
B+tree 알고리즘
B+tree 알고리즘이란?
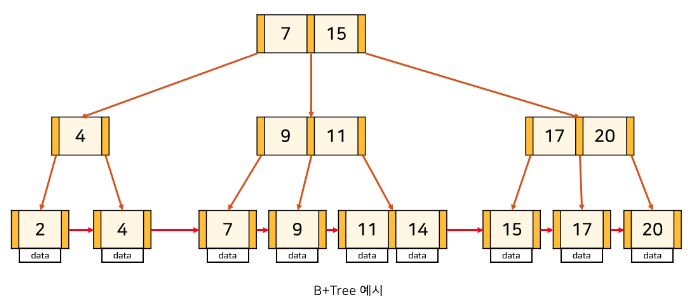
용어 정리
루트 노드(root node) : 부모가 없는 노드. 트리는 하나의 루트 노드만을 가진다.
단말 노드(leaf node) : 자식이 없는 노드이다.
형제(sibling) : 같은 부모를 가지는 노드.
특징
- 바이너리 트리와 개념적으로 비슷
- key 값으로 정렬되어 있다.
- childern 노드가 여러개이다.
- 각 노드가 메모리가 아닌 디스크에 저장한다.
- 데이터는 leaf 노드에만 있다.
- 각 노드에 sibling(형제)으로 가는 포인터가 있다.
[더 자세한 특징 설명]
리프 노드에만 데이터 저장: B+ 트리의 리프 노드에는 실제 데이터만 저장되고, 키 값은 인덱스 역할을 수행합니다. 이는 데이터베이스의 범위 검색과 정렬된 결과 반환에 유리합니다.키 값의 중복을 허용하지 않음: B+ 트리는 키 값의 중복을 허용하지 않습니다. 각 키 값은 유일해야 합니다.리프 노드 간의 연결: B+ 트리의 리프 노드는연결 리스트 형태로 연결되어 있어 범위 검색과 순차 접근에 효율적입니다.
Q) INDEX 구현시 B-tree가 아닌 B+tree 알고리즘을 사용하는가?
결론: B-Tree의 단점 때문이다.
B-Tree는 탐색을 위해서 노드를 찾아서 이동해야 한다는 단점이 있습니다.
즉, 모든 데이터를 순회하는 경우, 모든 노드를 방문해야해서 비효율적입니다.
이러한 단점을 해소하고자 B+Tree는 같은 레벨의 모든 키값들이 정렬되어 있고, 같은 레벨의 Sibiling(동기) node는 연결 리스트 형태로 이어져 있습니다.
B+tree 장단점
장점
효율적인 탐색: B+ 트리는 균형 잡힌 트리로서, 모든 리프 노드까지 도달하기 위한 경로의 길이가 동일합니다.(데이터 탐색 시간복잡도 O(log N))
범위탐색 유리: leaf 노드끼리 연결 리스트로 연결되어 있어서 범위 탐색에 매우 유리함
순차 액세스 성능: B+ 트리의 리프 노드는 연결 리스트로 구성되어 있으며,순차 액세스(Sequential Access)를 지원합니다.
단점
B-tree의 경우 최상 케이스에서는 루트에서 끝날 수 있지만, B+tree는 무조건 leaf 노드까지 내려가봐야 함
메모리 요구량: B+ 트리는 대부분의 중간 노드를 메모리에 유지해야 하므로, 메모리 요구량이 크다는 단점이 있습니다. 트리의 크기가 커질수록 메모리 사용량도 증가하므로, 메모리 제약이 있는 환경에서는 문제가 될 수 있습니다.
공간 사용 비효율성: B+ 트리는 각 노드마다 포인터와 키 값을 저장해야 합니다. 이로 인해 트리의 크기가 실제 데이터 크기보다 커지며, 디스크 공간의 낭비를 초래할 수 있습니다.
검색
전반적인 과정
- 검색의 경우에는
B-Tree와 동일하다.
