바킹독님이 올려주신 [실전 알고리즘] 영상을 보면서 공부한것을 기록
모든 사진은 바킹독님의 블로그에서 가져왔습니다.
https://blog.encrypted.gg/
기초 정렬
선택정렬 O(n^2)
STL max_element는 arr[0]부터 arr[k-1]까지 반환하는 함수다. arr[k]가 아니라는것에 주의
#include <bits/stdc++.h>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int arr[10] = { 3,2,7,116,62,235,1,23,55,77 };
int n = 10;
for (int i = n - 1; i > 0; --i)
swap(*max_element(arr, arr + i + 1), arr[i]);
for (int i = 0; i < n; ++i)
cout << arr[i] << ' ';
}버블 정렬 O(n^2)
앞에서부터 인접한 두 원소를 보면서 앞의 원소가 뒤의 원소보다 클 경우 자리를 바꾸는 방식
#include <bits/stdc++.h>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int arr[10] = { 3,2,7,116,62,235,1,23,55,77 };
int n = 10;
for (int i = 0; i < n-1; ++i)
{
for (int j = i + 1; j < n; ++j)
{
if (arr[i] > arr[j])
swap(arr[i], arr[j]);
}
}
for (int i = 0; i < n; ++i)
cout << arr[i] << ' ';
}삽입 정렬 O(n^2)
병합 정렬 (merge sort) O(nlogn)
재귀적으로 수열을 나눠 정렬한 후 합치는 정렬
먼저 길이가 N, M인 두 정렬된 리스트를 합쳐서 길이 N+M의 정렬된 리스트를 만들어야 한다.
이는 버블 정렬을 하는 방법으로 구할 수 있지만 그러면 시간 복잡도가 O(N+M)^2이 된다. 따라서 다른 방법으로 접근해야 한다.
바로 두 배열의 가장 작은 원소들 만 비교해가면 O(N+M)에 해결할 수 있는 것이다.
#include <bits/stdc++.h>
using namespace std;
int A[1000002], B[1000002], C[1000002];
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int n, m, aidx = 0, bidx = 0;
cin >> n >> m;
for(int i=0;i<n;++i)
cin >> A[i];
for(int i=0;i<m;++i)
cin >> B[i];
for (int i = 0; i < n + m; ++i)
{
if (bidx == m) C[i] = A[aidx++];
else if (aidx == n) C[i] = B[bidx++];
else if (A[aidx] <= B[bidx]) C[i] = A[aidx++];
else C[i] = B[bidx++];
}
for (int i = 0; i < n + m; ++i)
cout << C[i] << ' ';
}병합정렬은 3단계의 과정을 가진다.
- 주어진 리스트를 2개로 나눈다. -> O(n)
- 나눈 리스트 2개를 정렬한다.
- 정렬된 두 리스트를 합친다. -> O(nlogn)
#include <bits/stdc++.h>
using namespace std;
int n;
int arr[1000001];
int tmp[1000001]; // merge 함수에서 리스트 2개를 합친 결과를 임시로 저장하고 있을 변수
// mid = (st+en)/2라고 할 때 arr[st:mid], arr[mid:en]은 이미 정렬이 되어있는 상태일 때 arr[st:mid]와 arr[mid:en]을 합친다.
void merge(int st, int en)
{
int mid = (st + en) / 2;
int lidx = st; // arr[st:mid]에서 값을 보기 위해 사용하는 index
int ridx = mid; // arr[mid:en]에서 값을 보기 위해 사용하는 index
for (int i = st; i < en; ++i)
{
if (ridx == en) tmp[i] = arr[lidx++];
else if (lidx == mid) tmp[i] = arr[ridx++];
else if (arr[lidx] <= arr[ridx]) tmp[i] = arr[lidx++];
else tmp[i] = arr[ridx++];
}
for (int i = st; i < en; i++) arr[i] = tmp[i]; // tmp에 임시저장해둔 값을 a로 다시 옮김
}
// a[st:en]을 정렬하고 싶다.
void merge_sort(int st, int en)
{
if (en == st + 1) return; // 리스트의 길이가 1인 경우
int mid = (st + en) / 2;
merge_sort(st, mid); // arr[st:mid]을 정렬한다.
merge_sort(mid, en); // arr[mid:en]을 정렬한다.
merge(st, en); // arr[st:mid]와 arr[mid:en]을 합친다.
}
int main(void)
{
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
for (int i = 0; i < n; ++i)
cin >> arr[i];
merge_sort(0, n);
for (int i = 0; i < n; ++i) cout << arr[i] << ' ';
}stable sort
우선순위가 같은 원소 끼리는 원래의 순위를 따르게 하는 정렬
퀵 정렬 (quick sort) O(nlogn)
만약 코딩테스트에서 STL을 사용하지 못한다면 quick sort 말고 merge sort로 구현해야 한다.
퀵 소트도 재귀로 구현하는 정렬이다.
퀵 소트는 매단계마다 pivot이라고 이름 붙은 원소 하나를 제자리로 보내는 작업을 반복한다.
제자리로 보낸다는 의미는 pivot을 올바른 자리에 넣고 pivot의 왼쪽은 pivot보다 작은 원소가, 오른쪽은 pivot보다 큰 원소가 오게 하는것을 의미한다.
