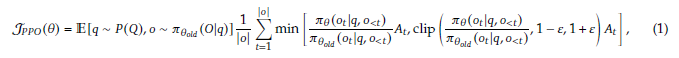DeepSeek-R1을 리뷰하려다가 GRPO 개념을 이해하기 위해 본 논문을 리뷰하게 됐습니다.
GRPO의 개념만 궁금하신 분들은 '4. Reinforcement Learning' 참고하시면 됩니다!
PPO도 처음 접하시는 분들은 맨 밑에 '+PPO에 관한 설명' 참고하시면 됩니다!
1. Introduction
LLM의 수학 추론 분야는 혁신적으로 발전했고, 인간이 복잡한 수학 문제를 해결하는데 많은 기여를 했습니다. 하지만, GPT-4, Gemini-Ultra 등의 최신 모델들은 private이고, open-source 모델들은 성능이 크게 좋지 않습니다.
따라서 저자들은 DeepSeekMath라는 domain-specific 언어 모델을 제안합니다. 이 모델은 오픈 소스 중에서는 가장 성능이 좋고, academic benchmarks에서는 GPT-4와 성능이 비슷합니다. 이를 위해서 저자들은 DeepSeek-Math Corpus를 구축했습니다.
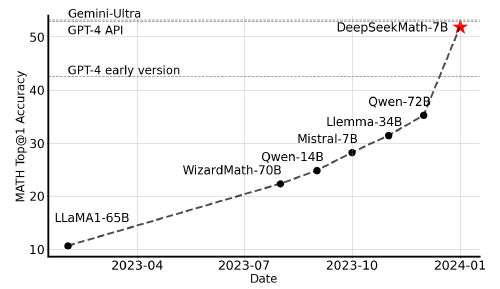
또한, 코드 학습을 통해 수학 추론의 성능을 향상할 수 있고, 수학 학습을 통해 general 추론 성능을 향상할 수 있다고 합니다. 이렇게 학습된 DeepSeekMath-Instruct 7B는 open-source 모델들 중 7B 뿐만 아니라 70B에도 맞먹는 성능을 보입니다.
뿐만 아니라, Group Relative Policy Optimization(GRPO)이라는 RL 알고리즘을 소개합니다. GRPO는 PPO와 다르게 group score를 활용해 학습에 필요한 자원을 상당히 줄일 수 있습니다. 저자들은 본 논문의 후반부에 자세히 소개하는 unified paradigm을 통해 RL 테크닉을 직관적이고 간단하게 개념화 할 수 있다고 합니다. 또한, 이 RL 방식이 어떻게 instruction-tuned 모델의 성능을 향상 시키는지, 앞으로 어떤 식의 연구가 진행되면 좋을지 소개합니다.
1.1 Contributions
Math Pre-Training at Scale
- Public하게 접근 가능한 Common Crawl 데이터를 활용할 수 있다는 사실을 증명
- 수학 추론 모델은 사이즈가 정답이 아니라는 사실을 발견. (high-quality 데이터가 중요)
- 'does code training improve reasoning abilities?' 라는 오래된 질문에 Yes라는 결론
- ArXiv의 데이터 셋은 성능 향상에 도움이 별로 안 된다는 사실 발견
Exploration and Analysis of Reinforcement Learning
- 효율적이고 효과적인 GRPO라는 RL 알고리즘을 소개
- GRPO를 통해 instruction-tuning data만으로 성능을 크게 향상 (out-of-domain 성능도 향상)
- unified paradigm을 소개
- RL이 효과적인 이유, 추후 연구 방향을 제시
1.2 Summary of Evaluations and Metrics
크게 아래 세 가지 task에 대한 실험을 많이 진행했고, 본 논문에서 제안한 방식들이 굉장히 효과적이었다는 내용입니다. (생략)
- English and Chinese Mathematical Reasoning
- Formal Mathematics
- Natural Language Understanding, Reasoning, and Code
2. Math Pre-Training
2.1 Data Collection and Decontamination
Seed Corpus(small & high-quality)로 Common Crawl(CC)을 활용해 DeepSeekMath Corpus를 구축했습니다. 이는 코딩 등의 다른 도메인에도 적용할 수 있다고 합니다!
