[1] 데이터베이스 구축
1. 데이터베이스 개념
데이터베이스의 정의
공장통운
- 공유 데이터 (Shared Data)
여러 응용 프로그램들이 공동으로 사용하는 데이터 - 저장 데이터 (Stored Data)
컴퓨터가 접근 가능한 저장 매체에 저장된 데이터 - 통합 데이터 (Integrated Data)
검색의 효율성을 위해 중복이 최소화된 데이터의 모임 - 운영 데이터 (Operational Data)
조직의 목적을 위해 존재 가치가 확실하고 반드시 필요한 데이터
데이터 언어
상암 DMC
정조제
- DDL (Definition : 정의어)
- DB의 구축과 변경 목적으로 사용
- 데이터에 대한 형식, 구조, 제약조건들 명시
- DML (Manipulation : 조작어)
검색, 삽입, 삭제, 갱신 연산을 포함한 집합 - DCL (Control : 제어어)
- 데이터 무결성 (Integrity)
- 보안(Security), 권한(Authority) 검사
- 병행 제어 (Concurrency Control)
스키마 (Schema)
데이터 사전(Data Dictionary)에 저장
3계층 스키마
- 외부 스키마 (External Schema)
- 사용자 뷰
- DB의 논리적 구조 정의
- 개념 스키마 (Conceptual Schema)
DB의 전체적인 논리적 구조 - 내부 스키마 (Internal Schema)
물리적 저장장치 입장에서 본 DB구조
데이터 독립성
- 논리적 독립성
개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원 - 물리적 독립성
내부 스키마가 변경되어도 외부/개념 스키마가 영향을 받지 않도록 지원
외부스키마1 외부스키마2 ...
| <-- 논리적 독립성
개념스키마
| <-- 물리적 독립성
내부스키마DBMS : 데이터베이스 관리 시스템
(1) 기능
- 데이터 정의
- 데이터 조작
- 데이터 제어
- 데이터 공유
- 데이터 보호
- 데이터 구축
- 유지보수
(2) 종류
- 계층형 (Hierarchical)
트리형태 구조 - 네트워크형 (Network)
- 망형 구조 (N:N)
- CODASYL 제안
- 관계형 (Relational)
키와 값으로 이루어진 데이터들을 행과 열로 구성된 테이블 구조로 단순화 - 객체 지향형 (Object-Oriented)
비정형 데이터들을 데이터베이스화 할 수 있도록 하는 목적 - 객체 관계형 (Object-Relational)
관계형 데이터베이스에 객체 지향 개념 도입 - NoSQL
Not Only SQL : SQL뿐만 아니라 다양한 특성을 지원한다 - NewSQL
RDBMS의 SQL과 NoSQL의 장점을 결합한 관계형 모델
2. 데이터베이스 설계 단계
데이터베이스 설계 단계
개논물
- 요구조건 분석
- 개념적 설계
- 현실세계를 데이터 관점으로 추상화하는 단계
- E-R 다이어그램 : 개념적 스키마 구성
- 논리적 설계
- 자료를 컴퓨터가 이해할 수 있도록 목표 DBMS의 논리적 구조로 변환하는 과정
- 정규화
- 트랜잭션 인터페이스 설계
- 물리적 설계
- 물리적 스키마 생성, 트랜잭션 세부 설계
- 반정규화
- 구현
3. 데이터 모델링
(1) 개념
현실세계의 요소를 인간과 컴퓨터가 이해할 수 있는 정보로 표현한 것
(2) 종류
- 계층형 데이터 모델
- 네트워크 (망)형 데이터 모델
- 관계형 데이터 모델
- 객체 지향형 데이터 모델
(3) 구분
- 개념적 데이터 모델
개체-관계 (E-R 모델) - 논리적 데이터 모델
- 개념구조를 컴퓨터가 이해할 수 있도록 변환한 구조
- 목표 DBMS
- 물리적 모델
- 데이터가 저장되는 방법 표현
- 특정 DBMS
(4) 구조
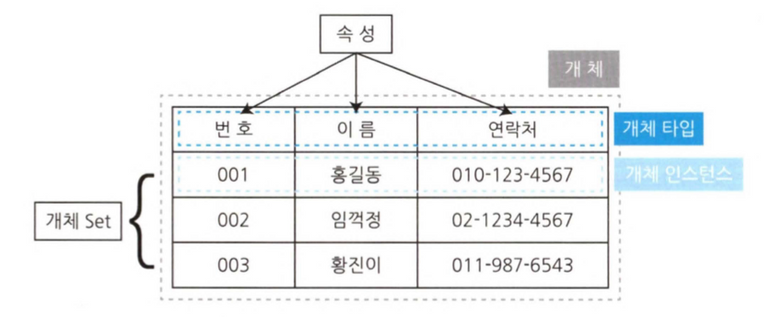
