MariaDB심화
- 트랜잭션
- 정의
- 트랜잭션이란 하나의 논리적인 작업 단위로 처리되어야 하는 하나 이상의 SQL 문의 집합
- 예시1) 은행 계좌 간에 이체를 할 때, 금액을 한 계좌에서 빼고 다른 계좌에 더하는 두 가지 연산은 한 작업의 단위로 처리되어야 하는 트랜잭션
- 예시2) 주문을 하고 order테이블에 주문을 생성하고, item테이블에서 재고까지 빼주는 작업이 한 단위로 처리되어야 하는 트랜잭션
- commit
- COMMIT 명령은 한 트랜잭션의 모든 변경사항을 데이터베이스에 영구적으로 저장
- rollback
- ROLLBACK 명령은 트랜잭션의 변경사항을 모두 취소하고, 데이터베이스를 트랜잭션 시작 이전의 상태로 되돌리는 것
- COMMIT, ROLLBACK 실습
- sql툴에서 auto_commit 모드 해제
- 예시)
insert into board_test.author(id, name, email) values(2, 'test', 'test@naver,com');
insert into board_test.post(title, contents, author_id) values('hello', 'hello is', 10);
- 위 코드 실행후 commit하면 첫번째 쿼리만 확정
- 위 코드 실행후 rollback하면 모두 취소
- 예시)
insert into board_test.author(id, name, email) values(1, 'test', 'test@naver,com');
commit;
insert into board_test.author(id, name, email) values(2, 'test2', 'test2@naver,com');
insert into board_test.post(title, contents, author_id) values('hello', 'hello is', 10);
- 첫번째 쿼리는 commit되어 확정
- 두번째 쿼리는 실행은 되나 세번째 쿼리 실행이후 rollback을 하게 되면 함께 rollback되므로, 하나의 논리적인 transaction으로 볼 수 있음
- 일반적으로는 사용자가 위와 같은 쿼리를 실행시킬수는 없으니, 프로그램에서 논리적인 트랜잭션을 지정하고, 전체 commit 또는 전체 rollback하는 명령을 실행
- DB 동시성 이슈
- 트랜잭션이 동시에 실행됐을때 발생할 수 있는 문제 관련한 상황을 DB동시성 문제라함
- dirty read
- 한 트랜잭션이 다른 트랜잭션이 수정 중인 데이터를 읽을 수 있는 문제
- 아직 commit되지 않은 데이터가 읽힘으로서, 추후 rollback 될 가능성이 있는 데이터 read
- 해결책 : Read Committed 격리성
- Non-Repeatable Read
- mariaDB의 기본 설정은 Repeatable Read
- 한 트랜잭션에서 동일한 조회 쿼리를 두 번 이상 실행할때에, 그 중간에 다른 트랜잭션에서 데이터를 수정하여 한 트랜잭션의 결과가 다르게 나타나는 문제
예시) 재고 업데이트 전 현재 재고 조회 -> 수량업데이트 -> 변경된 재고 수량을 다시 조회(한트랜잭션에서). 그러나 만일 이를 중간에 누가 수정을 가하면 재조회시 오차 발생하여 에러.
- 해결책 : Repeatable Read 격리성 -> 한 트랜잭션이 조회하는 동안 다른 트랜잭션이 update를 하더라도 현재 트랜잭션의 read값이 변경되지 않도록 하는 격리성. 그러나, 만약 다른 트랜잭션에서 update를 통해 값을 변경해버렸다면, read한 값 자체에 문제 발생. => 타 트랜잭션의 update를 막기 위한 select for update 쿼리 필요
- Phantom Read
- 한 트랜잭션이 같은 조회쿼리를 여러 번 실행했을 때, 그 중간에 다른 트랜잭션에서 새로운 데이터를 추가/삭제하여 다르게 나타나는 문제
- 해결책 : Repeatable Read 격리성. 팬텀(유령) 읽기 또한 repeatable Read격리성으로 해결이 가능하나, 이 부분은 DB마다 차이가 있어 phantom read를 해결하기 위해 Serializable 격리수준이 필요할수도 있음. 다만, DB에서 주로 발생하는 문제는 동시에 수정하는 상황이므로, 수정에 초점을 두고 해결 전략을 살펴봐도 좋을것.
- 사실 동시성 문제는 read만이 문제는 아니고, read이후 DB에 어떠한 수정사항을 가할때도 read의 오차로 인한 또다른 오차가 발생하여 DB 전체에 영향이 발생하므로 DB 전체에 대한 동시성이라 보면 될것.
- DB 격리수준
- DB 동시성 문제를 해결하기 위한 격리수준
- Read Uncommitted
- 즉, 데이터가 변경되었다면, 커밋되지 않았다 하더라도 읽을 수 있도록 하는 격리수준
- dirty read 발생 가능
- Read Committed
- 다른 트랜잭션이 커밋된 데이터만 읽을 수 있는 격리수준.
