
Deep Neural Networks for YouTube Recommendations
0. ABSTRACT
YouTube는 현존하는 가장 정교하고 거대한 추천시스템을 가지고 있으며 이 논문에서는 YouTube의 수준 높은 시스템과 Deep Learning의 도입이 가져온 드라마틱한 성능 향상을 설명한다.
이 논문은 Information Retrieval에서 기본적인 구조인 Candidate Generation Model(후보생성 모델)과 Ranking Model(랭킹 모델)을 설명할 것이다. 또한 YouTube가 추천 시스템을 설계, 유지하는 과정에서 인사이트를 공유할 예정이다.
1. INTRODUCTION
YouTube는 전 세계 최대 규모의 영상 플랫폼으로 YouTube의 추천 시스템은 10억 명 이상의 User들이 개인화된 Content를 찾는 데 도움을 주고 있다. 이 논문에서는 2010년과 마찬가지로 3가지 도전 과제에 대해 집중할 것이다.
-
Scale
YouTube의 거대한 User, Video data를 다루기 위해서는 고도의 distributed learning 알고리즘과 효율적인 Serving 시스템이 필요함. -
Freshness
YouTube는 초 단위로 Video가 업로드 되는 매우 동적인 Data를 가지고 있음. 그렇기 때문에 추천 시스템은 새로 업로드 된 Content 뿐만 아니라 사용자가 최근에 취한 Action도 모델링 할 수 있을 만큼 반응성이 뛰어나야 함. -
Noise
YouTube User의 행동은 Sparsity와 관찰할 수 없는 외부 요인들 때문에 예측하기가 매우 어렵다는 특성이 있음. YouTube는 User의 선호에 대한 Ground-Truth를 얻지 못하고 대신에 implicit feedback signal를 사용하여 Modeling을 진행함.
2. SYSTEM OVERVIEW
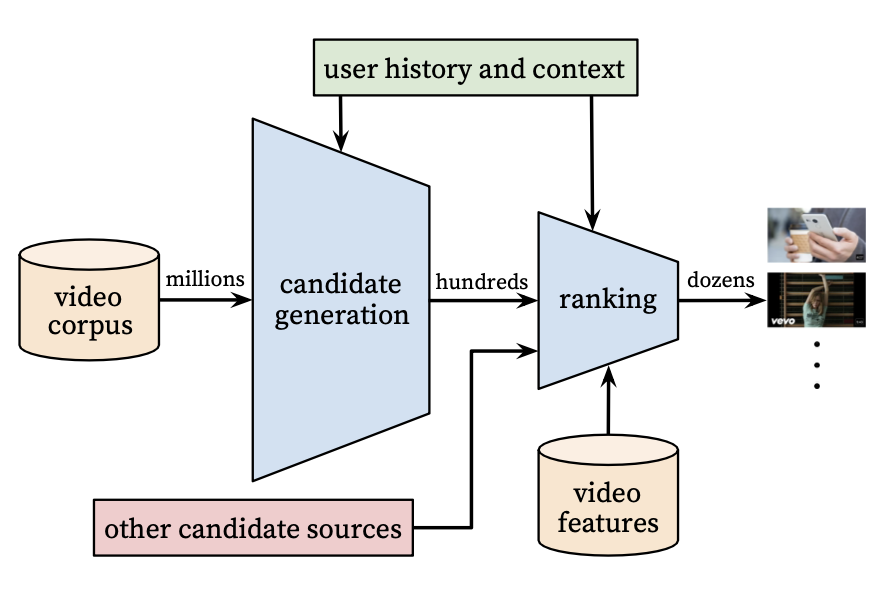
YouTube 추천 시스템의 구조는 위의 그림과 같이 candidate generation, ranking 두 부분으로 구성된다.
Candidate Generation Network는 YouTube User의 행동 데이터를 Input으로 받고 Large Corpus에서 후보 비디오를 검색한다. 이러한 후보 비디오들은 User들의 선호도를 높은 정밀도로 예측하도록 설계됐다.
