2차 프로젝트 회고록
2차 프로젝트 회고록의 전반적인 내용은 여기서 보실 수 있습니다
마지막 주 수요일부터 몸이 굉장히 안 좋아서 수, 목은 거의 죽만 먹고 지냈습니다.
몸관리를 못 한 아쉬움이 들었던 이번 프로젝트를 하며,
단순히 내가 어떤 걸 구현했다가 아닌, 2주동안 느낀 점을 쓰려고 합니다.
회고록이라는 거창한 이름을 쓰기에는 부족한 점이 많습니다.
0. Team RIDIBOOKSL 소개
프론트엔드 Git링크
백엔드 Git링크
팀 트렐로 링크
프론트엔드 : 김수민, 김용현, 박세연, 이나영
백엔드 : 이기용(PM), 이정아
1. 1주차
1-1. 역할분담
프론트엔드 역할분담
김수민 : 상세페이지
김용현 : 카카오 로그인, 카테고리 페이지
박세연 : 메인페이지
이나영 : 책 리스트 및 실시간 알림
백엔드 역할분담
이기용 : 카카오 로그인, 작가 및 책 검색, 구독 및 취소, AWS EC2 & RDS배포,
faker Library를 이용한 데이터 생성 및 전체 DB 관리
이정아 : 메인 페이지/특정 카테고리 리스트 조회, 상세페이지 조회
1-2. Scrum & Trello
프로젝트 진행방식은 Scrum 방식을 따랐습니다.
Scrum
- 1~4주 단위의 개발주기를 설정하여, 각 주기마다 실제 동작할 수 있는 결과를 제공하는 개발 방식
- 작은 목표를 짧은 주기마다 설정하여, 점진적으로 개발
Trello
트렐로의 경우, 제가 1차때 했던 방식을 이번에도 팀원들에게 제시했습니다.
다행히 팀원들 모두 제 의견에 동의해주어서 아래와 같이 나눠지게 되었습니다.

1-3. 마음가짐
일단 재미있겠다라는 건 1차 때와 변함없었습니다.
1차 때 팀을 이끌었던 경험을 토대로, 2차 때는 더 잘 이끌 자신이 있었습니다.
다만, 이번엔 하드코딩보다는 외부 자원들을 많이 이용해보자라는 목표가 있었습니다.
1-4. 프로젝트 시작
시작하면서, 걱정되는건 마이그레이션 꼬여서 DB 날리는 것 말고는 없었습니다.
이상하게 한 번 성공적으로 끝마치니, 자신감이 정말 하늘을 찌르는.. 상태였습니다.
다만, 자신감이 넘쳐서 할 수 있다였지, 절대 자만심이라던가 얕보는 건 아니었습니다
덕분에 회의를 이끌때도 어떻게 진행해야 되는지 아니까 진행순서에 맞게 진행되었고
1차 때 못했던 프론트엔드와 함께 DB설계도 할 수 있었습니다.
2. 2주차
2-1. Unit Test
이번 프로젝트의 가장 큰 복병이었습니다.
Git Rebase의 경우, 이게 왜 필요한지 알게 된 다음 사용해보면서 익혔는데
단위테스트는 너무 헷갈렸습니다.
특히, 세션때 멘토님께서 여기에 views.py 로직짜는 사람있는데 그러는거 아닙니다
라고 하셨던 말씀때문에 이걸 어떻게 하라는걸까.. 라는 생각이 들었습니다.
그런데, 계속 테스트코드를 작성해보고 돌려보며 테스트 코드 작성에 대해 깨달았습니다.
이건 단위테스트 깨닫고나서 너무 기뻐가지고 담당 멘토님께 보낸 DM ㅎㅎ

특히 목요일에는 최종 Merge가 되어야 했는데, 같은 팀원이 정아님께서
약 8개의 테스트코드를 작성해야 하는 상황이 었습니다.
정아님께서 아직 단위테스트에 대한 이해가 잘 안되었다고 저에게 말씀해주셨고,
상황이 급해서 제가 정아님께 테스트코드를 설명해주면서 작성하게 되었습니다.
