About algorithm
problem: A well-specified input and output
algorithm: a well-defined precedure to solve a problem
about computer? > computional problem & algorithm
How to analyze the running tume of an algorithm?
- 우리가 직접 실제 Running Time을 구하는 것은 어렵다.
- 우리는 the number of instructions을 직접 세서 실제 running time을 예측할 수 있다.
- Instructions: Arithmetic(사칙연산, 올림, 내림 등) , Data movement(값 할당, 데이터 복사 등), Control(조건, 함수 호출, 재귀 함수 등)
- 보통 input size에 비례해서 증가한다.
Peseudocode Conventions
-
Indentation: Used to indicate block structure, such as for loops and conditionals. This removes the need for explicit begin and end statements, improving clarity.
-
Looping Constructs: while, for, repeat-until, and if-else constructs.
-
Loop Counter Syntax: Use to for incrementing counters and downto for decrementing. Optionally, you can use by to change the step size for the loop counter.
-
Comments: The symbol // indicates a comment.
-
Multiple Assignments: Expressions like i = j = e mean both i and j are assigned the value of e. This is equivalent to first assigning j = e and then i = j.
-
Variables: Variables such as i, j, and key are local to the procedure, and global variables are not used without explicit indication.
-
Array Access: Arrays are accessed with square brackets. A[i] refers to the ith element of array A. The notation A[1:j] refers to a subarray of A containing elements from index 1 to j.
-
Object Attributes: Compound data types are treated as objects with attributes. You access attributes by writing object.attribute. For example, A.length refers to the length of array A.
-
Pointers and Assignment: A variable representing an array or object is treated as a pointer to its data. When assigning y = x, both x and y refer to the same object. Changing x.attribute will also change y.attribute.
Pointer attributes can cascade, such as x:f:g, which is equivalent to (x:f).g. -
NIL: A pointer that does not refer to any object is assigned the special value NIL.
-
Parameter Passing: Parameters are passed by value, meaning the procedure receives its own copy of the parameters. Changes to the parameter inside the procedure do not affect the original parameter. However, when passing objects, a pointer to the object is copied, so changes to the object's attributes are visible to the caller.
-
Return Statement: This immediately transfers control back to the calling procedure. A return statement may pass back one or more values.
-
Boolean Operators: The and and or operators are short-circuiting. For x and y, if x is FALSE, y is not evaluated. For x or y, if x is TRUE, y is not evaluated.
-
Error Handling: The keyword error indicates that an error occurred, and the calling procedure is responsible for handling it.
Sorting Algorithm
정렬 알고리즘
Insertion Algorithm
Idea: 이미 정렬되어져 있는 배열에 삽입하자
pseudocode of Insertion algorithm
INSERTION-SORT(A)
for j=2 to A.length
key = A[j]
//Insert A[j] into the sorted sequence A[1...N]
i = j-1
while(i>0 & A[i] > key)
A[i+1] = A[i]
i = i-1
A[i+1] = key
}Running time of Insertion sort
T(N) = C1n + C2(n-1) + C4(n-1) + C5 + C6 + C7 + C8(n-1)
n: A의 길이, Ci = 각 라인에 대한 가중치, ti = j가 상수일 때 5~7 라인의(while문) 반복 횟수, T(N) = 전체 소요 시간
for, while 문의 조건은 한 번 더 실행된다. 마지막 조건를 체크하기 때문이다.
Best case running time
Best case: A[1...n] is already sorted, so tj for j 2,3,...,n
T(N)
= C1n + C2(n-1) + C4(n-1) + C5 + C8(n-1)
= (C1+C2+C4+C5+C8)n - (C2+C4+C5+C8)
Linear function of n = (n)
Worst case running time
Worst case: A[1..n] is sorted in reverse order, tj for j = 2,3,...,n.
= & =
T(N)
= C1n + C2(n-1) + C4(n-1) + C5() + C6() + C7() + C8(n-1)
= (++) + (C1+C2+C4+--+C8)n - (C2+C4+C5+C8)
Quandratic function of n = ()
Space consumption of insertion sort
(n+c) Space
- n space needed for store array.
- c space needed for input numbers or variables.
Merge sort
합치는 것을 이용한 정렬
pseudocode of merge
MERGE(A, p, q, r)
//p=배열 시작, r=배열 끝
n1= q–p+1 //첫 번째 배열의 크기
n2= r–q //두 번째 배열의 크기
//let L[1 .. n1+1] and R[1 .. n2+1] be new arrays
for i=1 to n1
L[i] = A[p+i-1]
for j=1 to n2
R[j] = A[q+j]
L[n1+1] = ∞
R[n2+1] = ∞ //배열 끝에 가장 큰 수를 넣음으로써 i<=n, j<=n과 같은 조건을 추가하지 않는다.
i = 1
j = 1
//merge
for k=p to r
if L[i] ≤ R[j]
A[k] = L[i]
i = i + 1
else
A[k] = R[j]
j = j + 1Running time of merge
()
Main operators: compare and move
- of comparision of movement
- movement는 항상 + 이다.
