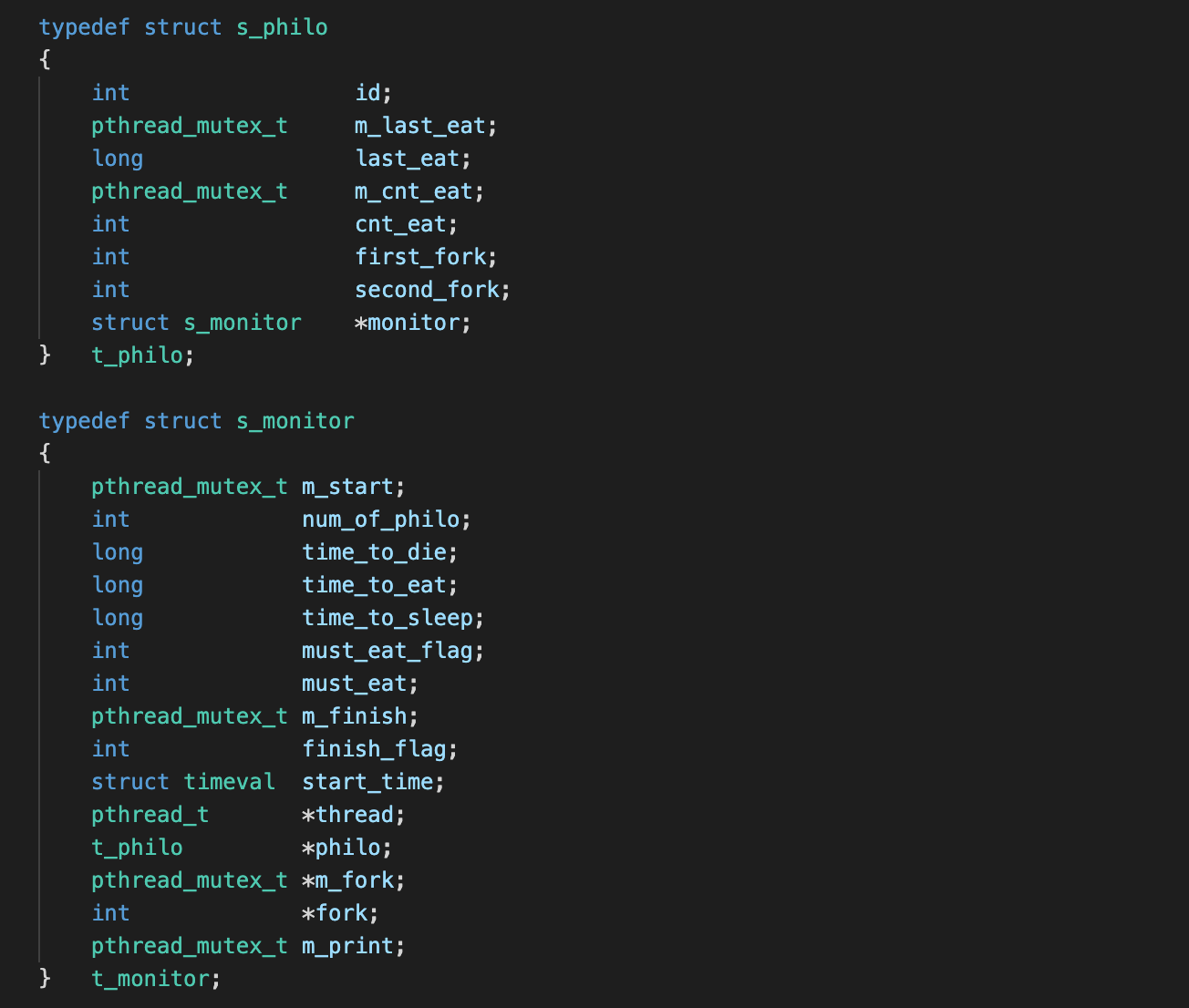
기본적인 흐름 설계
- main 흐름은 모든 철학자에 대해 monitoring을 할 수 있도록 한다.
- 각 스레드는 철학자를 의미한다.
따라서 각 스레드는 철학자가 해야할 routine을 진행한다.
Mutex는 언제 써야할까?
Mutex는 Data race를 방지하기 위해 사용한다.
Data race란?
프로그램의 실행 결과가 일정하지 않고, 실행 순서에 영향을 받는 상태
운이 좋게 코드가 정상적으로 실행되기도 하고 나쁘면 잘못된 결과가 나오기도 한다.
ex) 스레드A와 B가 있는 프로세스가 있고, 해당 프로세스의 공유자원 x가 0으로 초기화되어 있었다고 가정해보자.
