프로그래머스_알고리즘
1.해시 : 프로그래머스 - 위장
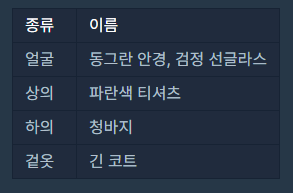
: 어떻게 하지 어떻게 하지 하다가, 일단 노트에다가 \-> 23개가 나온다. 1번 예제를 표로 그려보면 : 사용안한다라는 표현을 + 1 추가하는 방식으로 생각을 해볼수 있다.그렇다면 head에는 사용안함, "yellowhat","green_turban"그러면 eye에
2.dp : 프로그래머스 - 가장 큰 정사각형
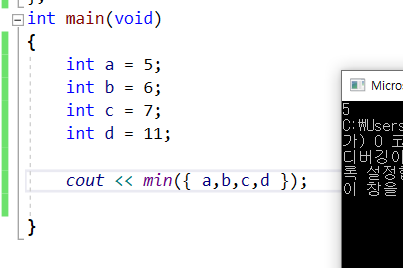
1) 처음에는 정사각형이니까 우측 하단부가 1일 경우에 상하좌우를 일일 확인하는 방식으로 하려고 했는데, 정사각형이 클수록 효율이 좋지 않아지므로 이건 아니다 싶음2) 정사각형을 작게 만들어보면서 생각해보면 다이나믹 프로그래밍으로 접근하면 풀수 있다고 생각함. 2by
3.프로그래머스 - 기능개발

입출력 1번에서는 7 - 3 - 9 일작업순 이고 입출력 2번에서는 5 - 10 - 1 - 1 - 20 - 1 일작업순이다 .규칙성을 찾을 수 있다. 1번의 결과는 2 - 1 이고2번의 결과는 1 - 3 - 2 이다. 7번을 가지고 마지막 인덱스까지 비교하면서 큰 값이
4.프로그래머스 - 프린터

문제를 읽어보면, priority가 가장 큰 친구부터 빼야되는 것을 확인할 수 있다.1) 2,1,3,2 에서 제일 큰 친구가 3이므로 맨 앞의 친구 2를 빼서 꼬리에다가 추가를 해야한다. -> queue stl을 사용하면 되겟다. 라고 생각함.2) 우선 순위가 가장
5.프로그래머스 - 다리를 지나는 트럭
먼저 들어간 친구가 먼저 나오는 방식이어서 큐를 사용해야겠다고 생각함.대키 트럭과 카운트값을 pair형식으로 가지고 진행하면서 카운트값이 bridge_length가 되면 pop하는 방식으로 진행하려고 했다. pair로 가지고 있으려면 vector를 사용한다. 문제점으로
6.프로그래머스 - 완주하지 못한 선수
문제를 읽어보면 참가자 - 완주한 사람으로 이루어짐.낙오자가 단 한명만 있다고 한다.중복됨=> unordered_map으로 풀이하면 된다고 생각함.unordered_map<string, int>man;
7.프로그래머스 - 전화번호 목록
phone_book이라는 컨테이너에 전화번호를 저장 , 중복 처리 안됨.문제를 보면 접두어가 다른 목록에 있다면 false를 리턴하고,만약에 다른 목록 중에 접두어가 없다면 true라고 한다. => 찾는 문제다. 그리고 제한사항으로 phone_book에는 1 ~ 100
8.프로그래머스 - 베스트 앨범.
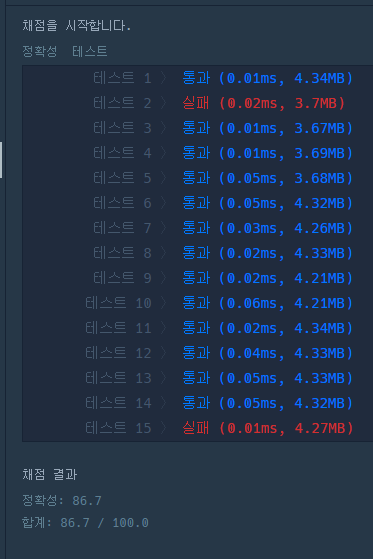
: first 값만으로 정렬이 가능하므로, multimap으로 풀경우 머리 아파진다...