1) root node부터 탐색을 시작한다.
2) node의 key를 순회하여 K가 존재하면 탐색을 종료한다.
3) k가 존재하지 않는다면, 어떤 이웃한 두 key 사이에 K가 들어가는 경우 사이의 포인터를 통해 자식 node로 내려간다.
4) leaf node까지 2~3을 반복한다.
- 14라는 key를 검색한다고 가정한다.
root node의 key를 순서대로 확인
7보다 크므로 다음 key 확인. 15보다 작으므로 사이에 있는 포인터가 가리키는 자식으로 이동
자식으로 이동한 후 key 순서대로 확인
11보다 크므로 11의 오른쪽에 있는 포인터를 통해 자식으로 이동
---- 생략 ----
5. 마찬가지로 순서대로 탐색 후 14 확인
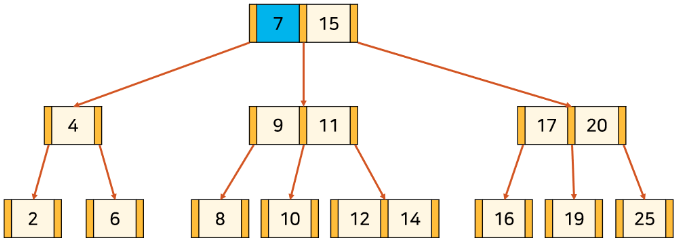
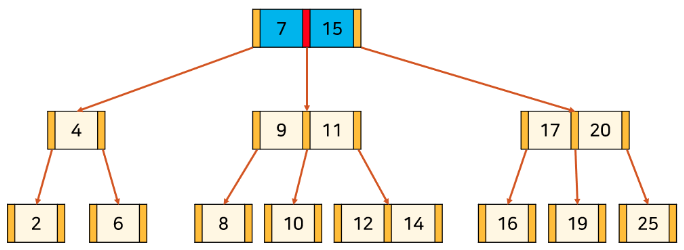
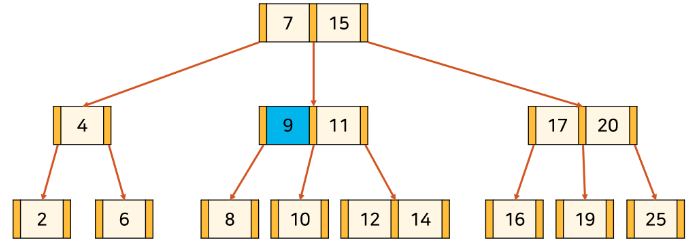
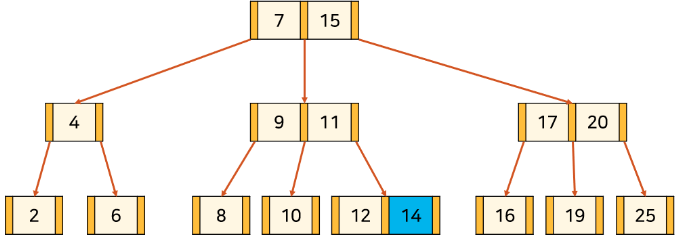
- 실제 데이터베이스에선 한
node에 매우 많은key가 포함될 수 있기 때문에, 정렬되어 있음을 이용하여binary search등으로 효과적으로 찾을 수 있다.
삽입
💡B- Tree의 삽입 과정
삽입시 규칙
- 추가는 항상 leaf 노드에 합니다.
- 추가를 할때 오름차순으로 정렬이 되도록 합니다.
- 노드가 넘치면 가운데 key를 기준으로 좌우 key들은 분할하고 가운데 key를 승진시킵니다.
삽입 1) 아래 노드에 2를 추가하고자 한다.
- 2를 추가하고 오름차순으로 정렬, 최대 2개까지이므로 3번 규칙으로 나눠줍니다.
(이때 2를 승진시키기 위해 상위에 노드를 하나 만들어주고 승진시킵니다.)