- 스레드 A가 하는 일 : x를 1 증가시킨다.
- 스레드 B가 하는 일 : x를 2 증가시킨다.
우리가 원하는 프로세스의 결과는 x가 3이 되는 것일 것이다.
성공 case 1
1. A : 공유자원 x 값 읽어오기
2. A : x += 1
3. B : 공유자원 x 값 읽어오기 (A의 결과가 반영된 값을 읽어오게 됨)
4. B : x += 2
=> x = 3
성공 case 2
1. B : 공유자원 x 값 읽어오기
2. B : x += 2
3. A : 공유자원 x 값 읽어오기 (B의 결과가 반영된 값을 읽어오게 됨)
4. A : x += 1
=> x = 3
실패 case 1
1. B : 공유자원 x 값 읽어오기
2. A : 공유자원 x 값 읽어오기
3. B : x += 2
4. A : x += 1
=> x = 1
실패 case 2
1. B : 공유자원 x 값 읽어오기
2. A : 공유자원 x 값 읽어오기
3. A : x += 1
4. B : x += 2
=> x = 2
따라서 우리는 Mutex를 통해 값을 동기화 시켜주어야 한다.
즉, 해당 공유 자원에 접근 하는 동안에는 다른 스레드에서 이 값을 읽거나 쓰지 못하도록 점유함으로써 data race를 방지 !