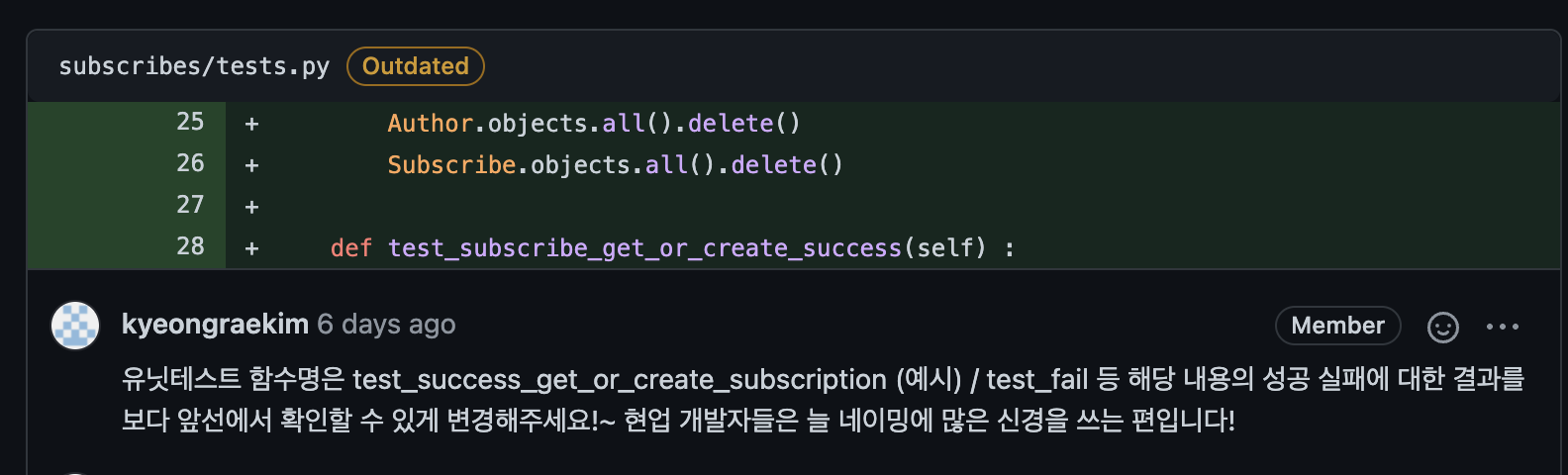
그리고 테스트를 하며 받은 피드백이 꽤 많았는데
첫 번째로, 테스트의 함수명은 성공/실패 결과를 앞에 기술하여 확인할 수 있게 하는 것
두 번째로 데이터를 임의로 for문 돌려서 만드는 게 아닌, 직접 생성하는 것
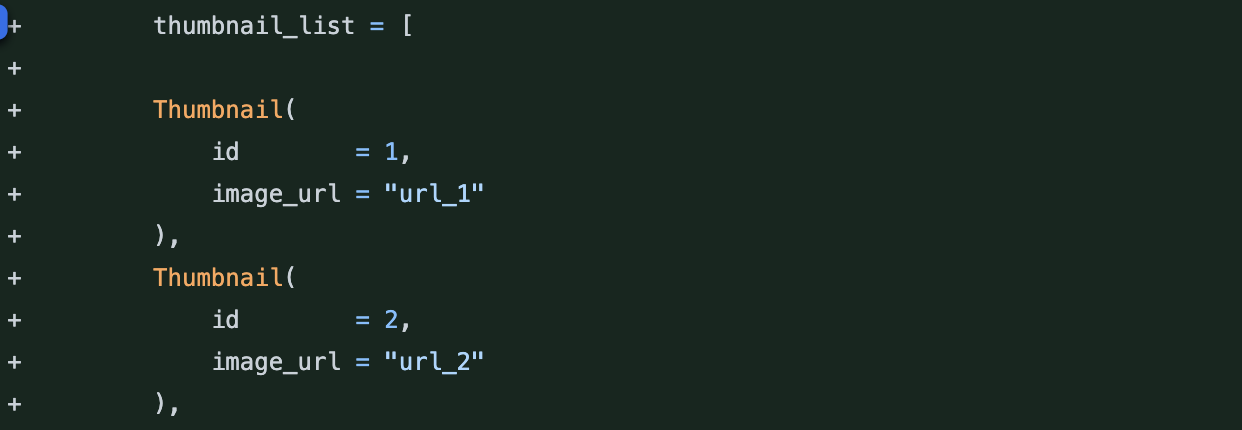
마지막으로, 생성할 때 데이터마다 값의 차이를 두어 조금 더 명확하게 하는 것

이 세가지에 피드백을 통해 단위테스트에 대해 조금 더 이해할 수 있게 되었습니다.
