List 代 Tuple
List
우리가 여러개의 값이 필요하다면
a,b,c,d,e ... = 1,2,3,4,5 ... 이런식으로 선언해야 하는데
그러면 수십개, 수백개의 변수를 계속 설정해줘야 한다.
이런 불편함을 없애기 위한 것이 리스트이다.
리스트 : 순서가 있는, 수정가능한 요소의 집합
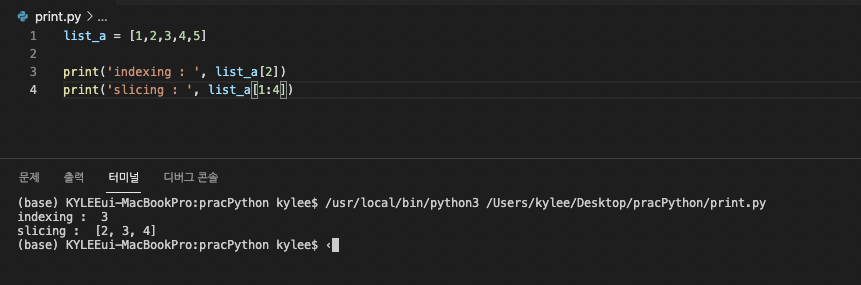
인덱싱과 슬라이싱
인덱싱은 특정위치의 값을 가져오는 것, 슬라이싱은 특정 구간에 속해있는 값을 가져오는 것이다.
그런데 다차원배열이라서 리스트안에 리스트가 있다면?
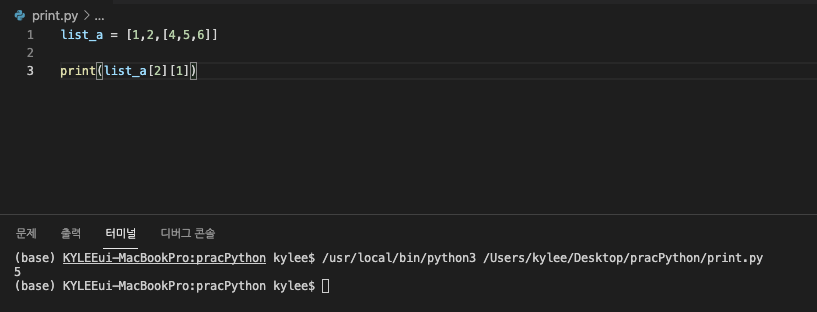
기존의 접근 방식 그대로, 인덱스에 인덱스를 찾아가며 범위를 좁혀가면 된다.
특히 인덱스와 슬라이싱 모두 마이너스 위치를 사용하여 구할 수 있고,
슬라이싱의 경우 간격도 내가 정할 수 있다.
마이너스 인덱스는 역순이라고 생각하면 된다.
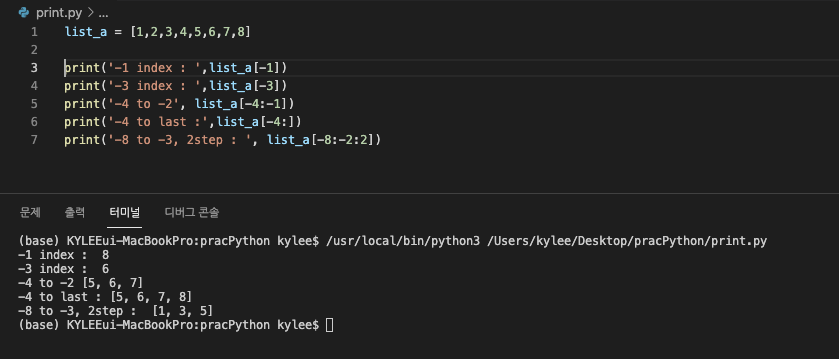
마지막 출력부분에서 뒤에 ':2'라고 쓴 것이 간격(step)이다.
2단위로 건너뛰어서 값을 출력하겠다는 뜻이었다.
리스트 연산
리스트끼리 더할 수도 있고 반복할 수 있다.