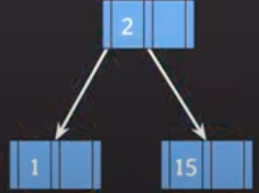
삽입 2) 위 상황에서 5를 추가하고자 한다.
- 규칙 1) leaf 노드에 추가하기 위해서
'조회'를 하게됩니다.
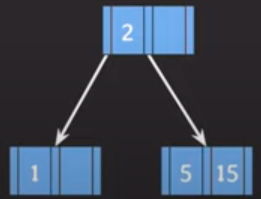
삽입 3) 위 상황에서 30을 추가하고자 한다.
- 2보다 크므로 오른쪽으로 빠지고 정렬된 상태로 추가가 됩니다
- 규칙3)에 의해서 15의 값을 위로 승진시키고, 좌우 key값을 분할해줍니다.
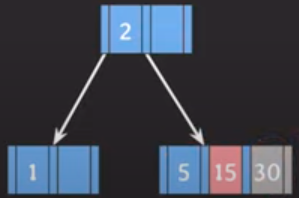

삽입 3) 위 상황에서 90을 추가하고자 한다.
- 2보다 크고, 15보다도 크니까 오른쪽 leafnode로 이동
- 빈공간이 있으므로 바로 추가해줍니다.

삽입 4) 위 상황에서 20을 추가하고자 한다.
- 2보다 크고, 15보다도 크니까 오른쪽 leafnode로 이동합니다.
- 위 상황처럼 90이 들어오고(정렬은 이루어짐) 30이 가운데 값이므로 승진시켜주고 좌우를 분할한다.
- 위 상태에서 노드가 3개이므로 분할이 필요하다.
- 가운데 값 15 승진, 좌우값 2와 30은 분할


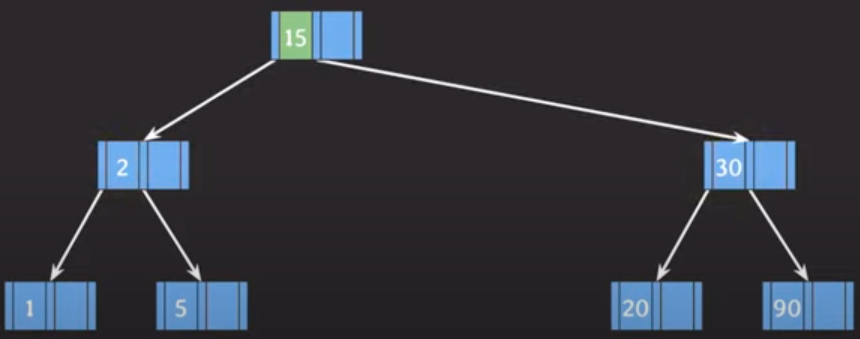
💡B- Tree의 삽입 과정
(1) key의 수가 최대보다 적은 leaf node에 삽입하는 경우
해당 node의 가장 앞이 아닌 곳에 삽입되는 경우는 단순히 삽입해 주면 된다.
하지만, leaf node의 가장 앞에 삽입되는 경우는, 해당 node를 가리키는 부모 node의 포인터의 오른쪽에 위치한 key를 K로 바꿔준다. 그리고 leaf node끼리 Linked list로 이어줘야 하므로 삽입된 key에 Linked list로 연결한다.