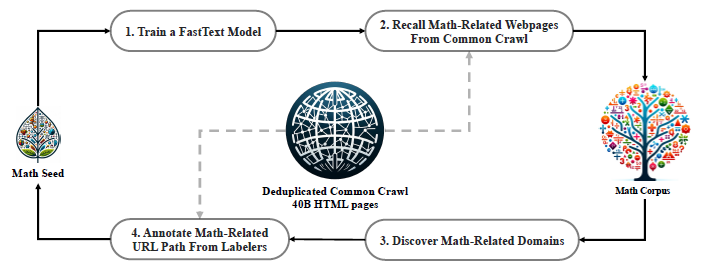
첫째로, OpenWebMath를 seed corpus로 설정하여 fastText 모델을 학습했습니다. 이후 original CC의 사이즈를 줄이기 위해 URL-based deduplication과 near-deduplication을 적용해 결론적으로 50B HTML 웹페이지를 확보했습니다. 데이터의 퀄리티를 향상하기 위해서 fastText모델의 score rank로 낮은 퀄리티 데이터를 제거했습니다.
둘째로, seed corpus를 늘리기 위해 같은 URL을 공유하는 도메인 중, 수학과 관련된 컨텐츠를 직접 annotation하여 추가했습니다. (mathoverflow.net -> mathoverflow.net/questions) fastText모델은 positive example set으로만 학습되었기 때문에, 첫 iteration에서 많은 웹페이지가 수집되지는 못하기 때문입니다.
셋째로, 벤치마크 데이터 오염을 방지하기 위해서 필터링을 적용했습니다. 10 gram 이상일 때는 sub-string과 정확히 일치할 때 drop, 3~10gram은 정확히 일치할 때 drop하는 방식입니다.
2.2 Validating the Quality of the DeepSeekMath Corpus
2.2.1 Training Setting
학습 세팅 설명 (생략)
2.2.2 Evaluation Results
"DeepSeekMath Corpus는 가장 크고 high-quality이면서 multilingual(영어, 중국어) 수학 데이터이다!" 라는 내용입니다.
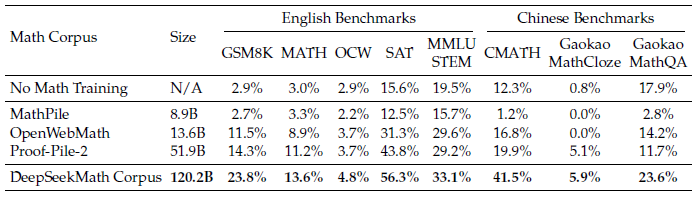
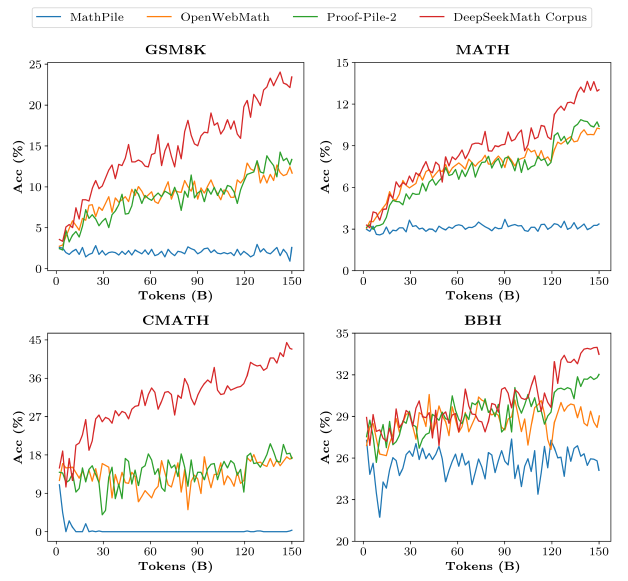
- High-quality: 여러 벤치마크와 비교해서 압도적인 성능 향상
- Multilingual: 영어와 중국어 둘 다 성능 향상
- Large-scale: 기존 corpora보다 몇 배 더 크고, Token이 증가할수록 성능이 증가
2.3 Training and Evaluating DeepSeekMath-Base 7B
"이렇게 수집한 DeepSeekMath Corpus는 다양한 task에 도움이 된다"는 내용입니다.
DeepSeekBase-7B는 DeepSeek-Coder-Base-v1.5 7B로 init했고, 학습된 데이터는 DeepSeekMath Corpus 54%, AlgebraicStack 4%, arXiv 10%, Github code 10%, CC 10%로 구성되었습니다.