- 개체 (Entity)
- 개체 타입 (Entity Type)
- 개체 인스턴스 (Entity instance)
- 개체 세트 (Entity Set)
- 속성 (Attribute)
- 관계 (Relation)
(5) 데이터모델 표시해야할 요소
구연제
- 구조 (Structure)
- 연산 (Operation)
- 제약조건 (Constraint)
개체-관계 모델 (Entity Relation Modal)
데이터베이스에 대한 요구사항을 그래픽적으로 표현하는 방법
(1) E-R 다이어그램 기호
| 기호 (생략) | 기호 이름 | 설명 |
|---|---|---|
| 사각형 | 개체 (Entity) | |
| 마름모 | 관계 (Relationship) | |
| 타원 | 속성 (Attribute) | |
| 밑줄 타원 | 기본키 속성 | |
| 이중 타원 | 복합 속성, 다중값 | |
| 선 링크 | 개체와 속성 연결 |
(2) 개체 간 대응 관계 표현
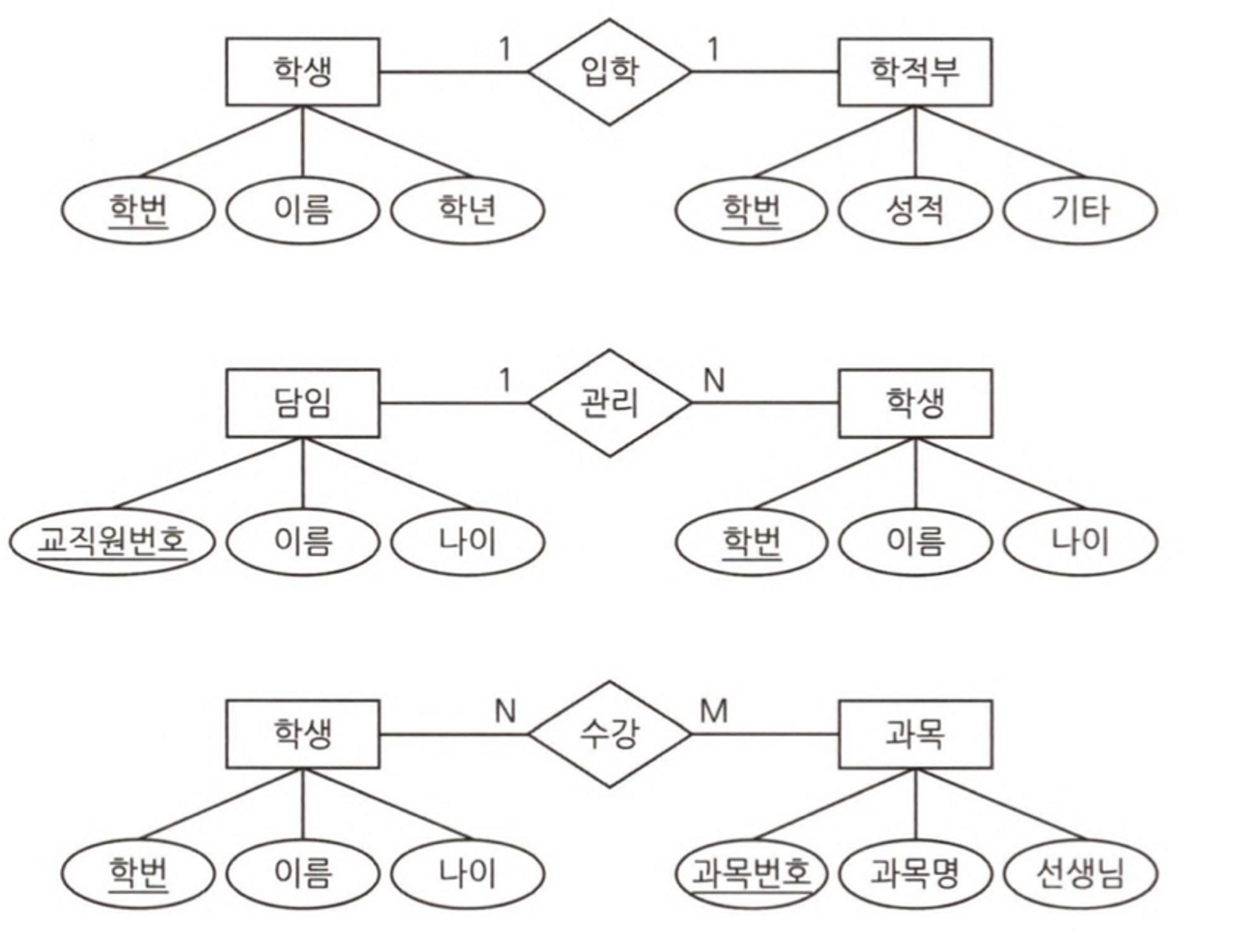
(3) 세발 표기법
| 종류 (기호생략) | 설명 |
|---|---|
| 1:1 관계 | |
| 1:N 관계 | |
| N:M 관계 | |
| 관계가 있을 수도 없을 수도 있음 |
데이터 모델의 품질 기준
정완준최일활 : 정완이가 준 강아지가 제일 활발해!
- 정확성 : 정확하게 표현, 요구사항 정확 반영
- 완전성 : 정의할 때 누락 최소화, 반영에 누락 없음
- 준거성 : 제반 준수 요건들이 누락 없이 정확히 준수
- 최신성 : 최신 상태 반영, 이슈사항들 지체 없이 반영
- 일관성 : 여러 곳에서 참조, 활용 일관성 유지
- 활용성 : 유연하게 설계
4. 논리 데이터베이스 설계
정규화
(1) 목적
- 데이터의 중복을 최소화
- 정보의 무손실 : 정보가 사라지지 않아야 함
- 독립적인 관계는 별개의 릴레이션으로 표현
- 정보의 검색을 보다 용이하게 함
- 이상 현상 최소화
(2) 장/단점
장점
- 데이터중복의 최소화
- 저장 공간의 효율적 사용
- 이상현상 제거
단점
- 처리 명령의 복잡
- 실행 속도 저하
- 분리된 릴레이션 간 참조 무결성 유지를 위한 노력 필요
- 분리된 여러 개의 테이블에서 정보를 취합하기 위해 JOIN 연산 필요
이상현상 (Anomaly)
데이터 중복으로 인해 예상하지 못한 곤란한 현상이 발생하는 것
삽삭갱
- 삽입 이상
데이터를 삽입할 때 불필요한 데이터가 함께 삽입되는 현상 - 삭제 이상
한 튜플을 삭제할 때 연쇄 삭제 현상으로 인해 정보 손실 - 갱신 이상
튜플의 속성값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 모순이 생기는 현상
함수적 종속 (Functional Dependency)
X → Y : X를 알면 Y를 알 수 있다.
- 완전 함수적 종속 (Full Functional Dependency)
- 부분 함수적 종속 (Full Functional Dependency)
- 이행적 함수 종속 (Transitive Functional Dependency)
정규화 과정
도부이결다조
비정규 릴레이션
| 도메인이 원자값
1NF
| 부분 함수적 종속 제거
3NF
| 결정자이면서 후보키가 아닌 것 제거
BCNF
| 다치 종속 제거
4NF
| 조인 종속 이용
5NF5. 물리 데이터베이스 설계
물리 데이터베이스 설계 시 고려사항
- 무결성
- 일관성
- 회복성
- 효율성
- 확장성
반정규화
시스템의 성능향상을 위해 정규화에 위배되는 중복을 허용하는 기법
데이터베이스 이중화
-
장애발생 시 데이터베이스를 보호하기 위한 방법
-
동일한 데이터베이스를 중복시켜 동시에 갱신하여 관리하는 방법
(1) 목적
고가용성을 위해서!
