[면접을 위한 CS 전공지식 노트] 도서를 읽고 정리한 글 입니다.
티스토리에 정리했던 내용을 벨로그로 옮겼어요!
https://kkomyoung.tistory.com/5
1. 메모리 계층
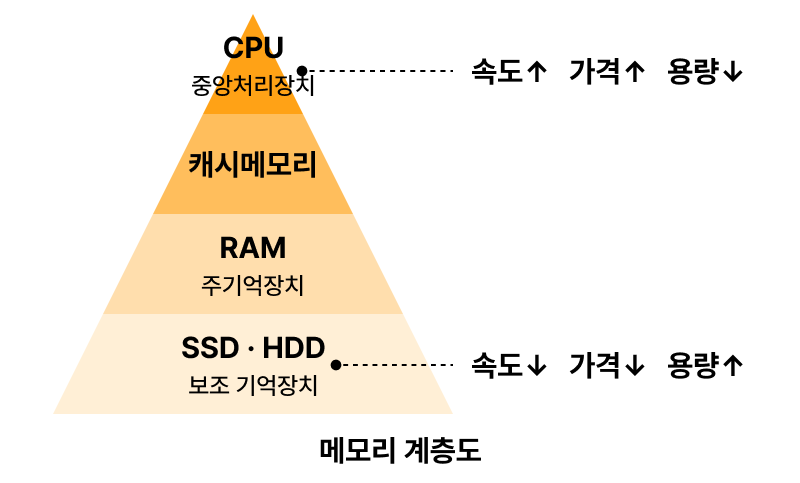
메모리 계층구조는 속도, 가격, 용량과 같은 요소를 고려하여 메모리를 계층적으로 구성하는 것이다.
이러한 계층화는 데이터를 빠르게 가져와서 CPU에 제공하는 것이 목적이다.
- 레지스터(Register) : CPU 내부에 위치하며 가장 빠르게 데이터를 저장할 수 있는 메모리이다. 하지만 용량이 작고 가격이 비싸다.
- 캐시(Cache) : CPU와 주기억장치 사이에 위치하며 데이터를 미리 가져와서 CPU가 더 빠르게 데이터에 엑세스 할 수 있게 한다. 레시스터보다는 용량이 크고 비용이 적은 편이지만, 주기억장치보다는 속도가 빠르다.
- 주기억장치(Main Memory) : 컴퓨터가 프로그램과 데이터를 저장하는 데 사용하는 일반적인 메모리이다. 용량은 캐시에 비해 크지만 속도는 비교적 느리며 비용도 더 많이 든다. (종류 : ROM(비휘발성), RAM(휘발성))
- 보조기억장치(Secondary Storage) : SSD, HDD, USB와 같은 외부 기기이다. 메인 메모리와 달리 비교적 저렴하고 큰 용량을 가지고 있고 데이터를 영구적으로 저장할 수 있다.
1-1. 캐시
캐시는 CPU가 자주 액세스하는 데이터를 저장함으로써 메모리 액세스 시간을 줄이고 전체 시스템 성능을 향상시킨다.
캐시의 작동 방식은 다음과 같은 지역성의 원리에 기반한다.
시간 지역성
최근에 액세스한 데이터는 다시 액세스될 가능성이 높다는 개념이다.
더보기
예시) 반목문에서 변수를 참조할 때,
예를 들어, 반복문을 실행하는 프로그램에서, 같은 변수를 반복적으로 참조한다고 가정해 봅시다. 이 경우, 변수가 캐시에 로드되고 이후의 반복문에서도 계속해서 참조되므로, 캐시에 계속해서 남아있게 됩니다. 이는 CPU가 매번 변수를 참조할 때마다 메모리에서 데이터를 가져오는 것보다 캐시에서 데이터를 가져오는 것이 더 빠르게 처리됩니다.
이러한 방식으로, 캐시의 시간 지역성은 CPU가 캐시에서 데이터를 가져와야 할 때, 동일한 데이터가 반복적으로 액세스될 가능성이 높으므로, 해당 데이터를 캐시에 유지함으로써 전체적인 성능을 향상시킬 수 있습니다.