- 다만, 나의 트랜잭션에 여러 select 문이 있을 경우에, 그 사이에 다른 트랜잭션에서 update 또는 insert 등을 발생시키고 commit하게 될시 phantom read 또는 non-repeatable-read 발생가능
- Repeatable Read
- 한 번 읽은 데이터는 같은 트랜잭션 내에서는 항상 같은 값을 갖도록 하는 격리수준
나의 트랜잭션에서 먼저 read하는 동안 다른 트랜잭션에서는 변경,추가 하더라도 같은 read값을 보장하는 것. -> Non-Repeatable Read과 Phantom read를 해결
- repeatable read를 하더라도 문제가 발생할 가능성 존재
- 나의 트랜잭션이 read하는 동안 타 트랜잭션에서 update하게 되면 read해온 값이 달라지는 문제 발생
- 대안은 locking
- 공유락(shared lock - select for share)
- 두 다른 트랜잭션이 동시에 read하는 것은 가능하여 lost update 문제 가능성 존재
ex)상품주문의 최종 수량이 1개 -> transaction에 read && update가 있을때 -> 내 tran에서 1 read -> 타 트랜잭션이 1 read -> 내 tran에서 0으로 update -> 타 tran에서 0으로 update -> 최종 수량에 오류 발생
- 배타락(exclusive lock - select for update)
- read부터 lock을 걸어 lost update 문제 해결
- Serializable
- 동시에 실행되는 여러 트랜잭션들을 순차적으로 실행한 것과 같은 결과를 보장 -> 즉 데이터베이스 차원에서 동시에 특정 데이터에 접근하는 것을 차단
- DB 동시성 관련 실무 해결책
- 위와 같은 동시성 이슈는 일반적이지는 않은 상황이지만, 쇼핑몰이벤트 또는 예매 시스템에서는 빈번하게 발생할수 있는 가능성 존재
- Spring에서의 전략
- optimistic lock
- 버전정보 활용하여 update시에 정합성 체크
- update item set stock_count = new_count where id=1 and version = 1;
만일, version이 맞지 않다면 0rows affected
- pessimistic lock
- 공유락
- 배타락
- lock - PESSIMISTIC_WRITE
- 특정행에 대해 lock을 걸어 read조차 막음으로서 update시에 발생하는 이슈 원천 차단.
- Serializable수준의 격리를 특정테이블과 특정데이터에 적용가능
- queue사용
- 이벤트, 예매 상황에서 고려될수 있는 아키텍처
- 동시성에 대한 효율을 감수해야 하지만, 시스템의 정확도와 사용자경험의 향상을 꾀할수 있음
- Redis 사용
- JOIN
- 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현
- 크게는 INNER JOIN, OUTER JOIN으로 구분
- INNER JOIN
- 두 테이블 사이에 지정된 조건에 맞는 레코드만을 반환. 양쪽 테이블에 모두 해당 조건에 맞는 값이 있어야 결과에 포함
- ex)author와 post를 inner조인하면 글을 작성한적이 있는 author와 해당 author가 작성한 post정보를 결합하여 조회
- 가장 일반적인 형태
- OUTER JOIN
- 하나의 테이블을 기준으로 모든 레코드와 그에 JOIN된 다른 테이블의 일치하는 레코드를 반환
- 왼쪽테이블이 기준이면 LEFT (OUTER) JOIN, 오른쪽 기준이면 RIGHT (OUTER) JOIN
- LEFT JOIN이 더 일반적으로 많이 사용되는 JOIN
- ex)author의 테이블은 일단 다 조회하고 author가 작성한 글정보를 조회하고 싶다면, author테이블에 post테이블을 left join
- INNER JOIN
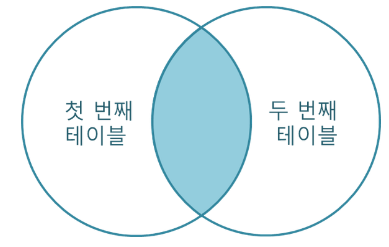
- tableA의 ID와 tableB의 a_id가 일치하는 ON 조건을 만족하는 데이터만 JOIN
- SELECT * FROM tableA INNER JOIN tableB ON tableA.ID = tableB.A_ID
- SELECT * FROM tableA AS a INNER JOIN tableB AS b on a.ID = b.a_id;
- 출력결과
- TableA의 모든컬럼 + TableB의 모든컬럼
- 그 중에 ON조건을 만족하는 row만 출력
- LEFT OUTER JOIN

- 문법
- SELECT * FROM tableA a LEFT JOIN tableB b ON a.id = b.a_id
- 출력결과
- TableA의 모든컬럼 + TableB의 모든컬럼
- A테이블 데이터는 row는 모두 출력 B데이터는 ON 조건에 맞는 데이터만 출력
- ON조건에 맞지 않는 B데이터는 null로 출력
