1주차 TIL
1. 오늘 배운 개념 / 주제
- Numpy(넘파이)
- Pandas(판다스)
- 데이터 시각화
2. 핵심 내용 요약
-
Numpy -
import numpy as np
넘파이는 행렬을 만들고 다루는 데 사용되고 평균, 분산과 같은 값들을 계산할 수 있어 통계에 유용하게 쓰인다. -
Pandas -
import pandas as pd
데이터를 수정하고 가공하는 전반적인 일에 유용하게 사용되는 라이브러리이다. 넘파이를 기반으로 데이터 분석의 기본을 담당한다. -
pd.read_csv('경로')로 파일을 불러온다. -
sns.barplot으로 x축과 y축, 데이터를 지정하면 가장 직관적인 막대그래프를 그릴 수 있고,plt.figure(figsize=(,))을 통해 그래프의 크기를 결정한다.
3. 실습 / 과제 결과물
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns이 코드를 통해 필요한 라이브러리를 불러왔다.
3-1. 타이타닉 데이터를 이용해서 남녀 생존율과 등급별 생존율을 살펴보기
df['Age'] = df['Age'].fillna(df['Age'].mean())
sns.barplot(x='Sex', y='Survived', data=df)
plt.show()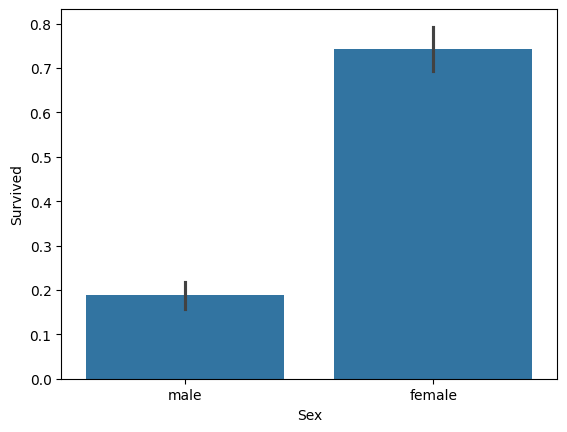
결측치를 평균값으로 대체하고 sns.barplot으로 시각화를 한 결과, 남성보다 여성이 생존율이 높다는 시각화를 얻을 수 있었다.
pclass_survivors = survivors.groupby('Pclass')['Survived'].count().reset_index()groupby를 통해 객실 등급별 생존자 수를 정확히 산출한 후 sns.barplotdm을 통해 시각화 하였다.
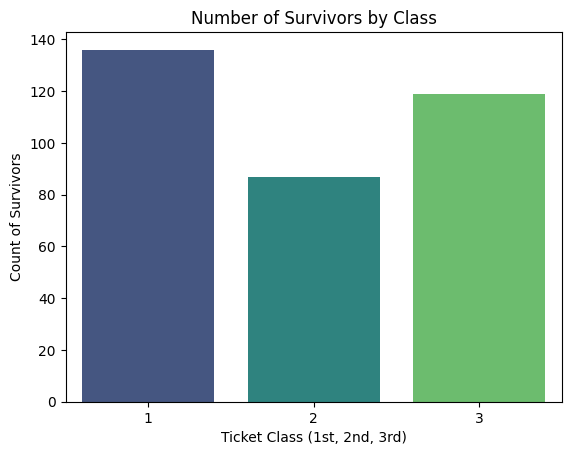
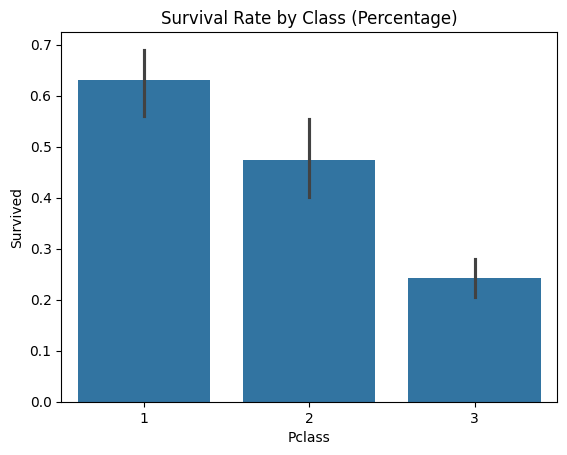
x축을 Pclass로 하고 y축을 Survived로 시각화를 한 결과, 등급이 높을수록 생존율이 높아졌다는 것을 알 수 있었다.
