생활 데이터 과제로 MBTI와 소개팅 어플의 상관관계를 알아보는 설문을 진행했다. 우리의 가설은 E(외향)성향의 사람이 I(내향)성향의 사람보다
소개팅 어플을 통해 오프라인에서 상대방을 만난 경험이 많을 것이다. 였다.
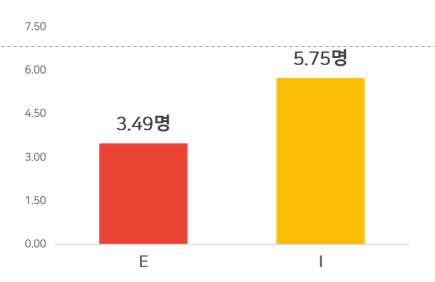
실제 설문을 통해 받은 데이터를 확인해보면
I 성향이 5.75명으로 E 성향(3.49명)보다 오프라인으로 만난 상대방 수가 더 많았다. 그렇다면 우리의 가설은 틀린 것일까?
I 성향의 총 응답자는 64명이다.
- 분산 : =VAR.S(범위)
- 표본평균 : 표본의 평균값. =AVERAGE(범위)
- 신뢰수준 : 보통 95%, 99% 중에 하나를 고정한다.
- 표본표준편차 : =STDEV.S(범위)
편차는 평균에서 얼마나 떨어져 있는지를 의미한다.
표준편차는 어떤 모집단에서 추출된 표본값들과 표본평균과의 표준편차.
표준편차는 분산의 제곱근으로 각 관측값과 평균의 차이를 제곱한 값을
모두 더하고 여기에 제곱근을 씌운 값을 말한다. - 표준의 크기 : =RAWS:(범위) 혹은 데이터의 전체 열을 세주면 된다.
- 오차범위 : =CONFIDENCE.T(100%-신뢰수준, 표본표준편차, 표본크기)
- 상한 : 표본평균에서 오차범위를 더한 값
- 하한 : 표본평균에서 오차범위를 뺀 값
응답 데이터를 계산해보니 다음과 같았다.
- 평균 5.75명
- 분산 87.42857
- 표본표준편차 9.350325
- 신뢰수준 95%
- 오차범위 2.3356
즉 오차범위는 3.41명~8.09명이 된다.
분산과 오차범위가 커서 이성을 가장 많이 만난
상위 다섯개 데이터 값을 제거해보았다.
- 평균 3.50명
- 분산 19.56458
- 표본표준편차 4.423
- 신뢰수준 95%
- 오차범위 1.1048
다시 계산해보니 오차범위가 2.4명~4.61명이 되었다.
이렇다면 E 유형의 응답과 비슷한 결과가 나온다.
I 유형의 상위 5개의 데이터로 인해 결과가 왜곡될 수 있다는 것을 알았다.

재미있게 배우고 흔적 남기기