1. 배열 (Array)
설명: 동일한 자료형의 값들을 연속된 메모리 공간에 저장하는 자료구조.
특징: 인덱스를 통해 O(1) 시간 복잡도로 접근 가능하지만, 크기가 고정되어 있으며 삽입 및 삭제가 비효율적일 수 있음.2. 연결 리스트 (Linked List)
설명: 각 요소가 데이터와 다음 요소의 포인터로 이루어진 자료구조.
특징: 삽입과 삭제는 O(1)로 효율적이지만, 임의 접근은 O(n) 시간이 걸림.3. 스택 (Stack)
설명: LIFO(Last In, First Out) 원칙을 따르는 자료구조.
특징: 삽입(push)과 삭제(pop)가 O(1) 시간에 이루어짐. 함수 호출 시의 호출 스택과 같은 곳에서 사용됨.4. 큐 (Queue)
설명: FIFO(First In, First Out) 원칙을 따르는 자료구조.
특징: 삽입과 삭제가 O(1)로 이루어지며, 작업 예약이나 BFS와 같은 알고리즘에서 사용됨.5. 해시 테이블 (Hash Table)
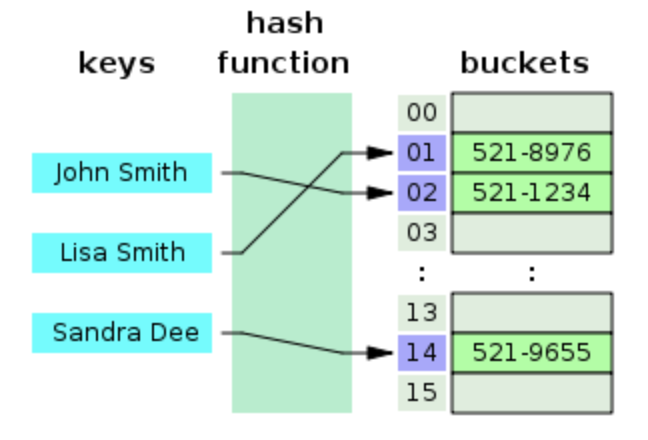
설명: 키와 값을 쌍으로 저장하는 자료구조로, 해시 함수를 통해 키를 인덱스로 변환.
특징: 평균적으로 O(1) 시간에 요소를 검색, 삽입, 삭제할 수 있지만, 해시 충돌이 발생하면 성능 저하가 있을 수 있음. (분리연결법, 개방 주소법 사용)
6. 트리 (Tree)
설명: 계층 구조를 표현하는 자료구조로, 노드들이 부모-자식 관계를 가짐.
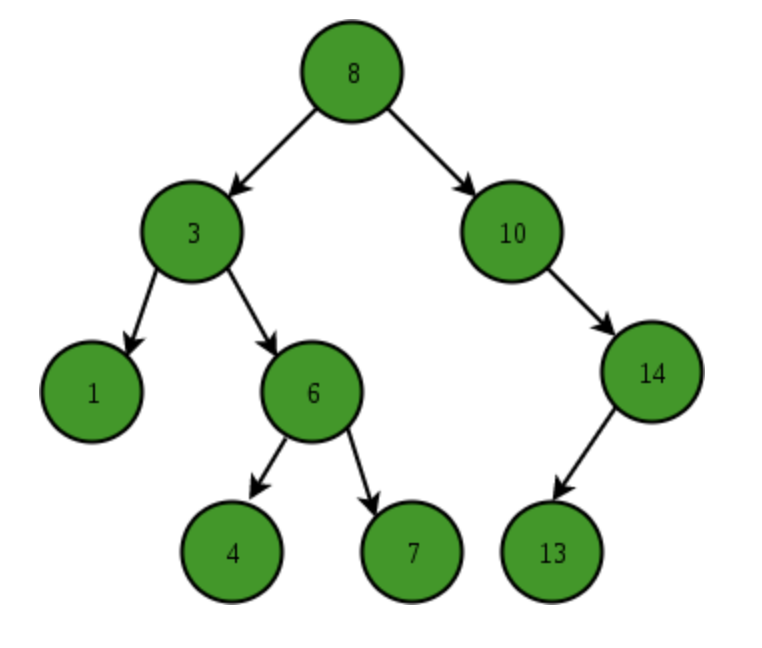
특징: 이진 탐색 트리(BST)의 경우 평균적으로 O(log n)의 시간 복잡도로 탐색, 삽입, 삭제 가능.7. 이진 탐색 트리 (Binary Search Tree)
설명: 이진트리+연결리스트 형태로, 탐색능력과 삽입삭제에 유리하게 구성
특징: 삽입, 검색, 삭제가 균등트리 O(logN), 편향트리 O(N)
8. 그래프 (Graph)
설명: 정점(Vertex)과 간선(Edge)으로 이루어진 자료구조. 정점들 간의 관계를 나타냄.
