1. 기존 모니터링의 한계
현재, 내가 맡은 회사 프로젝트의 모니터링 시스템에는 아래와 같은 단점이 존재한다.
- 프로젝트 전반적으로 로그가 충분하지 않고, 그나마 있는 로그도 레벨이나 메시지 형식이 제각각이다.
- CloudWatch를 이용한 메트릭이 생각보다 비싸고, 대시보드를 사용하는게 생각보다 불편하다.
- CloudWatch Logs에서 로그를 다양한 조건으로 필터링 하기가 불편하다.
- 임계치 알림 설정을 하려면 Lambda와 같은 별도 서비스를 이용해야 하는데, 결국 이것도 다 돈이다.
물론, CloudWatch는 정말 잘 만들어진 시스템이지만 점점 메트릭과 로그가 다양해지는 상황에서 개인적으로 불편함을 느꼈던 것 같다.
2. 목표
새롭게 적용할 모니터링 시스템의 목표를 아래와 같이 결정했다.
- 프로젝트 전반적으로 로그를 세세하게 작성한다.
- 로그 레벨의 기준과 메시지의 형식을 정한다.
- 컨텍스트 파악을 용이하게 하기 위해 MDC를 이용한다.
- 서버 인스턴스 뿐만 아니라, Spring과 DB 그리고 모니터링 시스템 자체에 대한 모니터링도 진행한다.
- Slack으로 임계치 알림이 올 수 있도록 설정한다.
그리고 이를 위해, 사람들이 많이 사용하는 Grafana + Promtail + Loki + Prometheus 조합을 이용해 구축하고자 했다.
ELK도 많이 사용하긴 하는데, 아직 주니어로서 ElasticSearch는 내 실력에 다루기 쉽지 않을 거라 판단하여 선택하지 않았다.
3. 설계
Grafana + Promtail + Loki + Prometheus에서 각각의 역할은 다음과 같다.
Grafana: Loki와 Prometheus를 통해 수집한 데이터를 하나의 대시보드로 시각화 해주는 역할Promtail: 로컬에서 로그 파일을 실시간으로 감시하여, 새 로그가 감지되면 Loki로 전송하는 역할Loki: Promtail이 전송한 로그 데이터를 수집 및 저장하는 역할Prometheus: 메트릭 데이터를 수집 및 저장하는 역할
이를 바탕으로 아키텍처를 다음과 같이 설정했다. 애플리케이션 서버가 꺼지더라도 모니터링 서버는 안전할 수 있도록 서버를 독립적으로 구성했다.
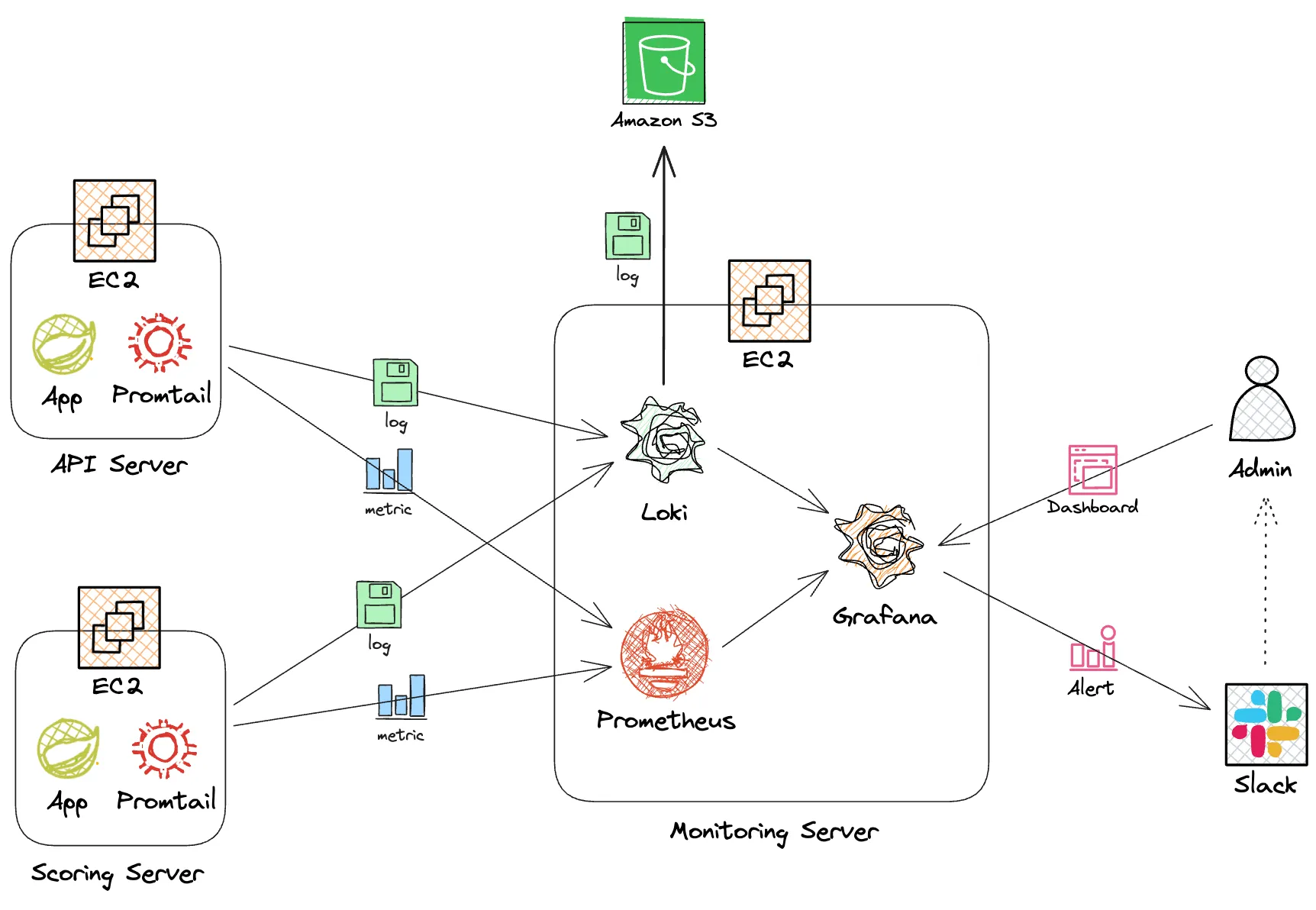
- 각 애플리케이션에서 로그가 발생하고 이를