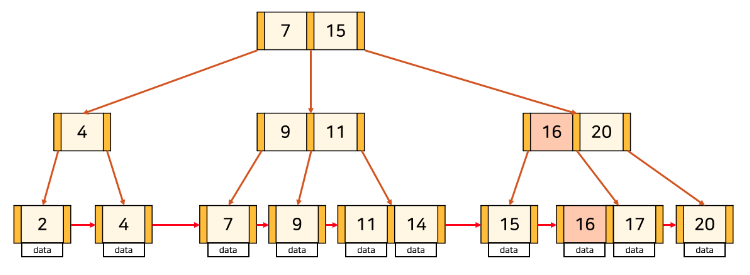
(2) key의 수가 최대인 leaf node에 삽입하는 경우
key의 수가 최대이므로 삽입하는 경우 분할을 해주어야 한다. 만약 중간 node에서 분할이 일어나는 경우는 B-Tree와 동일하게 해주면 된다.
leaf node에서 분할이 일어나는 경우는 중간 key를 부모 node로 올려주는데 이때, 오른쪽 node에 중간 key를 붙여 분할한다. 그리고 분할된 두 node를 Linked List로 연결해준다.
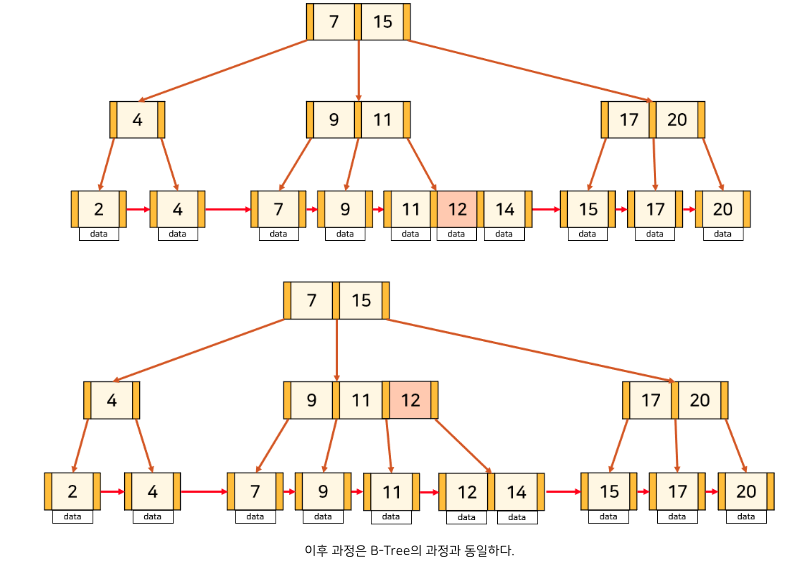
삽입하면서도 볼 수 있는데, B Tree는 모든 leaf 노드들은 같은 레벨에 있다.
즉, balanced Tree 이다.
-> 검색: 평균, 최악일때 시간복잡도가 O(log(n))
삭제
💡B- Tree의 삭제 과정
삭제시 규칙
- 삭제도 항상 leaf노드에서 발생합니다.
- 삭제 후 최소 key 수보다 적어졌다면 재조정합니다.
- B tree의 각 노드의
최소 key의 개수는 1개
- 1번이 불가능하면 부모의 지원을 받고 형제와 합칩니다.
- 2번 후 부모에 문제가 있다면 거기서 다시 재조정합니다.
삭제 1) 아래 상황에서 5를 삭제하고자 한다.
- 삭제를 해도 최소 key 1개를 만족하므로 그냥 삭제하면 됩니다.
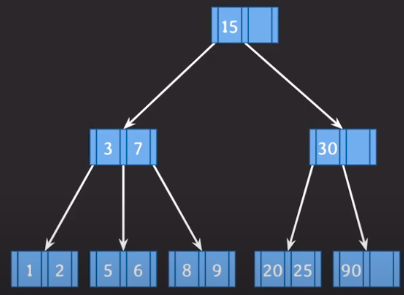
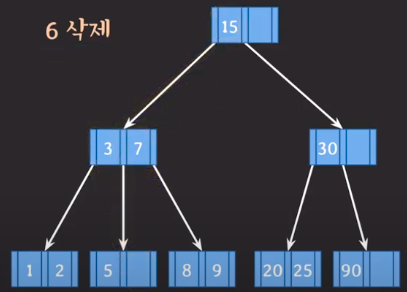
삭제 2) 위 상황에서 5를 삭제하고자 한다.
