논문 주제
대형 언어 모델(LLM, Large Language Models)을 활용한 자동 침투 테스트(Automated Penetration Testing)의 평가 및 실용화
목표
직접 해보기..
화욜까지 해볼거임..!!!!!!!!!!!
논문의 Motivation
- Pentest에서 LLM의 포괄적인 평가에는 벤치마크가 필요함
- 기존 벤치마크에는 제한 사항 존재
- OWASP juiceshop 프로젝트는 웹 취약점 평가를 위해 가낭 널리 알려짐 근데 pentest의 핵심인 권한 상승 취약점은 포함되어 있지 않음!
- 기존 벤치마크는 최종 익스플로잇 성공만을 평가하는 경향이 있음, 그래서 침투 테스트의 여러 단계를 거치는 동안의 진행 가치(과정으로 이해함)을 인식 못 할 수 있음 - 그래서! 이 논문에서는 작업 다양성, 챌린지 레벨, 진행 상황 추척 이렇게 세 가지의 기준을 충족하는 벤치마크를 구성함
침투 테스트(Pentest)란
- 조직 시스템의 보안을 강화하기 위한 중요한 과정
- 일반적으로 보안 전문가가 자동화된 도구를 활용하여 대상 시스템을 분석
- 표준 프로세스 : 정찰 - 스캔 - 취약점 평가 - 익스플로잇 - 보고서
- 일반적으로 테스터는 깊이 우선 탐색 및 너비 우선 탐색 기술을 결합함
- 대상 환경의 범위를 파악한 다음 특점 취약점으로 드릴 다운!
PentestGPT란
- Pentest에서 LLM의 적용을 향상시키기 위해 설계된 대화영 시스템
- Reasoning, Generation 및 Parsing Module로 구성된 3자 아키텍처가 있음
- Reasoning Module은 리드 테스터의 기능을 에뮬레이트하여 침투 테스트 상태에 대한 높은 수준의 개요를 유지하는 데 중점을 둠
- Generation Module은 특정 하위 작업에 대한 자세한 절하를 구성하는 역할을 담당한다.
- Parsing Module은 도구 출력, 소스 코드 및 HTTP 웹 페이지와 같이 침투 테스트 중에 발생하는 다양한 텍스트 데이터를 처리한다.
- 선임 테스터와 주니어 테스터 간의 협업 역학을 반영하는 3자 설계를 통합
Lead Tester란!
침투 테스트 팀에서 팀장 역할을 하는 사람이다. 전체적인 공격 전략을 수립하고, 어떤 작업을 언제 할지 결정한다.
에뮬레이트(Emulate)란!
어떤 것의 기능이나 역할을 모방하는 것이다. 이 논문에서는 LLM이 리드 테스트처럼 행동하도록 설계했다는 의미이다.
Pentesting Task Tree(PTT)란
테스트 프로세스의 진행 중인 상태를 인코딩하고 후속 작업을 안내한다. 이 표현은 자연어로 번역되어 LLM에 의해 해석될 수 있으므로 Generation Module에서 이해하고 테스트 절차를 지시한다.
이 논문에서 한 것
포괄적인 침투 테스트 벤치마크 개발 -> 공정하고 포괄적인 평가를 제공
벤치마크 설계
작업 선택
- 벤치마크가 실제 침투 테스트 환경에서 발생하는 문제를 정확하게 반영하도록 설계
- OWASP Top 10 Project에 나열된 모든 취약점을 포괄적으로 다루는 하위 집합을 식별하고 선택하기 위해 두 플랫폼에서 사용 가능한 최신 시스템을 꼼꼼하게 검토
- 침투 테스트 도메인의 기존 표준에 따라 쉬움, 중간, 어려움 범주로 분류된 다양한 난이도를 나타내는 시스템을 선택
작업 분해
- 각 대상의 테스트 프로세스를 침투 테스트에서 일반적으로 "워크스루"라고 하는 표준 솔루션에 따라 일련의 하위 작업으로 추가로 구문 분석
- 보안 테스트 기술 가이드인 NIST 800-115에 따라 하위 작업을 분해
벤치마크 유효성 검사
- 벤치마크 개발의 마지막 단계는 이러한 벤치마크 시스템의 재현성을 보장하는 엄격한 유효성 검사를 포함
-> 이를 위해 세 명의 인증된 침투 테스터가 독립적으로 침투 테스트 대상을 시도하고 워크스루를 작성
따라서
OWASP Top 10 Project에 나열된 모든 유형의 취약점을 효과적으로 포괄하는 벤치마크를 컴파일했다!