9.프로그래머스 - k번째 수
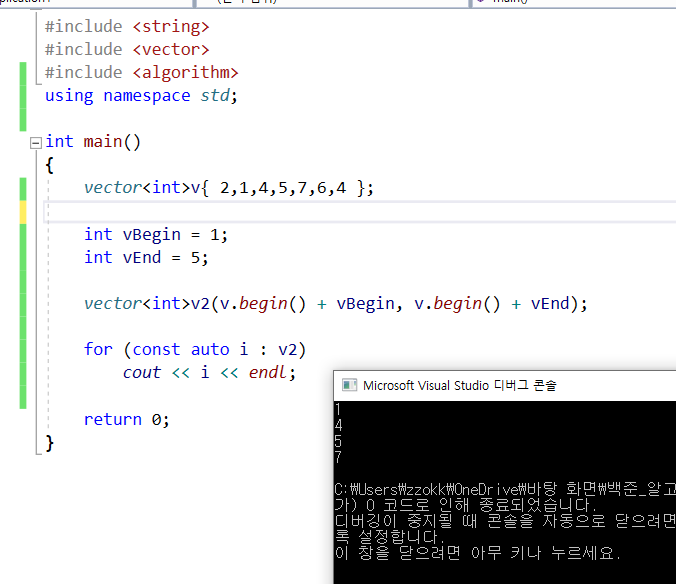
vectorv(v1.begin(), v1.end()) 이렇게 복사를 해왔다.그래서 index값을 넣을수 있지 않을까 생각했는데 안된다.벡터 초기화 : 이런식으로 가능하다. 하지만 + 1을 더 진행해야 한다. sort(v.begin(), v.end()) 이런식으로 했다.
10.프로그래머스 - 정렬
정렬을 해야하므로 생각할 수 있는 점으로 원소 2개를 이용한다는 것을 캐치해야 한다. 예를 들어 6 vs 2 일때62 vs 26을 비교한다
11.프로그래머스 - hIndex
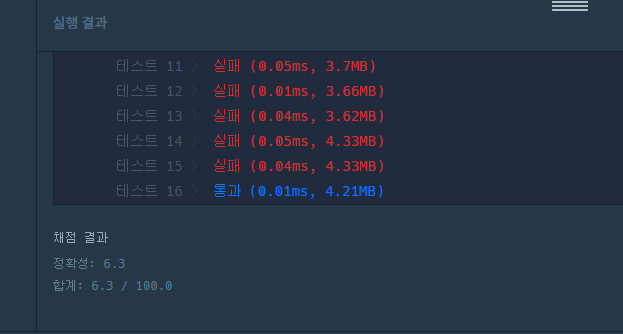
\-> 코드 실행은 맞았다. 다른방법으로 접근하자.
12.프로그래머스 - 더 맵게
https://velog.io/@kwt0124/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84%ED%81%90가장 작은 친구 + 그 다음 친구 \* 2를 추가해야 한고예외처리로 진행 중, 2번째 친구를 추출해야 하는데 추출못하는 상황즉, 첫번
13.프로그래머스 - 모의고사
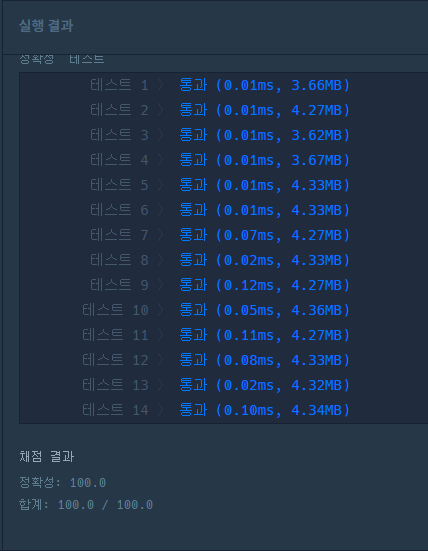
수포자 3명의 규칙성을 찾고, 벡터로 도식화하자 문제랑 수포자 3명의 답안 이랑 비교해야 하므로 2차원 for문 을 사용해야 함.수포자 3명의 답안이 마지막번 다음에 첫번째로 복귀해 하므로 이부분을 주의 깊게 생각해보자 \-> 나머지를 이용하면 첫번째 답안으로 복귀 가
14.프로그래머스 - 소수찾기
소수 구하는 식 알아야함.순열하는 방법을 알아야함. => 다른 방법을 생각해보자. 그게 아니라,,, 정렬을 안했다....