구조체 구축하기
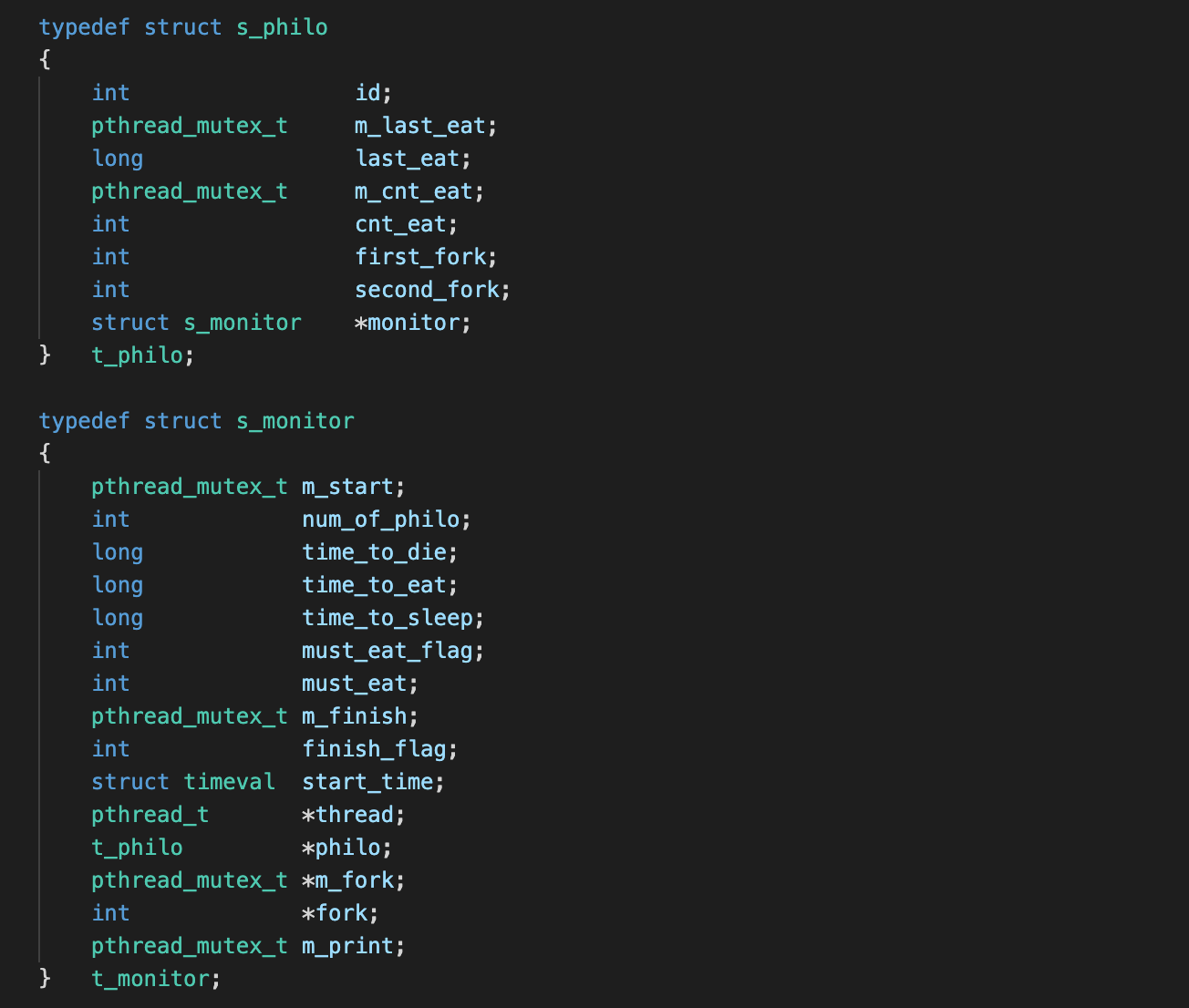
t_monitor
monitoring을 하는 스레드에서 사용하기 위한 구조체
- m_start
스레드(철학자)를 생성해주자마자 routine을 진행하기 보다는 모든 철학자가 생성된 이후에 본격적으로 다들 routine을 진행하도록 구현하는 것이 타당하다고 판단하여 만들어준 mutex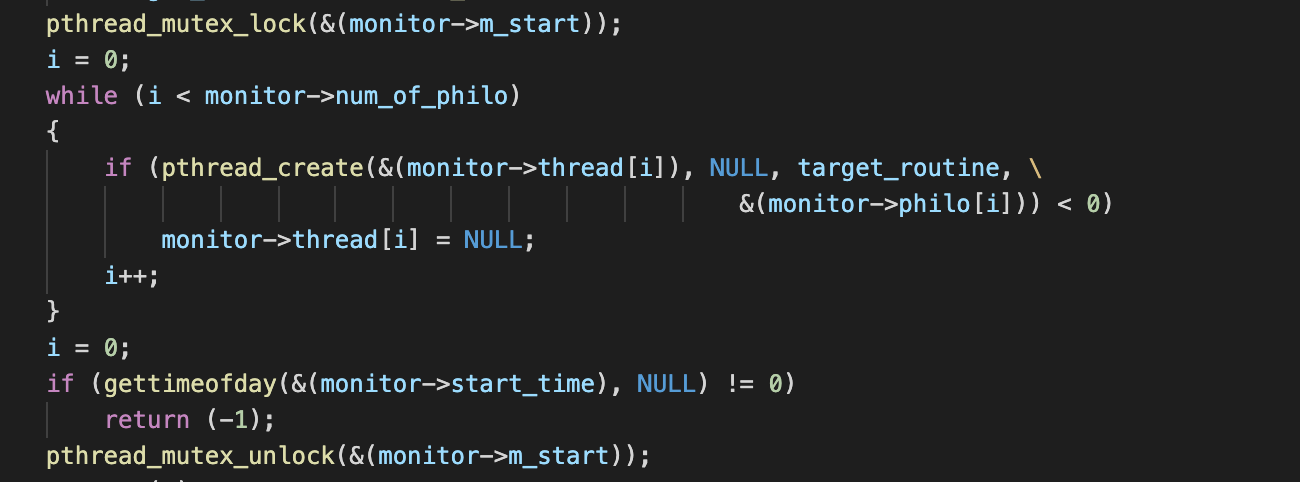 main에서는 스레드 생성 전에 lock을 해주고, 스레드를 모두 생성 및 시작 시점 측정 뒤 unlock을 해준다.
main에서는 스레드 생성 전에 lock을 해주고, 스레드를 모두 생성 및 시작 시점 측정 뒤 unlock을 해준다.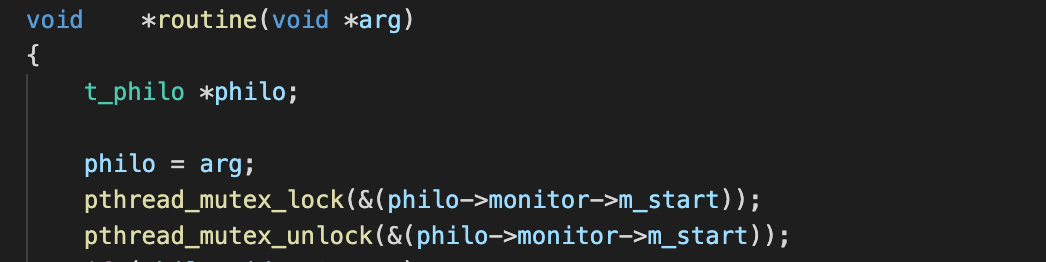 모든 스레드는 처음 처음에 m_start를 lock을 하도록 하여 모든 스레드가 생성될 때까지 waiting을 할 수 있다. 다른 스레드들도 바로 시작할 수 있도록 lock을 잡은 뒤 바로 unlock !
