1. 영속성 컨텍스트
1-1. 엔티티 등록 - 트랜잭션을 지원하는 쓰기 지연
EntityManager em = emf.createEntityManager();
EntityTransaction ts = em.getTransaction();
ts.begin(); // 트랜잭션 시작
em.persist(memberA);
em.persist(memberB);
// 여기까지 InsertSQL을 데이터베이스에 보내지 않는다.
// 커밋하는 순간 데이터베이스에 Insert SQL을 보낸다 즉 flush()가 발생
ts.commit(); // 트랜잭션 커밋1-2. 엔티티 수정 - 변경감지(Dirty Checking)
EntityManager em = emf.createEntityManager();
EntityTransaction ts = em.getTransaction();
ts.begin(); // 트랜잭션 시작
// 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
// 엔티티 데이터 수정
memberA.setUsername("admin");
memberA.setAge(20);
// em.update(memberA); 이런 코드는 없다.
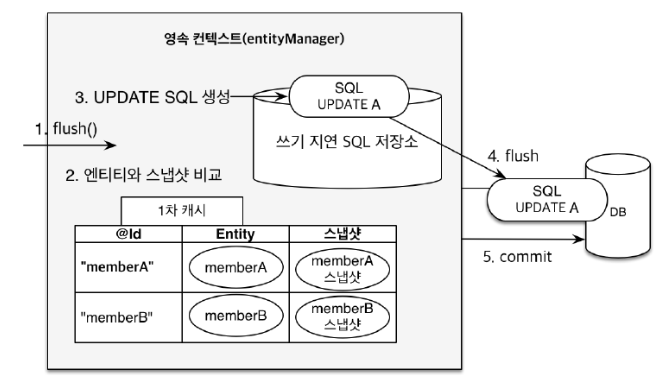
ts.commit(); // 트랜잭션 커밋-> flush() 가 호출되는 시점에 Entity와 스냅샷을 전부 비교 후(최적화 된 알고리즘으로 진행)변경이 된것을 감시(Dirty Checking)한 후에 update 쿼리를 작성 후, update쿼리를 날린다.
캐시에 Entity이외에 스냅샷(사본같은 개념)에 있는 데이터와 비교하여 값이 다를 경우 쓰기지연 SQL저장소에 자동으로 update를 날려줌
1-3. 엔티티 삭제
// 삭제 대상 엔티티 조회
Member memberA = em.find(member.class, "memberA");
em.remove(memberA);저번 포스팅의 복기파트로 보면 된다.
2. 플러시(flush)
2-1. 플러시 발생
- 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영
- 변경감지
- 수정된 엔티티 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL저장소의 쿼리를 데이터베이스에 전송
(등록, 수정, 삭제 쿼리)
2-2. 영속성 컨텍스트를 플러시 하는 방법
- 트랜잭션 커밋 -> 플러시 자동 호출
- em.flush() -> 직접호출
- jpql 쿼리 실행 -> 플러시 자동 호출
jpql 쿼리 실행은 이번 포스팅에는 언급하지않는다.
2-3. 플러시 주요 사항
- 영속성 컨텍스트를 비우지 않음
- 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화
- 트랜잭션이라는 작업 단위가 중요 -> 커밋 직전에만 동기화 하면 됨
- JPA는 동시성, 데이터를 맞추거나 등을 모두 트랜잭션에 위임한다.
2-4. 준영속 상태
- 영속상태 -> 준영속 상태
- 준영속 : 영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)
- 영속성 컨텍스트가 제공하는 기능을 사용하지 못함
2-5. 준영속 상태로 만드는 방법(알아만 둘것)
- em.detach(entity);
: 특정 엔티티만 준영속 상태로 전환 - em.clear();
: 영속성 컨텍스트를 완전히 초기화 - em.close();
: 영속성 컨텍스를 종료
3. 엔티티 매핑 소개
- 객체와 테이블 매핑 : @Entity, @Table
- 필드와 컬럼 매핑 : @Column
- 기본 키 매핑 : @Id( Id = 컬럼 이름)
- 연관관계 매핑 : @ManyToOne, @JoinColumn (ManyToOne이 중요)
3-1. 객체와 테이블 매핑 - @Entity
- @Entity가 붙은 클래스는 JPA가 관리하는 엔티티라 한다.
- JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수
-> 기본 생성자 필수(파라미터가 없는 Public 또는 protected 생성자)
-> final 클래스, euum, interface, inner 클래스 사용 불가
-> 저장할 필드 final 사용x
3-2. @Entity 속성 정리
- 속성 : name
-> JPA에서 사용할 엔티티 이름을 지정
-> 기본값 : 클래스 이름을 그대로 사용한다.
-> 같은 클래스 이름 없으면 가급적 기본값 사용하는걸 지향한다.
