
안드로이드의 모든 저장소를 한 눈에 살펴보려고 합니다.
저장소 설명, 정책, 이슈를 설명하고 어떻게 동작하는 알아보려고 합니다. ☺️
SharedPreferences & DataStore
SharedPreferences
https://developer.android.com/training/data-storage/shared-preferences?hl=ko
안드로이드에서 제공하는 키-값 쌍 데이터 저장소이고, 기본적으로 XML 형태로 관리합니다.
직접 파일을 읽고 쓰는 것보다 훨씬 쉽고 빠른 접근 방법입니다. 안드로이드 내부 전용 파일에 저장됩니다.
간단하게 예시코드와 주석으로 설명합니다.
/*
1) 파일 이름을 지정합니다. 파일 이름(infomation) 앞에
애플리케이션 id (com.example.kwanhee)를 붙여주는 것이 좋습니다.
*/
val fileName = "com.example.kwanhee.infomation"
/*
2) 공유 파일을 가져옵니다. mode의 경우, MODE_PRIVATE을 사용하여 앱 외부에서 접근이 불가능하도록 지정합니다.
*/
val sharedPref = getSharedPreferences(fileName, MODE_PRIVATE)
/*
3) 에디터를 사용해 데이터를 쓸 수 있습니다.
*/
val editor = sharedPref.edit()
editor.putString("name", "JoKwanhee")
/*
4) 데이터를 저장합니다.
apply() | commit()
비동기 | 동기
(editor 에서 edit {} 람다를 사용해서 default 로 apply() 를 사용할 수 있습니다.)
*/
editor.apply() // 또는 .commit()
/*
5) 데이터 읽기
*/
val userName = sharedPref.getString("name", "")*주의사항 : commit() 으로 데이터를 쓰는 경우, UI 스레드를 차단하는 것을 피해야합니다. (UI 렌더링이 일시정지 될 수 있습니다.)
만약에 중요한 정보를 저장하려면, EncryptedSharedPreferences (Android Security)를 적용하는 것도 좋은 방법입니다.
- commit() 는 동기적으로 apply() 는 비동기적으로 동작합니다. 그렇다면 apply()를 기본으로 사용할텐데, commit() 은 언제 사용하면 좋을까요?
commit()은 스레드를 블록킹할 위험이 있어서 apply()를 권장하비다. 하지만 해당 스레드가 UI 스레드가 아닌 백그라운드 스레드이고, commit() 반환형은 boolean 타입이기 때문에 명확하게 성공/실패를 알기 위해서 좋은 api 입니다.
- 어디에 저장되는 지 확인하고 싶은데, 방법이 있을까요?
앱 내부 저장소에 저장됩니다. SharedPrferences를 사용하고 실행된 앱의 아이디는 com.example.kwnahee 라고 가정하겠습니다.
Android Studio Tool 중에서 Device Explorer가 존재합니다. 해당 Tool을 열고, 아래 경로를 찾아주면 됩니다.
/data/data/com.example.kwanhee/shared_prefs/com.example.kwanhee.infomation.xml
- SharedPreferences 파일 이름 앞에 앱 아이디를 적어주는 이유가 뭘까요?
별도의 라이브러리나 다른 모듈과의 충돌을 방지하기 위해, 고유하게 관리가 필요합니다.
즉, 외부 라이브러리가 SharedPreferences를 사용하면서 중복되는 파일 이름일 수 있으므로 고유한 이름을 만들어주기 위함입니다. 추가적으로 앱의 아이디로 파일 이름을 설정해놓았다면 추적관 관리에 용이하게 됩니다.
com.example.kwanhee 앱이 있다면, 해당 앱에서의 SharedPreferences 저장소 파일은 모두 com.example.kwanhee.{name} 으로 시작하기 때문입니다. 😎
- File I/O 와 SharedPreferences I/O 중 SharedPreferences 가 경량이고, 빠른 이유가 뭔가요?
우선 key-value 형식이기 때문입니다. 일반 텍스트 파일이라면 파싱하여 원하는 값을 찾아야겠지만, 원하는 값을 key를 통해 가져올 수 있으므로 처리가 간단합니다.
key-value 값을 가져오는 것은 알겠지만, 디스크 I/O 발생은 여전하지 않은가? 그렇지 않습니다. 내부 구현체에서는 이를 Map 자료구조를 활용하여 캐싱하고 있습니다.