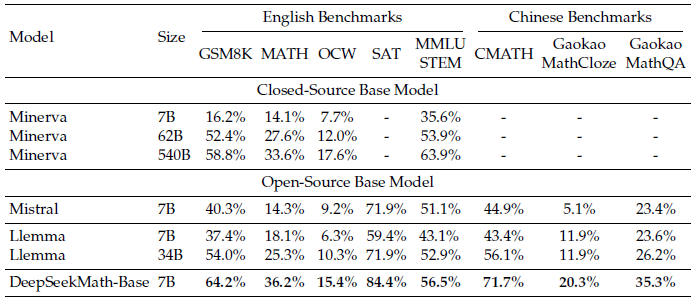
Mathematical Problem Solving with Step-by-Step Reasoning: 초등~대학 수준의 여러 수학 문제 해결
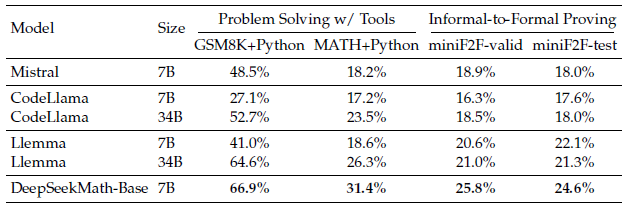
Mathematical Problem Solving with Tool Use: 프로그래밍을 활용한 수학 추론 (python with math library등)
Formal Mathematics: Formal proof automation
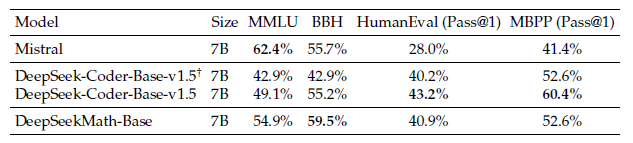
Natural Language Understanding, Reasoning, and Code: 기타 LLM 모델 활용 tasks 실험
특히, 위 실험에서 MMLU(자연어 이해), BBH(추론) 데이터 셋에서 DeepSeekMath-Base가 DeepSeek-Coder-Base보다 성능이 크게 향상된 것을 보아, 수학 학습이 자연어 이해와 추론 task에 도움이 된다는 것을 확인할 수 있습니다.
3. Supervised Fine-Tuning
3.1 SFT Data Curation
SFT 데이터 설명 (생략)
3.2 Training and Evaluating DeepSeekMath-Instruct 7B
Instruct 실험은 비교 모델이 매우 많습니다. (closed-source 6개, open-source 10개)
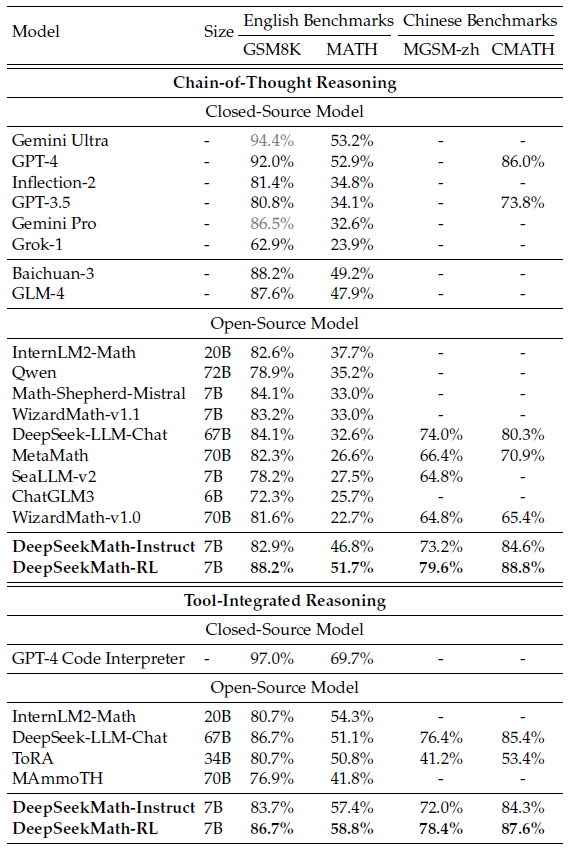
Math 데이터 셋에서는 Gemini Ultra, GPT-4를 제외하고는 proprietary 모델들보다도 성능이 좋습니다. (Inflection-2, Gemini Pro, Baichuan-3, GLM-4)
4. Reinforcement Learning (⭐)
4.1 Group Relative Policy Optimization
LLMs의 SFT 이후 RL만으로 수학 추론 성능이 향상된다는 것을 증명하는 내용입니다.