xxx.log파일로 저장한다. (logback을 이용) - Promtail이 이를 감지하고 Loki로 로그를 전송한다. 이때, 어느 서버에서 발생한 로그인지 라벨링해서 전송한다.
- Loki는 로그를 보관하고 인덱스를 생성한다. 일정 주기마다 S3로 장기 보관한다.
- Admin은 Grafana 대시보드를 통해 Loki로 부터 로그를 불러와 볼 수 있다.
- Prometheus는 지속적으로 Spring actuator를 호출하여 메트릭 정보를 가져온다.
- Admin이 Grafana 대시보드를 통해 Prometheus로 부터 메트릭을 불러와 볼 수 있다.
- 메트릭이나 로그가 사전에 설정한 임계치에 다다르면 Slack으로 알림을 전송한다.
4. 형식 및 기준
4-1. 메시지 형식
먼저, 로그 메시지의 형식은 Json 형식의 구조화된 형식을 따르기로 결정하였다.
timestamp: 로그 생성 시각level: 로그 레벨 (DEBUG, INFO, WARN, ERROR)threadName: 스레드 이름loggerName: 로거 이름message: 로그 메시지- 예외 상황에서는 최대한 원인과 문제 데이터를 담으려고 노력한다.
- 영어보다는 한글로 작성한다.
stacktrace: 스택트레이스 (예외 상황에서만 출력)context: 로그의 문맥을 파악하도록 도와주는 항목들 (MDC)instanceId- 서버 인스턴스 별로 구분endpoint- API Path 별로 구분httpMethod- HTTP Method 별로 구분memberId- 사용자 ID 별로 구분
예시를 보여주자면 아래와 같다.
{
"timestamp": "2025-01-01T00:00:00.000+0900",
"level": "INFO",
"threadName": "http-nio-8080-exec-1",
"loggerName": "com.example.hello",
"context": {
"instanceId": "a-123456789abcde",
"endpoint": "/api/v1/articles/1",
"httpMethod": "GET",
"memberId": "1"
},
"message": "1번 Article 조회"
}4-2. 로그 레벨
또한, 팀원끼리 합의하여 로그 레벨에 관한 기준도 결정하였다.