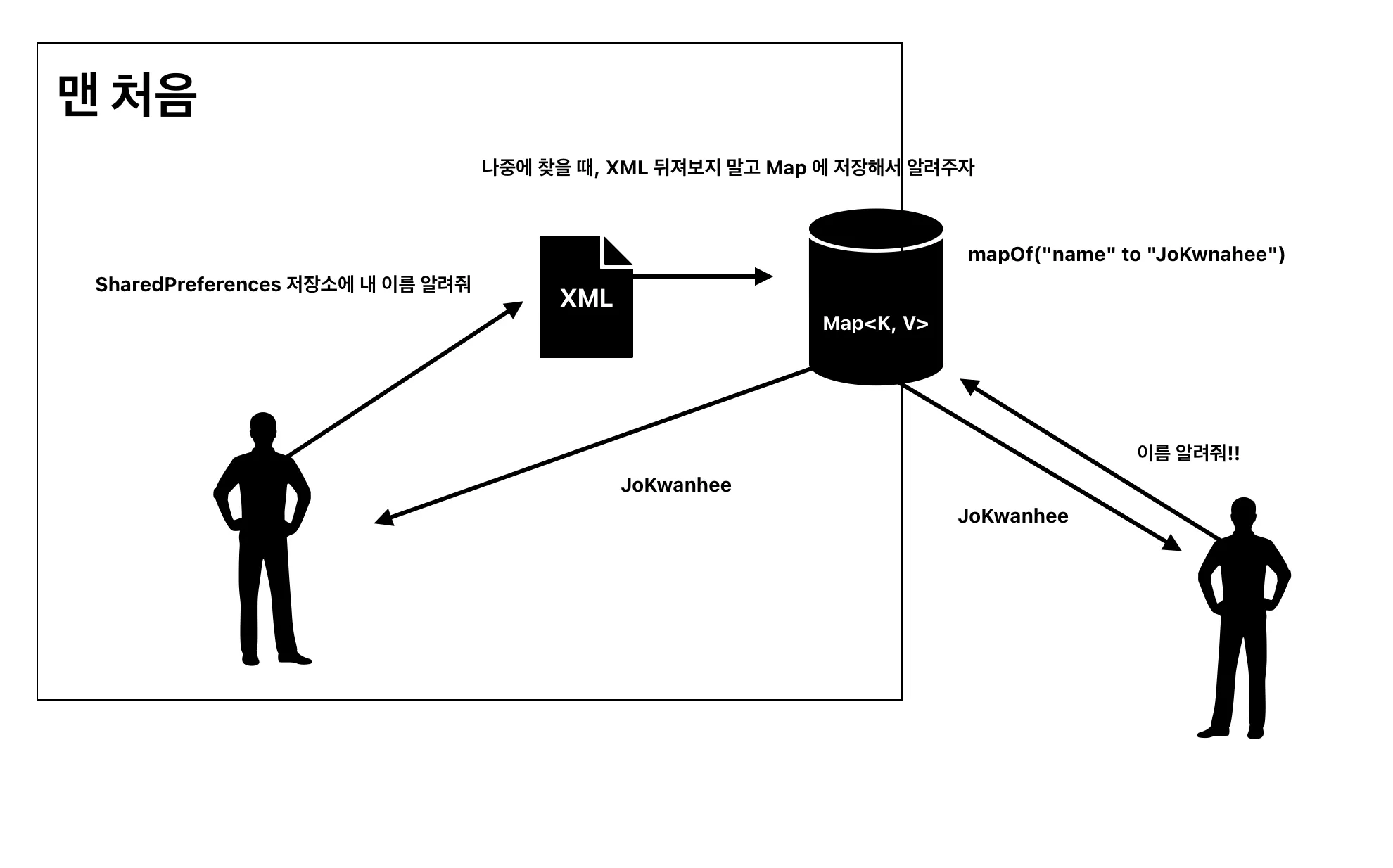
위 그림을 살펴보면 간단한 구조로 캐싱을 진행하고 있습니다.
내부 구현을 어떻게 되어있을까요?
context.getSharedPreferences() API 가 호출되면 내부적으로 SharedPrefencesImpl 클래스가 호출됩니다. 생성자로 startLoadFromDisk() 함수가 호출되어지고, 백그라운드 스레드에서 loadFromDisk() 함수가 호출됩니다. XML key-value 데이터를 Map 데이터로 할당하여 캐싱역할을 해주도록 로직이 구현되어 있습니다.
final class SharedPreferencesImpl implements SharedPreferences {
...
@GuardedBy("mLock")
private boolean mLoaded = false;
private void loadFromDisk() {
synchronized (mLock) {
// 호출한 적이 있다면, return
// return => xml 읽지 않음
if (mLoaded) {
return;
}
...
