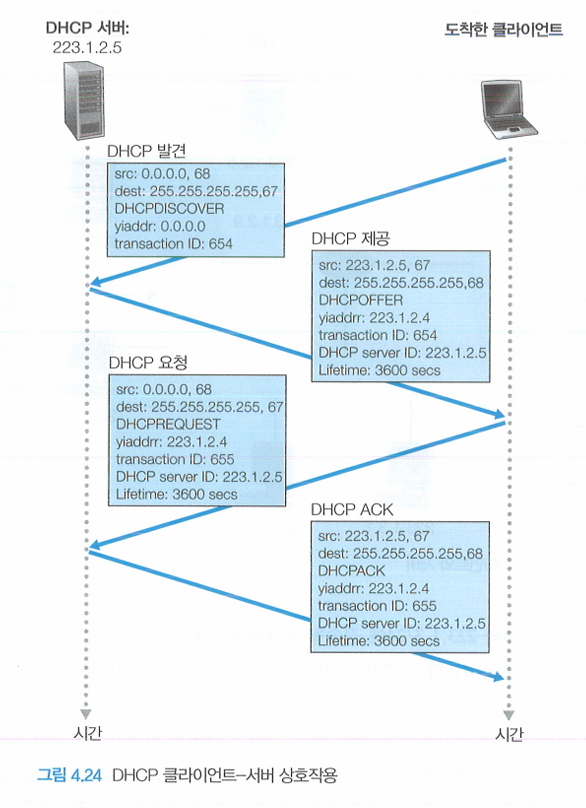
DHCP의 동작
새로운 호스트가 도착하였을 때, 수행되는 DHCP 과정을 알아보자.
yiaddr: 새롭게 도착한 client에 할당될 주소
-
DHCP 서버 발견
- DHCP discover message: Port number 67으로 UDP packet을 보낸다.
- 정확한 Server의 주소를 모르기 때문에 Broadcasting address를 이용한다.
-
DHCP 서버 제공
- Client로부터 가장 가까이 있는 DHCP Server가 DHCP offer message로 client에 응답한다.
- 이때에도 Broadcasting address를 이용한다.
- 각각의 서버 제공 메시지는 수신된 발견 메시지의 트랜잭션 ID, 클라이언트에 제공된 IP 주소, 네트워크 마스크, IP address lease time (IP 주소 임대 기간)을 포함한다.
-
DHCP request
- Server의 DHCP offer message에 대해 DHCP request message로 응답한다.
-
DHCP ACK
- Server는 request에 대해 DHCP ACK message로 응답한다.
-
상호작용 종료
- Client가 DHCP ACK message를 수신하면 상호작용을 종료한다.
- 이후, IP address lease time 동안 DHCP allocate IP address 를 사용 가능하다.
C) NAT (Network Address Translation)
IP Address의 변경이 필요할 때 어떻게 처리하는지를 알아보자.
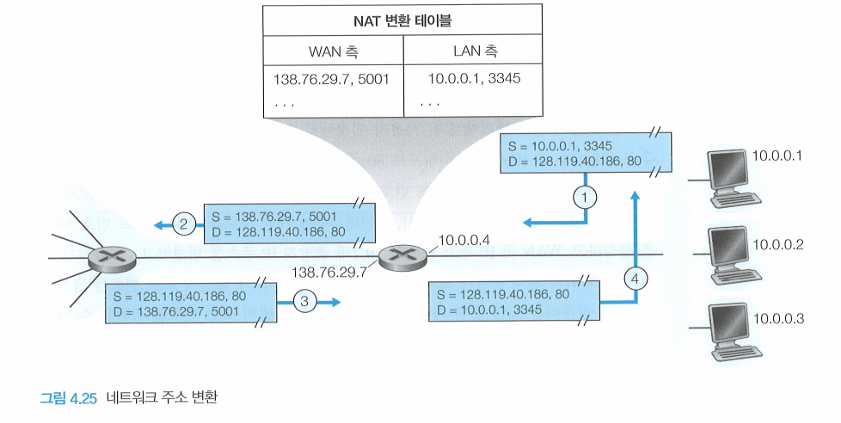
- 홈 네트워크의 사설 네트워크 주소는 10.0.0.0/24
- 이는 RFC 1918에서 예약된 사설 IP 주소 범위 중 하나로, 외부 인터넷에서는 사용되지 않으며, 홈 네트워크 내부에서만 의미가 있다.