- A테이블의 데이터를 기준으로 B테이블의 데이터를 정렬
- JOIN 특이사항
- JOIN된 데이터에 WHERE조건
- where조건을 걸게 되면, ON 조건을 만족하는 데이터중에서도 WHERE문을 만족하는 데이터만 출력
- SELECT * FROM tableA AS a INNER JOIN tableB AS b on a.ID = b.a_id where a.name like ‘kim%’;
- RIGHT JOIN의 경우 LEFT JOIN과 동일
- 다만, 기준이 되는 테이블이 왼쪽 테이블에서 오른쪽으로 변경
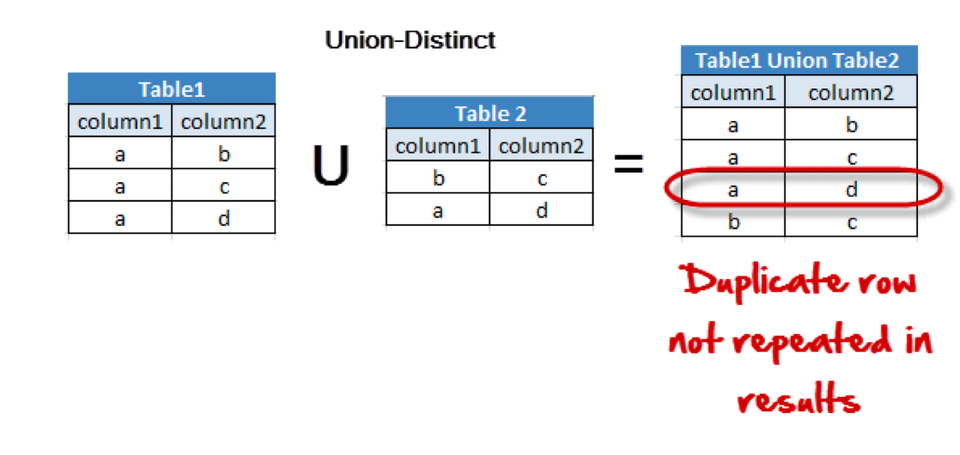
- 여러 개의 SELECT 문의 결과를 하나의 테이블이나 결과 집합으로 표현
- 각각의 SELECT 문으로 선택된 필드의 개수와 타입은 모두 일치해야함
- UNION은 DISTINCT 키워드를 따로 명시하지 않아도 중복되는 레코드를 제거
- 중복되는 레코드까지 모두 출력하고 싶다면 UNION ALL
- SELECT 컬럼1, 컬럼2 FROM TABLE1 UNION SELECT 컬럼1, 컬럼2 FROM TABLE2;
- 서브쿼리
- 서브쿼리(subquery)란 다른 쿼리 내부에 포함되어 있는 SELECT 문을 의미
- JOIN대신 서브쿼리를 써보자
- SELECT a.* FROM author a INNER JOIN post p ON a.id = p.author_id;
- SELECT a.* FROM author a WHERE a.ID IN (SELECT p.author_id FROM post p);
- IN과 NOT IN을 많이 사용
- SELECT * FROM tableA WHERE id IN (SELECT a_id FROM tableB);
- 서브쿼리는 반드시 괄호(())로 감싸져 있어야 한다
- 대부분의 서브쿼리는 join으로 대체가능하고 join을 쓰는것이 성능이 더 좋음
- 단, 매우 복잡한 쿼리는 join으로 대체하는 것이 불가능
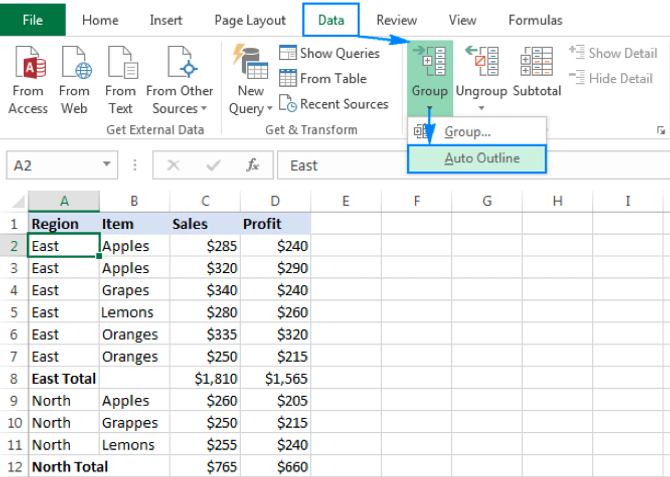
- GROUP BY
- 선택된 레코드의 집합을 특정 값으로 그룹화한 결과 집합
- select 컬럼명 from 테이블명 group by 컬럼
- 사용목적
- 데이터의 값을 집계하기 위해
- 주로 집계 함수와 같이 사용(total sum, average 등)
- 아래 excel의 경우 Region을 group화 시켜 통계값 산출
- 집계함수
- COUNT() : 행의 개수를 세어줌
- AVG() : 행 안에 있는 값의 평균을 내어줌
- MIN() : 행 안에 있는 값의 최솟값을 반환해줌
- MAX() : 행 안에 있는 값의 최댓값을 반환해줌
- SUM() : 행 안에 있는 값의 합을 내어줌
- 예시)
- select author_id, count(*) from post group by author_id
- author_id로 그룹화한 데이터의 갯수구하는 집계 SQL
- 만약 post마다 원고료가 있었다면, select author_id, sum(price), avg(price) from post group by author_id
- HAVING 절
- HAVING 절은 GROUP BY를 사용하여 그룹화된 후의 데이터에 대한 조건을 설정
- WHERE 절은 데이터를 그룹화하기 전의 개별 레코드에 대한 조건을 설정
- HAVING 절은 주로 집계 함수(COUNT(), SUM(), AVG() 등)와 함께 특정 조건을 만족하는 그룹만을 필터링하고 싶을 때 사용
- select author_id, count(*) as count from post group by author_id having count > 3;
- UNION - WITH RECURSIVE
- WITH RECURSIVE 키워드는 sql에서 재귀문으로서 자기 자신을 참조하여 반복적으로 데이터를 생성하거나 변형하면서 하나의 테이블을 만드는 용도로 사용
- UNION과 함께 사용되며 데이터행을 더해나가는 방식
- WITH RECURSIVE 재귀문에서 WHERE 절은 재귀적으로 생성되는 각각의 행에 대해 평가되며, 조건이 거짓이 되는 순간 더 이상 새로운 행을 생성하지 않고, 전체 재귀문이 STOP
- 예시)0~10까지 출력
WITH RECURSIVE cte(cnt) AS (
SELECT 0
UNION ALL
SELECT cnt + 1 FROM cte WHERE cnt < 10
)
SELECT cnt FROM cte;
- 예시)피보나치 수열
WITH RECURSIVE Fibonacci (n, fib1, fib2) AS (
SELECT 1, 0, 1 -- 초기 값 설정
UNION ALL
SELECT n + 1, fib2, fib1 + fib2 FROM Fibonacci WHERE n < 10 -- 재귀 단계
)
SELECT n, fib1 FROM Fibonacci;
- INDEX
- 인덱스(index)란?