여기에는 다양한 난이도의 13개의 침투 테스트 대상이 포함된다.
연구 질문
RQ1 (Capability): LLM은 어느 정도까지 침투 테스트 작업을 수행할 수 있습니까?
RQ2 (Comparative Analysis): 인간 침투 테스터와 LLM의 문제 해결 전략은 어떻게 다릅니까?
LLM은 text 기반이고 독립적으로 작업을 수행할 수 없음!!!!!!!!이를 해결하기 위해 LLM의 기능을 정확하게 평가하기 위한 방법으로 human-in-the-loop 테스트 전략으로 개발! 이건 사람이 LLM의 침투 테스트 지시를 실행하는 대화형 루프를 특징으로 한다.
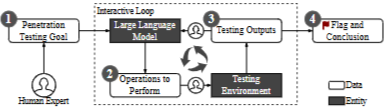
테스트 전략을 보여주는 그림이다. 순서대로
❶ LLM에 대상 세부 정보를 제시하여 잠재적인 침투 테스트 단계에 대한 지침을 구하여 루프 테스트 절차를 시작한다.
❷ 전문가는 LLM의 권장 사항을 엄격히 따르고 침투 테스트 환경에서 제안된 작업을 수행한.
❸ 테스트 작업의 결과가 수집 및 요약된다. 터미널 출력 또는 소스 코드와 같은 직접 텍스트 출력이 문서화된다. 그래픽 표현과 같은 비텍스트 결과는 인간 전문가가 간결한 텍스트 요약으로 변환한다. 그런 다음 데이터가 LLM으로 다시 피드되어 후속 권장 사항을 설정한다.
❹ 이 반복 프로세스는 결정적인 솔루션이 식별되거나 교착 상태에 도달할 때까지 지속된다. 그런 다음 성공적인 하위 작업, 비효율적인 작업 및 해당되는 경우 실패 이유를 포함하여 테스트 절차 기록을 컴파일한다.
이쯤 읽었을 때 내 생각.. 걍 유효한 벤치마크 데이터셋 마련해서 llm이 시키는대로 pentest 전문가가 자아없이 pentesting하는 거 아닌가..?
일반인이 아닌 pentest 전문가가 llm이 하라는대로 하는 이유는 llm이 생성한 작업을 정확하게 이해하고 수행할 수 있으니까~ 그리고 오류를 발견해도 정보나 컨텐츠를 변경하지 않고 llm이 제공하는 명령을 엄격히 실행한다.(왜지) 그리고 이 결과를 그대로 llm에게 보고한다. 그리고 burp suite 사용을 지양한다(아니 pentest인데 진짜 왜지) 읽어보니 도구 쓰면 전문가의 자아가 강해져서 llm이 시키는 대로 안 할 수도 있으니까..
RQ1. LLM은 어느정도까지 pentest를 할 수 있을까?
LLM은 end-to-end 침투 테스트 작업을 수행하는 데 능숙하지만, 더 어려운 대상이 제시하는 문제를 극복하는 데 어려움을 겪음
- nmap같은 일반적인 침투 테스트 도구를 능숙하게 활용함.
- 일반적인 취약점 유형에 대한 깊은 이해를 보여주고 이를 대상 시스템의 서비스에 연결함
- 코드 분석 및 셸 구성 작업에서 강함
RQ2. 침수테스트 전문가와 LLM의 차이
실제 침투 테스트에서는 brute force가 비효율적인데, LLM은 이것부터 냅다 함.
