데이터 스케일링
• 개념
• 변수들의 분포나 범위를 동일하게 조정하는 전처리 작업
• 필요성
• 변수들의 단위가 다르기 때문에 범위 차이가 큰 변수가 함께 학습시문제가 될 수 있음
• 단위가 큰 변수의 값이나 아웃라이어(outlier) 값이 학습에 큰 영향을 줄 수있음
데이터 스케일링
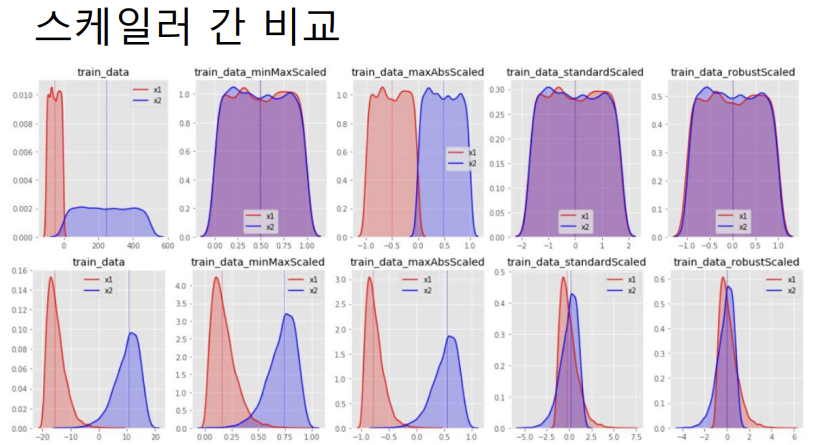
- 스케일링의 종류
• StandardScaler()
• 모든 변수들을 평균이 0, 분산이 1인 정규분포를 갖도록 함
• MinMaxScaler()
• 모든 변수들을 0(최소값)과 1(최대값) 사이의 값을 갖도록 함
• MaxAbsScaler()
• 모든 변수들의 절대값이 0과 1(최대 절대값) 사이에 놓이게 함
• 이상치의 영향을 크게 받음
• RobustScaler()
• StandardScaler와 비슷한데 평균과 분산 대신 중간값과 사분위값을 이용함• 이상치의 영향이 최소화됨
1번,4번이 비슷
2번,3번이 비슷
스케일링
- 모든 변수의 분포를 동일하게 만들 필요는 없음
• 원본데이터의 분포를 유지하는 것이 더 유의할 수도 있음 - 아웃라이어는 모든 스케일링 기법에서 변환효과를 저해함
• 아웃라이어 처리에 대한 판단이 필요함 - 모델 별로 스케일링에 민감하거나 덜 민감함
• 군집(클러스터링) 모델, 회귀 모델, 서포트벡터머신(SVM) 등은민감
• 트리기반 모델, 로지스틱 회귀 모델 등은 덜 민감

지식을 흡수하고 싶다!!!