- DEBUG
- 개발 및 문제 진단을 위한 상세 로그 레벨을 의미한다.
- 개발 환경이나 테스트 환경에서만 출력되는 로그로 운영 환경에서는 출력하지 않는다.
세부 동작 흐름, 내부 객체 상태, 매개변수 값, DB 쿼리, 요청/응답 상세를 기록한다.
- INFO
- 정상 동작 이벤트를 나타내는 로그 레벨을 의미한다.
시스템 초기화/종료, 환경 설정 값, 주요 비즈니스 처리 과정(시작, 완료 등)을 기록한다.
- WARN
- 잠재적인 문제이지만 당장 큰 오류는 아닌 상황을 나타내는 로그 레벨을 의미한다.
사용자 입력 오류, try에서 예외가 발생했으나 catch에서 핸들링한 경우를 기록한다.
- ERROR
- 시스템 동작에 치명적인 문제가 발생했음을 나타내는 로그 레벨을 의미한다.
복구 불가능한 예외, DB 접근 실패, 디스크 공간 부족, OOM, 외부 API 오류로 인한 비즈니스 로직 실패 등서버 에러를 기록한다.
4-3. 임계치 알림
마지막으로, 메트릭과 로그의 임계치 알림 기준은 다음과 같이 결정하였다. 하지만 이는 서비스를 운영하면서 계속 동적으로 변할 예정이다.
cpu사용률이 80% 이상으로 5분 이상 지속되면 알림 & 95% 이상이면 알림메모리사용률이 80% 이상으로 5분 이상 지속되면 알림 & 95% 이상이면 알림디스크사용률이 95% 이상이면 알림HikariCP활성 커넥션 수가 최대 커넥션 풀의 90% 이상인 경우 알림Tomcat활성 스레드 수가 최대 스레드 수의 90% 이상인 경우 알림- 애플리케이션이 갑작스럽게 종료되면 알림
- WARN 레벨의 로그가 1분 당 20개 이상일 경우 알림
- ERROR 레벨의 로그가 1개라도 발생하면 알림 (너무 알림이 빈번해지면 1분 당 5개 이상일 경우 알림으로 변경 예정)
5. 구현
어느정도 설계와 합의를 진행하였으니, 실제로 모니터링 시스템을 구축해보자.
5-1. Promtail을 이용한 로그 전송
먼저, 각 애플리케이션이 존재하는 서버에 Promtail을 설치하여 애플리케이션 로그를 모니터링 서버로 전송하도록 해야한다.
Promtail은 docker compose를 이용하면 간단하게 띄울 수 있다.
$ vim docker-compose.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
{} 안의 내용은 직접 명시해야 한다.
services:
promtail:
image: grafana/promtail:3.4.1
container_name: promtail
restart: unless-stopped
volumes:
- {애플리케이션 로그의 절대 경로}:/logs:ro
- ./promtail/promtail-config.yaml:/etc/promtail/promtail-config.yaml
- ./promtail/positions:/tmp
command:
- --config.file=/etc/promtail/promtail-config.yaml- 애플리케이션 로그가 생성되는 절대 경로와, Promtail의
/logs폴더를 읽기 전용으로 마운트한다. promtail-config.yaml은 Promtail에 대한 환경 설정 파일이고, 직접 만들어서 사용할 예정이다./position은 로그 파일을 어디까지 읽었는지 그 위치(offset)을 저장하는 폴더이다. 이는 Promtail이 중복으로 로그 수집을 하지 않도록 한다.- Promtail은 별도의 포트 포워딩을 하지 않아도 된다.
이후, 동일 경로에 /promtail 폴더를 만들고 그 안에 promtail-config.yaml까지 작성한다.