공간 지역성
최근에 액세스한 데이터와 인접한 주소의 데이터도 다음에 액세스될 가능성이 높다는 개념이다.
더보기
예시) 배열에 대한 반목문을 실행할 때,
예를 들어, 배열에 대한 반복문을 실행할 때, 배열의 첫 번째 요소를 액세스하고 그 이후에 이어지는 요소들을 차례로 액세스한다고 가정해 봅시다. 이 경우, 첫 번째 요소를 액세스할 때 캐시가 이를 로드하고 이후의 요소들도 캐시에 저장됩니다. 따라서, 다음 요소들을 액세스할 때 캐시에 이미 존재하기 때문에, 매번 메모리에서 데이터를 가져오는 것보다 캐시에서 데이터를 가져오는 것이 더 빠르게 처리됩니다.
이러한 방식으로, 캐시의 공간 지역성은 CPU가 캐시에서 데이터를 가져와야 할 때, 해당 데이터 근처에 있는 데이터를 미리 로드함으로써 전체적인 성능을 향상시킬 수 있습니다.
1-2. 캐시히트와 캐시미스
- 캐시 히트 (Cache Hit) : CPU가 캐시에 있는 데이터에 액세스할 경우를 말한다.
- 캐시 미스 (Cache Miss) : 캐시에 데이터가 없어 메모리에서 데이터를 가져와야 할 경우를 말한다.
캐시 히트는 해당 데이터를 캐시에서 바로 가져올 수 있기 때문에 시스템 성능을 향상시키는 요소이지만 캐시 미스는 메모리 엑세스 시간이 필요하기 때문에 전체 시스템 성능을 저하시키는 요소이다.
캐시매핑
캐시 매핑은 캐시 메모리에 데이터를 저장하는 방법을 결정하는 것이다.
캐시 매핑 방법에 따라 어떤 데이터를 어떤 위치에 저장할지가 결정된다.
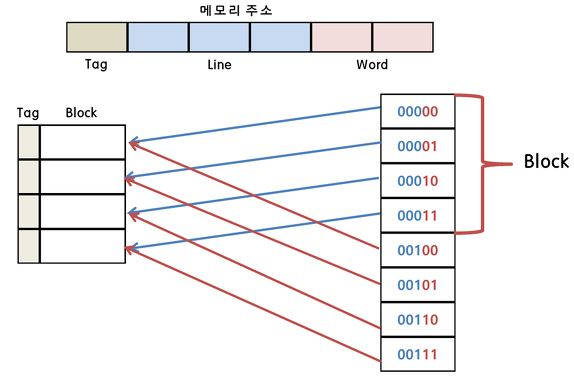
1. 직접 매핑(Direct Mapping)
메모리의 주소를 캐시의 특정 블록에만 매핑하여 저장하는 방식이다.
- 장점 : 검색 속도가 빠르고 구현이 간단하다.
- 단점 : 메모리의 주소가 캐시의 특정 블록에만 할당되기 때문에 데이터 충돌이 발생할 수 있다.
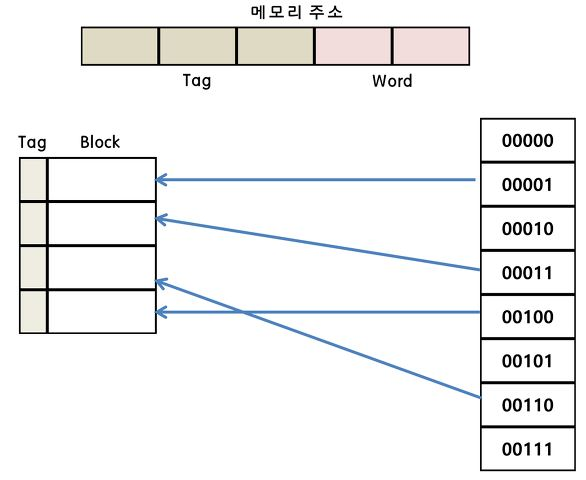
2. 연관 매핑(Associative Mapping)
메모리의 주소가 캐시 전체의 어느 위치에나 저장될 수 있도록 하는 방식이다.
