혼자 만들어보는 Zara - 메뉴 크롤링
1. 기존의 조회 방식
데이터베이스안에 메뉴 데이터가 있다는 가정하에, 메뉴 테이블에 넣을 데이터는
아래와 같았습니다.

WOMAN부터 JOIN LIFE까지 DB에 있다면 메뉴 리스트를 프론트에 뿌려줄때
def get(self, request) :
menu_list = [{'id' : menu.id, 'name' : menu.name} for menu in Menu.objects.all()]
return JsonResponse({'menu_list' : menu_list}, status=200)이렇게 됩니다.
하지만 이걸 크롤링으로 가져올 수 있을까? 라는 생각이 들어 크롤링하는 방법부터
찾아보게 되었습니다.
2. Zara 크롤링
크롤링을 위해 필요한 라이브러리가 있습니다.
pip install requests
pip install bs4requests는 카카오 로그인할 때 사용했었는데, http 요청을 쉽게 보내기 위해
사용하는 라이브러리입니다.
카카오할때, 프론트엔드로부터 받은 토큰으로 카카오에 유저정보를 달라고 요청할 때
requests에 카카오 디벨로퍼에 적혀진 URL과 토큰을 넘겼습니다.
bs4는 HTML문서를 분석할 수 있는 라이브러리이며, 이걸 통해 태그에 쉽게 접근하고
데이터를 추출할 수 있습니다.
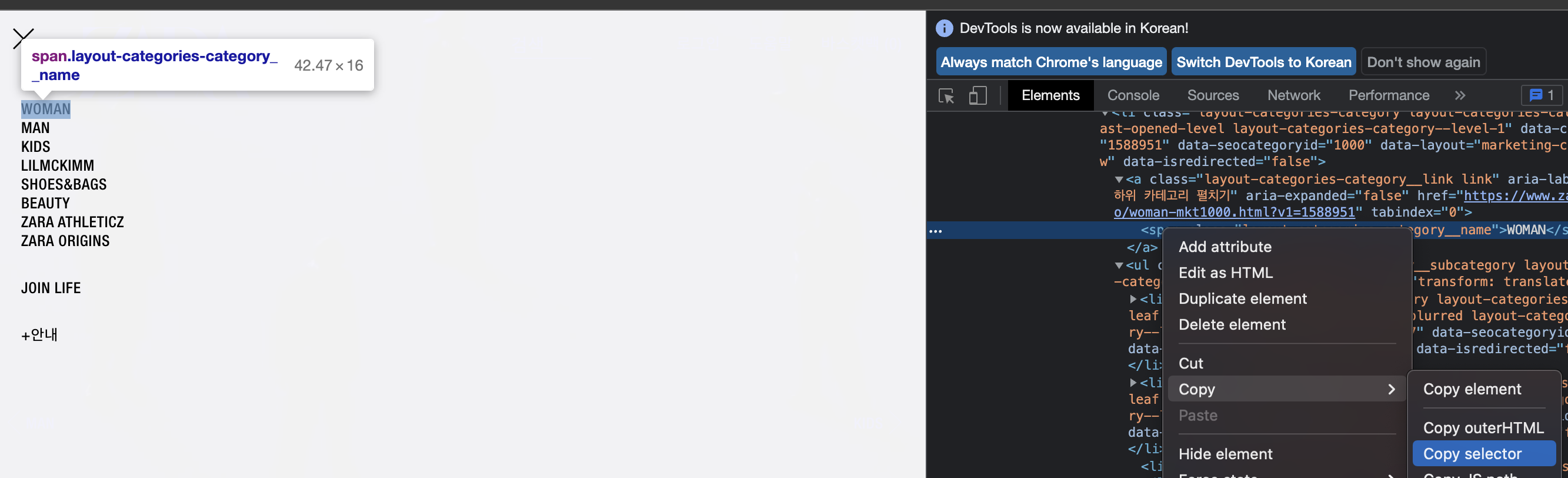
우선 홈페이지의 WOMAN 부분을 가져와보려고 했습니다.
WOMAN 부분의 Elements를 우클릭하여 Copy selector를 합니다.
이후 코드를 작성해보면
def get(self, request) :
req = requests.get('https://www.zara.com/kr/')
html = req.text
soup = BeautifulSoup(html, 'html.parser)
info = soup.select('#sidebar > div > nav > div > ul > li.layout-categories-category.layout-categories-category--opened.layout-categories-category--level-1 > a > span')이렇게 되고 복사한 셀렉터를 info에 넣어줍니다.