(2) 분류
- Eager 기법
트랜잭션 수행 중에 발생한 변경은 발생 즉시 모든 이중화서버로 전달하여 변경 내용 반영 - Lazy 기법
트랜잭션의 수행이 완전히 완료된 후에 변경 사실에 대한 새로운 트랜잭션을 작성하여 각 노드에게 전달
(3) 종류
- Active-Active
다중화된 장비가 모두 가동되는 방식 - Active-Standby
두 대 중 하나는 가동이 되고, 하나는 장애 상황의 경우를 대비해서 준비 상태로 대기
[타입]
Hot Standby: 장비가 가동되었을 때 즉시 사용가능
Warm Standby: 장비가 가동되었을 때 설정에 대한 준비가 필요함
Cold Standby: 장비를 평소에는 정지시켜두며 필요에 따라서 직접 켜서 구성을 함
데이터베이스 백업
(1) 백업방식
- 전체 백업 (Full Backup)
선택된 폴더의 데이터를 모두 백업하는 방식 - 증분 백업 (Incremental Backup)
Full 백업 이후 변경/추가된 데이터만 백업하는 방식 - 차등 백업 (Differential Backup)
Full 백업 이후 변경/추가된 데이터를 모두 포함하여 백업 - 실시간 백업 (RealTime Backup)
즉각적으로 모든 변경사항을 분리된 스토리지 디바이스에 복사 - 트랜잭션 로그 백업 (Transaction Log Backup)
- 데이터베이스에서 실행되는 모든 SQL문을 기록한 로그
- REDO(다시 실행), UNDO(원상태로 복구)로 복원
- 합성 백업
기존의 전체 백업본과 여러 개의 증분 백업을 합하여 새로운 전체 백업을 만드는 작업
(2) 복구 시간 목표/복구 시점 목표
- 복구 시간 목표 (RTO)
- 서비스 중단 시점과 서비스 복원 시점 간에 허용되는 최대 지연 시간
- 서비스를 사용할 수 없는 상태로 허용되는 기간
- 복구 시점 목표 (RPO)
- 마지막 데이터 복구 시점 이후 허용되는 최대 시간
- 마지막 복구 시점과 서비스 중단 시점 사이에 허용되는 데이터 손실량
데이터베이스 암호화 방식
- API 방식
애플리케이션에서 데이터의 암/복호화 수행 - Plug-in 방식
데이터베이스 서버에 제품을 설치하고 암복호화 수행 - TDE (Transparent Data Encryption) 방식
DBMS에 내장 또는 옵션으로 제공되는 암호화 기능을 이용
6. 데이터베이스 물리속성 설계
파티셔닝
데이터베이스를 여러 부분으로 분할하는 것
(1) 샤딩 (Sharding)
하나의 거대한 데이터베이스나 네트워크 시스템을 여러 개의 작은 조각으로 나누어 분산 저장하여 관리하는 것
(2) 장점
- 가용성
- 관리용이성
(3) 분할 기준
- 범위 분할 (Range Partitioning)
ex) 월별, 분기별 등```sql CREATE TABLE TB_USER( id INT, year INT ) PARTITION BY RANGE (year) ( PARTITIONU1 VALUES LESSTHAN (2000) ); ``` - 목록 분할 (List Partitioning)
ex) [한국, 일본, 중국 → 아시아]```sql CREATE TABLE TB_USER( id INT, year INT ) PARTITION BY LIST (year) ( PARTITIONU1 VALUES LESSTHAN (2000) ); ``` - 해시 분할 (Hash Partitioning)
- 라운드 로빈 분할 (Round Robin Partitioning)
- 합성 분할 (Composite Partitioning)
클러스터 설계
- 디스크로 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법
- 데이터 조회 성능을 향상 시키지만 데이터 저장, 수정, 삭제, Full Scan 시 성능이 저하된다.
인덱스 (INDEX)
추가적인 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
(1) 종류
- 클러스터 인덱스
- 테이블당 1개만 허용
- 해당 컬럼을 기준으로 테이블이 물리적으로 정렬
- 넌클러스터 인덱스
- 테이블당 약 240개의 인덱스 생성 가능
- 레코드의 원본은 정렬되지 않고, 인덱스 페이지만 따로 만들기 때문에 용량을 더 차지함
- 밀집 인덱스
데이터 레코드 각각에 대해 하나의 인덱스가 만들어짐 - 희소 인덱스
레코드 그룹 또는 데이터 블록에 대해 하나의 인덱스가 만들어짐
뷰 (View)
실제로 데이터를 저장하지 않고 논리적으로만 존재하는 가상 테이블
데이터의 논리적 독립성을 제공 (외부스키마가 뷰와 연관있음)
시스템 카탈로그 (데이터 사전 : Data Dictionary)
데이터베이스에 저장되어 있는 모든 데이터 개체들에 대한 정보가 수록되어 있는 시스템
(1) 내용
- 릴레이션
- 인덱스
- 뷰
- 통계
- 사용자
(2) 특징
- SQL문을 이용하여 내용 검색 가능 → 수정(ALTER)불가 검색만 가능!
