scikit-learn model selection 모듈
Model Selection 모듈
학습 데이터와 테스트 데이터 세트를 분리하고, 교차 검증 분할 및 평가, 그리고 Estimator의 하이퍼 파라미터를 튜닝하기 위한 다양한 함수와 클래스를 제공한다.
train_test_split()
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.3, randomstate=121)교차 검증
test 데이터에만 평가를 치중해서 할때, 해당 테스트 데이터에만 과적합되는 학습 모델이 만들어져 다른 테스트용 데이터가 들어올 경우 성능이 저하되서, 정확도가 떨어지게 된다. 교차검증은 이러한 Overfitting(과적합)에 취약한 약점을 극복하기 위해서 제시된 방법이다
간단히 설명하자면, 테스트 데이터 세트를 학습하기전 (본고사를 치르기전)
검증 데이터 세트를 반복해서 학습하는 것 (모의고사를 치는것)
k fold
: k 개의 데이터 폴드 세트를 만들어서 그 만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법
전체 데이터 셋에서 k=5일때의 경우를 생각해보자
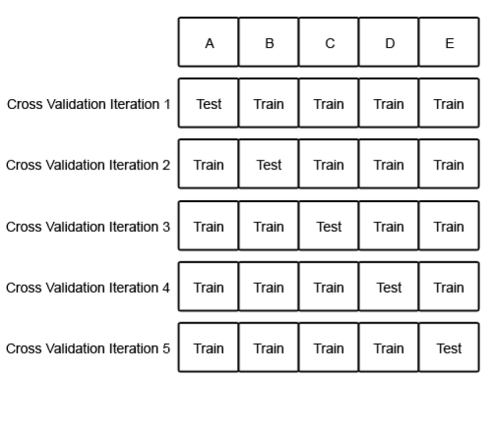
전체 데이터 셋에서 5개로 분할을 한뒤 한구역을 Test 나머지는 Train 영역으로 하고 5번 반복하면서 전부분을 교차적으로 Test하고 있다.
이와 같이 5번 학습한 평가 결과로 정확도의 값을 평균값을 매겨서 평가를 내린다
K - FOLD 교차 검증의 구현
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassfier(random_state=156)
#5개의 폴드세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성
kfold = KFold(n_splits=5)
cv_accuracy = []
print('iris dataset size : ', features.shpae[0])
n_iter = 0
#KFold 객체의 split()을 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 array로 반환
for train_index, test_index in kfold.split(features):
#kfold.split()으로 반환된 인덱스를 이용해 학습용, 검증용 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습 및 예측
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
#반복시마다 정확도 측정
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_train.shape[0]
Stratified K 폴드
: 불균형한 분포도를 가진 레이블 데이터 집합을 위한 k 폴드 방식

DEVELOPE_FRESHMAN