$ mkdir promtail
$ cd promtail
$ vim promtail-config.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://{Loki가 있는 EC2의 private ip}:3100/loki/api/v1/push
tenant_id: {서비스 별 로그 구분용 id (생략 가능)}
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*.log
- job_name: app
static_configs:
- targets:
- localhost
labels:
job: applogs
__path__: /logs/*.log
pipeline_stages:
- json:
expressions:
timestamp: timestamp
level: level
threadName: threadName
loggerName: loggerName
message: message
stacktrace: stacktrace
endpoint: context.endpoint
instanceId: context.instanceId
httpMethod: context.httpMethod
memberId: context.memberId
- labels:
level: ''
endpoint: ''
instanceId: ''
httpMethod: ''
memberId: ''
- timestamp:
source: timestamp
format: "2006-01-02T15:04:05.000-0700"- clients
url: Promtail이 수집한 로그를 어디로 보낼지에 대한 엔드포인트이다. Loki가 있는 EC2의 private ip를 이용한다.tenant_id: 여러 팀 또는 서비스의 로그를 구분할 수 있는 멀티 테넌시(Multi-tenancy) id를 의미한다. 생략 가능하다.
- scrape_configs
job_name: 로그를 수집하는 job 단위를 의미한다. (우리는 system과 app으로 지정)targets: 로그를 수집할 호스트를 의미한다.job: Grafana에서 검색 시 로그 구분에 사용되는 job 단위를 의미한다. (우리는 varlogs와 applogs로 지정)__path__: 실제 로그 파일이 존재하는 경로를 의미하며, Promtail이 여기서 긁어서 Loki에게 전송한다. (도커 볼륨으로 마운트한 곳)json.expressions: Json 형식의 로그에서 키를 파싱하여 필드로 추출하기 위한 설정이다. (우리 로그가 Json 형식이라 지정)labels: 위에서 추출한 필드 중 일부를 Loki에 라벨로 추가하기 위한 설정이다. 이게 있어야 Grafana에서 라벨로 보인다. 원하는 라벨만 선택적으로 지정하면 된다.timestamp: 로그 내에 기록된 timestamp를 기준으로 Loki에서도 시간 정보를 맞추기 위한 설정이다. 이걸 지정하지 않으면, Loki는 로그가 "기록"된 시간이 아닌, 로그를 "수집"한 시각을 기준으로 로그를 보여준다.
모두 작성했다면 docker compose를 이용해 Promtail을 띄우면, 자동으로 환경 설정이 반영되며 컨테이너가 시작한다.
$ docker compose up -d5-2. Loki를 이용한 로그 수집
애플리케이션 서버에서 Promtail을 띄웠으니, 이번에는 모니터링 서버에서 Loki를 띄워 로그를 수집해보자.
Loki도 docker compose를 이용하면 간단하게 띄울 수 있다.
$ vim docker-compose.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
services:
loki:
image: grafana/loki:3.4.1
container_name: loki
restart: unless-stopped
user: root
volumes:
- ./loki/data:/loki
- ./loki/loki-config.yaml:/etc/loki/loki-config.yaml
ports:
- "3100:3100"
command:
- --config.file=/etc/loki/loki-config.yaml- 설정은 Promtail과 비슷한데, Loki는 3100번 포트로 포워딩을 해야한다.
- 혹시나 권한 문제가 발생하면 위처럼 user를 root로 실행하면 된다.
이후, 동일 경로에 /loki 폴더를 만들고 그 안에 loki-config.yaml까지 작성한다.
$ mkdir loki
$ cd loki
$ vim loki-config.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
auth_enabled: true
server:
http_listen_port: 3100
common:
ring:
instance_addr: 127.0.0.1
kvstore:
store: inmemory
replication_factor: 1
path_prefix: /loki
schema_config:
configs:
- from: 2025-01-01
store: tsdb
object_store: s3
schema: v13
index:
prefix: index_
period: 24h
storage_config:
tsdb_shipper:
active_index_directory: /loki/index
cache_location: /loki/index_cache
aws:
s3: s3://ap-northeast-2/{로그를 장기 저장할 S3 버킷 이름}
s3forcepathstyle: true
limits_config:
retention_period: 744h # 로그 보존 기간: 31일
compactor:
working_directory: /loki/compactor
compaction_interval: 10m
retention_enabled: true
retention_delete_delay: 2h
delete_request_store: s3auto_enabled: true로 설정하면 Loki로 들어온 요청의X-Scope-OrgID헤더 값을 검사한다. Promtail에서 작성한 tenant_id가 해당 헤더 값이 된다. 즉auto_enabled : true는 멀티 테넌시를 가능하게 하여, Loki가 각 서버의 로그를 구분할 수 있게 해준다.common: Loki의 클러스터링 관련 설정으로, 여기서는 싱글 인스턴스를 기준으로한다.schema_config: Loki가 TSDB 기반으로 로그를 저장하며, S3와 같은 스토리지를 사용할 수 있게 설정한다.storage_config: 인덱스를 임시로 저장할 곳과 장기로 저장할 곳을 설정한다.limits_config: 여기서는 로그 보존 기간을 744시간(=31일)로 설정했다.compactor: 로그 압축 및 보존 정책에 따른 삭제 기능을 설정한다. 10분마다 압축을 수행하고, S3에서 위에 설정한 로그 보존 기간이 지난 로그를 삭제한다.