}
Map<String, Object> map = null;
...
// 실제로 SharedPreferences XML 파일을 읽어옴
if (mFile.canRead()) {
try (BufferedInputStream str = new BufferedInputStream(new FileInputStream(mFile), 16 * 1024)) {
map = (Map<String, Object>) XmlUtils.readMapXml(str);
} catch (Exception e) {
Log.w(TAG, "Cannot read " + mFile.getAbsolutePath(), e);
}
}
...
synchronized (mLock) {
mLoaded = true;
...
if (map != null) {
// SharedPreferences XML 데이터를 mMap 데이터로 할당
mMap = map;
} else {
// 파일이 없는 경우, 새 HashMap으로 초기화
mMap = new HashMap<>();
}
}
}
...
}데이터를 읽어올 때는 어떻게 되어있을까요?
(데이터를 쓸 때는 apply() 또는 commit() 을 사용하여 XML과 mMap 모두 갱신합니다. 디스크 I/O가 발생하는 부분은 쩔 수 없음. 그래도 데이터를 읽을 때 캐시되니깐 다행입니다. ☺️)
간단하게 String을 가져오는 함수입니다. awaitLoadedLocked 함수가 보이네요.
getString 을 빠르게 맨 처음 호출한 경우, XML에서 데이터를 로딩하는게 마무리되지 않아 awaitLoadedLocked() 로 동기화 대기를 걸어주게 되는 것입니다.
@Override
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
awaitLoadedLocked();
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}
// mLoaded가 false면 load가 끝날 때까지 대기합니다.
@GuardedBy("mLock")
private void awaitLoadedLocked() {
...
while (!mLoaded) {
try {
mLock.wait();
} catch (InterruptedException unused) {
}
}
if (mThrowable != null) {
throw new IllegalStateException(mThrowable);
}
}즉, mLoaded가 true인 상태라면, 이미 디스크 로딩이 끝났으므로 다시 디스크를 읽지 않고 mMap을 바로 사용합니다.
자세한 내용은 SharedPreferencesImpl.java 구현체를 확인해주세요!
하지만 Kotlin Coroutine과 Flow를 기반으로 하는 DataStore에 등장으로 SharedPreferences 역할을 대신하고 있습니다. 뿐만 아니라 공식 문서에서도 권장하고 있습니다.
다음은 DataStore에 대해서 알아보도록 하겠습니다.
DataStore
https://developer.android.com/topic/libraries/architecture/datastore?hl=ko
DataStore는 Coroutine-Flow를 지원하고 있으며, 원자성을 보장하고 충돌이 발생하지 않아 데이터를 안전하게 지킬 수 있습니다. 스레드 Safety한 장점도 있습니다.
그렇다면, SharedPreferences 는 버리고 모두 마이그레이션 해야할까요? 그건 아닙니다.
팀 내에서 적절한 판단과 논의로 결정하면 됩니다.
- 아주 간단하게 로컬 저장소를 사용하고 있는가? ⇒ 그렇다면 굳이 DataStore로 마이그레이션하는 것은 오버 엔제니어링이 될 수 있습니다. (하지만 학습이 목표라면 너무너무 긍정적으로 진행해봐도 좋을 것 같아요 ☺️)
- 기존 레거시인 경우 ⇒ 이미 SharedPreferences 의 영향이 여러 곳에 연결되어 있다면, 사이드 이펙트를 고려해보며 마이그레이션을 신중하게 결정해야합니다. 그래서 억지로 마이그레이션을 진행하지 않아도 괜찮은 거죠.
DataStore에는 어떤 방식이 존재할까요?
- Preferences Datastore
- Proto Datastore
Preferences Datastore
Preferences Datastore , SharedPreferences와 같은 key-value 방식입니다.
초기화, 데이터 읽기/쓰기는 공식문서를 확인해주세요!
그런데 SharedPreferences와 마찬가지로 궁금합니다.
- Preferences Datastore 에서는 어디에 저장이 될까요?
아래 경로인 내부 저장소에 저장되게 됩니다.
/data/data/com.example.kwanhee/files/datastore/[파일이름].preferences_pb조금 특이한 부분은 확장자가 preferences_pb 라는 점입니다. xml이 아닙니다.
Preferences DataStore는 내부적으로 프로토콜 버퍼(Protocol Buffers) 를 사용합니다. 그렇기 때문에 일반 텍스트가 아니라 바이너리 형태로 저장되어지고, 텍스트 에디터로 열어도 내용을 이해하기 어렵습니다.