- 데이터베이스 관리 시스템에 의해 생성되고 유지됨
7. 관계 데이터베이스 모델
관계 데이터 릴레이션의 구조
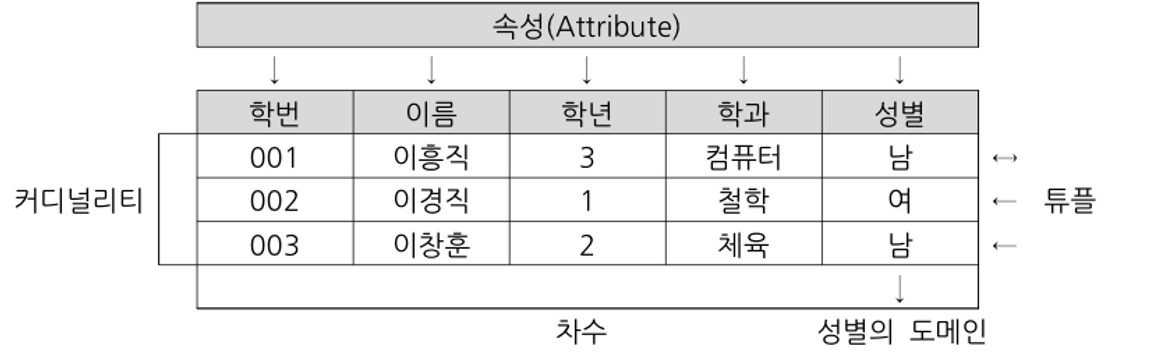
- 속성 (Attribute)
아차- 열
- 속성의 수 = 차수(Degree)
- 튜플 (Tuple)
- 행
- 튜플의 수 = 카디널리티(Cardinality)
- 도메인 (Domain)
하나의 속성이 가질 수 있는 값의 범위
8. 관계데이터 언어 (관계대수, 관계 해석)
관계대수
절차적 : 원하는 데이터를 찾기 위한 처리과정을 명시
(1) 순수 관계 연산자
- SELECT : 선택
σ (시그마)σ<조건>(테이블) σ 성적=90 (학생) - PROJECT : 추출
π (파이)π <리스트>(테이블) π 학번,이름,성적 (σ 성적=90 (학생)) - JOIN : 연관된 튜플 결합
⋈ (보타이)R⋈<조건>S (학생)⋈학번=학번(수강과목) - DIVISION : 관련있는 튜플 반환
÷ (나누기)
(2) 일반 집합 연산자
- 합집합 (Union) : ∪
(중복허용X) - 교집합 (Intersection) : ∩
- 차집합 (Difference) : -
- 교차곱 (Cartesian Product) : X
관계 해석
비절차적 : 원하는 정보가 무엇이라는 것만 정의
- 연산자
- V
OR 연산 - Λ
AND 연산 - ᄀ
NOT 연산
- V
- 정량자
- ∀
모든 가능한 튜플 “For All” - ∃
어떤 튜플 하나라도 존재
- ∀
9. 키와 무결성 제약조건
구성방식에 따른 키 분류
- PK (Primary Key) 속성
릴레이션에서 튜플을 유일하게 구분할 수 있는 속성 - FK (Foreign Key) 속성
다른 릴레이션과의 관계에서 참조하고 있는 속성 - 일반 속성
릴레이션에 포함된 속성 중, PK와 FK가 아닌 속성
키 종류
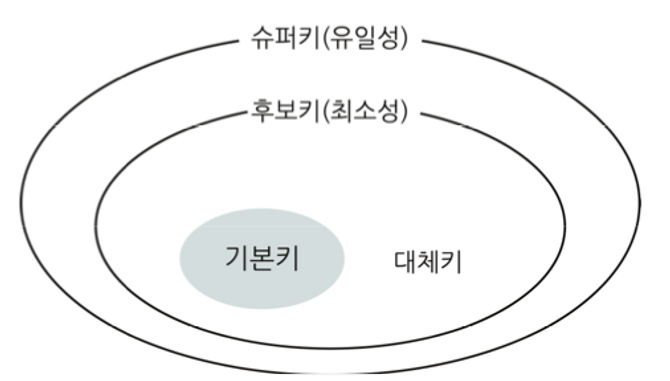
- 후보키 (Candidate Key)
- 튜플을 유일하게 식별할 수 있는 속성들의 부분집합
- 유일성 + 최소성 만족
- 기본키 (Primary Key)
- 후보키 중에서 선택한 주키 (Main Key)
- ex) 주민번호
- 대체키 (Alternate Key)
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
- 슈퍼키 (Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키, 모든 가능한 조합들!
- 유일성만 만족
- 외래키 (Foreign Key) 관계를 맺고 있는 릴레이션 R1, R2에서 릴레이션 R1이 참조하고 있는 릴레이션 R2의 기본키와
같은 R1 릴레이션의 속성
데이터베이스 무결성
데이터의 정확성, 일관성, 유효성이 유지되는 것
(1) 종류
- 개체 무결성 (Entity Integrity)
- 모든 릴레이션은 기본키(PK)를 가져야 한다.
- 기본키는 중복되지 않은 고유한 값
- 기본키는 NULL 값 허용하지 않음
- ex) 주민번호
- 참조 무결성 (Referential Integrity)
- 외래키 값은 NULL이거나 참조하는 릴레이션의 기본키 값과 동일해야 한다.
- 각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다.
- ex) 쇼핑몰
- 참조 무결성 제약조건
제한 (Restrict): 문제가 되는 연산을 거절연쇄 (Cascade): 부모 튜플 삭제하면 자식 튜플도 함께 삭제널값 (Nullify): 부모 튜플 삭제하면 자식 릴레이션에서 참조하는 튜플들의 외래키에 NULL 등록기본값 (Default): Null을 넣는 대신에 디폴트 값을 등록
- 도메인 무결성 (Domain Integrity)
- 고유 무결성 (Unique Integrity)
- 키 무결성 (Key Integrity)
- 릴레이션 무결성 (Relation Integrity)
10. 물리데이터 모델 품질 검토
CRUD 분석
Create, Read, Update, Delete를 묶어서 표현한 말
옵티마이저
사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할을 수행
(1) SQL 처리 흐름 중 옵티마이저 단계
- 구문분석 (Parsing)
- 실행 (Execution)
- 인출 (Fetch) : SELECT문을 실행하는 경우에만 추출(인출)단계 실행됨
(2) 구분
- 규칙기반 옵티마이저 (Rule Based Optimizer)
규칙(우선순위)를 가지고 실행 계획을 생성 - 비용기반 옵티마이저 (Cost Based Optimizer)
통계정보와 시스템 통계정보를 활용하여 가장 적은 비용이 드는 실행 계획을 선택함
SQL 성능 튜닝
SQL을 최적화하여 빠른 시간 내에 원하는 결과값을 얻기 위한 작업
11. 분산 데이터베이스
분산 데이터 베이스
(1) 구성요소
- 분산 처리기
- 분산 데이터베이스
- 통신 네트워크
(2) 분산 데이터베이스의 적용 기법 中
- 테이블 요약 (Summarization) 분산
- 분석요약 (Rollup Replication)
같은구조: 각각 존재하는 요약정보를 마스터에 통합하여 다시 전체에 대해서 요약정보를 산출 - 통합요약 (Consolidation Replication)
다른구조: 각각 존재하는 다른 내용의 정보를 마스터에 통합하여 다시 전체에 대해서 요약정보를 산출
- 분석요약 (Rollup Replication)
(3) 투명성 조건
어디에 뭐가 저장되어있는지 난 몰라도 된다~
- 위치 투명성 (Location)
엑세스 하려는 데이터베이스의 실제 위치를 알 필요 없음 - 분할 투명성 (Division)
하나의 논리적 테이블이 여러 단편으로 분할되어 각 단편의 사본이 여러 위치에 저장됨 - 지역사상 투명성 (Local Mapping)
지역 DBSM와 물리적 DM 사이에 Mapping 보장 - 중복 투명성 (Replication)
동일 데이터가 여러곳에 중복되어 있더라도 사용자는 하나의 데이터만 존재하는 것처럼 사용함 - 병행 투명성 (Concurrency)
다수의 트랜잭션이 동시에 실현되더라도 그 트랜잭션의 결과는 영향 받지 않음 - 장애 투명성 (Failure)
장애에도 불구하고 트랜잭션을 정확히 처리함
(4) CAP 이론
어떤 분산 환경에서도 C, A, P 세 가지 속성 중 2가지만 가질 수 있다는 것
- 일관성 (Consistency)
같은 시간에 동일한 항복에 대하여 같은 내용의 데이터를 사용자에게 보여준다. - 가용성 (Availability)
모든 사용자들이 읽기 및 쓰기가 가능해야 하며, 장애 시에도 다른 노드에 영향을 미치면 안된다. - 분단 허용성 (Partition Tolerance)
메세지 전달 실패, 시스템 일부 망가져도 시스템이 계속 동작할 수 있어야 한다.