15.프로그래머스 - 카펫
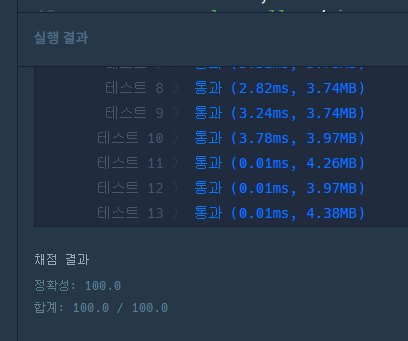
테두리의 갈색은 한줄이다. 가로의 길이는 세로보다 크거나 같다. 문제를 읽고 그림을 그려보면서 공통점을 찾아보면 일단 (yellow의 가로 2) + (yellow의 세로 2) + 4 => brown의 갯수라는 것을 찾을 수 있다. yellow의 개수만을 이용한 경우
16.프로그래머스 - 체육복
중복 없고, 두개의 값이 있어서 unordered_map으로 접근하려고 햇다. 앞뒤 인덱스를 확인해야 하므로\-> 인덱스 접근을 해야했다. unordered_map 접근 잘못 되었다.vector<pair<int,int>> 로도 접근 해볼까? 라는 생각도 함.
17.프로그래머스 - 조이스틱
풀다 보니 dp로 알파벳 a부터 z까지 타겟으로 잡은 값을 비교한 최소값을 넣어준 다음에 해야 효율이 좋겠구나 생각을 했지만, 이미 순차적으로 진행해서 못 바꿈.자리 이동하는 거 cur위치에서 타겟 자리로 좌측이동 vs 우측 이동한 값의 최소값을 구하고, 알파벳을 위로
18.프로그래머스 - 구명보트
1번 : 문제를 보고 처음 들었떤 생각은 가장 큰 친구와 가장 작은 친구의 합이 limit보다 작거나 같다면 최소비용으로 구조할수 있다고 생각했다.\-> 일단 sort 시키자.한번 생각할 점이... 만약에 20,40,40,60,80 이 있다면 limit은 가장 큰 친구
19.프로그래머스 - 정수삼각형
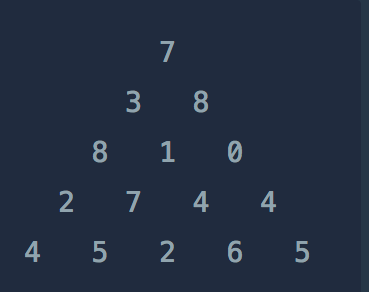
문제를 보면 대각선 왼쪽, 오른쪽 아래로 향하면서 가장 큰값을 출력해는 문제이다. 처음 생각으로는 아래를 보았을때 가장 큰 친구를 뽑아서 진행할까?라는 생각을 했지만,,,, 추후를 생각했을때 문제가 될 소지가 있는 생각이다.왜냐하면 8을 선택했다면... 7-3-8 이
20.프로그래머스 - 타켓 넘버