그래서 내부적으로 DataStore는 해당 데이터를 읽거나 쓸 때, 내부 API가 안전하게 직렬화/역직렬화 처리를 해줍니다.
- 프로토콜 버퍼가 무엇이고, 사용하는 이유가 뭔가요?
프로토콜 버퍼
구글이 개발한 직렬화(Serialization) 포맷이자 라이브러리입니다.
Protobuf ↔ Json 으로 데이터를 변환할 수 있습니다.
그래서 사용하는 이유가 뭘까요? 크기가 작고, 속도가 빠릅니다. 이유는 이진(Binary) 형태로 직렬화되기 때문입니다.
*여담 : 최근 STT 기술을 사용해보면서, 구글에서 지원하는 STT API를 적용할 때 gRPC(Google Remote Procedure Call) 를 사용했고, 여기서 빠른 통신을 위해 프로토콜 버퍼를 사용합니다.
.proto 확장자로 파일을 만들 수 있습니다.
만약에 Json 객체는 어떻게 구성되어질까요? 그리고 그 Json 데이터는 proto에서 어떻게 작성될까요?
우선 Json 예시를 들겠습니다.
{
"name" : "Jokwanhee",
"id" : 1,
}위 Json 데이터는 proto로 나타낼 때, 아래와 같이 나타낼 수 있습니다.
(아래 코드를 실제로 안드로이드에서 .proto 파일을 만들 때 예시입니다.)
syntax = "proto3";
option java_package = "com.example.myapp"; // 생성되는 Java 클래스가 위치할 패키지
option java_outer_classname = "PersonOuterClass"; // 생성되는 Outer class 이름
message Person {
string name = 1;
int32 id = 2;
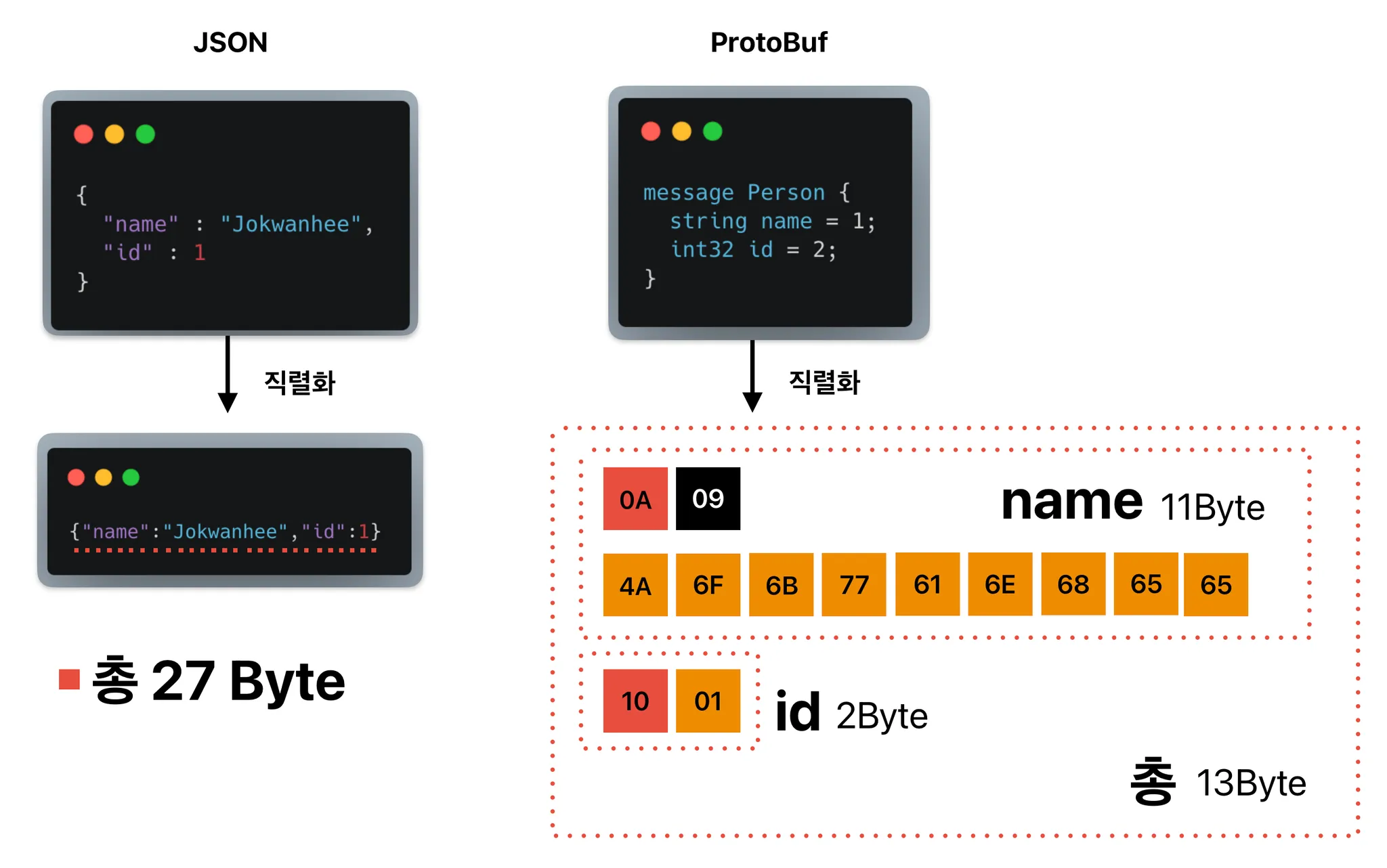
}위 Json 데이터를 직렬화하면 아래처럼 됩니다. 그렇게 될 경우, 데이터의 크기는 총 27Byte가 됩니다.