Q) 위와 같은 경우 Gloval Internet과의 송수신은 어떻게 처리할까?
NAT-enabled router를 이용하여 해결이 가능하다.
NAT-enabled router는 외부 세계로는 Router처럼 보이지 않고 하나의 IP 주소를 갖는 하나의 장비로 동작한다.
-
그림을 보면 홈 라우터를 떠나 인터넷으로 가는 트래픽의 출발지 IP 주소는 138.76.29.7, 라우터의 출력 라우터 인터페이스의 IP 주소를 갖는다.
-
홈으로 들어오는 트래픽의 목적지 주소는 마찬가지로 138.76.29.7을 가져야한다.
-
이때의 주소는 DHCP Server로부터 얻어온다.
-
본질적으로 NAT 가능 라우터는 외부에서 들어오는 홈 네트워크의 상세한 사항을 숨긴다.
Q) NAT Router에 같은 목적지 IP 주소를 가진 Datagram이 여러개 도착하면 어떻게 구별할 수 있을까?
NAT router에서 NAT translation table을 사용하고, 그 테이블에 IP 주소와 Port nubmer를 포함한다.
예시


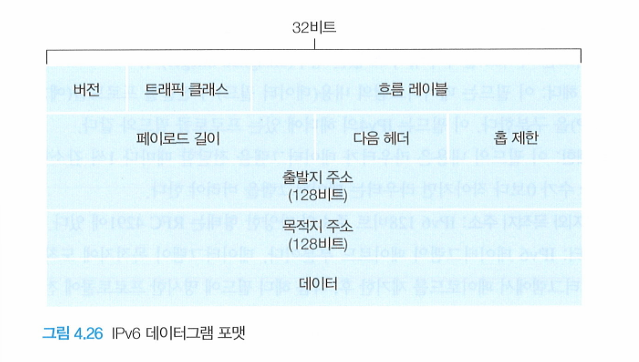
D) IPv6 Datagram format
-
확장된 주소 기능
- IPv6는 IP 주소 크기를 32비트에서 128비트로 확장했으므로 IP 주소가 고갈되는 일은 발생하지 않을 것이다.
-
간소화된 40 바이트 헤더
- 40 바이트 고정 길이 헤더는 라우터가 IP 데이터그램을 더 빨리 처리하게 해준다.
- 새로운 옵션 인코딩은 유연한 옵션 처리를 가능하게 한다.
-
흐름 레이블링
- 정의하기 어려운 흐름을 갖고있다.
- 아직 정확한 의미는 정의되지 않았지만, 언젠가 필요할 흐름 차별화를 예견하여 구현하였다.
-
버전
- 4비트 필드는 IP 버전 번호를 인식한다.
- IPv6 = 6
-
트래픽 클래스
- IPv4의 TOS 필드와 비슷한 의미로 만든 8비트 필드는 흐름 내의 SMTP 이메일 같은 애플리케이션의 데이터그램보다 Volp 같은 특정 애플리케이션 데이터그램에 우선순위를 부여하는데 사용된다.
-
흐름 레이블
- 데이터그램의 흐름을 인식하는데 사용된다.
-
페이로드 길이
- 이 16비트 값은 IPv6 데이터그램에서 고정 길이 40바이트 패킷 헤더 뒤에 나오는 바이트 길이이며, 부호 없는 정수다.
-
다음 헤더
- 이 필드는 데이터그램의 내용이 전달될 프로토콜을 구분한다.(TCP, UDP)
-
홉 제한
- 라우터가 데이터그램을 전달할 때 마다 1씩 감소하고, 0이되면 데이터그램이 라우터에 의해 버려진다.
-
출발지와 목적지 주소
- 출발지와 목적지 주소를 담고 있다.
-
데이터
- IPv6 데이터그램의 페이로드 부분이다. 데이터그램이 목적지에 도착하면 IP 데이터그램에서 페이로드를 제거한 후, 다음 헤더 필드에 명시한 프로토콜에 전달한다.