2-2. 프로젝트 종료
이번에 저는 외부 소스를 사용해 쓰다보니, 특별히 연동할 게 없었고
정아님께서 프론트엔드와 연동할 부분이 많았습니다.
다행히 정아님께서 잘 구현해주셔서, 그리고 1차 때와 달리 틈틈히 프론트엔드와
변수 맞추고 연동한 덕에 에러 없이 무사히 끝날 수 있었습니다.
2-3. 마무리
1차 때는 0에서 시작하는 느낌이라면, 이번엔 50정도에서 시작하는 느낌이었습니다.
그래서 1차 때는 힘든만큼 서로 의지 하며 으쌰으쌰하는 일꾼들이었다면
2차 때는 진짜 개발자가 되어, 필요한 부분에 대해 이야기할 줄 아는 모습들이었습니다.
특히, 아까도 제가 언급했듯이 이번에는 코더보다 개발자스러운 사람이 되는 것이
이번 프로젝트의 목표였는데, 유능한 팀원들덕에 그 모습에 더 가까워지지 않았나 싶습니다.
그리고, 위코드에서 강조했던 함께 일하고 싶은 개발자가 되었나? 라는 물음을
스스로에게 던져봤습니다.
그 질문은 생각보다 쉽게(?) 답을 얻을 수 있었습니다.
2차 프로젝트가 끝난 뒤, 다른 팀원분들과도 수고했다는 이야기와 함께 여러 이야기들을
나눌 수 있었습니다.
그 때마다 다른 분들께서 저와 함께 팀 해보고 싶었다고 해주시거나,
두 번의 프로젝트동안 PM하시는 걸 보고 정말 대단하다고 해주시거나,
어떤 분은 저에게 동기지만 나중에 정말 잘 될거 같다고 해주시는 등
제가 부족한 실력임에도 좋은 덕담들을 너무 너무 많이해주셔서
적어도 위코드에서 2달은 내가 많이 성장했구나라는 걸 느꼈습니다.
소심했던 성격이기도 하고, 때론 자존감이나 자신감이 없던적이 많았는데
25기 동기분들덕에 자신감도 많이 얻을 수 있었습니다.
이대로 자만하거나, 다른 길로 세지 않고 더 좋은 사람이 되고,
더 좋은 개발자가 되어야 겠다는 마음가짐을 하게 된 좋은 시간이었습니다.
3. 구현 사항
코드를 다 올리는 건 비효율적이라고 생각하여, 필요한 코드만 기입하였습니다.
3-1. Kakao Login
카카오 로그인의 경우, 이전 글에 포스팅을 한 내용이어서 해당 문서로 대체하겠습니다.
3-2. get_or_create를 이용한 코드 간소화
이전에 코드 작성할 때는, 데이터가 있을 경우 없을 경우를 아래처럼 나누었습니다.