- 위처럼 삭제를 하고 났더니 최소 key 1개를 만족하지 못하므로 문제가 생긴다.
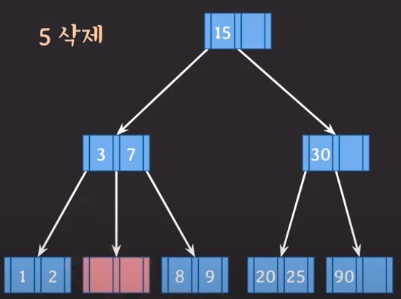
이때 해결 방안은 다음과 같다.
✅ 삭제후 최소 key보다 적어졌을 경우의 해결방안
- 삭제후 최소 key보다 적어졌다면 재조정을 한다.
- key수가 여유있는 형제의 지원을 받습니다.
- 1번이 불가능하면 부모의 지원을 받고 형제와 합칩니다.
- 2번 후 부모에 문제가 있다면 거기서 다시 재조정합니다.
문제발생에 따른 해결방안 1번을 채택
단, 2를 바로 넘겨주면 3보다 작으므로 바로 넘겨주면 안된다.
- 3을 내려주고 2를 올려주면 문제가 해결됩니다.
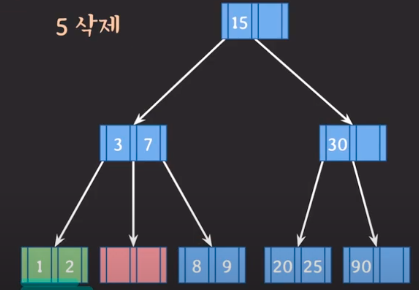
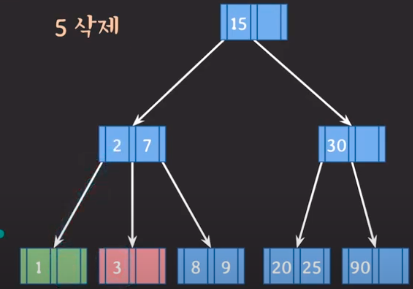
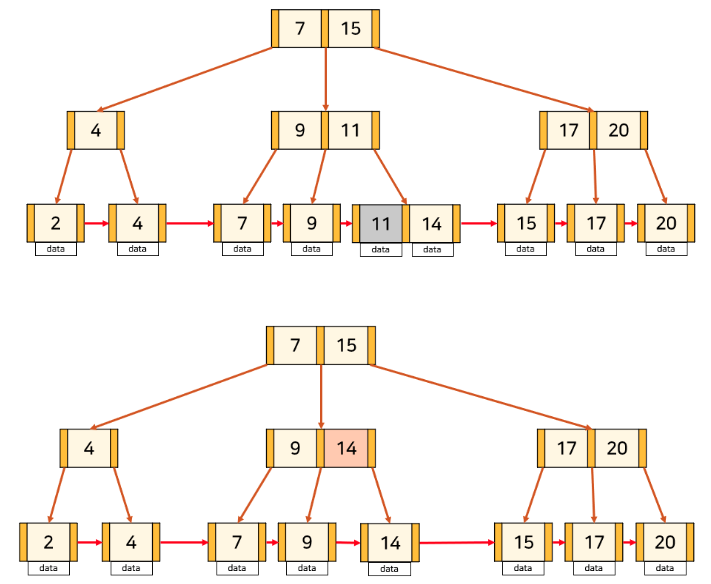
💡B+ Tree의 삭제 과정
(1) 삭제할 key가 leaf node의 가장 앞에 있지 않은 경우
B-Tree와 동일한 방법으로 삭제된다.
(2) 삭제할 key가 leaf node의 가장 앞에 위치한 경우
이 경우는 leaf node가 아닌 node에 key가 중복해서 존재한다. 따라서 해당 key를 노드보다 오른쪽에 있으면서 가장 작은 값으로 바꿔주어야 한다.
Reference & Additional Resources