IPv4에는 있지만 IPv6에는 없는 필드
-
단편화/재결합
- IPv6에서는 단편화와 재결합을 출발지와 목적지만이 수행한다.
- 라우터가 받은 IPv6 데이터그램이 너무 커서 출력 링크로 전달할 수 없다면 라우터는 데이터그램을 폐기하고 너무 크다는 ICMP 오류 메시지를 송신자에게 보낸다.
- 송신자는 데이터를 IP 데이터그램 크기를 줄여서 다시 보낸다.
- 라우터에서 이 기능을 수행하는 것은 시간이 오래 걸리므로 이 기능을 삭제하여 IP 전달 속도를 증가시켰다.
-
헤더 체크섬
- 트랜스포트 계층 프로토콜과 데이터 링크 프로토콜은 체크섬을 수행하므로 IP 설계자는 네트워크 계층의 체크섬 기능이 반복되는 것으로 생략해도 될 것이라 생각하여 삭제했다.
-
옵션
- IPv4에서도 잘 사용되지 않았던 필드가 사라지고 고정 헤더의 길이를 갖게되었다.
- 옵션 필드는 IPv6 헤더에서 다음 헤더 중 하나가 될 수 있다.
IPv4에서 IPv6로의 전환
IPv4는 IPv6를 처리하는 것이 불가능하기 때문에 전환이 필요하다.
flag day 선언
모든 인터넷 장비를 끄고 IPv4에서 IPv6로 업그레이드하는 시간과 날짜를 정하는 법
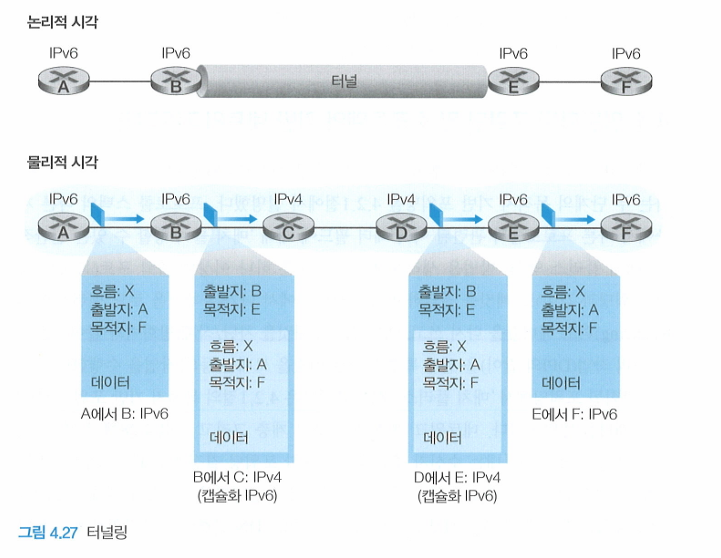
Tunneling
두 IPv6 노드(그림에서는 B와 E)가 IPv6 데이터그램을 사용해서 작동한다고 가정해보자.
물론 이들은 IPv4 라우터를 통해 연결되어있다. 이렇게 IPv6 노드 사이에 연결되어있는 IPv4 라우터들을 터널(tunnel)이라고 한다.
-
터널의 송신 측에 있는 IPv6 노드는 IPv6 데이터그램을 받고 IPv4 데이터그램의 데이터 필드에 이것을 넣는다.
-
IPv4 데이터그램에 목적지 주소를 터널의 수신 측에 IPv6 노드(E)로 적어서 터널의 첫 번째 노드(C)에 보낸다.
-
터널 내부에 있는 IPv4라우터는 IPv4 라우터는 IPv4 데이터그램이 IPv6 데이터그램을 갖고 있다는 사실을 모른채 다른 데이터그램을 처리하는 방식으로 IPv4 데이터 그램을 처리한다.
-
터널 수신 측에 있는 IPv6 노드는 IPv4 데이터그램을 받고 이 IPv4 데이터그램이 실제 IPv6 데이터그램임을 결정한다.
-
다음 노드에 IPv6 데이터그램을 보낸다.