모두 작성했다면 docker compose를 이용해 Loki를 띄우면, 자동으로 환경 설정이 반영되며 컨테이너가 시작한다.
$ docker compose up -d이후 Promtail과 Loki의 로그를 살피면서, 로그를 잘 전송하고 수집하는지 확인한다.
5-3. Prometheus를 이용한 메트릭 수집
다음은 Prometheus를 이용해 애플리케이션의 메트릭 정보를 수집해보자. Spring actuator과 연동하여 메트릭 정보를 가져올 수 있다.
먼저, 프로젝트의 build.gradle에 Spring actuator와 Prometheus 의존성을 추가한다.
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'그리고 application.yaml에서 Spring actuator의 엔드포인트를 열어줘야 한다.
...(생략)
management:
endpoints:
web:
exposure:
include:
- prometheus이제 모니터링 서버에서 Prometheus를 띄워보자. Prometheus도 docker compose를 이용하면 간단하게 띄울 수 있다.
$ vim docker-compose.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
services:
...(Loki 관련 설정 생략)
prometheus:
image: prom/prometheus:v3.2.1
container_name: prometheus
restart: unless-stopped
user: root
volumes:
- ./prometheus/prometheus-config.yaml:/etc/prometheus/prometheus.yaml
- ./prometheus/data:/prometheus
ports:
- "9090:9090"
command:
- --config.file=/etc/prometheus/prometheus.yaml- 위에서 작성한 Loki 관련 설정 아래에 Prometheus 설정을 추가한다.
- Prometheus는 9090 포트를 사용하므로 해당 포트 번호로 포워딩을 해야한다.
이후, 동일 경로에 /prometheus 폴더를 만들고 그 안에 prometheus-config.yaml까지 작성한다.
$ mkdir prometheus
$ cd prometheus
$ vim prometheus-config.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: [ 'localhost:9090' ]
- job_name: 'loki'
static_configs:
- targets: [ 'loki:3100' ]
- job_name: 'server1_metric'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: [ '{server1 private ip}:8080' ]
labels:
instance: 'server1'
- job_name: 'server2_metric'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: [ '{server2 private ip}:8080' ]
labels:
instance: 'server2'scrape_interval: 메트릭을 수집하는 주기를 설정한다. 여기서는 15초마다 메트릭을 수집하도록 하였다.job_name: 메트릭을 수집하는 job의 이름을 설정한다.metrics_path: 메트릭을 수집할 엔드포인트를 설정한다. 여기서는 Spring actuator에서 prometheus 관련 엔드포인트로 설정하였다.targets: 메트릭을 수집할 호스트 및 포트 번호를 설정한다.labels: grafana와 같은 대시보드에서 메트릭을 식별하는 라벨을 설정한다.
모두 작성했다면 docker compose를 이용해 Prometheus를 띄우면, 자동으로 환경 설정이 반영되며 컨테이너가 시작한다.
$ docker compose up -d5-4. Grafana를 이용한 메트릭과 로그 시각화
지금까지 한 일을 정리해보자.
- Promtail을 이용해 애플리케이션 서버의 로그를 모니터링 서버로 전송하였다.
- Loki를 이용해 Promtail이 전송한 로그를 수집하여 인덱스를 만들고, S3에 장기 저장까지 하였다.
- Prometheus를 이용해 애플리케이션의 actuator를 호출하여 메트릭 정보를 수집하였다.
이로써, 메트릭과 로그 정보를 모두 수집하는 것까지는 완료되었다. 하지만 아직 이들을 우리가 볼 수 있는 형태의 시각화가 되지 않았는데, 이를 Grafana를 통해 대시보드의 형태로 만들어보자.
