오늘 배운 개념 / 주제
머신러닝의 이론에 대해 학습하고 Classification 실습을 진행했다.
가상의 소개팅 데이터를 직접 만들고, 이를 바탕으로 애프터 여부(성공/실패) 를 예측하는 모델을 학습했다.
머신러닝
지도학습
분류 문제
로지스틱 회귀
결정트리
랜덤포레스트
XGBoost
핵심 내용 요약
머신러닝은 사람이 규칙을 하나하나 직접 만드는 대신, 데이터를 보고 규칙을 학습해서 결과를 예측하는 방법이다.
학습 방식은 크게 문제와 정답을 함께 제공하는 지도학습, 정답이 없는 데이터만 제공하는 비지도학습, 행동의 결과에 보상이나 벌점을 받으며 학습하는 강화학습으로 나뉜다.
모델을 학습 시키기 전에 데이터 전처리가 가장 중요하다. 이 단계에서는 학습용 데이터와 테스트용 데이터를 분리하는 과정을 거친다. 이는 overfitting을 방지하기 위한 과정으로, 보통 7:3이나 8:2로 나눈다.
모델의 종류
지도학습(회귀)
k-NN: 가까운 k개의 이웃 데이터 값을 참고해서 평균이나 가중평균으로 연속값을 예측하는 방법
선형회귀: 독립변수와 종속변수 사이의 선형 관계를 이용해 값을 예측하는 가장 기본적인 회귀 모델
다중회귀: 여러 개의 독립변수를 사용해 하나의 종속변수를 예측하는 회귀 모델
지도학습(분류)
로지스틱 회귀: 가장 기본적인 이진 분류 모델
나이브 베이즈: 각 특징이 서로 독립이라고 가정하고 확률을 계산해 클래스를 분류하는 모델
결정트리: 조건을 기준으로 데이터를 나누며 예측
랜덤포레스트: 여러 개의 결정트리를 묶어서 더 안정적으로 예측
XGBoost: 이전 모델의 오차를 보완하면서 성능을 높이는 부스팅 모델
SVM: 클래스 사이의 경계를 가장 크게 만드는 초평면을 찾아 데이터를 분류하는 모델
비지도 학습
k-means: 비슷한 데이터끼리 k개의 군집으로 묶는 클러스터링 알고리즘
PCA: 여러 변수의 차원을 줄이면서도 데이터의 중요한 정보는 최대한 유지하는 차원 축소 기법
실습 / 과제 결과물
데이터 생성
총 200명의 가짜 데이터를 만들었다.
np.random.seed(42)
n=200이 모델은 아래 4개의 변수를 만들어서 사용한다.
나이차이: -5 ~ 5
연락텀: 5 ~ 120분
MBTI점수: 30 ~ 100
티키타카지수: 1 ~ 5
데이터 분리
train data 80%, test data 20%로 분리
모델 학습
Logistic Regression
Decision Tree
Random Forest
XGBoost
위 4가지의 모델을 학습시키고 예측한 후 정확도 비교
모델 비교 결과
모델 정확도는 다음과 같다.
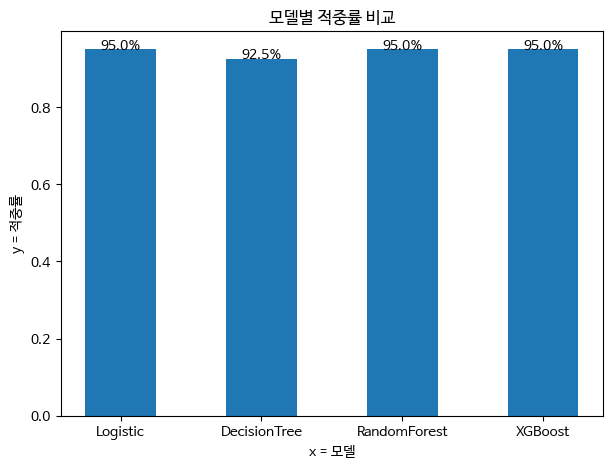
모델 정확도
Logistic Regression 95.0%
Decision Tree 92.5%
Random Forest 95.0%
XGBoost 95.0%
가장 정확도가 높은 모델은 로지스틱 회귀, 랜덤포레스트, XGBoost 이 세 가지 모델이다.
세 모델 모두 정확도 95.0% 이다.
결정트리는 92.5%로 가장 낮았지만, 큰 차이는 아니었다.
느낀 점 / 배운 점 / 다음 목표
이번 실습을 하면서 머신러닝은 단순히 모델만 돌리는 것이 아니라, 모델링 전 데이터를 준비하고 전처리 하는 과정이 중요하다는 것을 알게 되었다.
또한 각 모델 별 정확도가 조금씩 차이나는 것을 보고 정확도가 높은 적절한 모델을 선택하는 것 역시 매우 중요하다는 것을 깨달았다.
이번 실습 데이터는 내가 만든 규칙을 바탕으로 라벨을 붙였기 때문에
현실 데이터보다 예측이 훨씬 쉬웠다.
실제 데이터에서는 결측치, 이상치, 불균형 문제 등 훨씬 많은 문제가 있기 때문에 이를 해결하는 최적의 방법을 배우고 싶다.
또한 위 실습에서 어떤 변수가 모델의 예측에 가장 큰 영향을 미치는 지를 알아보고 싶다.