- 장점 : 검색 성능이 우수하고 데이터 충돌이 적다.
- 단점 : 캐시의 모든 블록을 탐색해야해서 속도가 느리고 구현이 복잡하다.
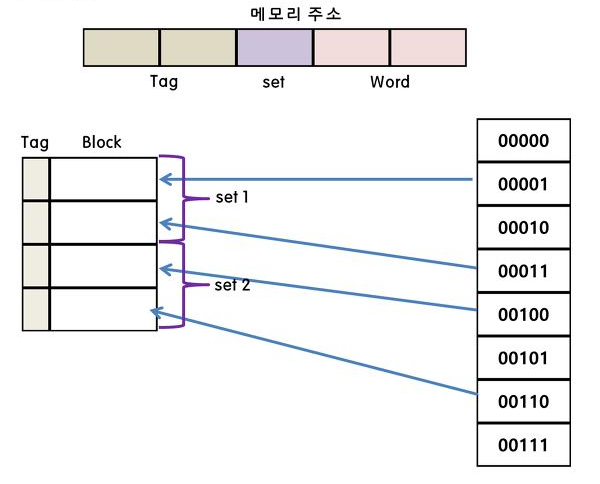
3. 집합 연관 매핑(Set Associative Mapping)
직접 매핑과 연관 매핑의 장점을 결합한 방식이다.
집합을 나누고 각 집합에 직접 매핑을 사용하는 것이다.
- 장점 : 모든 캐시를 뒤지는 일 없이 바로 캐시 히트, 미스 여부를 알 수 있다.
- 단점 : 데이터 충돌이 일어날 가능성이 있다.
웹 브라우저의 캐시
웹 브라우저 캐시란 웹 페이지에서 로드한 리소스(이미지 ,css, javascript 등)들을 일시적으로 저장하는 공간이다.
웹 브라우저 캐시를 사용하면 같은 웹 페이지를 다시 방문할 때 브라우저는 서버에서 리소스를 다시 다운로드하지 않고 캐시에 저장된 리소스를 사용하여 빠르게 웹 페이지를 로드할 수 있다.
1. 쿠키(Cookie)
- 만료기한이 있는 키-값 저장소이다.
2. 로컬 스토리지(Local Storage)
- 만료기한이 없는 키-값 저장소이다.
- 웹 브라우저를 닫아도 유지되고 도메인 단위로 저장된다.
3. 세션 스토리지(Session Storage)
- 만료기한이 없는 키-값 저장소이다.
- 탭 단위로 생성되며 탭을 닫으면 해당 데이터가 삭제된다.
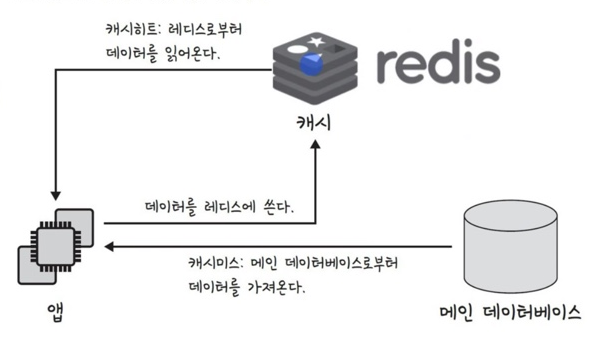
데이터베이스의 캐싱 계층
데이터베이스 시스템을 구축할 때도 메인 데이터베이스 위에 레디스(redis) 데이터 베이스 계층을 캐싱 계층으로 둬서 성능을 향상시키기도 한다.
2. 메모리 관리
2-1. 가상 메모리
물리적인 메모리(RAM)의 용량을 늘리기 위한 것이다.
당장 실행해야 하는 부분만 주 기억장치에 넣고 나머지는 보조기억장치에 넣어 동작하도록 한다.