트랜잭션
데이터베이스의 상태를 변환시키는 하나의 논리적인 기능을 수행하는 작업 단위
(1) 특성
ACID
- 원자성 (Atomicity)
하나라도 실패할 경우 전체가 취소되어야하는 특성 - 일관성 (Consistency)
트랜잭션이 실행 성공 후 항상 일관된 데이터베이스 상태를 보존해야하는 특성 - 독립성, 격리성 (Isolation)
트랜잭션 실행 중 생성하는 연산의 중간 결과를 다른 트랜잭션이 접근 불가한 특성 - 지속성, 영속성 (Durability)
성공이 완료된 트랜잭션의 결과는 영속적으로 데이터베이스에 저장하는 특성
(2) 상태
- 활동 (Active)
트랜잭션이 실행 중인 상태 - 실패 (Failed)
트랜잭션 실행에 오류가 발생하여 중단된 상태 - 철회 (Aborted)
트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태 - 부분완료 (Partially Committed)
트랜잭션의 마지막 연산까지 실행했지만, Commit 연산이 실행되기 직전의 상태 - 완료 (Committed)
트랜잭션이 성공적으로 종료되어 Commit 연산을 실행한 후의 상태
[2] SQL 활용
1. SQL
- DDL : 데이터 정의어
- CREATE
- ALTER
- DROP
- RENAME
- TRUNCATE
- DML : 데이터 조작어
- SELECT
- INSERT
- UPDATE
- DELETE
- DCL : 데이터 제어어
- GRANT
- REVOKE
- TCL : 트랜잭션 제어어
- COMMIT
트랜잭션을 메모리에 영구적으로 저장하는 명령어 - ROLLBACK : 트랜잭션 취소
오류발생시 특정 시점 이전으로 되돌려주는 제어어 - SAVEPOINT (CHECKPOINT) : 저장 시기 설정
ROLLBACK을 위한 시점을 지정하는 명령어
- COMMIT
2. DDL (데이터 정의어)
데이터를 담는 그릇을 정의하는 언어
DDL 명령어
- CREATE : 생성
- ALTER : 변경
- DROP : 삭제 (테이블 전체를 삭제)
- TRUNCATE : 삭제 (테이블은 삭제하지 않고 데이터만 삭제)
DDL 대상
- 도메인 (Domain)
하나의 속성이 가질 수 있는 원자값들의 집합 - 스키마 (Schema)
데이터베이스의 구조, 제약조건 등의 정보를 담고 있는 기본적인 구조
- 외부스키마 (= 서브 스키마)
사용자나 개발자의 관점에서 필요로 하는 데이터베이스의 논리적 구조
- 개념 스키마
데이터베이스의 전체적인 논리적 구조
- 내부 스키마
물리적 저장장치의 관점에서 보는 데이터베이스 구조 - 테이블 (Table)
- 데이터 저장 공간
- 릴레이션(Relation) 혹은 엔티티(Entity)라고도 불린다.
- 뷰 (View)
하나 이상의 물리 테이블에서 유도되는 가상의 테이블 - 인덱스 (Index)
검색을 빠르게 하기 위한 데이터 구조
TABLE 관련 DDL
CREATE TABLE
제약조건
- PRIMARY KEY
기본 키를 정의, 유일하게 테이블의 각 행을 식별 - FOREIGN KEY
외래 키를 정의 - UNIQUE
테이블 내에서 얻은 유일한 값을 갖도록 하는 제약조건 - NOT NULL
NULL 값을 포함하지 않도록 하는 제약 조건 - CHECK
참이어야 하는 조건을 지정 - DEFAULT
데이터를 삽입할 때 해당 칼럽의 값을 넣지 않는 경우 기본값으로 설정해 주는 제약조건
-- 생성 문법
CREATE TABLE 테이블명 (컬럼명 데이터타입 [제약조건], ...);
-- 상세문법
CREATE TABLE 테이블명
(
컬럼명 데이터타입 PRIMARY KEY,
컬럼명 데이터타입 FOREIGN KEY REFERENCES 참조테이블(기본키),
컬럼명 데이터타입 UNIQUE,
컬럼명 데이터타입 NOT NULL,
컬럼명 데이터타입 CHECK(조건식),
컬럼명 데이터타입 DEFAULT 값
);
-- 예시
CREATE TABLE 사원
(
사번 VARCHAR(10) PRIMARY KEY,
업무 VARCHAR(20) FOREIGN KEY REFERENCES 부서(부서코드),
이름 VARCHAR(10) UNIQUE,
생년월일 CHAR(8) NOT NULL,
성별 CHAR(1) CHECK (성별 = 'M' OR 성별 = 'F'),
입사일 DATE DEFAULT SYSDATE
);ALTER TABLE
- ADD : 추가
- MODIFY : 수정
- DROP : 컬럼 삭제
-- 추가 문법
ALTER TABLE 테이블명 ADD 컬럼명 데이터타입 [제약조건];
ALTER TABLE 사원 ADD 전화번호 VARCHAR(11) UNIQUE;
-- 수정 문법
ALTER TABLE 테이블명 MODIFY 컬럼명 데이터타입 [제약조건];
ALTER TABLE 사원 MODIFY 이름 VARCHAR(30) NOT NULL;
-- 삭제 문법
ALTER TABLE 테이블명 DROP 컬럼명;DROP TABLE
명령어 옵션
- CASCADE
참조하는 테이블까지 연쇄적으로 제거하는 옵션 - RESTRICT
다른 테이블이 삭제할 테이블을 참조 중이면 제거하지 않는 옵션
-- 삭제 문법
DROP TABLE 테이블명 [CASCADE | RESTRICT];
DROP TABLE 사원;VIEW 관련 DDL
VIEW는 ALTER(수정)이 없다!