특징: DFS, BFS와 같은 탐색 알고리즘을 사용할 수 있으며, 네트워크 구조나 경로 탐색에 사용됨.9. 트라이 (Trie)
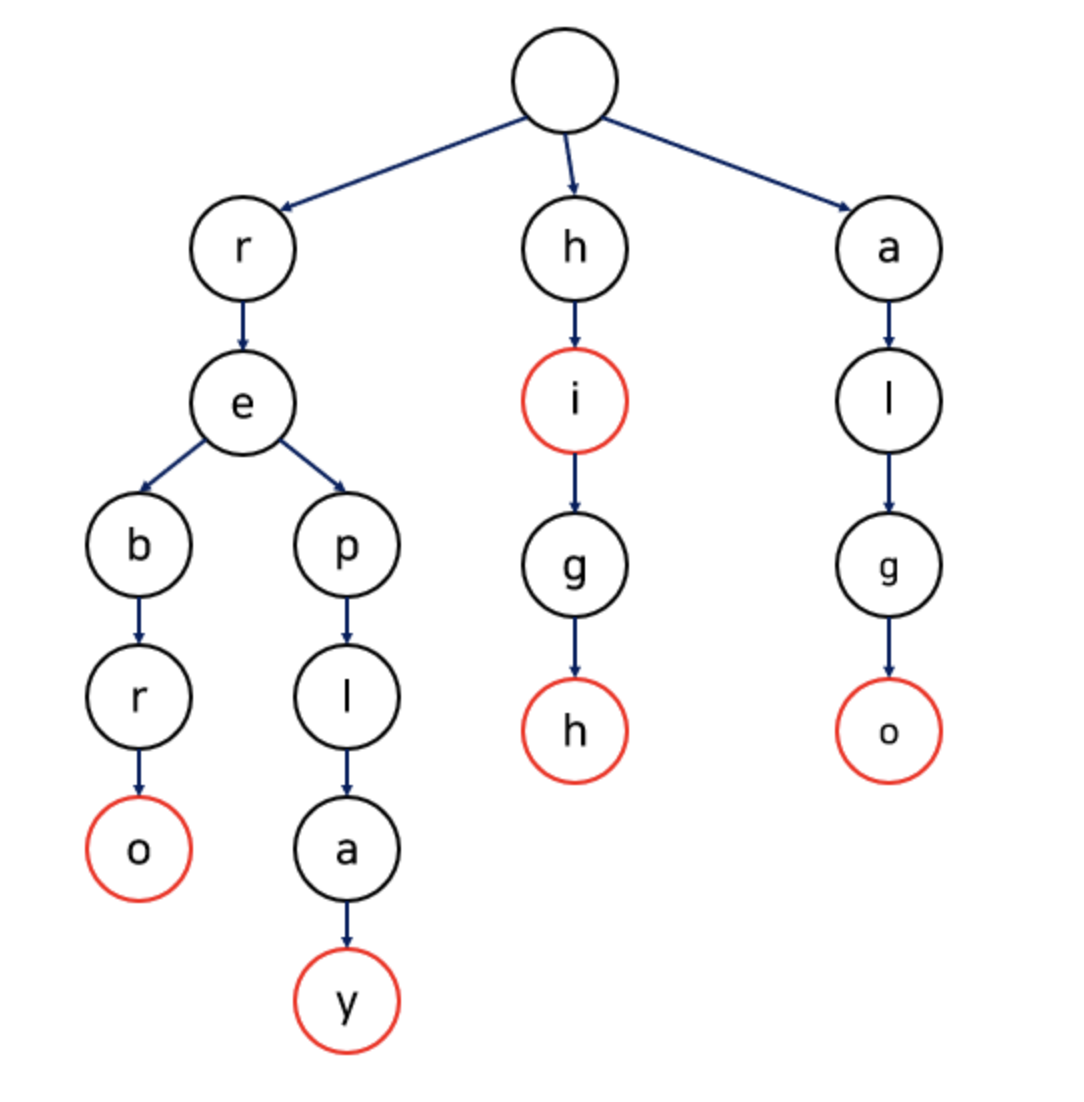
설명: 문자열 집합을 저장하고 효율적으로 검색하기 위한 트리 기반 자료구조.
특징: 문자열 검색에 O(문자열길이) 시간복잡도를 가지며, 자동완성 기능 구현에 사용됨.
Reference
https://inthiswork.com/archives/159726
https://velog.io/@klloo/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%9D%BC%EC%9D%B4Trie-%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0
https://gyoogle.dev/blog/computer-science/data-structure/Binary%20Search%20Tree.html