퀵 소트는 추가적인 공간을 필요로하지 않는다는 장점이 있다.
- 추가적인 공간을 쓰지 않으려면 원소의 위치를 서로 잘 바꿔주면 된다.
- 양쪽 끝에 포인터 2개를 두고 적절하게 스왑을 해준다.
- l, r이라고 이름 붙은 포인터 2개를 두고 l은 pivot보다 큰 값이 나올 때 까지 오른쪽으로 이동하고 r은 pivot보다 작거나 같은 값이 나올 때 까지 왼쪽으로 이동한다.
- 그 다음 두 포인터가 가리키는 원소의 값을 스왑하고 이걸 l과 r이 교차할 때 까지 반복하면 된다.
- r이 l보다 왼쪽에 위치한 그 즉시 멈추며 pivot과 r을 스왑하면 알고리즘이 끝나게 된다.
#include <bits/stdc++.h>
using namespace std;
int n = 10;
int arr[1000001] = { 15, 25, 22, 357, 16, 23, -53, 12, 46, 3 };
void quick_sort(int st, int en)
{ // arr[st to en-1]을 정렬할 예정
if (en <= st + 1) return; // 수열의 길이가 1 이하이면 함수 종료.(base condition)
int pivot = arr[st]; // 제일 앞의 것을 pivot으로 잡는다. 임의의 값을 잡고 arr[st]와 swap해도 상관없음.
int l = st + 1; // 포인터 l
int r = en - 1; // 포인터 r
while (1)
{
while (l <= r && arr[l] <= pivot) l++;
while (l <= r && arr[r] >= pivot) r--;
if (l > r) break; // l과 r이 역전되는 그 즉시 탈출
swap(arr[l], arr[r]);
}
swap(arr[st], arr[r]);
quick_sort(st, r);
quick_sort(r + 1, en);
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
quick_sort(0, n);
for (int i = 0; i < n; ++i) cout << arr[i] << ' ';
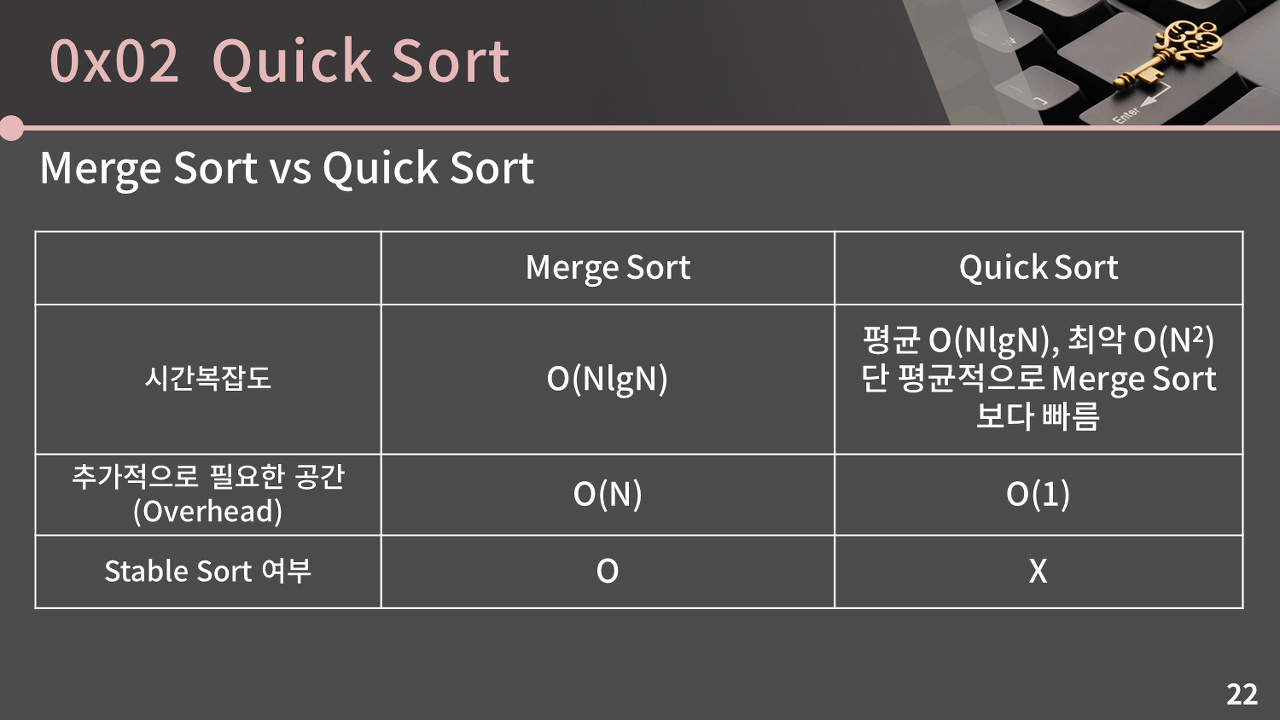
}퀵 소트는 평균적으로 O(nlogn)의 시간복잡도를 가지지만 최악의 경우 O(n^2)의 시간복잡도를 가진다.
이러한 이유 때문에 STL을 사용하지 못하고 직접 구현해야할 경우에는 merge sort를 사용해야 한다.
merge sort vs quick sort