{"name":"Jokwanhee","id":1}그렇다면, ProtoBuf에서는 직렬화 시, 데이터가 어떻게 될까요?
Json과 다르게 ProtoBuf에 데이터 규칙이 존재합니다.
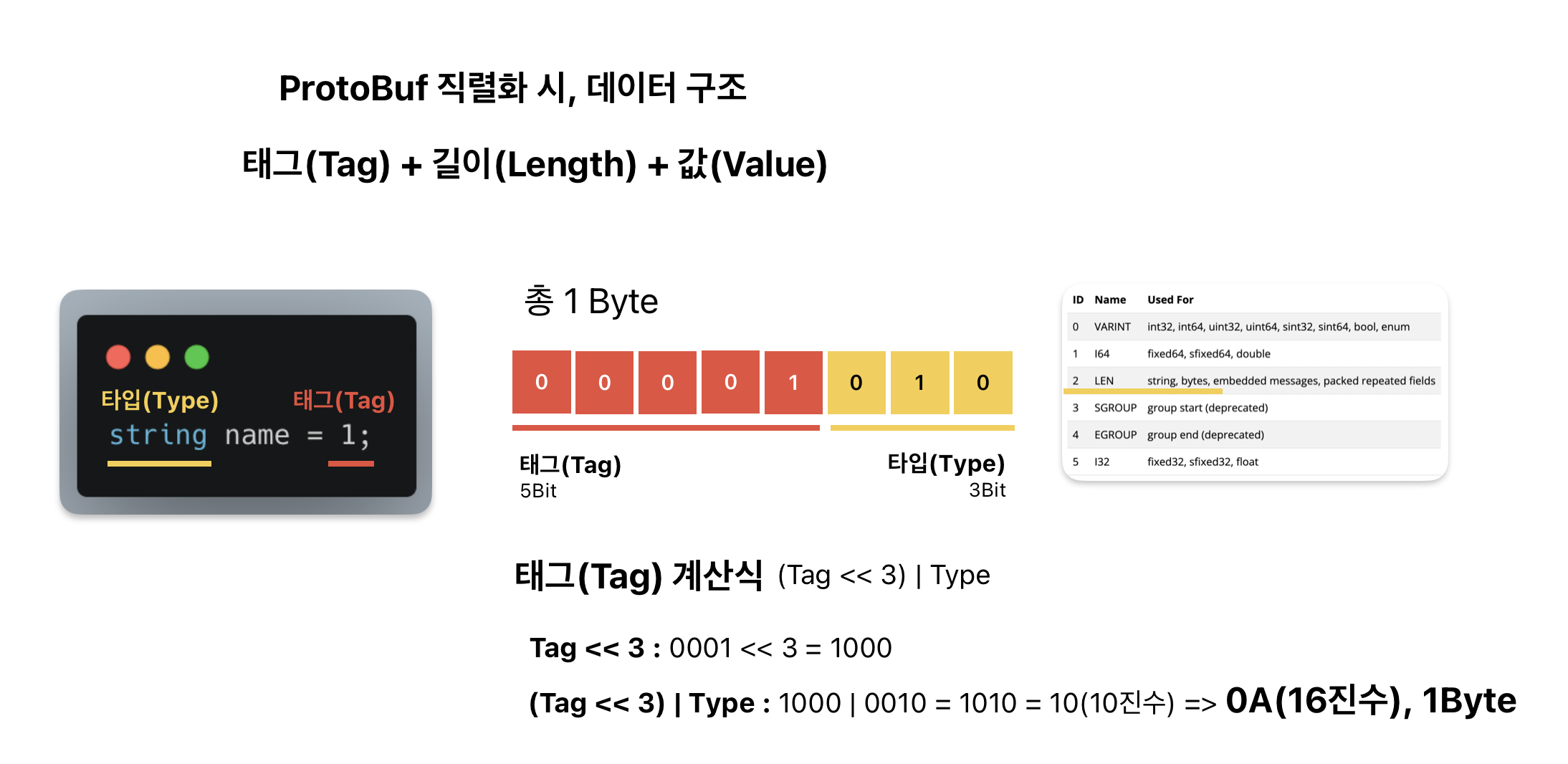
데이터는 Tag + Length + Value 구조를 가지고 있습니다. (즉, 태그 + 길이 + 값)
- name 필드 직렬화
name 부터 살펴봅시다.