CREATE VIEW
-- 생성 문법
CREATE VIEW 뷰이름 **AS**
조회쿼리;
-- 예시
CREATE VIEW 사원뷰 **AS**
SELECT 사번, 이름
FROM 사원
WHERE 성별 = 'M';
-- 주의) VIEW 테이블의 SELECT 문에는 UNION이나 ORDER BY 절을 사용할 수 없다.
-- 뷰를 교체하는 명령
CREATE OR REPLACE VIEW 뷰이름 AS
조회쿼리;DROP VIEW
-- 삭제 문법
DROP VIEW 뷰이름;INDEX 관련 DDL
CREATE INDEX
-- 생성 문법
CREATE [UNIQUE] INDEX 인덱스명 ON 테이블명(컬럼명1, 컬럼명2, ...);
-- 예시
CREATE INDEX 사번인덱스 ON 사원(사번);ALTER INDEX
-- 수정 문법
ALTER [UNIQUE] INDEX 인덱스명 ON 테이블명(컬럼명1, 컬럼명2, ...);
-- 예시
ALTER INDEX 사번인덱스 ON 사원(사번);DROP INDEX
-- 삭제 문법
DROP INDEX 인덱스명;3. DML (데이터 조작어)
데이터베이스에 저장된 자료들을 입력, 수정, 삭제, 조회(CRUD)하는 언어이다.
DML 명령어
- SELECT : 조회
- INSERT : 삽입
- UPDATE : 갱신
- DELETE : 튜플 삭제 (데이터만 지우고 테이블은 그대로, 삭제 후 되돌리기 가능)
SELECT 명령어
-- 기본 문법
SELECT [ALL | DISTINCT] 속성명1, 속성명2...
FROM 테이블명1, ...
[WHERE 조건]
[GROUP BY 속성명1, ...]
[HAVING 그룹조건]
[ORDER BY 속성 [ASC | DESC] ]SELECT 절
- ALL (기본값) : 모든 튜플 검색
- DISTINCT : 중복된 튜플 중 첫 번째 한개만 검색
SELECT 과목 FROM 성적;
SELECT DISTINCT 과목 FROM 성적;
SELECT 과목 FROM 성적 WHERE 학점 = 'A';
-- 성적 테이블에서 과목 중에 중복된 값을 제거한 튜플의 갯수를 출력
SELECT COUNT(DISTINCT 과목) FROM 성적;
-- 성적 테이블에서 과목 튜플의 갯수를 출력
SELECT COUNT(과목) FROM 성적;
SELECT 학번, COUNT(과목), SUM(총점) FROM 성적;
-- 성적 테이블에서 과목, 학점 두 칼럼이 모두 같은 값이면 제거
SELECT 과목, 학점 FROM 성적;WHERE 절
- 연산자
-
= : 값이 같은 경우 조회
-
<>, != 값이 다른 경우 조회
-
<, <=, >, >= 비교 연산에 해당하는 데이터 조회
WHERE 학점 = 'A'; WHERE 학점 != 'A';
-
- 범위 : BETWEEN
-
BETWEEN AND
-- 값1보다 크거나 같고, 값2보다 작거나 같은 데이터를 조회 WHERE 칼럼 BETWEEN 값1 AND 값2; WHERE 학점 BETWEEN 'A' AND 'B'; WHERE PRICE BETWEEN 1000 AND 2000;
-
- 집합
-
IN
-
NOT IN
-- 학점이 A또는 B또는 C인 튜플을 조회 WHERE 컬럼 IN (값1, 값2, ...); WHERE 학점 IN ('A', 'B', 'C'); -- 가격이 1000 또는 2000이 아닌 튜플을 조회 WHERE 컬럼 NOT IN (값1, 값2, ...); WHERE 가격 NOT IN (1000, 2000);
-
- 패턴 : LIKE
-
% : 0개 이상의 문자열과 일치
-
: 1개의 문자와 일치
-
[^] : 1개의 문자와 불일치
-
_ : 특정 위치의 1개의 문자와 일치
-- %는 글자수가 정해져 있지 않음 WHERE 이름 LIKE '마%'; -- '이'로 시작하는 사람 검색 WHERE 이름 LIKE '%크'; -- '크'로 끝나는 사람 검색 WHERE 이름 LIKE '%이%'; -- '이'가 들어가는 사람 검색 -- 대괄호 안의 글자를 한개씩 끊어서 보고 '또는'의 의미로 생각함 WHERE 이름 LIKE '[이마]%'; -- 첫번째 문자가 '이' 또는 '마' 인 문자열과 일치하는 문자열 검색 -- 언더바는 글자 수 정해져있음 WHERE 이름 LIKE '이_'; -- '이'로 시작되고 '이' 뒤에 1글자만 있는 사람 검색 WHERE 이름 LIKE '이__'; -- '이'로 시작되고 '이' 뒤어 2글자만 있는 사람 검색 WHERE 이름 LIKE '이_크'; -- '이*크'이라는 사람 검색
-
- NULL
-
IS NULL : 컬럼이 NULL인 데이터 조회
-
IS NOT NULL : 칼럼이 NULL이 아닌 데이터 조회
-- 가격이 NULL인 튜플 조회 WHERE PRICE IS NULL; -- 가격이 NULL이 아닌 튜플 조회 WHERE PRICE IS NOT NULL;
-
- 복합조건
-
AND
-
OR
-
NOT, !
SELECT 이름 FROM 고객 WHERE 나이 BETWEEN 50 AND 59 OR 성별 = '남';
-
GROUP BY 절
속성값을 그룹으로 분류하고자 할 때 사용
-- 직책을 기준으로 그룹을 묶었을 때,
SELECT 직책, COUNT(직책), SUM(급여)
FROM 급여
GROUP BY 직책;
-- 직책과 부서 기준으로 그룹을 묶었을 때,
SELECT 직책, 부서, SUM(급여) AS 급여합계
FROM 급여
GROUP BY 직책, 부서;HAVING 절
GROUP BY에 의해 분류한 후 그룹에 대한 조건을 지정할 때 사용
SELECT 직책, 부서, SUM(급여) AS 급여합계
FROM 급여
GROUP BY 직책, 부서
HAVING 급여합계 >= 5000;ORDER BY 절
- ASC (기본값) : 오름차순
- DESC : 내림차순
-- 이름에 대해 오름차순으로 정렬, 문자열은 가나다순으로 정렬
SELECT *
FROM 성적
ORDER BY 이름;
-- 먼저 선언된 속성으로 정렬 후, 같은 값일 때 다음 속성으로 정렬
SELECT *
FROM 성적
ORDER BY 과목, 이름;
-- 학점은 내림차순으로 정렬한 후 값은 값일 때 이름을 오름차순으로 정렬
SELECT *
FROM 성적
ORDER BY 학점 DESC, 이름 ASC;조인 (Join)
두 개 이상의 테이블을 연결하여 데이터를 검색하는 방법
[도서]
[도서가격]
| 책번호 | 책명 |
|---|---|
| 111 | 운영체제 |
| 222 | 자료구조 |
| 555 | 컴퓨터구조 |
| 책번호 | 가격 |
|---|---|
| 111 | 20,000 |
| 222 | 25,000 |
| 555 | 10,000 |
| 444 | 15,000 |
내부 조인
SELECT A.컬럼1, A.컬럼2, B.컬럼1, B.컬럼2, ...