4.1.1 From PPO to GRPO
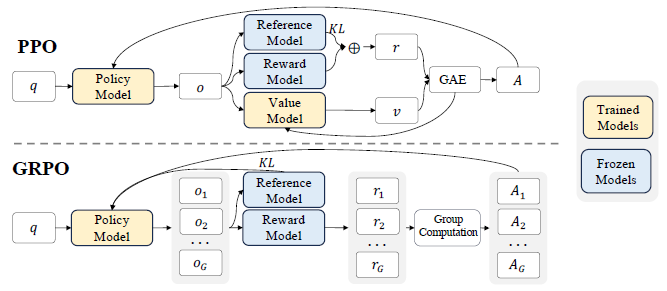
Proximal Policy Optimization(PPO)은 LLM fine-tuning에 널리 사용되는 actor-critic RL 알고리즘입니다. 아래 surrogate objective를 최대화하는 방식입니다.
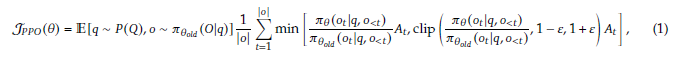
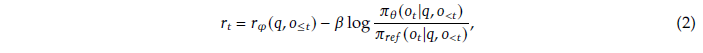
,는 policy, ,는 question과 output, 은 reward를 의미합니다.
objective function을 아주 간단히 요약하면 현재 policy에서의 Advantage 기대값입니다. 여기서 Advantage는 reward와 valu의 GAE로 계산됩니다.
(현재 policy에서의 Advantage의 기대값이라는 표현이 이해되지 않으시는 분들은 '+PPO에 관한 설명' 부분을 참고해주시면 좋을 것 같습니다.)
PPO의 한계
- policy 모델과 비슷한 사이즈의 value모델을 활용하기 때문에 메모리와 계산 비용이 매우 큼
- 일반적으로 LLM에서는 마지막 토큰에만 reward를 할당
이러한 문제를 해결하기 위해 저자들은 GRPO를 제안합니다. GRPO의 objective는 아래와 같습니다.
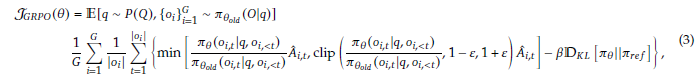
policy 모델에서 개의 output을 출력하고, 각각의 output에 대한 reward가 출력됩니다. 이를 normalization하여 Advantage를 계산합니다. (4.1.2, 4.1.3에서 설명)
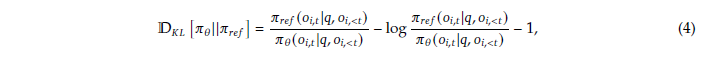
PPO와 다르게 직접 추가된 unbiased KL divergence 식은 위와 같고, 항상 positive임을 보장합니다.
4.1.2 Outcome Supervision RL with GRPO
각각의 질문 마다 old policy model에 의해 group output 와 그에 따른 reward 를 추출하고, 해당 r들을 normalize하여 으로 계산합니다.
4.1.3 Process supervision RL with GRPO
4.1.2의 방식은 마지막 output에 대한 reward를 활용하는 방식이고, output별로 모든 j-step의 마지막 token index에 대한 reward를 활용하는 방식도 있습니다.
4.1.4 Iterative RL with GRPO
reward 모델을 업데이트 해주지 않으면 old reward 모델과 current policy model을 사용하게 됩니다. 따라서 policy 모델을 활용해서 reward 모델용 training set을 생성하는 방식으로 업데이트 해줍니다. reward 모델이 업데이트 되면 policy 모델을 reference 모델로 설정하는 방식입니다.

요약
- Advantage 계산에 value와 GAE 대신 group normalize된 reward를 사용
- reward 모델을 함께 업데이트
4.2 Training and Evaluation DeepSeekMath-RL
DeepSeekMath-Instruct 7B를 기반으로 DeepSeekMath-RL을 학습했습니다. GSM8K, MATH 데이터 셋으로만 학습했으며, 해당 데이터들로 chain-of-thought 추론만 실험했습니다.
- DeepSeekMath-RL은 모든 open-source(7B~70B), 대부분의 closed-source 모델보다 성능이 좋음
- 좁은 범위의 training 데이터로 instruction tuning했을 때 DeepSeekMath-Insturct보다 성능이 좋음
5. Discussion
5.1 Lessons Learnt in Pre-Training
5.1.1 Code Training Benefits Mathematical Reasoning
code와 수학 학습을 two-stage, one-stage training으로 진행했을 때 성능에 관한 실험입니다.
