⏰ 성능 이슈 발생
쿼리 메서드를 작성하고 의도한대로 작동했는지 확인하고 있었습니다.
엔티티에 존재하는 applicant, group, status 필드를 조건으로 하여 데이터를 조회하는 쿼리 메서드입니다.
Repository
import org.springframework.data.jpa.repository.JpaRepository;
public interface SubscriptionRepository extends JpaRepository<Subscription, Long> {
Optional<Subscription> findByApplicantIdAndGroupIdAndStatus(UUID applicantId,
Long groupId,
SubscriptionStatus status);
}
Entity
import jparest.practice.group.domain.Group;
import jparest.practice.user.domain.User;
@Entity
public class Subscription extends TimeBaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "subscription_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "group_id")
private Group group;
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "user_id")
private User applicant;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private SubscriptionStatus status;
@Column(length = 40)
private String message;
...
}
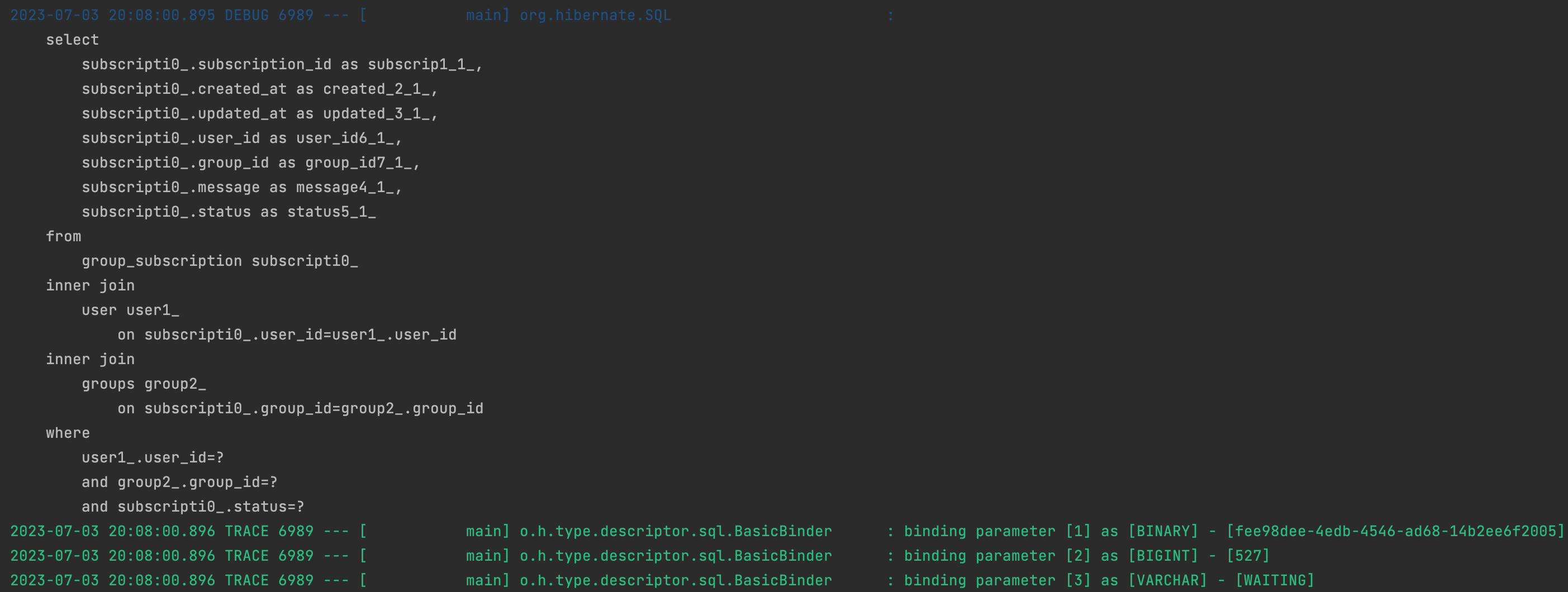
제가 의도한 동작 방식은 조인을 하지 않고 Subscription 엔티티의 필드만으로 데이터를 조회하는 것이었습니다.
