
데이터베이스 풀(Database Pool) 이란?
- 소프트웨어 응용 프로그램에서 데이터베이스 연결을 효율적으로 관리하기 위한 기술입니다.
- 즉, 매번 연결을 생성 및 해제하는 대신 미리 생성된 연결들을 풀(pool)에 저장해 두고 재사용하는 방식
- 다른말로
Connection Pool라고도 부릅니다.
데이터베이스 풀(Database Pool)의 주체는 쓰레드 풀(Thread)이다.
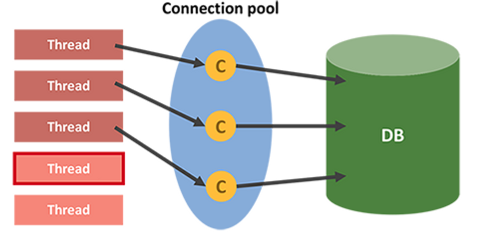
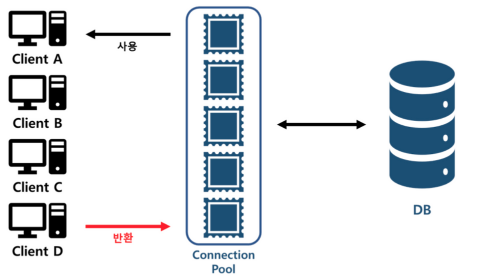
데이터베이스 풀(Database Pool) 필요한 이유?
다수의 사용자들이 동시다발적으로 데이터베이스의 연결(Connection)을 요청한다면 최악의 경우 서버가 다운될 수 있습니다.
- 일반적으로 데이터베이스 연결은 생성 및 해제하는 과정이
비용이 많이 들기때문에, 매번 연결을 생성 및 해제하는 대신 미리 생성된 연결들을 풀(pool)에 저장해 두고 재사용하는 방식을 사용합니다. - 응용 프로그램에서 데이터베이스 작업이 필요할 때마다 풀에서 연결을 가져와 사용하고, 작업이 끝나면 연결을 풀에 반환합니다.
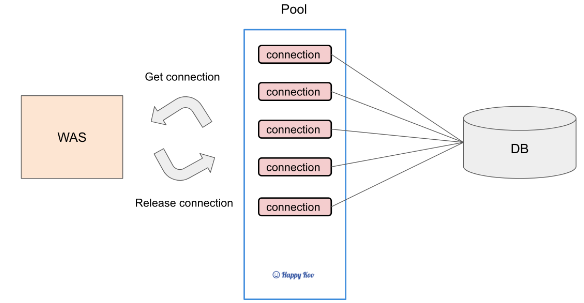
데이터베이스 풀(Database Pool) 과정
1. 서버(WAS)는 미리 DB와 일정 수의 connection을 맺은 후 connection 객체를 Pool에 저장합니다.
2. 사용자의 요청이 발생하게 되면 서버(WAS)는 Pool에 connection을 요청합니다.
3. connection을 얻은 후 쿼리를 실행하여 데이터를 read / write 합니다.
4. connection을 Pool에 반납합니다.
데이터베이스 풀(Database Pool) 장단점
데이터베이스 풀(Database Pool) 장점
- 데이터 베이스 반복적으로 생성하고 해제하는
오버헤드(OverHead)를 줄일 수 있습니다.connection 수를 제한할 수 있어서 과다한 요청으로 인한 서버의 자원 고갈을 막을 수 있습니다.- 응용 프로그램의
성능을 향상시킬 수 있습니다.- 동시에 여러 사용자가 데이터베이스에 접근하는 경우에도
효율적인 연결 관리가 가능합니다.- 데이터
처리 속도가 빨라집니다.
데이터베이스 풀(Database Pool) 단점
- 요청이 들어올 때마다 Connection을 생성한다면 속도가 느려져서 성능에 문제가 생길 수 있습니다.
- connection 객체는 메모리를 많이 사용하기 때문에 오히려 성능을 떨어뜨릴 수도 있습니다.
- 최대로 저장되는
connection 수는 정해져 있기에 많은 요청이 발생한 경우 connection이 모두 사용 중이라면 반납될 때까지 대기해야합니다.
Q) 데이터베이스 풀(Database Pool)이 커지면 성능이 좋아질까?
그렇지 않다. Connection의 주체는 Thread이므로 Thread와 함께 고려해야합니다.
Thread Pool & Connection Pool
- Thread Pool
- 비슷한 맥락으로 Thread pool이라는 개념도 있다.
- 이 역시 매 요청마다 요청을 처리할 Thread를 만드는것이 아닌, 미리 생성한 pool 내의 Thread를 소멸시키지 않고 재사용하여 효율적으로 자원을 활용하는 기법이다.- CASE1) Thread Pool 크기 < Connection Pool 크기
:Thread Pool에서 트랜잭션을 처리하는 Thread가 사용하는 Connection 외에 남는 Connection은 실질적으로 메모리 공간만 차지하게 됩니다.
- CASE2) Thread Pool 크기와 Connection Pool 모두 크기 증가
: Thread 증가로 인해 더 많은Context Switching이 발생합니다.- Disk 경합 측면에서
성능 한계가 발생합니다.
: 데이터베이스는 하드 디스크 하나 당 하나의 I/O를 처리하므로 블로킹이 발생합니다.
즉, 특정 시점부터는 성능적인 증가가 Disk 병목으로 인해 미비해집니다.
- Disk 경합 측면에서
- CASE1) Thread Pool 크기 < Connection Pool 크기
✅ Thread Pool 수 가 Connection Pool 수 보다 많은게 좋다.
- 모든 요청이 DB에 접근하는 요청이 아니니까 (즉, 모든 Thread가 DB에 접근하는 요청이 아닐 수 있다.)
Reference & Additional Resources

의미있는 성장의 태도, 긍정적인 사고를 지닌 Deveolper