FROM 테이블1 A **[INNER] JOIN** 테이블2 B
ON 조인조건
[WHERE 검색조건];
-- '도서' 테이블은 A라는 별칭으로,
-- '도서가격' 테이블은 B라는 명칭으로 설정 후 책번호가 같은 것끼리 조인
SELECT A.책번호, A.책명, B.가격
FROM 도서 A JOIN 도서가격 B
ON A.책번호 = B.책번호;외부조인
- 왼쪽 외부 조인
왼쪽 테이블은 모두 가져온다.```sql SELECT A.컬럼1, A.컬럼2, B.컬럼1, B.컬럼2, ... FROM 테이블1 A **LEFT [OUTER] JOIN** 테이블2 B ON 조인조건 [WHERE 검색조건]; -- '도서' 테이블은 A라는 별칭으로, '도서가격' 테이블은 B라는 명칭으로 설정 후 -- 왼쪽에 위치한 '도서' 테이블 기준으로 왼쪽 외부 조인 SELECT A.책번호, A.책명, B.책번호, B.가격 FROM 도서 A LEFT JOIN 도서가격 B ON A.책번호 = B.책번호; ``` - 오른쪽 외부 조인
오른쪽 테이블은 모두 가져온다.```sql SELECT A.컬럼1, A.컬럼2, B.컬럼1, B.컬럼2, ... FROM 테이블1 A **RIGHT [OUTER] JOIN** 테이블2 B ON 조인조건 [WHERE 검색조건]; ``` - 완전 외부 조인
양쪽 테이블 모두 가져온다.```sql SELECT A.컬럼1, A.컬럼2, B.컬럼1, B.컬럼2, ... FROM 테이블1 A **FULL [OUTER] JOIN** 테이블2 B ON 조인조건 [WHERE 검색조건]; ```
교차 조인
경우의 수 모두 가져온다. (왼쪽 데이터 n개 X 오른쪽 데이터 m개 = nm개)
SELECT A.컬럼1, A.컬럼2, B.컬럼1, B.컬럼2, ...
FROM 테이블1 **CROSS JOIN** 테이블2셀프 조인
SELECT A.컬럼1, A.컬럼2, B.컬럼1, B.컬럼2, ...
FROM 테이블1 A **[INNER] JOIN** 테이블1 B
ON 조인조건
[WHERE 검색조건];서브쿼리 (Sub-Query)
-- 예시1
SELECT (SELECT MAX(가격)
FROM 도서 A
WHERE A.책번호 = B.책번호
AND 책명='자료구조')
FROM 도서가격 B;
-- 예시2
SELECT MAX(가격)
FROM 도서가격 A,
(SELECT 책번호
FROM 도서
WHERE 책명='자료구조') B
WHERE A.책번호 = B.책번호
-- 예시3
SELECT MAX(가격)
FROM 도서가격
WHERE 책번호 IN (SELECT 책번호
FROM 도서
WHERE 책명='자료구조');집합 연산자 (Set Operator)
- UNION
중복된 제거 합집합 - UNION ALL
중복 포함 합집합 - INTERSECT
교집합 - MINUS
(첫 번째 쿼리 결과) - (두 번째 쿼리 결과) = 차집합
SELECT 칼럼명
FROM 테이블명
WHERE 검색조건
**UNION -- 위치 기억**
SELECT 칼럼명
FROM 테이블명
WHERE 검색조건INSERT(데이터 삽입) 명령어
속성과 데이터 개수, 데이터 타입이 일치해야 함
속성명은 생략 가능
**INSERT INTO** 테이블명(속성명1, ...)
**VALUES** (데이터1, ...);
-- 예) [학생]테이블에 학번이 6677, 성명 '장길산' 학년이 3학년, 수강과목은 '수학'인 학생을 삽입
INSERT INTO 학생(학번, 성명, 학년, 수강과목)
VALUES (6677, '장길산', 3, '수학');UPDATE(데이터 변경) 명령어
WHERE 절의 조건이 만족할 경우에만 특정 컬럼 값을 수정하는 용도
UPDATE 테이블명
SET 속성명 = 데이터, ...
WHERE 조건;
-- 예) [학생]테이블에 장길산의 주소를 인천으로 수정
UPDATE 학생
SET 주소 = '인천';
WHERE 이름 = '장길산';DELETE(데이터 삭제) 명령어
**DELETE FROM** 테이블명
WHERE 조건;
-- 예) [학생]테이블에 장길산에 대한 튜플을 삭제
DELETE FROM 학생
WHERE 이름 = '장길산';
-- * 모든 레코드를 삭제할 때 (삭제해도 테이블 구조는 남아있어서 DROP 명령어와 다르다.)
DELETE FROM 테이블명4. DCL (데이터 제어어)
데이터 보안, 무결성 유지, 병행제어, 회복을 위해 관리자가 사용하는 제어용 언어이다.