- 인덱스는 색인과 목차처럼 데이터 검색 속도를 향상시키는데 사용
- 책의 목차에서 원하는 주제를 찾아 해당 페이지로 바로 이동하는 것처럼 DB는 해당 인덱스를 활용하여 테이블의 전체 레코드를 스캔하지 않고도 필요한 데이터를 빠르게 찾음
- 기본적으로 DB는 데이터를 검색할 때 테이블 전체를 탐색해야 하나, 인덱스를 사용하면 테이블의 특정 컬럼 값과 그 레코드의 위치 정보를 보유하고 있어, 테이블 전체를 읽지 않아도 돼 성능 향상
- 일반적으로 인덱스는 B-tree의 자료구조를 가지고, 이는 이진 트리를 확장한 형태로, 한 노드가 두 개 이상의 자식을 가질 수 있는 자료구조
- 이진트리는 최대 2개의 자식 노드를 가지는 구조로. 모두 2개의 자식노드만을 가진 이진트리를 완전이진트리라 부른다.
- 결론은, 테이블의 특정 컬럼의 INDEX 정보를 만들어 검색의 속도를 높이기 위해서 사용
- 예시)특정컬럼에 index가 없이 테이블 전체를 읽어야 하는 case
id=897 번째의 데이터를 조회하기 위해서는 897번의 check가 필요
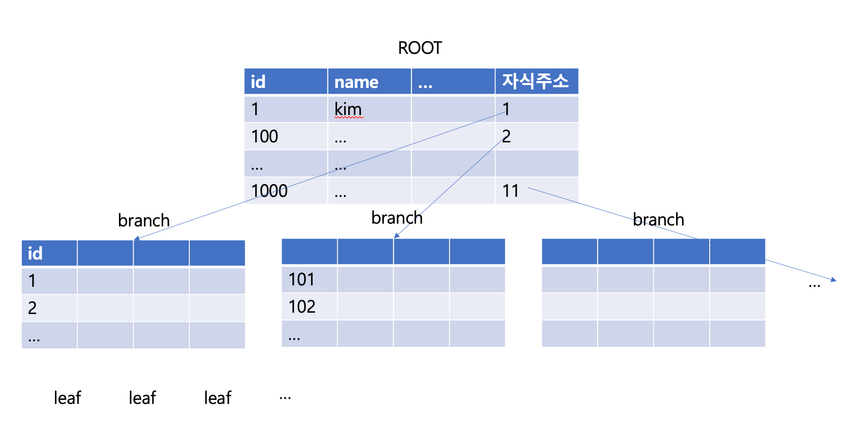
- 예시)id 컬럼에 대해 index가 만들어져 있어, 성능이 향상되는 case

- root페이지는 100개당 1개씩 branch를 갖는 구조
- branch는 10개당 1개씩 leaf를 갖는 구조
- id=897 번째의 데이터를 조회한다면 root에서8번, 그 다음 branch에서 9번, 그 다음 leaf에서 7번, 24번만에 검색완료
- 특정 테이블에 생성된 index 조회
- show index from 테이블명;
- 인덱스 생성 방법
- pk, fk, unique 제약조건 추가시에 해당컬럼에 대해 index 자동생성
- 단일 컬럼 index : CREATE INDEX index_name ON 테이블명(컬럼명);
- 복합(다중 컬럼) 인덱스 생성 : CREATE INDEX index_name ON 테이블명(컬럼1, 컬럼2);
- 인덱스의 사용
- 인덱스 정보를 활용하여 검색이 되려면, 조회 where 조건에 index 컬럼을 조건으로 걸어줘야 index페이지를 활용하여 검색이 이루어짐
- select * from author where id = 1;
- select * from author where id = 1 and name = ‘abc’;
- 이경우, name에 index가 없다면 id인덱스 페이지를 참조
- name에도 별도로 Index가 있다면, MariaDB엔진에서 최적의 알고리즘 실행
- id, name에 동시에 index가 걸려있다면 해당 index 참조하여 검색
- 데이터모델링
- 데이터 모델링이란 구축할 DB 구조를 약속된 표기법에 의해 표현하고 설계해 나가는 과정을 의미
- 데이터모델링 단계
- 개념적 데이터 모델링
- ERD 다이어그램을 통해 데이터베이스의 구조를 시각화
- 이 단계는 추상화된 DB구조를 그리는 것이므로, 필요시 생략 가능
- 논리적 데이터 모델링
- 구체적으로 데이터베이스 설계. 각 데이터의 타입, 관계, key등을 지정
- 엑셀 또는 ERD 사용
- 물리적 데이터 모델링
- 실제 데이터베이스를 만드는 과정이고, SQL 작성이 여기에 해당
- 개념적 데이터 모델링
- ERD (Entity Relationship Diagram)란 'Entity 개체'와 'Relationship 관계'를 중점적으로 표시하는 데이터베이스 구조를 한 눈에 알아보기 위해 그려놓는 다이어그램
- ERD를 사용한 개념적 데이터 모델링
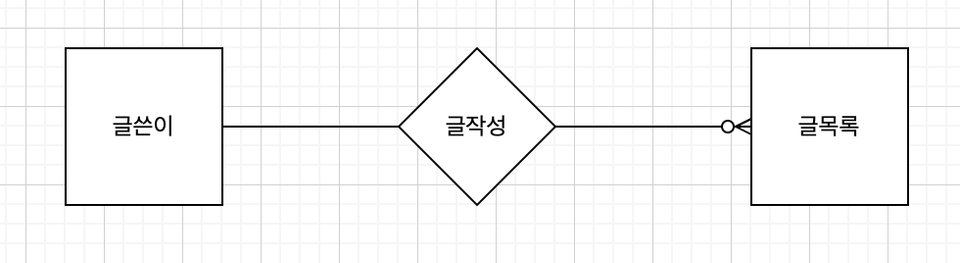
- https://app.diagrams.net/ 등의 사이트에 UI 제공
- 논리적 데이터 모델링

- 개념적인 데이터 모델이 완성되면, 구체화된 업무 중심의 데이터 모델을 설계
- 이 단계에서 업무에 대한 Key, 속성, 관계등 구체화된 정보를 표시
- 물리적 데이터 모델링
- 최종적으로 데이터 베이스에 실제 테이블을 만드는 SQL문 작업
- 정규화
- 실습 데이터 https://docs.google.com/spreadsheets/d/18q1zXxHk69SwHiD6nc5fD_lLMqrX52gJNFLtzx6NSo8/edit#gid=138746620
- 함수적 종속성
- f(x)=y
- 함수적 종속이라는 표현은 수학의 함수에서 유래
- y는 x의 값에 의해 결정되는 관계로서, y는 x에 종속적이고, 이를 수학적인 표현에서는 y는 x에 함수종속적이다 라고 표현