또한 Candidates를 생성할 때는 협업 필터링을 사용하여 간단한 개인화를 제공하며 User 간의 유사성은 비디오 시청 ID, 검색 쿼리 토큰, 인구 통계 등과 같은 기본적인 특성을 통해 표현된다.
가장 좋은 추천을 제시하기 위해서는 각 후보 비디오들의 중요성을 정밀하게 구별할 수 있어야 한다. 이를 위해 Ranking Network가 사용된다. Ranking Network는 User, Video와 관련된 특성들을 사용하여 각각의 Video에 점수를 매기고 점수가 높은 정도에 따라 User들에게 순서대로 표시된다.
두 단계의 모델은 수백만개의 비디오 중에서 User가 선호하는 개인화 Video들을 추천할 수 있도록 해준다. 게다가 이러한 설계는 다른 출처에서 생성된 후보들도 포함할 수 있도록 해준다.
3. CANDIDATE GENERATION
수백만 개의 Video 중 일정한 기준에 따라 수백개의 후보들을 생성한다. YouTube의 이전 추천 시스템은 Matrix Factorization 방식을 채택했다. 이 논문에서 제시하는 방식도 이러한 Matrix Factorization 방식을 모방한 것이며 Factorization의 비선형화 방식이라고 할 수 있다.
3.1 Recommendation as Classification
YouTube는 추천의 문제를 Extreme Multiclass Classificaion으로 재정의 했다. 이 문제는 특정 시간(t)에 User(U)가 Context(C)를 가지고 있을 때 수백만 개의 비디오(V) 중에서 각각의 비디오(i)를 볼 확률(wt)을 구하는 것이다. 수식을 살펴보면 softmax 함수인 것을 확인할 수 있다.
은 User와 Context 쌍에 대한 고차원 Embedding을 나타내고 는 각각의 후보 비디오에 대한 Embedding을 나타낸다. Embedding은 단순히 sparse entities를 맵핑한 것이며 이러한 User Embedding을 학습하여 Video 구별 성능을 향상시킨다.
YouTube는 '좋아요', '싫어요'와 같은 explicit feedback이 존재하지만 이 데이터 보다는 implicit feedback을 사용했고 영상을 끝까지 본 것을 Positive Example로 설정했다. 그 이유는 implicit feedback이 explicit feedback 보다 훨씬 많고 explicit feedback이 부족한 영상들에 대해서도 추천을 생성할 수 있기 때문이다.
Efficient Extreme Multiclass
YouTube는 수백만 개의 class를 가지고 있는 Model을 효율적으로 학습시키기 위해서 Negative Sampling을 사용했고 이러한 방식은 속도와 성능을 향상시켰다.
Model의 성능을 고려하면서도 Serving latency를 고려해야 한다. 이전의 YouTube 시스템은 해싱 알고리즘을 사용했으며 이 논문에서도 비슷한 방식을 채택했다. 이 model에는 Nearest Neighbor Search 방식을 채택했고 A/B Test에서도 이 방식을 선택하는 것이 민감하지 않다는 것을 확인했다.