모니터링 서버에서 Grafana 또한 docker compose를 이용하여 띄울 예정이다.
$ vim docker-compose.yaml그리고 내부에 아래와 같이 작성하고 저장한다.
services:
...(Loki, Prometheus 관련 설정 생략)
grafana:
image: grafana/grafana:11.6.0
container_name: grafana
restart: unless-stopped
user: root
volumes:
- ./grafana:/var/lib/grafana
ports:
- "3000:3000"- Grafana는 3000번 포트를 사용하므로 해당 포트 번호로 포워딩을 해야한다.
- 여기서 중요한 건 Grafana의 설정을 계속 유지하기 위해서는 반드시
/var/lib/grafana을 docker volume으로 마운트 해야한다는 것이다.
모두 작성했다면 docker compose를 이용해 Grafana를 띄운다.
$ docker compose up -d모니터링 서버의 3000번 포트로 브라우저에서 접속하면 로그인 화면이 나타난다.
- 초기 계정과 비밀번호는 모두
admin이다. 이후 자유롭게 변경할 수 있다.
로그인 후 Home > Connections > Data sources에 들어가서 Prometheus와 Loki를 데이터소스로 등록한다.
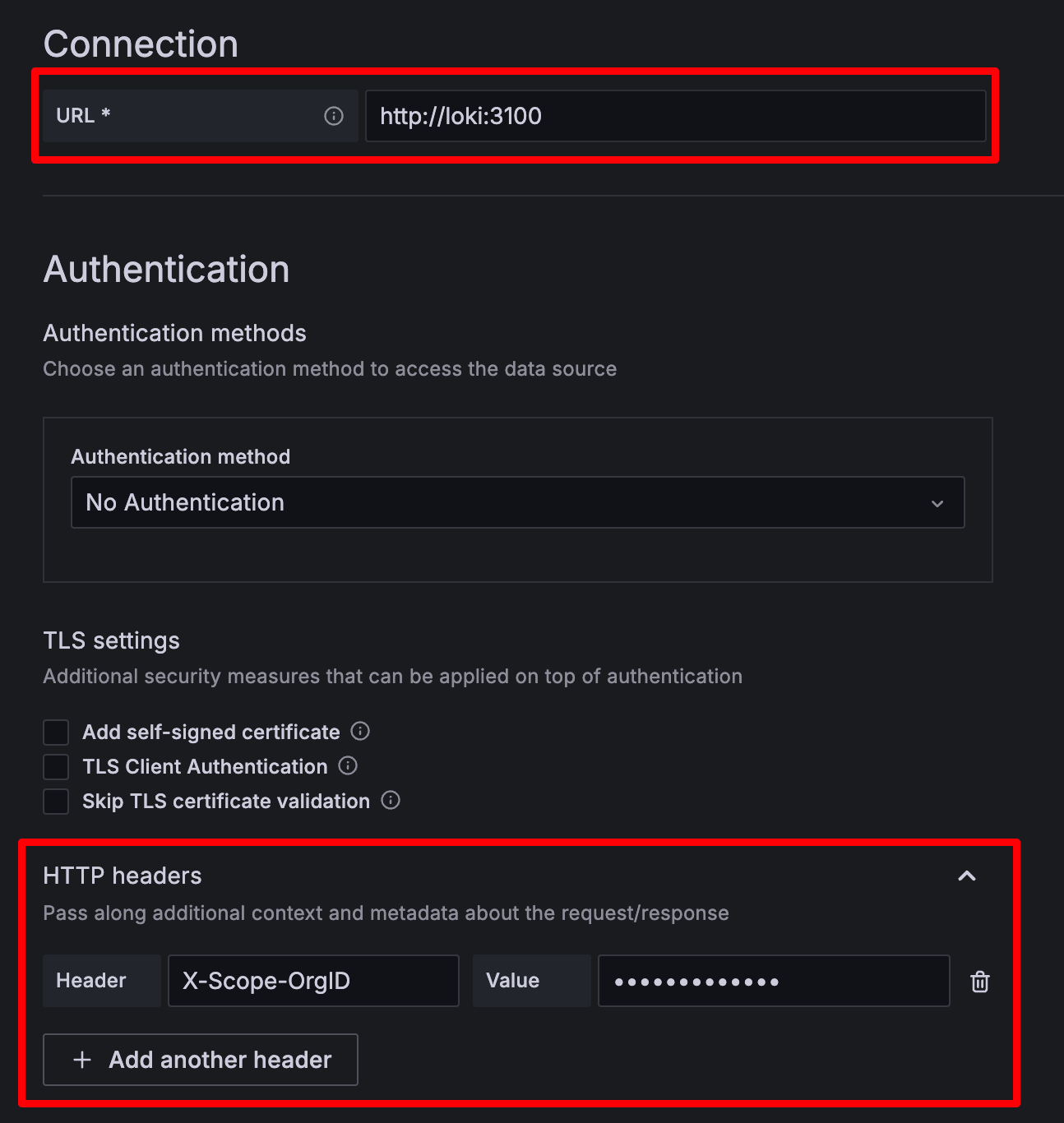
- Loki를 등록할 때는 일단 URL에 localhost가 아니라 docker에서 사용하는 loki로 해야한다. Grafana와 Loki가 같은 docker network에 띄워져 있기 때문이다.