- 정규화 관련해서 빈번히 사용되는 표현으로서, a가 b에 함수종속적이다 하면 b의 값에 의해 a가 결정됨을 의미
- 예시)
- 학번과 학부
- 학번 -> 학부
- 즉, 학번에 따라 학부가 결정되므로, 학부는 학번에 함수 종속적
- 등록금과 학부
- 학부 -> 등록금
- 학부에 따라 등록금이 결정되므로, 등록금은 학부에 함수 종속적
- 정규화란 관계형 스키마를 더 좋은 구조로 정제해 나가는 과정
- 몇단계의 정규화과정으로 나누는 여러 이론 존재
- 여기서는 주요한 내용만을 학습
- 1차 정규화(도메인 분해)
- 모든 열의 값이 원자적이어야 함. 즉, 각 열에는 하나의 값만 있어야 함을 의미
- 하나의 컬럼에 여러 원자값이 존재시, 조회조건을 통한 조회 어려움 발생
- 수정/삭제가 발생할때 특정 데이터를 찾아 수정/삭제의 어려움
- FK 및 index 지정이 불가능함
- 즉, 1차 정규화는 여러 원자값의 컬럼을 쪼개는 과정
- 2차 정규화(부분종속 제거)
- 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속된 상태를 의미
- 복합키로 이루어진 기본키 중에 특정 키에 종속적인 상황 제거
- 2차 정규화를 위한 방법
- 기본키가 아닌 키에 부분적으로 종속돼 있는 특정 컬럼값을 제거
- 기본키에 종속적이지 않다면 해당 테이블에 어울리지 않는 컬럼이라는 생각 필요
- 사실상 해당 테이블에 어울리지 않는 컬럼 분리 작업
- 불필요한 컬럼을 제거하면 공간 효율적
- 3차 정규화(이행종속(transitive depency)제거)
- X ->Y 이고 Y->Z 이면 X->Z 가 성립. Z가 X에 이행적으로 함수 종속
- 모든 속성이 기본키에 이행적 함수 종속이 되지 않아야 함
- 즉, 이행종속이 되는 부분종속을 제거해야 하는 특성상, 부분종속과 구분 이 어려운 부분
- 만약 학번이 PK. pk -> 학부, 학부 -> fees. 즉, pk -> fees가 되어 fees가 pk에 이행종속적
- 그외
- 결정자이면서 후보키가 아닌 것 제거 (BCNF)
- 후보키 집합에 속하지 않은 결정자가 존재하면 BCNF위반
- 후보키란 테이블내에 유일성을 가질수 있는 key 중 하나
- BCNF (Boyce and Codd Normal Form)은 제3 정규형을 조금 더 강화시킨 개념이다. 강한 제3 정규형.
- 다치 종속 제거 (4NF)
- 다치 종속성(MultiValued Dependency, MVD)이란 하나의 릴레이션에서 여러 속성과의 관계가 1:N 관계인 경우
- A->-> B 이중 화살표로 표시
- 조인 종속성 제거 (5NF)
- 조인종속성이란 하나의 릴레이션을 여러개의 릴레이션으로 분해하였다가, 다시 조인했을 때 데이터 손실이 없고 필요없는 데이터가 생기는 것
- 역정규화
- DB Dump
- 데이터베이스의 구조와 데이터를 SQL 형식으로 추출하는 데 사용되는 방식을 Dump라 함. 주로 특정 DB에서 다른 DB로 데이터와 DB구조를 이전, 복사, 백업 할때 사용
- 데이터베이스 dump
- mysqldump -u [username] -p [password][database_name] > dumpfile.sql
- mariaDB에서도 mysql명령어를 사용함에 유의
- dump파일 복원
- mysql -u [new_username] -p[new_password][new_database_name] < dumpfile.sql
- mariaDB가 mysql의 fork였던 관계로, mysql관련 명령어 사용됨에 유의
- 사용자관리
- 신규 사용자 생성
- CREATE USER 'testuser'@'localhost' IDENTIFIED BY ‘testpw’;
- 어떤 곳에서도 원격접속을 가능하도록 하려면 localhost대신 % 기호 사용
- 사용자 목록 조회
- SELECT User, Host FROM mysql.user;
- 특정DB의 특정테이블에 특정권한 부여
- GRANT SELECT ON board.author TO ‘testuser'@'localhost';
- 권한 변경사항 적용
- 특정 사용자 권한 조회
- SHOW GRANTS FOR 'testuser'@'localhost';
- view
- 뷰(View)는 데이터베이스의 테이블과 유사한 구조를 가지지만, 가상의 테이블로서 실제 데이터를 저장하지 않는 데이터베이스. 실제 데이터베이스를 참조만
- 기본문법
- 뷰 생성
CREATE VIEW author_for_view AS
SELECT 컬럼1, 컬럼2...