- name 필드 번호 : 1
- 타입 : string
태그(Tag) 계산은 (필드 번호 << 3) | type 으로 계산합니다.
(1 << 3) = 8 : 왼쪽 시프트 연산을 3번 진행합니다. (3번 진행하는 것은 약속입니다.)
type = 2
type은 어떻게 2라는 것을 알 수 있을까요? 아래 표를 보시면 string은 id가 2라는 것을 알 수 있습니다.
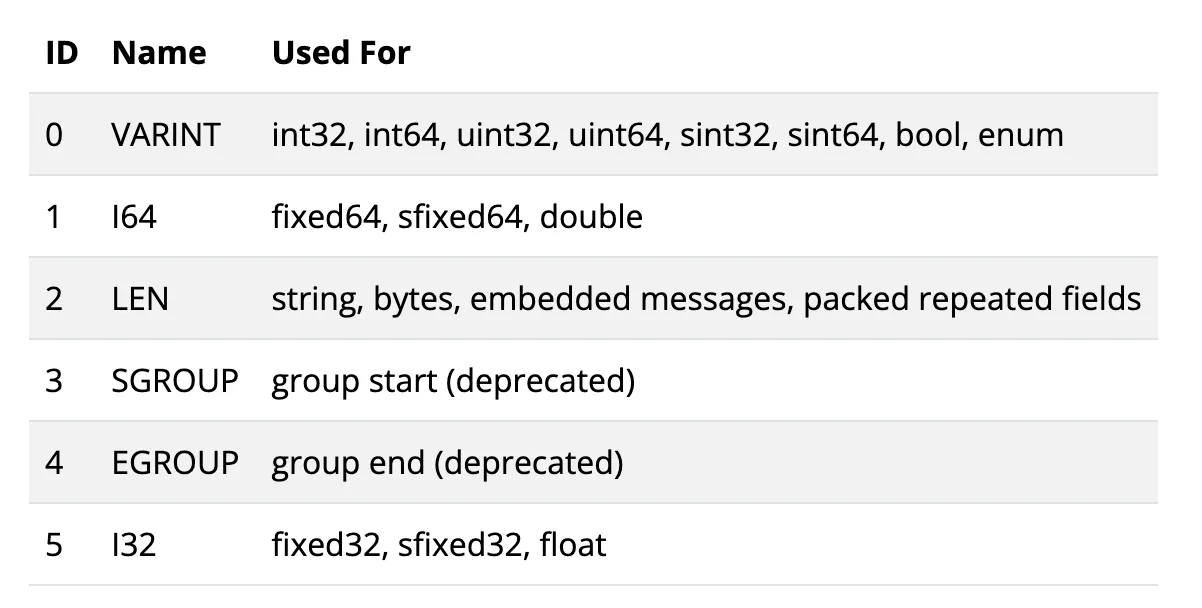
https://protobuf.dev/programming-guides/encoding/
결국 name의 태그(Tag)값은 10이 됩니다. ⇒
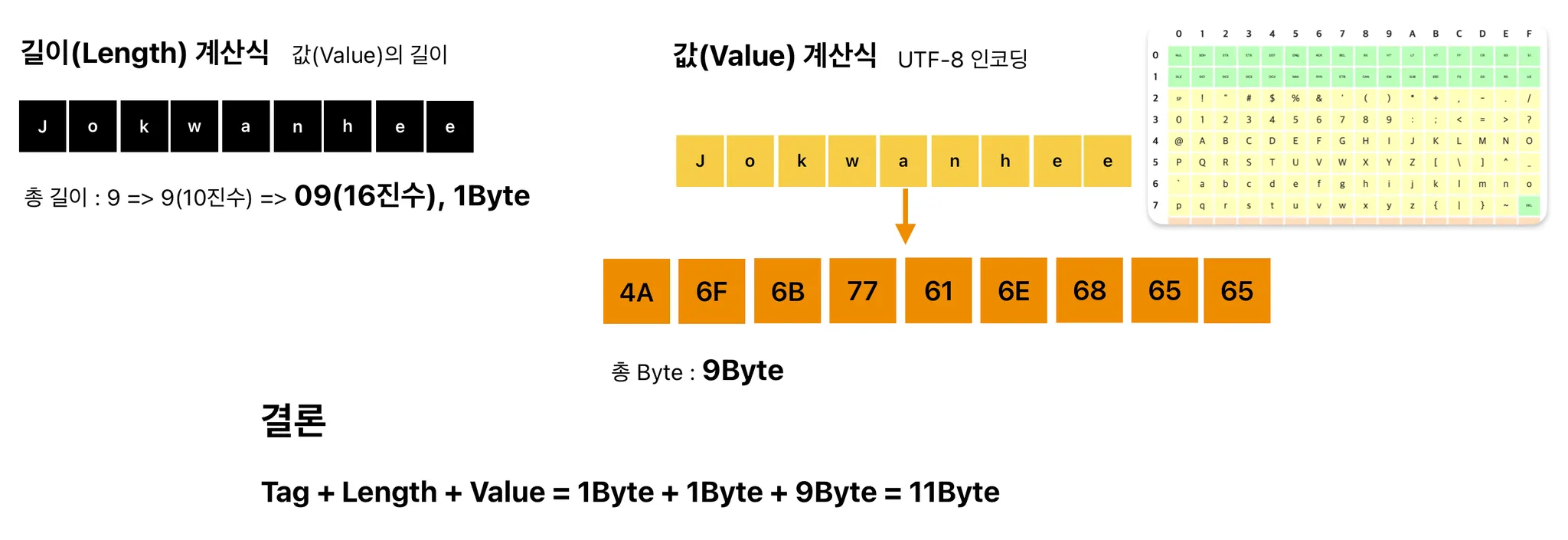
길이(Length)를 구할 수 있는 string은 Jokwanhee 의 길이의 값이 길이(Length)가 됩니다. 즉, 9가 됩니다.
마지막으로 값(Value)입니다. Jokwanhee 를 UTF-8로 인코딩하여 값을 얻을 수 있습니다. 아래 표에서 원하는 문자의 인코딩 값을 찾습니다.
J : 4A / o : 6F / k : 6B / w : 77 / a : 61 / n : 6E / h : 68 / e : 65 / e : 65
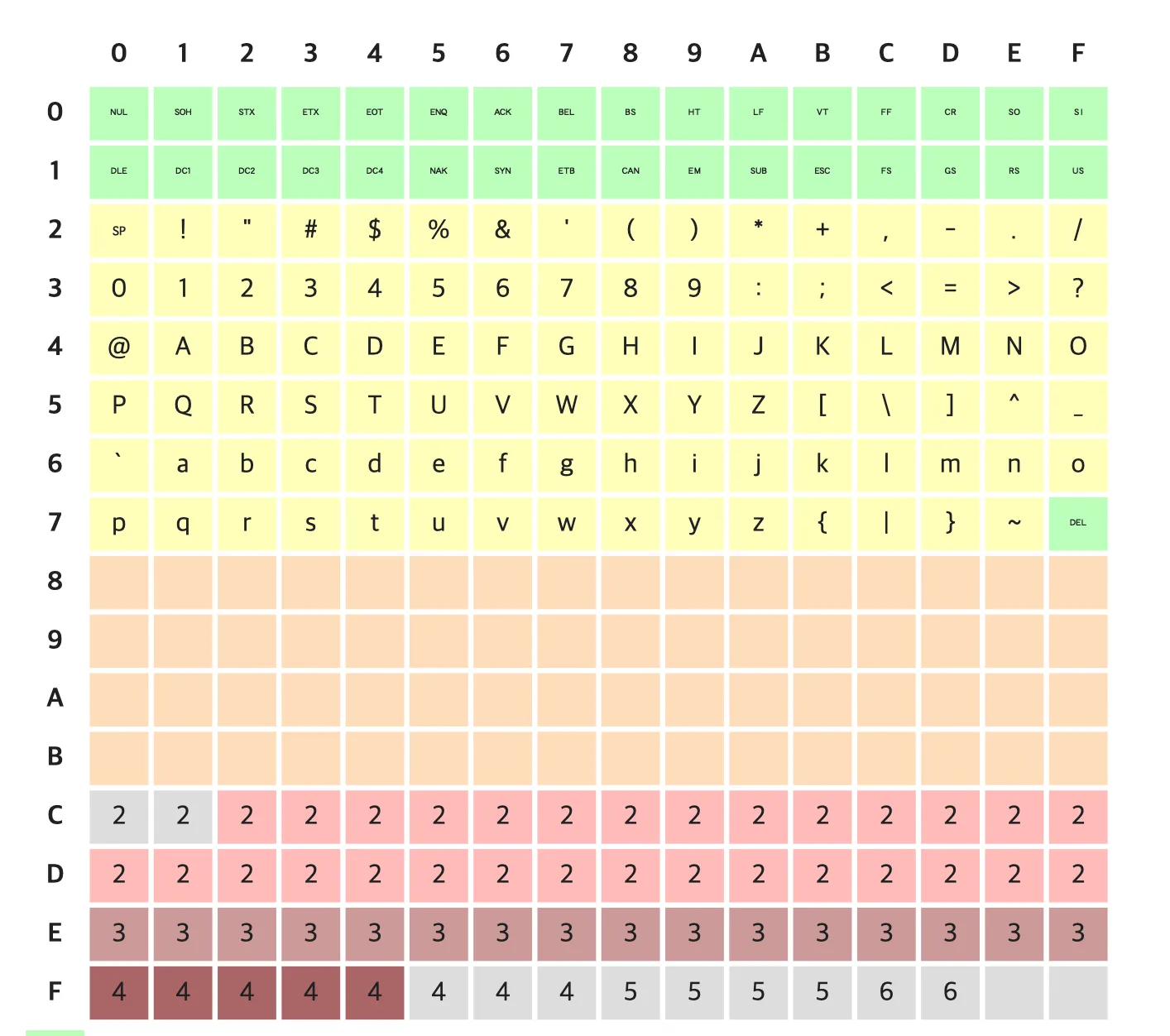
