개요
기존에 Databse 정규화와 비정규화를 알고 있었다. 하지만 그게 어떻게 사용이 되고 왜 사용하는지 잘 몰랐고, 이직을 준비하면서 알아야할 거 같아서 정리를 하기로 한다. (정규화와 비정규화 둘을 나눠서 정리를 하려한다.)
⚙️ Database 정규화란?
관계형 데이터베이스 설계에서 중복을 최소화하기 위해서 데이터를 구조화하는 프로세스를 정규화라고 한다. 정규화 기본 목표는 관련이 없는 함수 종속성은 별개의 릴레이션으로 표현하는 것이다.
정규화 결과를 정규형이라고 하며, 정규형은 기본 정규형과 고급 정규형으로 나뉜다.
- 기본 정규형 : 제 1,2,3 정규형, BCNF(보이스/코드 정규형)
- 고급 정규형 : 제 4,5 정규형

정규화의 장점?
- 데이터베이스 변경 시 이상 현상(Anomaly)을 제거할 수 있다.
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
- 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 되어 응용 프로그램의 생명을 연장 시킨다.
정규화의 단점?
- 릴레이션의 분해로 인한 릴레이션 간의 JOIN 연산이 많아진다.
- 질의에 대한 응답 시간이 느려질 수 있다.
- 데이터의 중복 속성을 제거하고 결정자에 의해서 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
- 따라서 데이터를 처리할 때 속도가 빨라질 수도, 느려질 수도 있다.
- JOIN이 많아서 성능 저하가 나타나면 반정규화를 적요할 수 있다.
제 1 정규형 (1NF)
제 1 정규형은 다음과 같은 규칙들을 지켜야한다.
- 각 컬럼이 하나의 속성만을 가져야한다.
- 하나의 컬럼은 같은 종류나 Type의 값을 가져야한다.
- 각 컬럼이 유일한 이름을 가져야한다.
- 컬럼의 순서가 상관없야한다.

제 2 정규형 (2NF)
제 2 정규형은 다음과 같은 규칙을 만족해야한다.
- 1 정규형을 만족한다.
- 모든 컬럼이 부분적 종속이 없어야한다. (모든 컬럼이 완전 함수 종속을 만족한다.)
부분적 종속 : 기본키 중 특정 컬럼에만 종속이 되는 것.
완전 함수 종속 : 기본키의 부분집합이 결정자가 되어선 안된다.

제 3 정규형 (3NF)
제 3 정규형은 다음과 같은 규칙을 만족해야한다.
- 2 정규형을 만족한다.
- 기본키를 제외한 속성들 간의 이행 종속성이 없어야한다.
이행 종속성은 A -> B, B -> C 일 때 A -> C가 성립이 되면 이행 종속이라고 한다. 즉, A를 알면 B를 알고, 이를 통해서 C를 알 수 있는 경우를 의미.
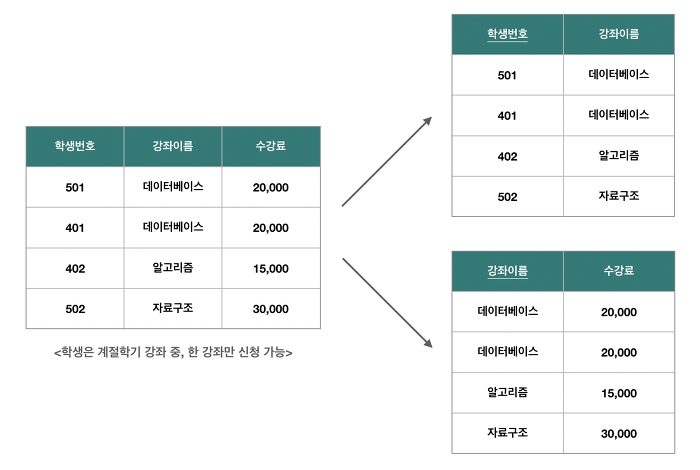
BCNF
릴레이션의 함수 종속 관계에서 모든 결정자가 후보키면 BCNF에 속한다.
하나의 릴레이션에 여러개의 후보키가 존재할 수 있는데, 이련 경우 제 3 정규형까지 모두 만족하더라도 이상 현상이 발생할 수 있다. 이러한 이상현상을 해결하기 위해서 제 3 정규형보다 좀 더 염격한 제약 족건을 제시한 것이 BCNF다.
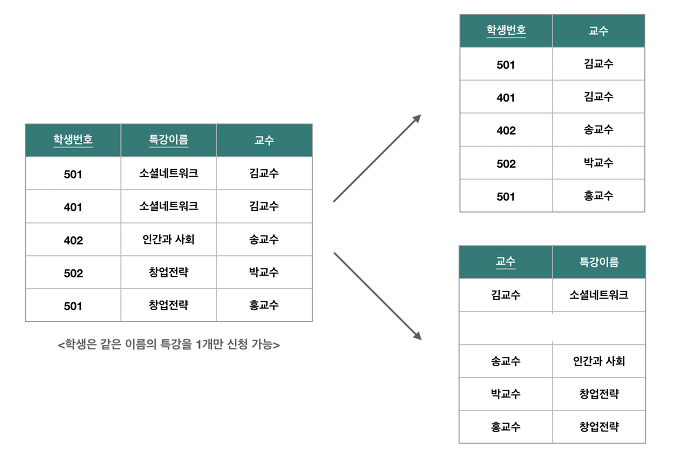
- 학생 번호와 교수 릴레이션은 함수 종속 관계가 성립하지 않는 동등한 학생번호, 교수 속성으로 구성하고 학생번호, 교수가 기본키의 역할을 담당한다. 즉, 후보키가 아니라 결정자가 존재하지 않기 때문에 BCNF에 속한다.
- 교수 및 특강 릴레이션은 교수와 특강이 함수 종속 관계를 띄우며, 교수가 유일한 후보키이자 기본키다. 즉, 후보키가 아닌 결정자가 존재하지 않기 때문에 BCNF에 속한다.
고급 정규형 (제 4,5 정규형)
- 제 4 정규형
- 릴레이션이 BCNF를 만족하면서, 함수 종속이 아닌 다치 종속을 제거해야 만족한다. - 제 5 정규형
- 릴레이션이 제 4 정규형을 만족하면서 후보키를 통하지 않는 조인 종속을 제거해야 만족할 수 있다.
실제로 DB 설계 시 모든 릴레이션이 무조건 제 5 정규형에 속하도록 분리해야 하는 것은 아니다. 오히려 그렇게 되면 비효율적인 경우가 많기 때문이다.
일반적 제 3 정규형이나 BCNF에 속하도록 릴레이션을 분해하여 데이터 중복을 줄이고 이상 현상이 발생하는 문제를 해결한다.