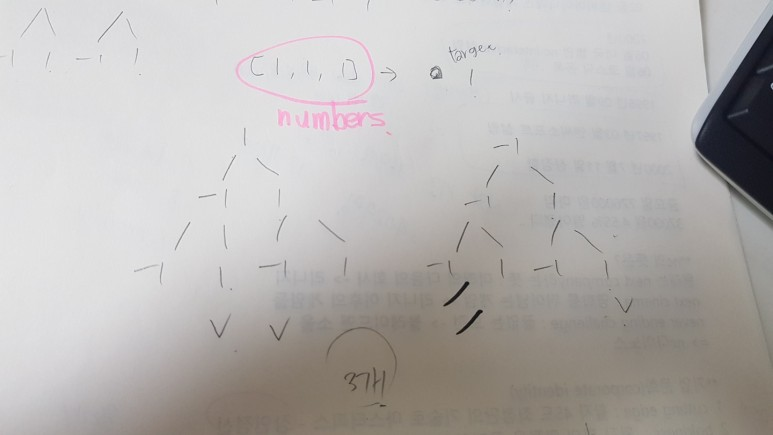
dfs를 이용해서 함수안에서 + 와 - 를 이용해 인덱스값을 이용해야 겠다고 생각했다.: 매개변수로 인덱스의 갯수를 증가하고, sum에 누적하는 방식으로 진행하고자함. 그런데 복귀해서 - 값 연산을 해야한다. \-> 문제점이 무엇이냐면... 전위 증감연산을 함으로써 i
21.프로그래머스 - 네트워크
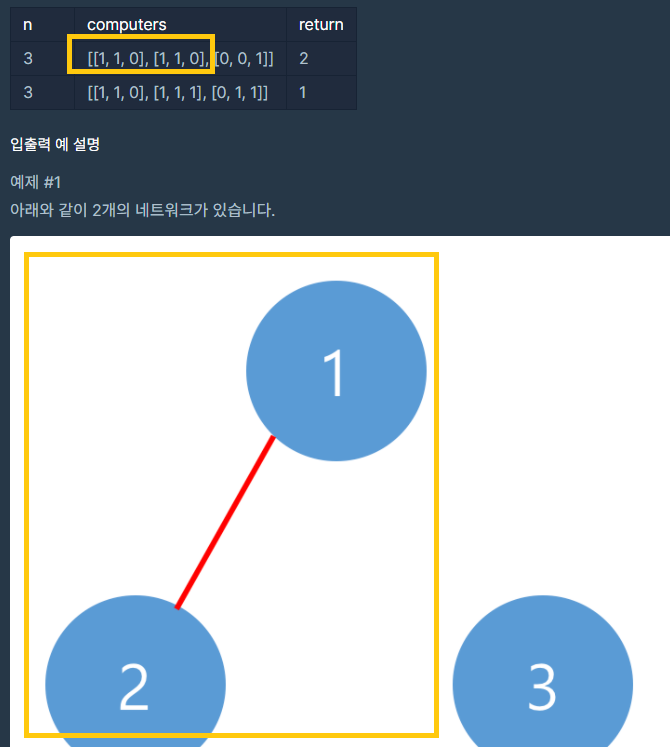
인덱스 번호 증가함에 따라 1이 포함된 값을 큐에 집어 넣고, 바로 옆에 붙어 잇는 친구들을 탐색하는 것이므로 bfs로 풀어야 겟다고 생각햇다.solution에다가 바로 작성하면 되지 않을까 생각을 했는데, 연결이 안되어 있는 친구들 접근을 못하므로, 바깥으로 뺀후,
22.bfs로 푼 : 프로그래머스 - 단어변환
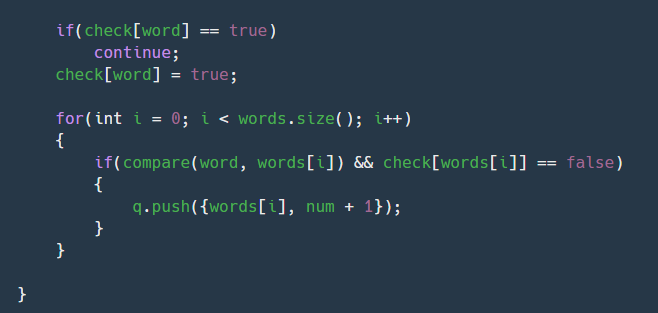
최소거리를 구하는 것이므로 bfs로 접근하는 것이 빠르다. 어떻게 bfs로 접근할지에 대해 고민해봐야 하는 문제다. 가. hot - dot - dog- log - cog나. hot - dot - dog - cog다. hot - lot - log - cog이런방식으로 접
23.프로그래머스 - 등굣길
1) 일단 기존의 좌표체계가 뒤집어졌다. 이것을 염두에 두고 풀어야한다. 우리의 좌표체계에 맞게 설계해야 한다. : 학교의 위치가 (4,3) 이라고 하는데, 우리의 좌표체계로는 저 부분은 (3,4)일 수 밖에 없다. 2) 놓친점으로는 부등호처리를 못해줬다는 점... :
24.백트래킹 : 프로그래머스 - 여행경로
문제에서 모든 도시를 방문해야 한다고 하므로 dfs를 생각할 수 있다. dfs vs bfs dfs : 모든 정점을 방문해야 한다. , 집합을 표현할때 사용한다. bfs : 모든 정점을 방문할 필요는 없다. , 최단 거리 구할때 사용한다.