FROM 테이블명;
- 뷰를 통한 테이블 조회
SELECT * FROM author_for_view;
- 특징
- 복잡한 쿼리 결과를 뷰로 생성해두면, 이후에는 뷰를 간단한 쿼리로 호출
- 뷰를 사용하여 특정 사용자에게 테이블의 일부 데이터만을 보여주는 것이 가능
- grant를 통해 뷰에 대한 권한만을 부여
- GRANT SELECT ON [데이터베이스 이름].[뷰 이름] TO 'testuser'@'localhost';
- FLUSH PRIVILEGES;
- 뷰를 사용하면 필요한 컬럼만 선택하여 보여줄 수 있음
- 저장 프로시저(stored procedure)
- Stored Procedure는 데이터베이스에 저장되어 실행될 수 있는 하나 이상의 SQL 문의 집합
- 특성
- SQL 문을 미리 컴파일하여 저장함으로써 데이터베이스 서버의 부하를 줄이고 성능을 향상
- 한 번 작성된 저장 프로시저는 여러번 재사용 가능
- 복잡한 조건문 반복문 등을 프로시저에서는 프로시저 문법에 맞게 사용할 수 있음
- sql은 본질적으로 선언문으로서 제어문에 대한 유연성 낮음(반복문불가)
- 프로시저는 절차적 언어로서 제어문 사용 가능
- 데이터베이스 수준에서 직접 접근 권한을 제어할 수 있으므로 보안을 강화
- 특정사용자에게 프로시저 실행권한 부여
- GRANT EXECUTE ON PROCEDURE 데이터베이스명.프로시저명 TO 'testuser'@'localhost
- 기본 문법
- 프로시저 생성
DELIMITER //
CREATE PROCEDURE procedure_name (parameters)
BEGIN
-- SQL 문법
END //
DELIMITER ;
- 파라미터의 기본 형식은 (IN 변수명 변수타입)
- 생성문의 파라미터는 생략가능하고, 함수와 같이 parameter를 전달하여 실행하는 것도 가능
- 프로시저 호출
- 생성한 프로시저 생성문 내용 조회
- show create procedure 프로시저명;
- 변수 선언
- DECLARE 변수명 변수타입 [DEFAULT default_value];
- 반드시 프로시저나 함수의 본문 시작 부분, 즉 BEGIN 바로 밑에 위치
- 조회 쿼리를 통한 "select 컬럼명 into 변수" 문과 함께 많이 사용
- 변수 수정
- 제어문
- if문
IF 조건식 THEN
-- 조건이 참일 때 실행할 명령
ELSE
-- 조건이 거짓일 때 실행할 명령
END IF;
- while문
WHILE 조건식 DO
-- 조건이 참일 동안 반복 실행할 명령
END WHILE;
- 테이블 간의 참조 관계의 종류
- 1:n관계
- n:1관계
- 1:1관계
- 한 테이블의 레코드가 다른 테이블의 레코드 하나와만 관련
- author테이블과 author_address 테이블로 분리 가능
- n:m관계
- 만약 여러 author가 posting 글 1개를 수정할 수 있다면 n:m 관계
- post의 author_id가 multi가 되므로, author_id를 문자열로 하여 여러개 두는 것은 가능.