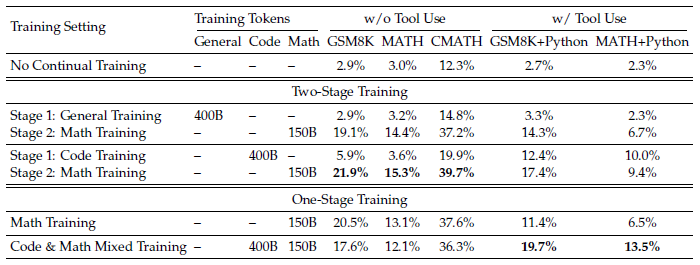
tool을 활용하든 안하든 수학 추론에서 code training이 성능을 향상합니다.
- with tool 실험: 두 경우 모두 code training이 수학 추론 성능을 향상
- without tool 실험: two-stage code training이 좋음
이는 실험에 활용한 DeepSeek-LLM 1.3B 모델의 scale이 작아서 두 데이터를 동시에 학습하지못하는 것 같다고 추정합니다. (lacks the capacity)
5.1.2 ArXiv Papers Seem Ineffective in Improving Mathematical Reasoning
제목 그대로 입니다. "ArXiv papers에서 주로 사용되는 데이터 셋들은 수학 추론에 부적절하다"라고 소극적으로 주장합니다. (this conclusion should be taken with a grain of salt)
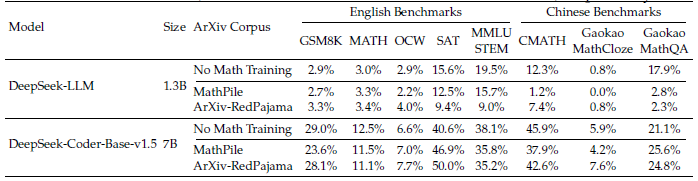
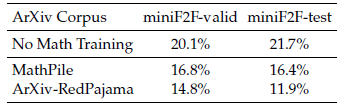
제대로 된 확인을 위해 3가지가 더 확인되어야 한다고 합니다.
- 다른 mathematical tasks
- 다른 타입의 데이터와 combined된 경우
- ArXiv papers의 장점이 더 큰 규모의 모델에서 작동하는가?
5.2 Insight of RL
다양한 Ablation Study (생략)
6. Conclusion, Limitation, and Future Work
Conclusion
- open-source중에 가장 우수하고 closed-source의 성능과 비슷한 DeepSeekMath를 제안
- 다양한 Ablation Study를 통해 public web pages를 Common Crawl해서 고품질 데이터를 확보할 수 있다는 점을 발견
- 반면 ArXiv 데이터는 예상만큼 유용하지 않을 수 있다는 점을 발견
- GRPO를 도입하여 PPO의 메모리 이슈를 해소하면서 수학적 추론 능력을 크게 향상
- unified paradigm을 제안하고 LLM의 RL 연구 방향을 제안
Limitation
- quantitative reasoning에서는 성능이 좋았지만, geometry, theorem-proof 등에서는 closed-source보다 성능이 떨어짐 (data selection bias 때문으로 추정)
- 모델 크기 제한으로 GPT-4에 비해 few-shot 성능이 떨어짐
Future Work
- 더 높은 품질의 Corpus를 구축
- 5.2.3 section에서 제시한 다양한 연구를 수행
+ PPO에 관한 설명
Surrogate Objective
policy gradient 알고리즘에서 목적함수 는 아래와 같이 표현할 수 있습니다.
만약 policy가 아주 조금만 변한다는 가정하에 를 로 대체하면 objective 를 surrogate objective 로 표현할 수 있습니다. 따라서, policy의 큰 변화를 방지하는 term을 추가하고 old policy에 관한 objective를 활용하는 것입니다.
Important Sampling
함수 의 기대값은 위의 식처럼 함수와 확률분포 곱의 합으로 표현됩니다. (이산확률분포를 따른다면 )
가운데 식에 ,를 곱해주면 우측 식이 되므로, = 로 계산할 수 있습니다.
PPO로 돌아와서, '현재 policy에서의 Advantage의 기대값'을 objective로 표현하면 아래와 같습니다.
이 식에 surrogate objective와 importatnt sampling을 반영해 표현하면 아래와 같습니다.
clipping
여기에서 surrogate objective는 policy의 과도한 업데이트를 막아야하므로, clipping이라는 테크닉이 추가됩니다.를 사이 값으로 제한한 합니다. (policy가 완전히 동일하면 1), (은 아주 작은 값) clipping term은 아래와 같이 간단히 표현합니다.
이 clipping term까지 PPO의 objective에 반영하면 최종적으로 우리가 본문에서 봤던 (1)번 식이 나오는 것을 확인할 수 있습니다.