LLM은 SQL Injection, command injection 시도하는 것을 권장함
LLM이 실패한 경우..
- 주요한 이유는 세션 컨텍스트 손실! = 모델이 이전 테스트 결과에 대한 인식을 까먹음
즉! LLM은 장기적인 세션을 유지하는데 어려움을 겪어서, 취약점을 연결하고 익스플로잇하는 데 어려움을 겪음 - LLM은 깊이 우선 탐색 방식을 선호함
- 최근 대화내용을 강조함
- 부정확한 결과, 할루시네이션 문제가 있음
이런 문제들을 해결하도록 설계된 것이 바로 PentestGPT!
핵심 전략
pentest를 1.다음 작업 식별과 2.작업을 완료하기 위한 작업 생성 이렇게 두 개로 나눔. 각 프로세스는 하나의 LLM 세션으로 구동된다. 1.작업식별을 담당하는 LLM세션은 진행 중인 침투 테스트 상태의 전체 컨텍스트를 유지한다.
사용자의 입력에 맞는 프롬프트 설계는 Chain-of-Thought(CoT) 방법론을 활용함.
Chain-of-Thought란 결과로 이어지는 일련의 중간 자연어 추론 단계
성능
- PentestGPT-4는 GPT-4에 비해 중간 난이도 목표를 하나 더 해결하고 하위 작업을 더 많이 달성함
- 더 어려운 난이도의 목표는 pentester의 깊은 이해를 요구하는데, 이를 위한 LLM의 취약점 시직을 확장하진 앟음
전략 평가
- PentestGPT는 전문가와 유사하게 작업을 분해하고 효과적으로 우선순위를 지정함
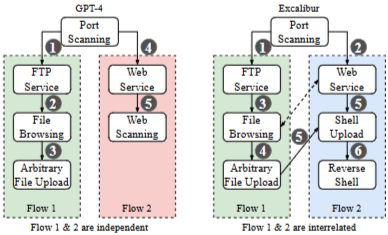
GPT-4가 FTP 서비스로 시작하여 업로드 취약점을 식별하는 것을 보여준다. 근데 웹 서비스와 연결하지 않아서 exploit이 불확실함.
반대로 pentestGPT는 FTP와 웹 서비스 사이를 전환한다. - 근데 여전히 인간이 적용하지 않을 전략 일부를 나타내긴함(brute force!)
- 이미지 해석은 어려워함
- 사회 공학적 기술 사용은 잘 못함
- 모델의 제한된 횟수의 시도 내에서 정확한 exploit 코드 작성에 어려움이 있음
실용성
- Hack The Box
- CTF
이렇게 두개로 증명함. HTB에서는 쉬운 난이도~중간 난인도를 대상으로.
CTF에서는 루트 플래그 획득을 목표로
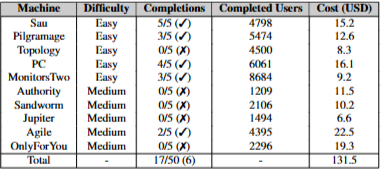
HTB에서 pentestGTP의 성능을 보여주는 표이다. HTB에서는 쉬운 난이도 4개와 중간난이도 1개의 챌린지를 성공함.
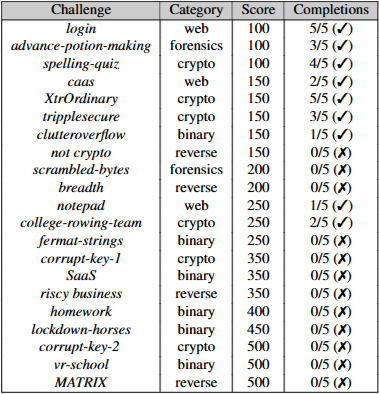
CTF에서 pentestGPT의 성능을 보여주는 표임
21개의 챌린지 중에서 9개 해결함.