https://en.wikipedia.org/wiki/UTF-8
결과적으로, proto 값 중 name 의 데이터는 총 11 Byte가 됩니다.
Tag(태그) : 10 ⇒ 0A
Length(길이) : 9 ⇒ 09
Value(값) : J : 4A / o : 6F / k : 6B / w : 77 / a : 61 / n : 6E / h : 68 / e : 65 / e : 65
proto 값 중 id도 똑같이 동작하지만, 여기서 Length는 없기 때문에 없이 진행하여 Byte를 구합니다.
구하면 id의 Byte는 Tag(태그) : 16 ⇒ 10 + Value(값) : 1 ⇒ 01 , 최종 10 과 01 ⇒ 2Byte입니다.
proto 의 name과 id를 직렬화하면 총 13Byte로 json의 27Byte 보다 적은 것을 알 수 있습니다.
아래 그림으로 이해하기 쉽게 설명해봤습니다! ☺️

즉, 결론은 DataStore를 사용할 경우, 저장되는 형식은 .proto 입니다. I/O 속도와 용량을 더 줄이기 위한 노력이 보입니다. 이로써, SharedPreferences 말고 DataStore를 사용해야하는 이유가 하나 더 추가되었네요 ☺️
Google의 노력은 끝이 없다..
Proto Datastore