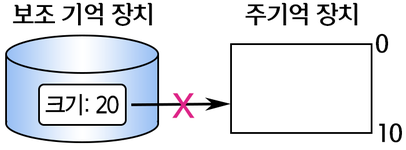
가상 메모리가 필요한 경우
- 주기억장치의 크기는 10이지만, 데이터의 크기는 20
- 주기억장치의 공간이 두 개이지만 실행된 프로그램은 세 개
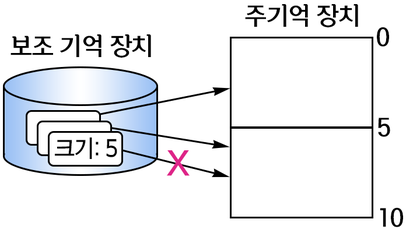
- 지금 당장 필요한 데이터만 주기억 장치에 넣는다.
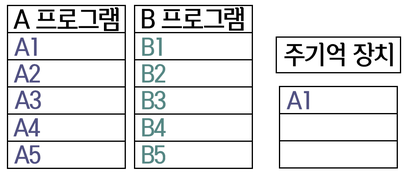
스와핑
메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮기고 하드디스크의 일부분을 마치 메모리처럼 불러와 사용하는 것을 말한다.
페이지 폴트
가상 메모리에는 존재하지만 실제 메모리인 RAM에는 현재 없는 데이터나 코드에 접근하는 경우에 발생하는 것을 말한다.
운영체제는 페이지 폴트가 발생하면 운영 체제는 그 데이터를 메모리로 가져와서 마치 페이지 폴트가 전혀 발생하지 않은 것처럼 프로그램이 계속적으로 작동하게 한다.
1. CPU는 물리 메모리를 확인하여 해당 페이지가 없으면 트랩을 발생해서 운영체제에 알린다.
2. 운영체제는 CPU의 동작을 잠시 멈춘다.
3. 운영체제는 페이지 테이블을 확인하여 가상 메모리에 페이지가 존재하는지 확인하고, 없으면 프로세스를 중단하고 현재 물리 메모리에 비어 있는 프레임이 있는지 찾는다. 물리 메모리에도 없다면 스와핑이 발동된다.
4. 비어 있는 프레임에 해당 페이지를 로드하고, 페이지 테이블을 최신화한다.
5. 중단되었던 CPU를 다시 시작한다.
- 페이지(page) : 가상 메모리를 사용하는 최소 크기 단위
- 프레임(frame) : 실제 메모리를 사용하는 최소 크기 단위
2-2. 스레싱
스레싱(thrashing)은 메모리의 페이지 폴트율이 높은 것을 의미한다. 스레싱은 컴퓨터의 심각한 성능 저하를 초래한다.
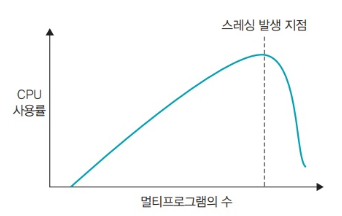
메모리에 너무 많은 프로세스가 동시에 올라간다 ->
스와핑이 많이 일어난다 ->
스레싱이 발생한다 ->
CPU 사용율이 낮아진다 ->
운영체제는 "CPU가 한가한가봐? 더 많은 프로세스 메모리에 올려!!"악순환의 반복...
작업 세트
작업 세트(working set)는 프로세스의 과거 사용 이력인 지역성을 통해 결정된 페이지 집합을 만들어서 미리 메모리에 로드하는 것이다.
미리 메모리에 로드하면 탐색에 드는 비용을 줄일 수 있고 스와핑 또한 줄일 수 있다.
PFF
PFF(Page Fault Frequency)는 페이지 폴트 빈도를 조절하는 방법으로 상한선과 하한선을 만드는 방법이다.
만약 상한선에 도달하면 프레임을 늘리고 하한선에 도달하면 프레임을 줄이는 것이다.

정보 감사합니다.