좋아요의 예를 들면
if Like.objects.filter(email=email).exists() :
Like.objects.filter(email=email).delete()
return jsonresponse({'message':'좋아요 취소'}, status=201)
#DB에 좋아요를 한 기록이 없으면 생성
Like.objects.create(..)이러한 형태로 Like라는 모델에 3번 접근하게 되는 비효율적인 코드였는데
subscribe, state = Subscribe.objects.get_or_create(
author_id = author_id,
user_id = request.user.id
)
if not state :
subscribe.delete()
return JsonResponse({'message' : 'delete success'}, status=201)get_or_create를 사용함으로써,
모델에 한 번 접근하여 원하는 결과를 얻어낼 수 있게 되는 것입니다.
3-3. icontains를 이용한 필터링
장고에서 SQL의 LIKE와 같은 기능을 하는 contains/icontains 사용입니다.
다만, 저는 대소문자 구분을 하지 않기 위해 icontains를 사용하였습니다.
아래 이미지는 실제 리디북스 홈페이지에서 검색 할 때 입니다.
특정 키워드가 들어간 작가와 책이 함께 검색됩니다.
'e'를 입력하면 소문자에 대해서만 결과가 나오는 것이 아닌 대문자도 나오게 됩니다.
그래서 icontains 사용해야겠다는 생각을 했습니다.
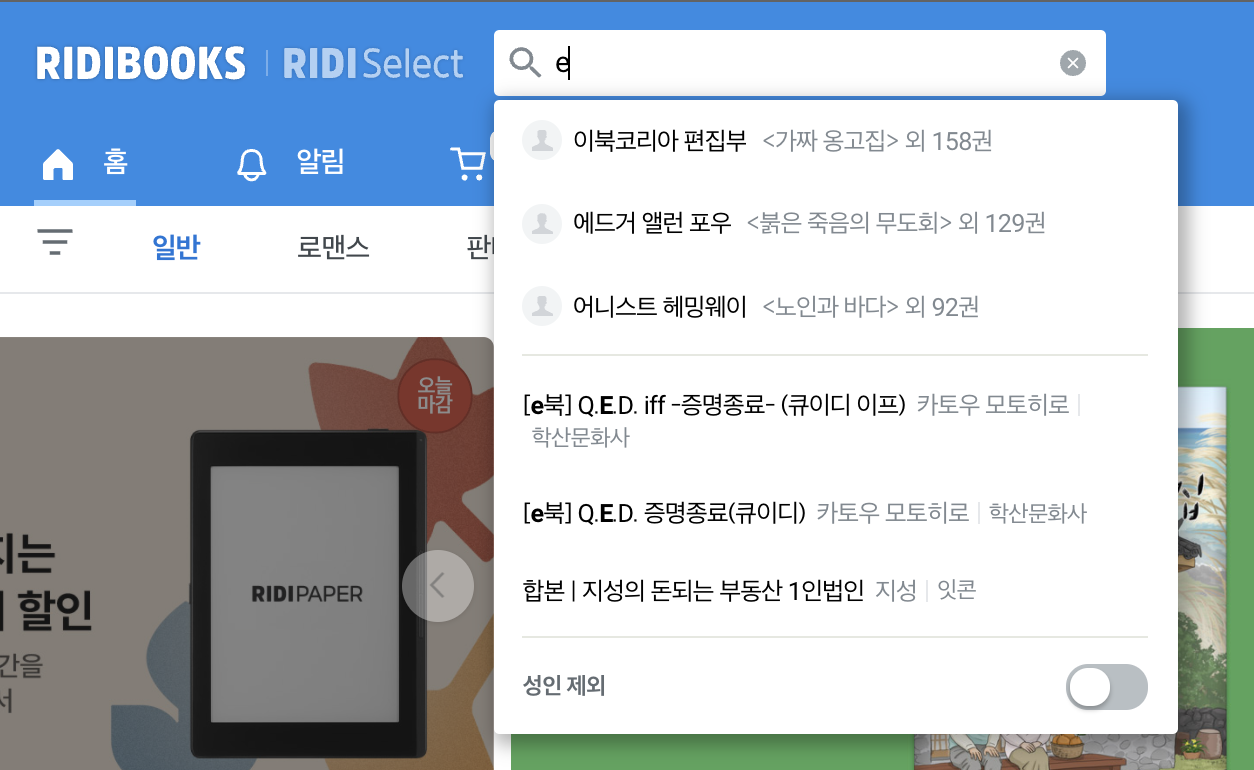
프론트엔드에서 검색창에 입력된 걸 keyword란 변수에 담아
Query Parameter로 보내주면 그걸 받아서 작가와 책에 해당하는 데이터가 있는지
필터링해주는 코드입니다.