3.2 Model Architecture
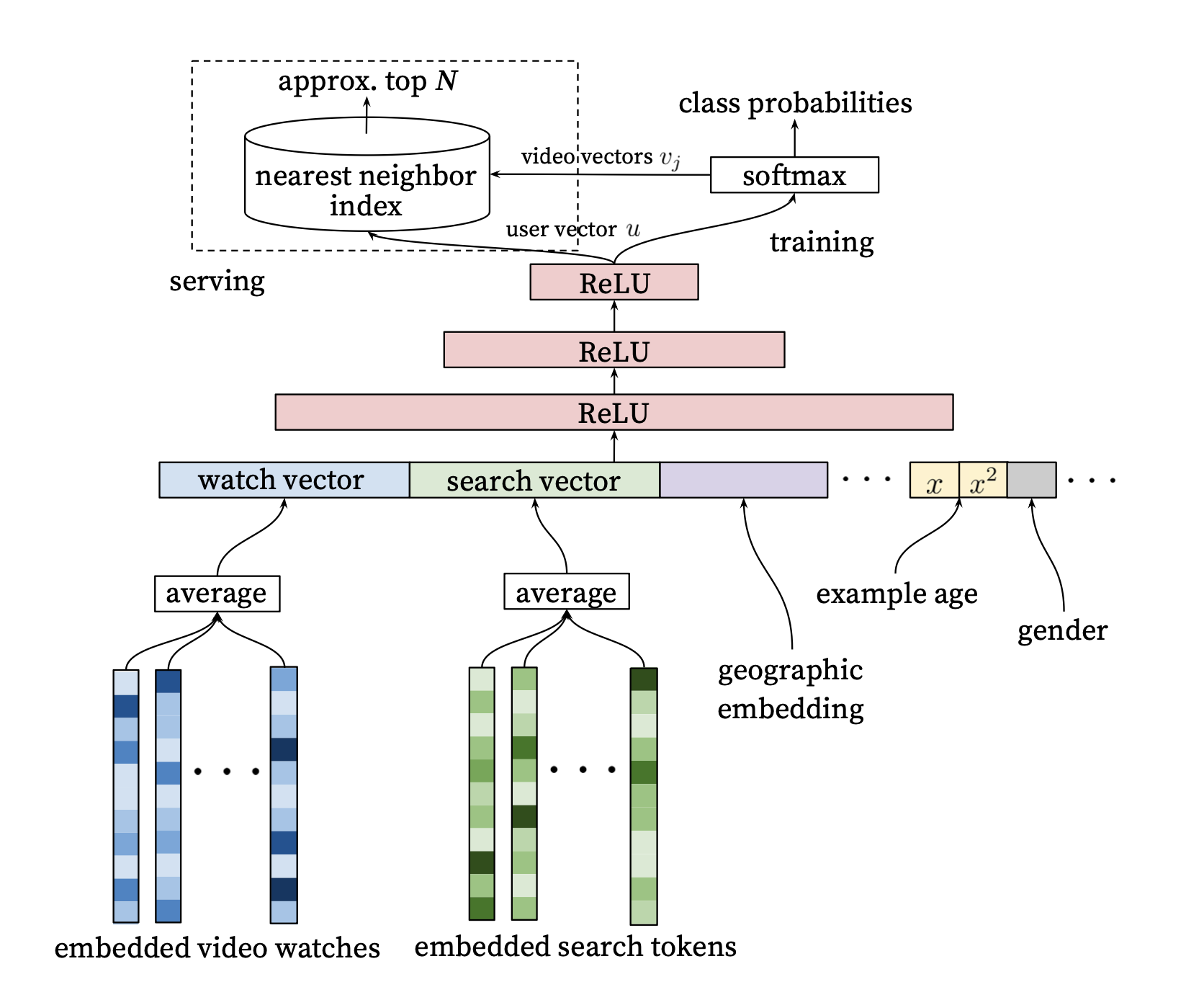
YouTube는 word2vec의 CBOW 방식을 참고하여 각각의 video에 대한 video ID를 고차원 embedding한다.
User의 시청 이력은 가변 크기를 가지고 있기 때문에 Embedding을 통해 dense vector로 변환된다. model은 고정된 크기의 dense inputs가 필요하며 vector들을 단순 평균 내는 방식이 가장 성능이 좋았다.
3.3 Heterogeneous Signals
일반화된 matrix factorization를 사용할 수 있는 DL의 가장 큰 장점은 Feature들을 쉽게 모델에 추가할 수 있다는 것이다.
검색 기록은 시청 이력과 비슷하게 각각의 query를 token화 하고 token들은 Embedding 된다. 또한 이러한 vector들은 모두 평균을 내서 사용된다.
Demo features는 새로운 user에게 추천을 제공하는 데 중요한 feature이며 Gender feature는 단순하게 0과 1 두 값으로 모델에 입력된다.
“Example Age” Feature
YouTube는 매 초 수많은 Video들이 업로드 되고 있다. User들은 최근 업로드 된 video들을 선호하는 경향이 있기 때문에 이 video들을 추천해야 한다. 그러나 과거의 데이터를 활용하여 미래를 예측하기 때문에 과거의 아이템에 편향된 결과를 제공하는 문제가 있다.