- 그러나 정규화가 되지 않는 문제 발생
- 해결책
- 연결테이블을 만들어 1:n, n:1 관계로 풀어주는 것이 일반적인 해결책
- post_author 와 같은 테이블 생성
- post_author는 post와 n:1관계, author와 n:1관계
- DB 서버 구성
- DB의 사용성에 문제가 생기지 않도록 하는 고가용성 확보를 위한 방안
- 클러스터링
- 1대의 스토리지와 여러대의 서버 운영
- active/active, active/stanby
- 레플리카
- 샤딩
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법
- 클러스터링
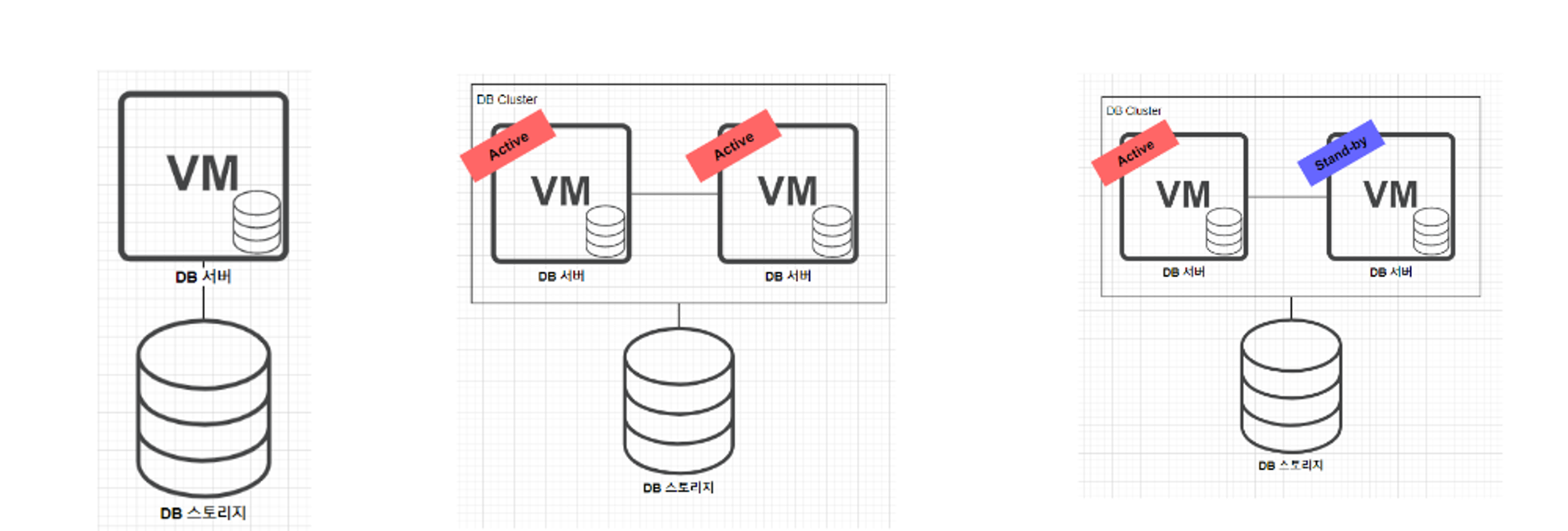
- DB를 한 대만 운영 할 경우에 문제점은 DB 서버가 죽으면 관련된 서비스가 전체가 중단
- 동일한 DB 서버를 두 대를 묶고 두 DB 서버
- active/active
- active/stanby
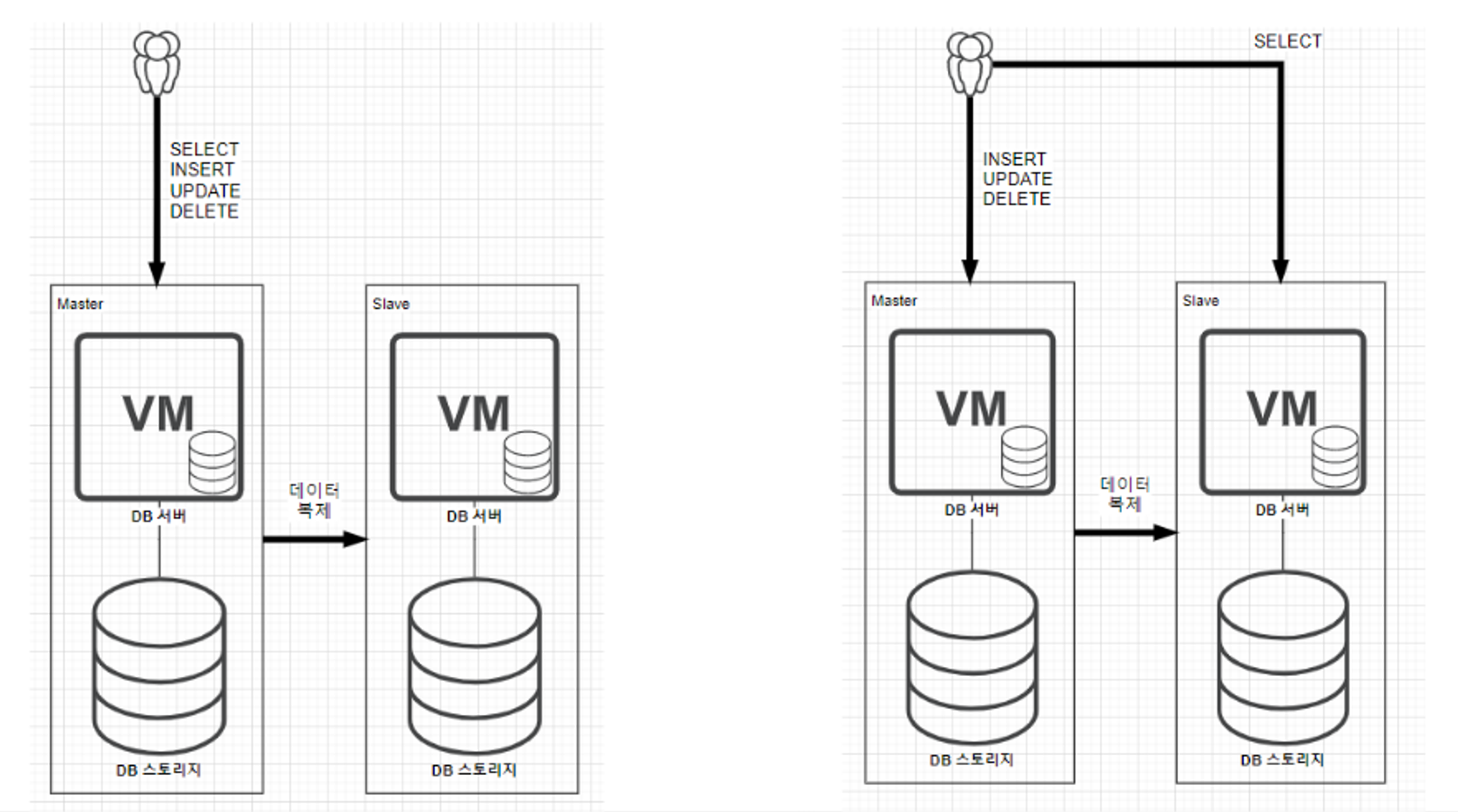
- 레플리카
- 데이터베이스 스토리지 유실에 대한 대안으로 스토리지 까지 복제