3-3. @Table
- 엔티티와 매핑할 테이블 지정
- name : 매핑할 테이블 이름(엔티티 이름을 사용)
- catalog : 데이터 베이스 catalog매핑
- schema : 데이터베이스 schema 매핑
- uniqueConstraints : DDL 생성시에 유니크 제약 조건 생성
4. 데이터베이스 스키마 자동생성
-
hibernate.hbm2ddl.auto <- xml파일에 넣는 문구
- create : 기존 테이블 삭제 후 다시 생성(Drop + Create)
- create-drop : create와 같으나 종료 시점에 Drop
- update : 변경문만 반영(운영 DB에는 사용하면 안됨)
- validate : 엔티티와 테이블이 정상 매핑되었는지만 확인
- none : 사용하지 않음
=> 데이터베이스 방언별로 달라진다. -
운영 장비에는 절대 create, create-drop, update 사용하면 안됨
-
개발 초기 단계는 create 또는 update
-
테스트 서버는 update 또는 validate
-
스테이징과 운영 서버는 validate 또는 none을 주로 사용한다.
5. DDL 생성 기능
-
제약조건 추가 : 회원 이름은 필수, 10자 초과 x
-> @Column(nullable==false, length=10) -
유니크 제약 조건 추가
-> @Table(uniqueConstraints={
@UniqueConstraint(
name="NAME_AGE_UNIQUE",
columnNames={"NAME","AGE"}
)
})
=> DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다.
6. 필드와 컬럼 매핑
- @Column : 컬럼 매핑
- @Temporal : 날짜 타입 매핑
- @Enumerated : enum 타입 매핑
- @Lob : BLOB, CLOB 매핑
- @Transient : 특정 필드를 컬럼에 매핑하지 않음 (매핑 무시)
@Transient은 자바안에서만 만들고, DB에는 쿼리문을 날리지 않는 말그대로 test용 더미 컬럼으로 보면 된다.
7. @Column
- name : 필드와 매핑할 테이블의 컬럼 이름
- nullable : null값의 허용 여부를 설정한다. false로 설정하면 DDL 생성시에 not null 제약조건이 붙는다
- unique : @Table uniqueConstraints 와 같지만 한 컬럼에 간단히 유니크 제약 조건을 걸 때 사용한다.
- length : 문자 길이 제약조건, String 타입에만 사용
@Entity
@Getter @Setter
public class Team {
@Id @Column(name="TEAM_ID")
@GeneratedValue
private Long id;
private String name;
}id를 pk로 설정하고, 해당 클래스에서는 id라고 변수이름을 설정 하였지만 DB에 insert할 경우 TAEM_ID로 값이 저장되는 어노테이션을 선언해주는모습, @GeneratedValue는 serquence를 만드는 어노테이션이다.
8. 기본키 매핑 방법
- 직접 할당하는 방법 : @Id 만 사용
- 자동 생성 방법 : @GeneratedValue -> 전략
-> IDENTITY
: 데이터베이스에 위임, MYSQL, SQL Server, DB2
-> SEQUENCE
: 데이터베이스 시퀀스 오브젝트 사용, ORACLE, PostgreSQL, DB2, H2
@SequenceGenerator 필요
-> TABLE
: 키 생성용 테이블 사용, 모든 DB에서 사용
@TableGenerator 필요
-> AUTO
: 방언에 따라 자동지정, 기본값
-> AUTO는 DB방언에 맞춰서 IDENTITY, SEQEUNCE, TABLE 3개의 방식중 하나가 선택이 된다.
9. @SequenceGenerator
- name : 식별자 생성기 이름 , name은 generator로 자바단에서 매핑이 된다.
- sequenceName : 데이터베이스에 등록되어 있는 시퀀스 이름
- initialValue : DDL생성 시에만 사용됨, 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정한다.(기본값 1)
- allocationSize : 시퀀스 한 번 호출에 증가하는 수(데이터베이스 시퀀스 값이 하나씩 증가하도록 설정되어 있으면 이 값을 반드시 1로 설정해야 한다. 기본값 = 50)
- catalog, schema : 데이터 베이스 catalog, schema(오라클을 쓰는 단계에서는 신경쓸 필요 가 없음, MySQL경우 DataBase(schema)생성을 하도록 한다. (오라클에서는 XE가 스키마))
10. TABLE 전략 -> 사용 빈도가 낮음
- 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀀스를 흉내내는 전략
- 장점 : 모든 데이터베이스에 적용가능
- 단점 : 효율이 낮음
11. 연관관계 매핑 기초
- 객체와 테이블 연관관계의 차이를 이해
- 객체의 참조와 테이블의 외래키를 매핑
- 용어 이해
-> 방향(Direction) : 단방향, 양방향
-> 다중성(Multiplicity) : 다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(N:M)
-> 연관관계의 주인(Owner): 객체 양방향 연관관계는 관리 주인이 필요
12. 단방향 연관관계
- 일방적으로 한 방향으로만 조인이 가능한 상태
두 개의 객체 테이블을 만들 경우, DB에서는 외래키 선언을 통한 두 테이블간에 data값을 join하고, 그 값을 불러올 수 있다.
그러나 자바단에서는 외래키 선언을 하기 위해서는 @ManyToOne이라는 어노테이션을 지정해야 외래키 지정을 할 수있다. 또한 한 객체에만 선언하면 다른 객체에서는 해당 키값을 이용해 매핑을 할 수 없다.
즉, 한 테이블에서는 가능하지만 다른 테이블에서는 조인할 수 없는 상태를 단방향 연관 관계라 할 수 있다.
결론은 DB에서는 외래키 설정을 하면 기본적으로 양방향 성격을 띄지만 자바에서는 경우에 따라서 단방향이란걸 인지해야 한다.