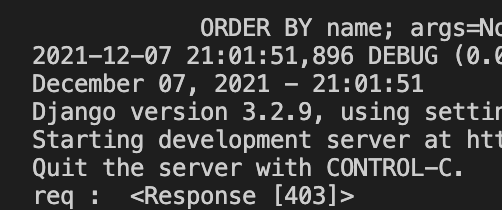
실행했더니 아무것도 안나와서 각 변수를 print로 찍어봤습니다.
그런데 requests를 이용해 요청보냈더니 Forbidden 403을 받아왔습니다.
자라에서는 크롤링 못 하게 막았습니다.
아쉽게도 네이버 검색을 이용해 크롤링해보는거로 해야 할 것 같습니다.
3. 네이버 검색 크롤링
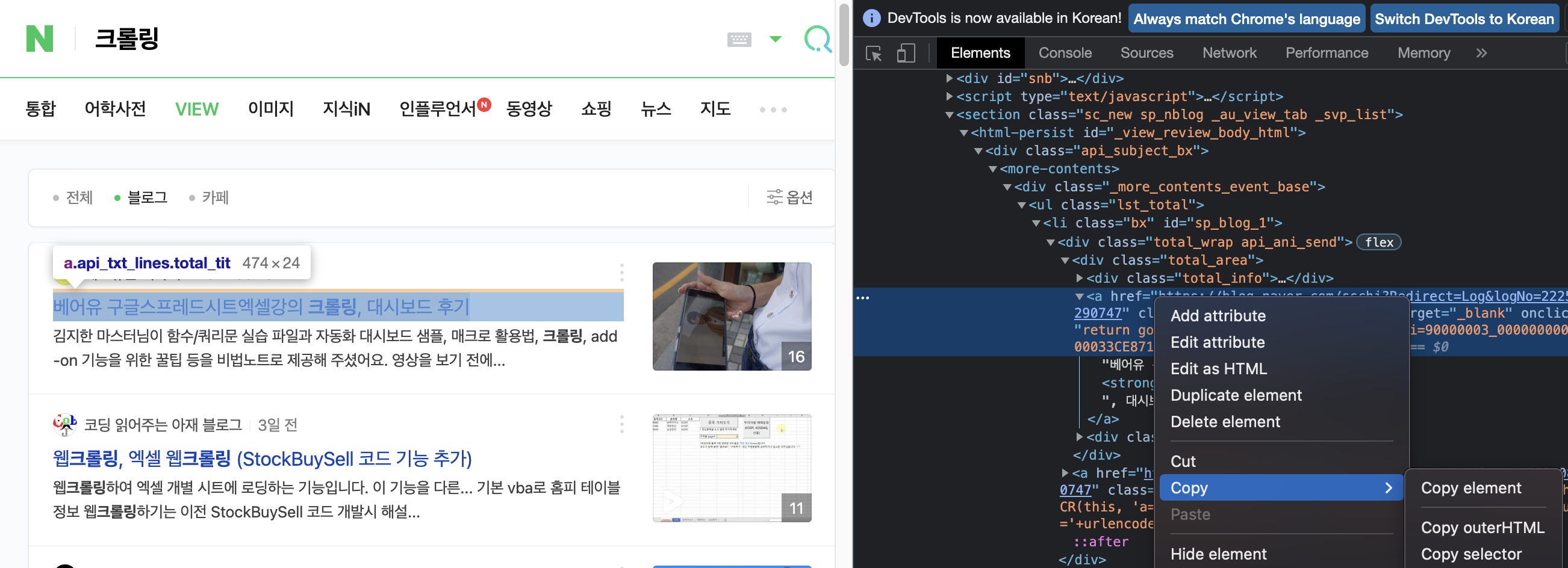
네이버에서 크롤링 검색 후, 오른쪽에서 셀렉터를 복사해옵니다.
def get(self, request) :
req = requests.get('https://search.naver.com/search.naver?query=%ED%81%AC%EB%A1%A4%EB%A7%81&nso=&where=blog&sm=tab_viw.all')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
title = soup.select('#sp_blog_1 > div > div > a')
print('*'*20, title)
for i in title :
print('*'*20, 'i :', i)
print('*'*20, 'i.text :', i.text)
크롤링을 통해 가져오는 데이터는 항상 리스트형태입니다.
그래서 직접 접근하려면 반복문을 돌려야 되기 때문에, 각각 어떤형태인지 찍어봤습니다.
soup.select에서 blog_1 만 선택되어 하나만 나오고 blog 묶음들이 있는
최상위를 선택하여 크롤링하면 반복문을 돌려서 제목만 추출할 수 있습니다.
원래 이번이 상품추가였는데, 크롤링때문에 다음으로 미뤄지게 되었습니다