3-2. '경기도 수원시 행정도별 유동인구 데이터'를 이용하여 수원시 행정동별 20-24세 남성 인구 분포 살펴보기
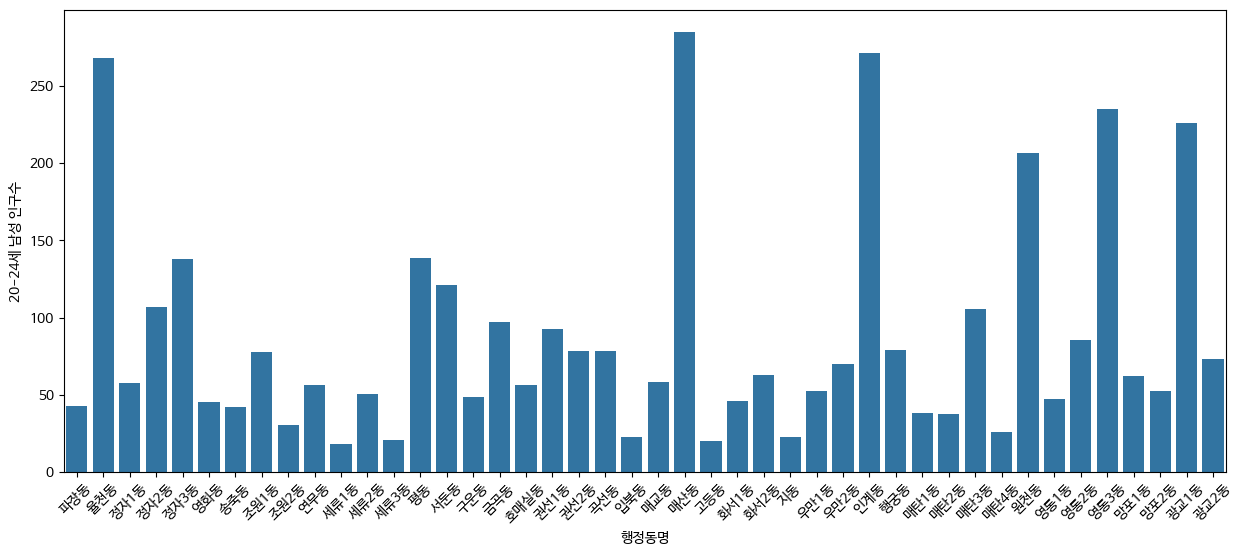
x축을 행정동명으로 설정하고 y축을 20-24세 남성 인구수로 설정하여 다음과 같은 시각화를 얻을 수 있었다.
매산동, 인계동, 율천동, 영통3동, 광교2동, 원천동 등이 20-24세 남성 인구가 월등히 높은 것을 확인할 수 있었다.
추가로 코랩에서 한글 깨짐 현상이 발생하였고 폰트를 설치 했음에도 한글이 ▢로 표시되는 현상이 나타났었지만, 런타임 세션 다시 시작을 통해 해결할 수 있었다.
4. 느낀점 / 배운점 / 다음 목표
- numpy와 pandas를 사용하면 데이터를 쉽게 전처리할 수 있다. 결측치를 쉽게 확인하고 중복 값을 쉽게 제거할 수 있다는 점 뿐만아니라 데이터를 수정하는 일에 전반적으로 사용이 가능하여 가장 중요하고 기본적인 라이브러리인 이유를 알게 되었다.
- 데이터를 전처리 하고
plt.show()를 이용해 시각화 하는 방법을 완벽하게 알게 되었다. 오늘은 기본적이고 간단한 결측치 처리만 실습하였지만, 이후에 오늘 배운 것을 바탕으로 더 복잡한 데이터의 결측치를 처리하고 전처리를 하는 방법을 정확히 알아보고 싶다. 실제 데이터는 훨씬 더 전처리가 힘들기 때문에 이번주에 배운 numpy와 pandas를 바탕으로 실습하며 배워나가야겠다.