- 두 배열 중 하나가 먼저 소진된다면, 비교하지 않기 때문에, comparision은 n1+n2 보다 작거나 같다.
- 따라서 of comparision + of movement 2( + ) 이다.
Divide-and-Conquer
Devide: n개의 keys를 n/2의 keys를 가진 두 개의 배열로 나눈다.
Conquer: Merge sort를 재귀적으로 이용하여 두 개의 배열을 정렬한다.
Merge: 두 정렬된 배열을 합친다.
MERGE-SORT(A,p,r)
if p<r
q = (p+r)/2 //나머지는 버림
MERGE-SORT(A,p,q)
MERGE-SORT(A,q+1,r)
MERGE(A,p,q,r)Running time of Merge sort
- Divede: ()
- Conquer: 2T(n/2)
- Merge: ()
T(n): Merge sort running time
= c if n = 1
= 2T() + cn if n > 1
c는 크기 1의 배열일 때, Merge sort를 처리하는 시간이다.
Recursion Tree of Merge sort
Merge sort를 두 갈래로 나뉘는 tree 형태로 표현할 수 있다.
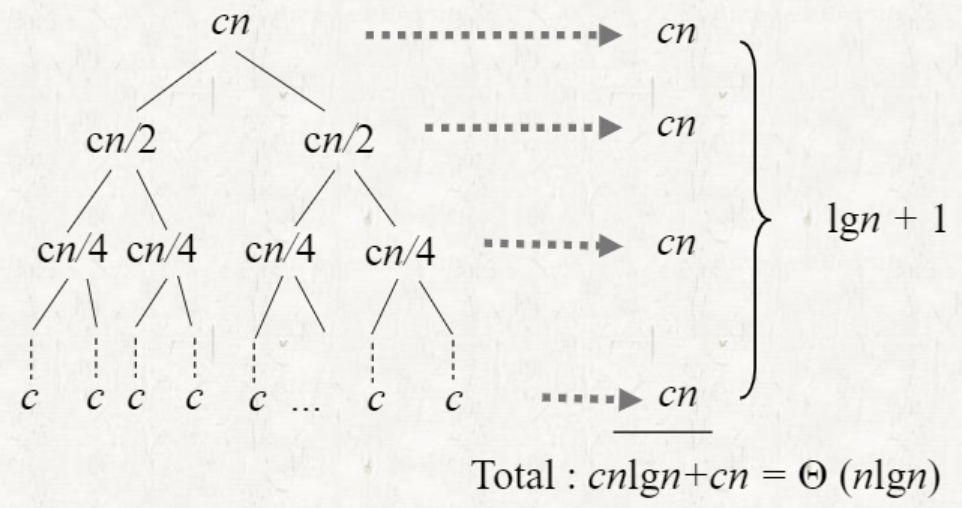
위 그림에서, 각 레벨에서 각 step이 merge 될 때의 소요시간은 이다. 는 가장 위 부터 0...k 이다.
Total time:
**Merge Sort의 running time은 best case과 worst case에 관계없이 이다.
Horner's rule
곱셈의 횟수를 계산하자
를 계산하게 되면 이다.
대신 의 형태로 사용하면 이다.
Binary search
오름차순으로 정렬된 배열 A가 있는 상황을 가정하자
- 우리가 찾고자하는 값을 KEY라고 하자
- 배열의 중간 지점을 로 찾는다.
- 배열의 중간 지점의 값과 KEY값을 비교한다.
- KEY값이 중간 지점의 값보다 크면 중간 지점의 오른쪽을 재귀적으로 탐색한다.
- KEY값이 중간 지점의 값보다 작으면 중간 지점의 왼쪽을 재귀적으로 탐색한다.
- KEY값과 동일한 값을 찾으면 멈춘다.
Running time of Binary sort
T(N) = 2(T()) + '
Best case: 배열A 중간에 KEY
Worst case: 과정 중 마지막 경우가 KEY
Selection sort
배열 A가 있을 때, 정렬된 A[1...i]가 있고 아직 정렬되지 않은 A[i+1...N]이 있다고 가정하자.
- 아직 정렬되지 않은 A[i+1...N]을 하나씩 탐색하여 최댓값/최솟값을 찾는다.
- 그 값을 A[1...i]의 끝자리에 이어 붙인다.
Running time of Selection sort
T(N) = T(N-1) +
여기서 은 최댓값/최솟값을 찾는 시간이다.
을 이라고 하면 T(N) = T(N-1) + 이다
T(N) =
best case, worst case에 관계없이 이다.