또한, 인기 있는 비디오는 시간에 따라 매우 크게 변화하고 이러한 변화를 반영하기 위해 YouTube의 추천 시스템은 지난 몇 주 간의 평균 시청 기록을 반영하여 추천을 제공한다. 이 때 평균 시청 기록은 시간성을 보장하지 못한다는 단점이 있다.
이것들을 보정하기 위해서 Example Age라는 Feature를 학습에 사용하고 있으며 이것은 성능을 향상시키는 결과를 가져왔다. 실제 예측 시에는 이 Feature를 0 또는 음수 값으로 설정하는데 이것은 모델이 최신 데이터를 기반으로 예측할 수 있도록 하기 위함이다.
3.4 Label and Context Selection
Training Example으로 외부 사이트 출처의 시청 기록을 포함한 YouTube의 모든 시청 기록을 사용한다. 그렇게 하지 않으면 새로운 Content가 노출되기 어렵고 기존의 인기 Content에 편향된 결과를 얻을 수 있기 때문이다.
User들이 추천 Content가 아닌 Video를 발견하면 CF를 통해 다른 User들에게 빠르게 이 Content가 전파되는 방식으로 설계했으며 User당 고정된 수의 Training Example을 할당하여 모든 User에게 동일한 Weight를 주도록 설계했다. 특히 User의 Weight를 고정시킨 것은 헤비 유저의 bias와 추천을 제한하기 위해서이다.
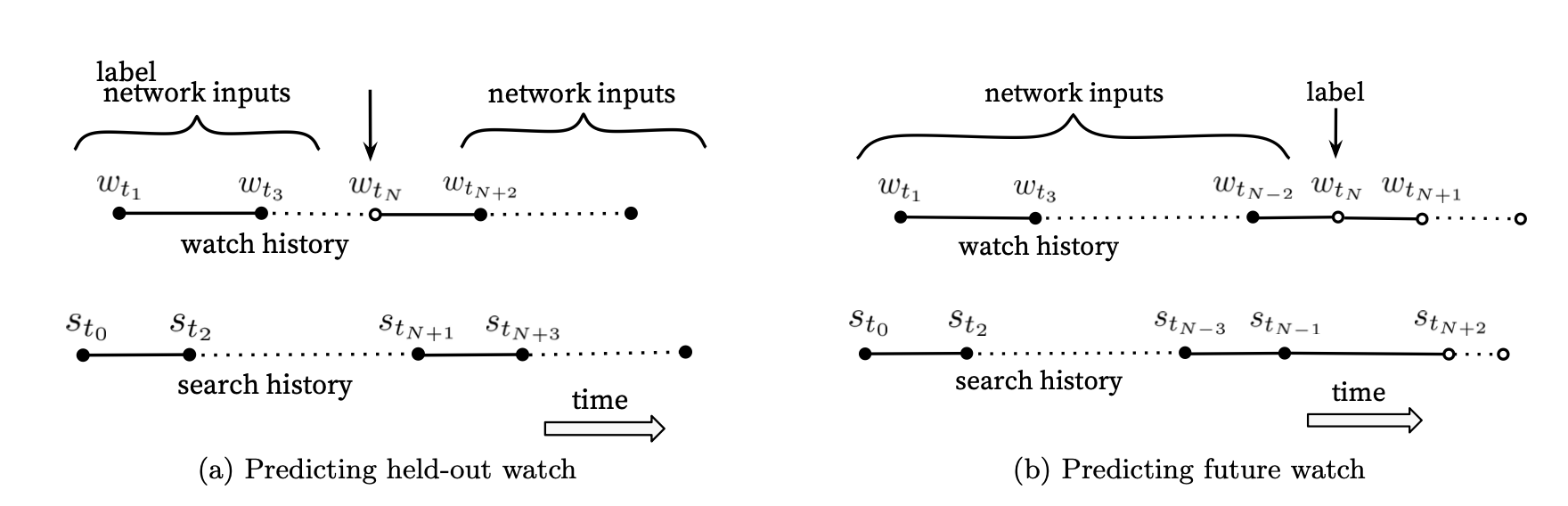
User의 시청 패턴은 불규칙적이기 때문에 이러한 특성을 반영할 수 있는 시스템을 설계해야 한다. 에피소드 형태의 Content는 순차적으로 시청하는 경향이 있고 특정 장르에 대한 관심이 생겼을 경우에는 가장 인기 있는 Content부터 Niche Content로 시청하는 경향이 있다. 따라서 어떤 User가 "Talyer Swift"를 검색했을 때, 단순히 "Talyer Swift"와 관련된 Content만을 추천해주는 것은 이러한 불규칙적 패턴을 반영하지 못하는 시스템이 될 것이다.