자세한 설명은 공식문서를 참고해주세요.
저는 구현 코드보다는 왜 Proto를 사용해야하고, 이점이 무엇이며 Preferences Datastore와의 차이점은 무엇인가에 대해서 초점을 맞춰서 알아보았습니다.
- 복잡한 데이터 구조
우선, 복잡한 데이터 구조를 다룰 수 있습니다. Preferences 는 key-value로 값을 가지기 때문에 아래와 같은 복잡한 데이터 구조는 할 수 없습니다. 하지만 proto는 할 수 있습니다.
message User {
string name = 1;
int32 age = 2;
bool isPremiumUser = 3;
}- 타입 안전성
Proto DataStore는 타입 안전성을 제공합니다. .proto 파일에서 필드 타입을 명확히 정의하고, 이를 기반으로 객체를 직렬화하므로 타입 오류를 사전에 방지할 수 있습니다. 예를 들어, name 필드는 반드시 string이어야 하며, age는 int32이어야 합니다. 이는 Preferences DataStore에서는 구현하기 어렵습니다.
사용할 일이 별로 없어서 Proto 에 대해서는 확 와닿는 느낌이 없네요.
단순히 gRPC를 사용할 때, proto 를 사용한 것이라서 구조적으로는 같아서 나름 이해는 잘 되었던 것 같습니다.