- 아래와 같이 복제만 하는 레플리카 케이스와 복제를 하면서 동시에 slave서버는 select 용도
- 재해복구를 위한 DR센터 운영
- 샤딩
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장
- 대규모 시스템에서 성능향상을 위해 사용
- 데이터베이스와 스토리지를 n개로 분리하여 데이터 분산 저장
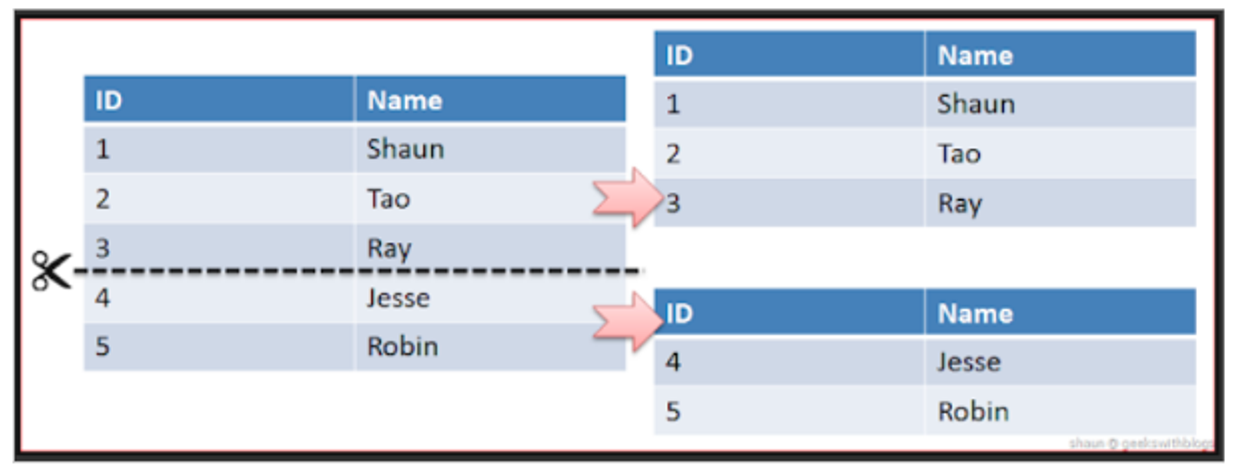
- 샤딩전략
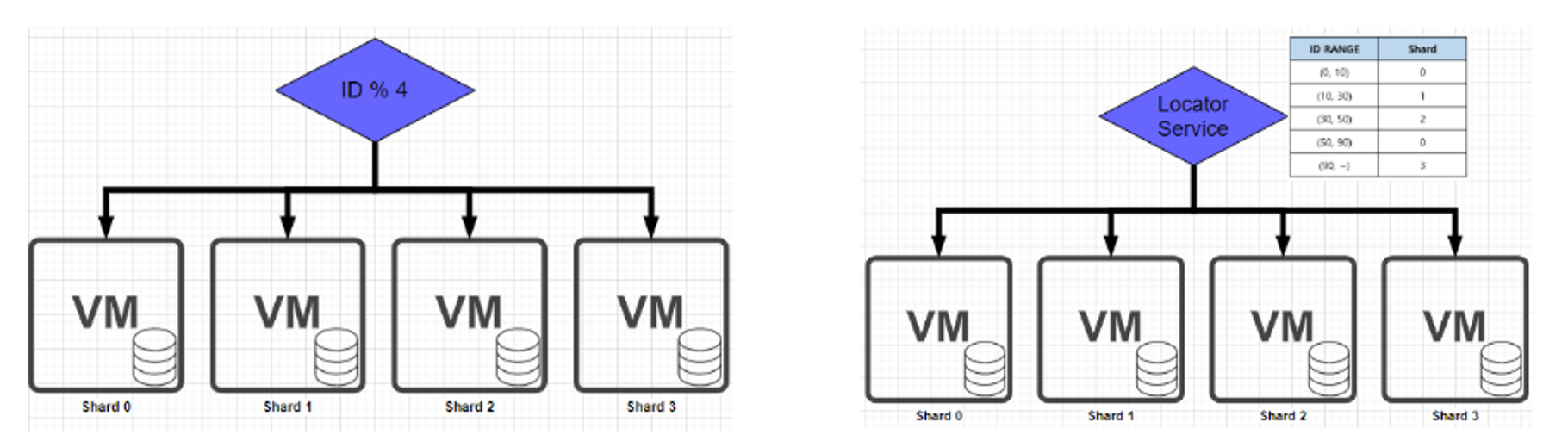
- Hash sharding
- DB 서버가 추가 될 경우 해쉬 함수가 변경
- Dynamic sharding
- 목적지 shard와 id range만을 지정하므로, 서버 추가시 용이
- HA구성

- HA(High Availablity)는 고가용성을 뜻하는 것으로 장애없는 지속가능한 서비스를 지칭하고, 서버의 다중화 구성을 의미
- MySQL 프록시 및 로드 밸런서
- 사용자의 요청을 분산처리 하는 것이 로드 밸런서(부하분산)
- 프록시는 사용자의 요청을 서버에 "대리"해서 전달하는것(리버스 프록시라고도 함)