모든 스레드는 처음 처음에 m_start를 lock을 하도록 하여 모든 스레드가 생성될 때까지 waiting을 할 수 있다. 다른 스레드들도 바로 시작할 수 있도록 lock을 잡은 뒤 바로 unlock ! - num_of_philo
철학자 수 - time_to_die
각 철학자가 굶주림으로 죽는 시간 - time_to_eat
철학자가 한 번 먹는데 걸리는 시간 - time_to_sleep
철학자가 자는데 걸리는 시간 - must_eat_flag
인자의 개수에 따라 must_eat으로 인한 종료 조건을 체크해야 하는지 여부를 저장 - must_eat
must_eat을 체크해야 하는 테스트 케이스인 경우 먹어야 하는 횟수를 저장num_of_philo, time_to_die 등의 변수가 mutex가 아닌 이유?
이 변수들도 공유 자원이고, 다른 스레드에서 이 변수에 접근하는 것은 맞지만 모든 스레드들이 READ만 진행하므로 동시에 접근한다고 해도 문제가 되지 않음 ! - m_finish
finish_flag를 보호하기 위한 Mutex
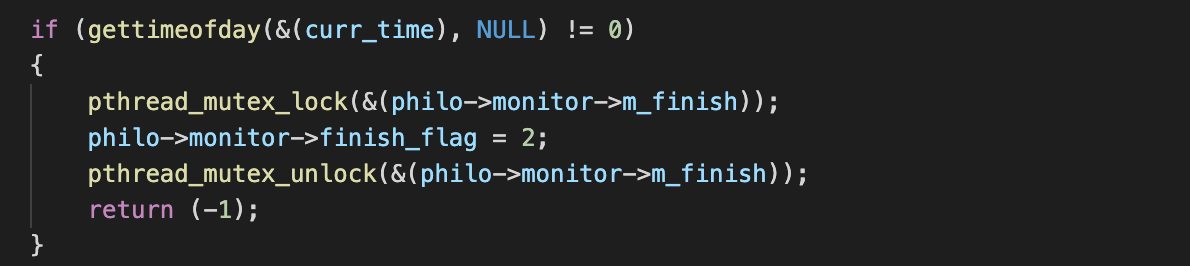
- finish_flag
철학자가 한 명 이상 죽었거나, must_eat 횟수만큼 모든 철학자가 먹었다면 finish flag를 세우고, 이 변수를 통해 스레드가 종료 시점을 파악한다. - start_time
프로그램의 시작 시각을 저장 - thread
각 thread들의 식별자를 저장하는 배열 - philo
각 철학자(스레드)들에 대한 정보를 구조체 배열로 저장 - m_fork
fork 배열의 각 원소를 보호하기 위한 mutex 배열
mutex m_fork[i]는 fork[i]를 보호한다. - fork
포크의 점유 여부를 저장fork가 결국 0 아니면 1의 상태로 점유 여부가 저장되므로 m_fork를 그 자체로 fork로 쓰는 경우도 있다.
- m_print
스레드에서 상태변화를 출력할 때 출력 문구가 서로 겹치지 않도록 하기 위한 mutex
t_philo
- id
철학자의 고유 id - m_last_eat
last_eat 변수를 보호하기 위한 mutex
모니터링 스레드에서 해당 철학자가 죽었는지 판단(READ)을 하는 것과 routine을 진행하면서 last_eat 정보가 덮어써지는(WRITE) 작업에서 data race가 일어날 수 있으므로 mutex를 사용해야 함 - last_eat
철학자가 마지막으로 식사를 한 시각
이 시각은 먹기 시작한 시각으로 저장 - m_cnt_eat
cnt_eat 변수를 보호하기 위한 mutex - cnt_eat
철학자가 밥을 먹은 횟수 - first_fork, second_fork
포크가 배열로 저장되어 있으므로, 철학자의 id에 따라 first_fork와 second_fork의 포크 index가 몇 인지 저장
- monitor
monitor 구조체에 대한 포인터
m_start, finish_flag 등의 변수를 사용해야 하므로 이 변수를 가지고 있어야 함
fsanitize=thread -g 옵션으로 data race check 가능하다 !
처음 코드를 작성했을 때부터 완전한 설계가 되어 있었던 것은 아니고
코드를 구현하다가 data race가 발생하고 있는지 여부를 확인하고 필요한 mutex를 하나씩 추가해주면서 구조체를 구축하였다.
🦋 Philosophers repo address
https://github.com/kyj93790/42-cursus/tree/master/Philosophers