Join 이 사용된 이유가 궁금했습니다.
🔍 성능 이슈 원인
의심이 됐던 원인은
쿼리 메서드 작성 시, 조건으로 외래키(ApplicantId, GroupId) 값을 사용했고,
엔티티에는 연관관계의 객체(User, Group)가 있다는 것입니다.
쿼리 메서드가 외래키를 읽지 못하고 join 이 발생한다?
이렇게 생각하기에는 이해가 되지 않아서 쿼리메서드의 동작 과정을 찾아봤습니다.
쿼리 메서드 동작 과정
Property travelsal
Property expressions can refer only to a direct property of the managed entity, as shown in the preceding example. At query creation time, you already make sure that the parsed property is a property of the managed domain class. However, you can also define constraints by traversing nested properties.
쿼리메서드는 기본적으로 엔티티의 직접적인 속성만 참조할 수 있다고 합니다.
그 외에는 사용된 값을 구분하기 위해서 중첩된 속성을 순회하여 제약 조건을 정의한다고 합니다.
예시
List<Person> findByAddressZipCode(ZipCode zipCode);위와 같은 예시에서 다음과 같은 알고리즘으로 동작합니다.
- 전체 이름이 엔티티에 존재하는지 찾는다.
- 존재하지 않을 경우, 카멜케이스 기준으로 머리와 꼬리로 분할하고 머리를 엔티티에서 찾는다.
- 존재하지 않을 경우, 분할 기준을 왼쪽으로 옮긴다.
- 머리가 엔티티에 존재하는 필드일 경우, 꼬리가 머리의 속성값이 맞는지 확인한다.
- 꼬리의 값이 머리에 존재하지 않는다면, 꼬리를 카멜케이스로 분할하여 동일한 알고리즘을 통해 트리를 계속 구축한다.
Address.Zip.Code 라는 값을 사용했을 경우의 속성 순환
- Person 엔티티에서 AddressZipCode 찾기
- AddressZip / Code - AddressZip 필드 찾기
- Address / ZipCode - Address 필드 찾기
- Address 에 ZipCode 속성이 있는지 확인하기
- ZipCode -> Zip / Code -> ... 위와 같은 알고리즘 반복
나의 사용목적과 쿼리 메서드의 동작방식이 다르다
-
저의 경우 And 구분자를 사용하였기 때문에
쿼리메서드는 AppicationId, GroupId, Status 세개의 조건이 엔티티의 필드가 맞는지 확인했을 것입니다. -
알고리즘을 통해 ApplicantId 과 GroupId 를 각각 Applicant / Id , Group / Id 로 분할합니다.
-
Applicant, Group 에 각각 Id 속성이 존재하는지 찾습니다.
존재하므로 Applicant.Id , Group.Id 와 일치하는 데이터를 찾습니다. -
Applicant.Id, Group.Id 는 각각 User, Group 엔티티에 존재하는 기본키 필드입니다.
쿼리메서드는 다른 엔티티의 기본키를 사용한것을 확인하고, Join 을 사용해 다른 엔티티와 연결된 결과를 출력하려 한 것이라 예상합니다.
저는 필드의 외래키를 이용해서 조건에 맞는 결과를 조회하고 싶었습니다.
그러나 쿼리메서드는 필드의 직접 속성을 사용하는 것이 기본 동작방식이고, 그 외에는 속성 순환을 통해 Join 으로 데이터를 조회하기 때문이었습니다.
🔑 성능 개선 방법
1. 외래키 대신 연관 관계의 엔티티 사용
쿼리 메서드가 원하는 조건 사용 방식은 엔티티의 직접적인 속성 사용입니다.
즉, 외래키인 id 값으로 조회하지 않고 연관 관계에 있는 엔티티를 매개변수로 사용하면 Join 을 사용하지 않습니다.