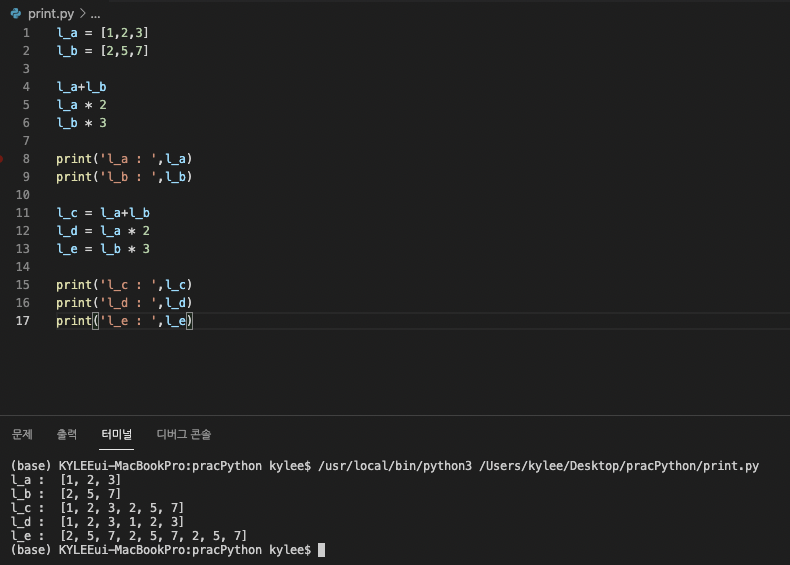
보다시피, 더하거나 곱할 때 그 값을 특정 변수에 대입해야 결과가 반영된다.
이거 유의하자
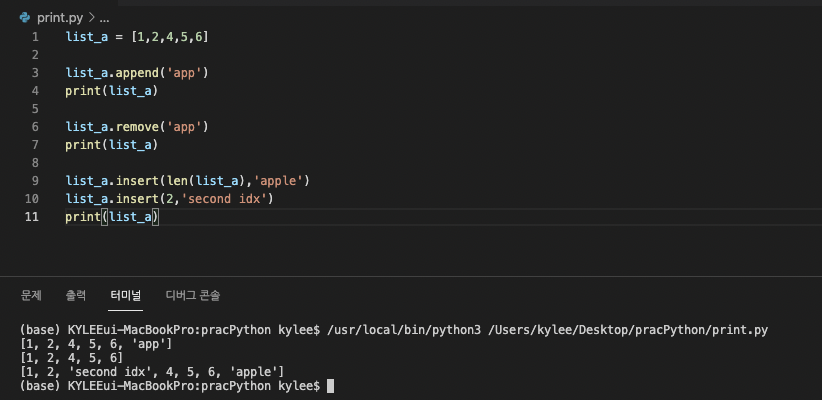
더하는 것과 비슷한 개념으로 리스트에 요소를 추가/삭제하는 경우도 있다.
추가에는 append()와 insert()를 사용하고, 삭제에는 remove()를 사용한다
append(value)는 리스트 맨 마지막에 값을 추가
insert(index,value)는 원하는 위치에 값을 추가
remove(value)는 해당 값이 있을 경우, 가장 최초로 등장한 값 삭제
수정 시, 원하는 인덱스에 값을 넣어주면 된다.
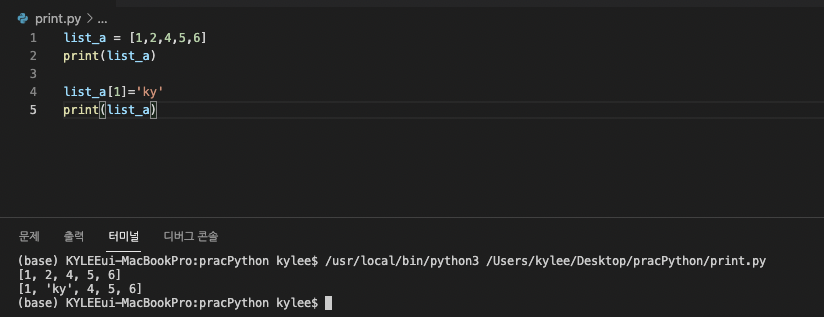
1번째 인덱스의 값을 'ky'라고 설정했더니 바뀐 모습이다.
Tuple
tuple은 리스트와 비슷하게 요소를 저장할 때 사용하되 약간의 차이가 있다.
1. 리스트와 달리 '( )'로 구성되어 있다.
2. 수정 불가
우리가 좌표를 찍을 때, (4,2) 이렇게 찍는 것도 그 좌표는 불변의 위치기 때문이다.
그래서 튜플은 리스트보다 차지하는 메모리 용량이 작다.
당연히 리스트는 더 많은 기능과 flexibility를 제공하기 때문에 클 수밖에 없다.
그래서 간단한 데이터를 사용할 땐 tuple을 사용한다!