YouTube에서는 이러한 User의 불규칙적 시청 패턴을 반영하기 위해서 실제 label 지점을 기준으로 이전의 데이터만을 사용해 모델을 학습시켰고 이것은 매우 좋은 성능을 보여줬다.
4. RANKING
어떤 User가 시청할 확률이 높은 Video를 추천 받았지만 thumnail image 때문에 클릭을 하지 않을 수 있다. 이때 Ranking 시스템의 역할은 Candidate Generation을 보정하여 User에게 맞춤 Video를 제공하는 것이다.
Ranking을 수행하는 과정에서 후보 생성 과정보다 더 많은 Feature들을 사용할 수 있는데, 수백만개의 Video를 평가하는 후보 생성 과정과는 다르게 수백개의 Video를 평가하기 때문이다.
Ranking 시스템은 Candidate Generation과 비슷한 구조를 사용하며 로지스틱 회귀를 통해 각 Video에 대해 점수를 부여하는 방식으로 작동한다. User에게 Serving 될 때에는 A/B Test를 통해 노출 당 시청 시간을 측정하여 최종 Ranking 결과를 조정한다. 단순히 CTR(Click-Through Rate)을 반영할 경우에는 Clickbait에 영향을 받을 수 있기 때문이다.
4.1 Feature Representation
YouTube에서도 categorical, ordinal Feature들을 사용하고 있다. categorical feature의 경우 적게는 2개의 범주, 많게는 수백개의 범주를 가진 feature가 있으며 단일 값을 가지는 경우와 다중 값을 가지는 경우 등이 있다.
또한, Item의 속성과 관련이 있는 Feature를 "impression feature", User, Context와 관련이 있는 Feature를 "query feature"로 구분하며 impression feature는 각각의 item마다 계산되고 query feature는 Ranking이 요청될 때 한번씩 계산되는 특징이 있다.
Feature Engineering
앞서 말한 것처럼 Ranking Model은 수백개의 Feature를 사용하고 categorical feature와 continuous feature를 대략 절반 정도로 나눠서 사용하고 있다.
YouTube는 Deep Learning을 사용했지만, YouTube의 row data들은 직접적으로 사용되기 어렵기 때문에 Feature Engineering에 여전히 많은 자원을 투입하고 있다.
주요한 과제 중 하나는 User의 Action를 시간적 특성으로 나타내고 이 Action이 Ranking에서 제공하는 Video와 얼마나 연관있는지를 나타내는 것이다.
가장 중요한 siganl은 User와 item, 이 item과 유사한 item과의 과거 상호작용이다. 예를 들어, 추천된 Video가 업로드 된 YouTube 채널과 User의 기록을 살펴보는 것이다. 이 User가 이 채널에서 얼마나 많은 영상을 봤는지, 언제 마지막으로 이 주제와 관련된 영상을 봤는지 등을 확인하는 데 이러한 continuous feature는 다른 item을 추천하는 데 있어서 매우 효과적이다. 그리고 어떤 Candidate Generation에서 왔는지, candidate가 생성될 때 score는 얼마인지와 같은 propagate imformation도 중요하다.
마지막으로 Video 노출의 빈도를 설명하는 Feature는 추천 시스템에 변화를 주는 데 중요하다. 만약 User가 Video를 추천 받았지만 그것을 시청하지 않는 경우, 그 즉시 Model은 해당 item이 다음 페이지에 노출되도록 만든다.