GRANT ON TO (권한 부여 명령어)
**GRANT 권한 ON 테이블 TO 사용자;**
-- 예) 관리자가 사용자 장길산에게 '학생' 테이블에 대해 UPDATE 할 수 있는 권한 부여
GRANT UPDATE ON 학생 TO 장길산;REVOKE ON FROM (권환 회수 명령어)
**REVOKE 권한 ON 테이블 FROM 사용자;**
-- 예) 관리자가 사용자 장길산에게 '학생' 테이블에 대해 UPDATE 할 수 있는 권한 회수
REVOKE UPDATE ON 학생 FROM 장길산;5. 절차형 SQL
저장 프로시저 (Stored Procedure)
일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
CREATE OR REPLACE PROCEDURE 프로시저명
( 변수1 IN 변수타입, 변수2 OUT 변수타입, 변수3 IN OUT 변수타입.... )
IS
변수 처리부
BEGIN
처리내용
EXCEPTION
예외처리부
END;트리거 (Trigger)
테이블에 대한 이벤트에 반응해 자동으로 실행되는 작업
(1) 유형
- 행 트리거
- 행 각각에 대해 실행
FOR EACH ROW옵션 사용- 문장 트리거
- INSERT, UPDATE, DELETE 문에 대해 단 한 번만 실행
// INSERT가 된 이후 TB_GOODS의 nStock 개수와 새롭게 등록된 nStock의 개수를 더해서 업데이트 해준다
CREATE TRIGGER TRIGGER_GOODS_STOCK
AFTER INSERT ON TB_GOODS_STOCK FOR EACH ROW
BEGIN
UPDATE TB_GOODS
SET
nStock = nStock + NEW.nStock
WHERE idx = NEW.p_idx;
END사용자 정의 함수
- 프로시저와 사용자 정의 함수 모두 호출하게 되면 미리 정의해 놓은 기능을 수행하는 모듈
- 파라미터는 입력 파라미터만 가능함
- 리턴값은 하나!
CREATE OR REPLACE FUNCTION 함수명
( 매개변수1, 매개변수2, 매개변수3,... )
RETURN 데이터 타입
IS
변수 처리부
BEGIN
처리내용
RETURN 반환값
EXCEPTION
예외처리부
END[3] 병행제어와 데이터전환
1. 병행제어
여러 트랜잭션들이 동시에 실행되면서도 데이터베이스의 일관성을 유지할 수 있게 하는 기법
병행제어의 목적
- DB 일관성 유지 : 무결성 지킴
병행제어의 문제점
갱현모연
- 갱신 분실 (Lost Update)
두 개 이상의 트랜잭션이 같은 자료를 공유하여 갱신할 때 갱신 결과의 일부가 없어지는 현상 - 비완료 의존성 (Uncommitted Dependency), 현황 파악오류 (Dirty Read)
하나의 트랜잭션 수행이 실패한 후 회복되기 전에 다른 트랜잭션이 실패한 갱신 결과를 참조하는 현상 - 모순성 (Inconsistency)
- 두 개의 트랜잭션이 병행수행될 때 원치 않는 자료를 이용함으로써 발생하는 문제
- 갱신 분실과 비슷해 보이지만 여러 데이터를 가져올 때 발생하는 문제
- 연쇄 복귀 (Cascading Rollback)
병행수행 된 트랜잭션들 중 어느 하나에 문제가 생겨 Rollback하는 경우 다른 트랜잭션도 함께 Rollback 되는 현상
병행제어의 기법
로낙타다
- 로킹 (Locking)
- 트랜잭션이 어떤 데이터에 접근하고자 할 때 로킹 수행
- 다른 사람이 변경하지 못하게 함으로써, 트랜잭션 무결성, 일관성을 유지하는 것
-
로킹 단위에 따른 구분 ex) 화장실
구분 로크 수 병행성 오버헤드 로킹 단위가 크면 적어짐 낮아짐 감소 로킹 단위가 작으면 많아짐 높아짐 증가 -
2단계 로킹 규약 (Two-Phase Locking Protocol)
Lock과 Unlock이 동시에 이루어지면 일관성이 보장되지 않으므로 Lock만 가능한 단계와 Unlock만 가능한 단계를 구분한다.
-확장단계: 새로운 Lock은 가능하고 Unlock은 불가능하다.
-축소단계: Unlock은 가능하고 새로운 Lock은 불가능하다.
-
- 낙관적 병행제어 (Optimistic Concurrency Control)
트랜잭션 수행 동안은 어떠한 검사도 하지 않고, 트랜잭션 종료 시에 일괄적으로 검사 - 타임스탬프 (Time Stamp)
데이터에 접근하는 시간을 미리 정해서 정해진 시간(Time Stamp)의 순서대로 데이터에 접근하여 수행 - 다중 버전 병행제어 (Multi-version, Concurrency Control)
여러 버전의 타임스탬프를 비교하여 스케줄상 직렬가능성이 보장되는 타임스탬프를 선택
회복 (Database Recovery)
트랜잭션들을 수행하는 도중 장애로 인해 손상된 데이터베이스를 손상되기 이전의 정상적인 상태로 복구시키는 작업
장애의 유형
- 트랜잭션 장애
- 시스템 장애
- 미디어 장애
Undo와 Redo
- Undo
취소하여 복구 수행 - Redo
재실행하여 복구 수행
회복 기법
- 로그 기반 회복 기법
- 지연갱신 회복 기법 (Deferred Update)
- 트랜잭션의 부분 완료 상태에선 변경 내용을 로그 파일에만 저장
- 커밋이 발생하기 전까진 데이터베이스에 기록하지 않음
- 중간에 장애가 생기더라도 데이터베이스에 기록되지 않았으므로 UNDO가 필요 없음 (미실행된 로그 폐기)
- 즉시갱신 회복 기법 (Immediate Update)
- 트랜잭션 수행 도중에도 변경 내용을 즉시 데이터베이스에 기록
- 커밋 발생 이전의 갱신은 원자성이 보장되지 않는 미완료 갱신이므로 장애 발생 시 UNDO 필요
- 지연갱신 회복 기법 (Deferred Update)
- 검사점 회복 기법 (Checkpoint Recovery) (= 체크포인트 회복 기법) 장애 발생 시 검사점(Checkpoint) 이전에 처리된 트랜잭션은 회복에서 제외하고 검사점 이후에 처리된 트랜
잭션은 회복 작업 수행
- 그림자 페이징 회복 기법 (Shadow Paging Recovery)
수행 전 복사본을 가지고 장애가 발생하면 엎어치기 한다 - 미디어 회복 기법 (Media Recovery)
디스크와 같은 비휘발성 저장 장치가 손상되는 장애 발생을 대비한 회복 기법 - ARIES 회복 기법 (Algorithms form Recovery and Isolation Exploiting Semantics)
- 주요 3단계
분석단계
REDO 단계: 재실행
UNDO 단계: 취소
- 주요 3단계
2. 데이터 전환
ETL (Extraction, Transformation, Loading)
기존의 원천 시스템에서 데이터를 추출(Extraction)하여 목적 시스템의 데이터베이스에 적합한 형식과 내용으
로 변환(Transformation)한 후, 목적 시스템에 적재(Loading)하는 일련의 과정
(1) 기능
- 추출 (Extraction)
- 변환 (Transformation)
- 적재 (Load)