25.프로그래머스 - 방문길이
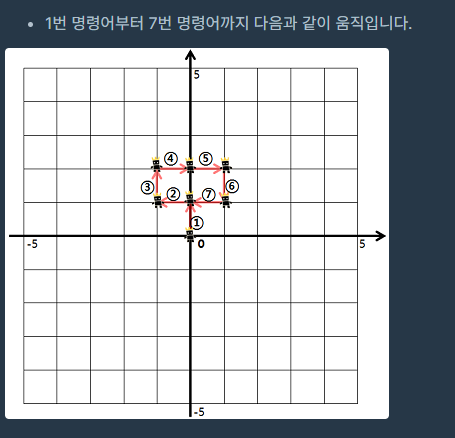
tuple을 활용하자. //헤더가 필요하다. 예외처리 중요하다.
26.프로그래머스 - 베스트 앨범
mapping을 이용해 <string, int> : 동일한 string에서의 합계를 구한 후 reverse 하자. reverse 상태에서 내림차순으로 만든 다음에 가장 큰 친구의 string을 뽑아서 전체 컨테이너 중에서 가장 plays 높은 두명의 친구를 뽑아서
27.이분탐색 : 프로그래머스 - 입국 심사.
소스코드
28.bfs : 프로그래머스 - 게임맵 최단거리
x값은 second값이고, y값은 first값이다. 그리고 x값은 가로의 총길이를 나타내고,y값은 세로를 나타낸다. vector<vector>v에서 v.size()는 세로의 길이고, v0.size()는 가로의 길이이므로second는 v0.size()와 매칭이 되어
29.dp : 프로그래머스 - n으로 표현
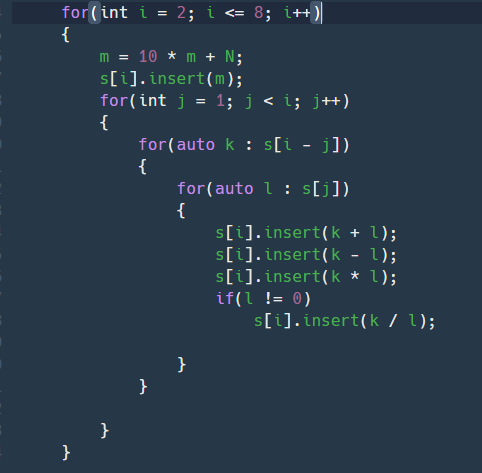
소스코드
30.프로그래머스 - 도둑질
https://chosh95.tistory.com/371
31.bfs : 프로그래머스 - 가장 먼 노드
최단 경로를 구하는 것인데 , 단순히 노드의 연결되어 있는 노드로 접근하는 것이다. \-> bfs로 접근하자 .원소의 갯수를 얻어야 하므로 lower_bound를 사용하자.
32.프로그래머스 - 좌석 구매 : 스쿨에 있는 문제
map의 key값을 pair값으로 사용하기
33.백트래킹 : 프로그래머스 단어 변환
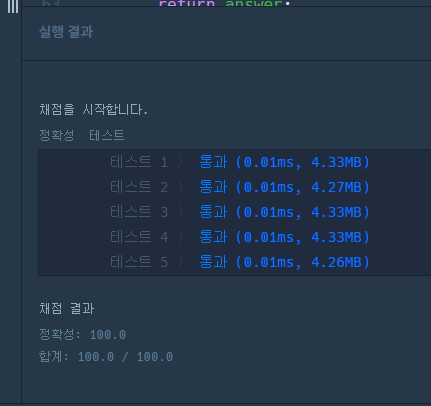
백트래킹으로 풀어보았다!
34.괄호 회전하기
: 스택과 큐를 사용했다.내가 몰랐던부분은 queue q;q.push('b');q.push('o');q.push('m');q.push('i');queue<char q2 = q1; 을 하게 되면 q2에 bomi가 들어있다는 것이다.