Optional<Subscription> findByApplicantAndGroupAndStatus(User applicant, Group group, SubscriptionStatus status);
단점은 클라이언트로부터 전달받는 값을 사용해서 조회하는 상황이 있을텐데, id 값으로 엔티티를 조회한 후에 매개변수로 사용해야 한다는 점입니다.
쿼리가 추가되는 단점이 생깁니다.
2. JPQL
쿼리 메서드 대신에 JPQL 을 사용하면 필드의 id 값 만으로도 Join 을 사용하지 않고 결과를 가져올 수 있습니다.
@Query("SELECT s FROM Subscription s " +
"WHERE s.applicant.id = :applicantId AND s.group.id = :groupId AND status = :status")
Optional<Subscription> findByApplicantIdAndGroupIdAndStatus(@Param("applicantId") UUID applicantId,
@Param("groupId") Long groupId,
@Param("status") SubscriptionStatus status);
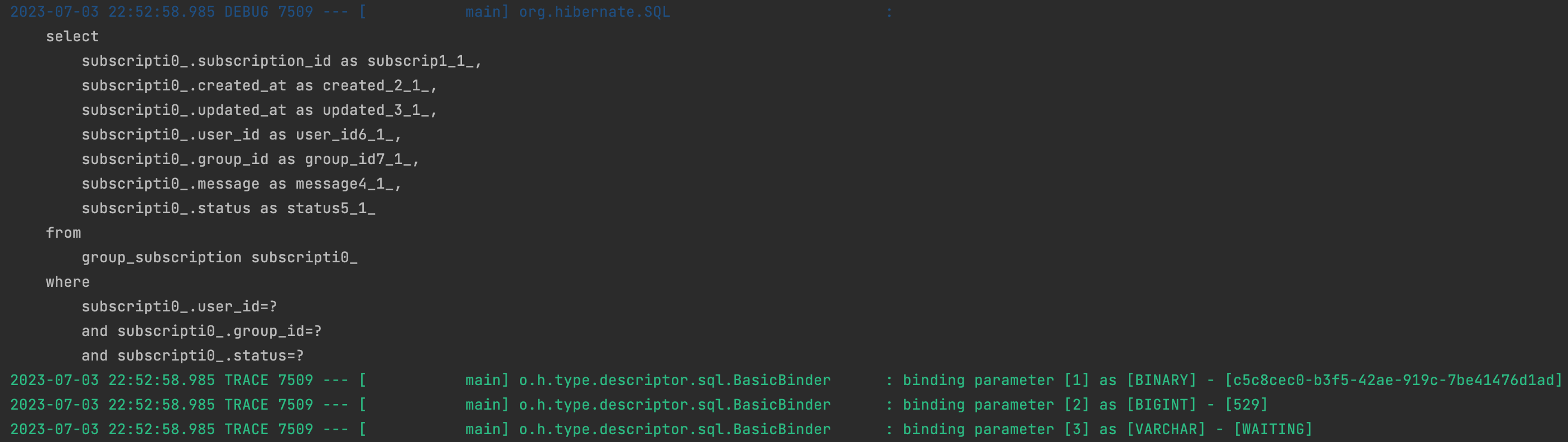
Join 을 호출하지 않습니다..⭐️
📄 요약
쿼리 메서드 사용 시 엔티티에 직접적으로 존재하지 않는 값은 속성 순환을 통해 값을 찾습니다.
속성 순환을 통해 찾은 값이 다른 테이블의 기본키일 경우, 다른 테이블과 연결된 결과를 원한다고 판단해서 자동으로 Join 을 사용합니다.
객체의 속성값처럼 엔티티 내에 직접 존재하지 않는 속성값으로 조회할 때는
연관 관계의 엔티티를 매개변수로 사용하거나,
쿼리메서드 대신 JPQL 을 사용하면 Join 을 사용하지 않을 수 있습니다.
참고 자료