keyword = request.GET.get('keyword')
...
for author in Author.objects.filter(name__icontains=keyword)
for book in Book.objects.filter(main_name__icontains=keyword)3-4. faker libray
1,2차 모두 크롤링을 하면 지적재산권에 문제가 있을 수 있으니,
faker 라이브러리를 이용하여 데이터를 생성해보라고 하셨습니다.
1차 때 csv파일을 이용해 업로드를 해봤기때문에, 이번에는 라이브러리를 이용했습니다.
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", 'ridibooksl.settings')
django.setup()
from faker import Faker
from datetime import date, datetime, timedelta
from users.models import User
from products.models import Book, Rating, ViewCount
from django.db import transaction
fake = Faker()
with transaction.atomic() :
Rating.objects.bulk_create([Rating(book_id=1, user_id=1, rating=fake.pyint(min_value=1, max_value=5)) for _ in range(30)])아래 더 많은 줄이 있지만 적용사례 한 줄만 가져왔습니다.
다 같은 형태로 생성했기 때문입니다.
우선 무작정 데이터를 넣는 게 아닌, DJANGO_SETTINGS_MODULE 기본값을
디폴트로 설정해준뒤, django.setup()을 해줘야 합니다.
그 다음 faker라이브러리를 import하고 작성하면 되는데,
여러개의 데이터를 한꺼번에 만들다보니, 트랜잭션을 설정하였습니다.
Rating은 별점에 대한 클래스인데, 특정 유저가 특정 책에 별점을 주면 저장하는 용도입니다.
별점의 경우 1~5점까지 랜덤생성을 위해 faker 라이브러리의 pyint라는 이용하여
최소, 최대값을 설정한 다음 bulk_create를 해주었습니다.
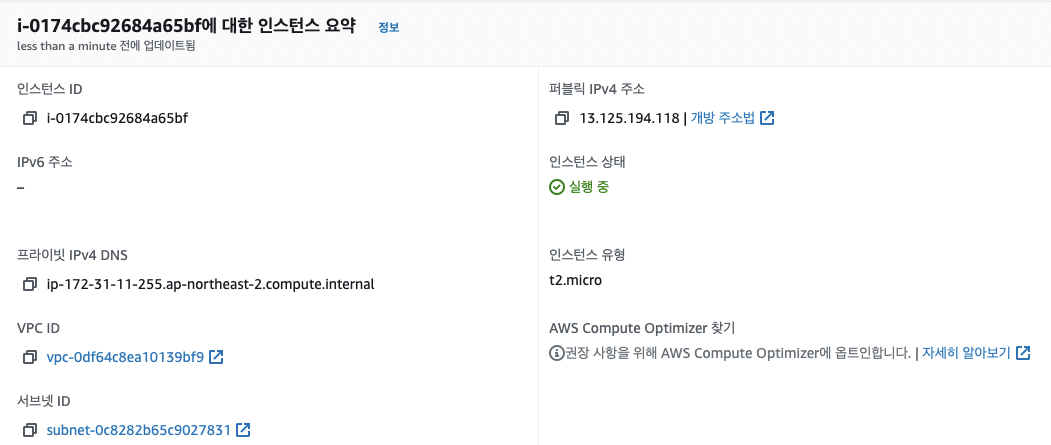
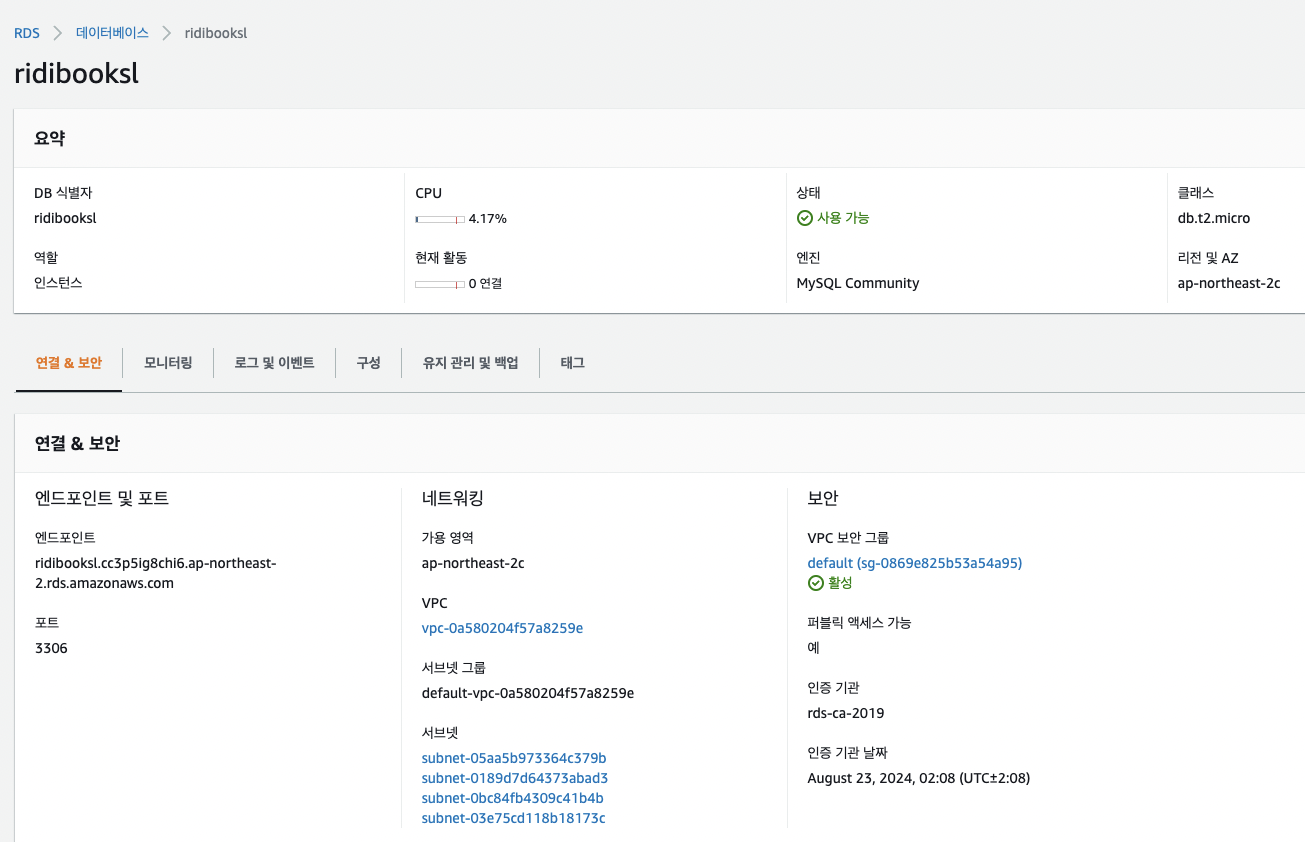
3-5. AWS
AWS EC2 인스턴스 생성, RDS 데이터베이스 생성을 직접 해봤습니다.
EC2의 퍼블릭IP로 연동도 해보고, 데이터도 호스트가 127.0.0.1 이 아닌
AWS 엔드포인트로 설정하여 작업하였습니다.
아직 클론코딩 수준에서 AWS를 배포하는 실력이지만,
현업에 나가 직접 배포할 일이 있을 때 이 때의 경험이 큰 자산이 될거라 확신합니다.