Embedding Categorical Features
Candidate Generation과 비슷하게 Ranking에서도 Embedding을 사용한다. Vocabulary라고 불리는 unique ID는 고유한 값에 따라 log에 비례하도록 증가하도록 Embedding된다. Cardinality가 매우 높은 Feature의 경우, 클릭 빈도수를 기반으로 상위 N개까지 잘린다. 상위 N개 이외의(Out-of-vocabulary) 값들은 일괄적으로 단순하게 zero-embedding 처리하며 candidate와 마찬가지로 multivalent feature는 average하여 처리한다.
Normalizing Continuous Features
Neural network는 input의 scale과 distribution에 매우 민감하기 때문에 Normalization이 필요함. YouTube는 continuous feature를 0과 1사이의 범위에서 균등하게 분포되도록 설정하였으며 과 도 함께 input 값으로 사용하여 offline 환경에서 성능을 높일 수 있도록 했다.
4.2 Modeling Expected Watch Time
YouTube Ranking model의 목표는 Positive(추천한 Video clicked), Negative(추천한 Video not clicked)를 통해 User의 예상 시청 시간을 예측하는 것이며 이를 위해서 weighted logistic regression을 사용했다.
Positive는 Video의 시청 시간에 따라 가중치를 부여 받으며 Negative는 Unit Weight를 받는다. 이러한 방식으로 logistic regression에 의해 학습된 odds는 에 대한 의 합계가 된다. 여기서 은 학습 데이터의 수, 는 Positive impression의 수, 는 번째 impression의 시청 시간이다. 실제 상황에서 positive impression의 비율은 매우 작기 때문에 odds는 에 가까우며 는 클릭 확률, 는 impression의 예상 시청 시간입니다. 가 작기 때문에 의 값은 에 가깝다. 최종 예측의 단계에서 활성 함수로 를 사용하며 변환된 odds는 예상 시청 시간을 근사하여 User가 특정 Video를 얼마나 오래 시청할지 예측하는 데 사용된다.
5. CONCLUSIONS
Deep Learning을 활용한 CF 모델은 이전에 YouTube에서 사용한 MF 모델 보다 뛰어난 성능을 보여줬다. YouTube는 단순히 User의 최근 검색 기록이나 특정 Video 시청을 학습하기 보다는 보다 일반적인 User Action을 사용하여 과적합 문제를 해결하고 live metric에서 좋은 성능을 보이는 Model을 제시했다.
Example Age Feature를 사용하여 편향을 제거하고 모델이 인기 동영상의 시간적 특성을 더 잘 반영할 수 있도록 했다. 이것은 오프라인 테스트에서 정밀도를 향상시키고, A/B 테스트에서 최근 업로드된 동영상의 시청 시간을 크게 늘릴 수 있음을 입증했다.
Logistic regression 방식을 통해 Positive와 Negative에 각각 가중치를 부여하였으며, 이것은 직접 CTR을 예측하는 것에 비해 훨씬 더 좋은 성능을 보였다.
Review
개인맞춤형 서비스의 중요성이 증대되고 있는 시점에서 추천 알고리즘은 개인화와 떨어질 수 없는 것이다. 특히 추천 알고리즘으로 매우 유명한 기업을 꼽으라면 Netflix와 YouTube인데, 이 논문은 2016년 발표된 것으로 기존의 방식에서 Deep Learning을 도입하여 성능을 향상시킨 사례를 다루고 있다.
Deep Learning을 도입했지만 YouTube가 Feature Engineering에도 엄청난 자원을 쏟고 있다는 점을 보며, Feature에 대한 중요성을 깨닫게 되는 계기가 되었다.
YouTube의 추천 시스템 논문은 2019년에도 발표된 바가 있다. 다음에는 이 논문을 읽고 2016년의 시스템과 어떤 차이가 있는지를 알아보도록 하자!
YouTube Recommendation system 트릴로지 리뷰 - [2]
[논문리뷰] Deep Neural Networks for YouTube Recommendations 논문 리뷰
유튜브 추천 시스템-2. DNN for YouTubue