- 멀티 테넌시 설정을 통해 Loki에 서로 다른 그룹의 로그들을 보내고 있기 때문에,
X-Scope-OrgID헤더를 추가하고promtail-config.yaml에tenant_id로 작성한 값을 넣어야 한다. (안보여서 좀 불편하다) - 멀티 테넌시를 적용하는 로그 그룹 개수만큼 각각의 Loki 데이터소스를 따로 만들어줘야 한다.
마찬가지로 Prometheus도 추가해주면 결론적으로는 아래와 같이 데이터소스가 마련된다. (서버 2개에서 로그를 각각 따로 보내므로 Loki도 2개 생성)
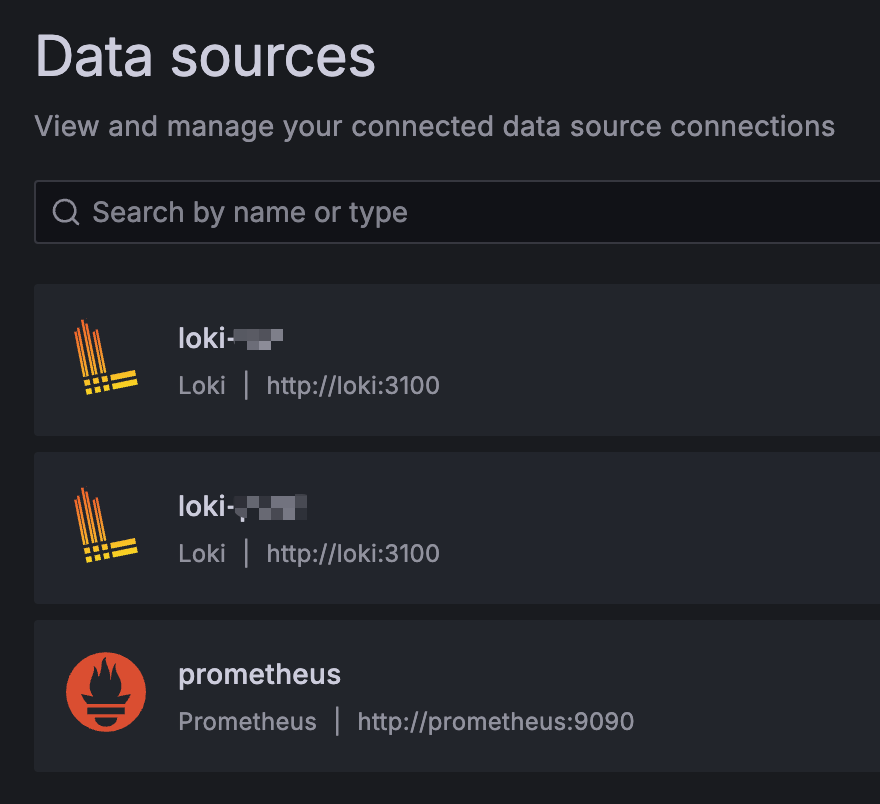
이후 Grafana Dashboard를 제공하는 사이트에 접속하여 원하는 대시보드를 템플릿처럼 가져올 수 있다.
개인적으로는 Spring Boot 3.x Statistics라는 대시보드를 가져와서 Prometheus가 가져온 메트릭과 연결하였다.
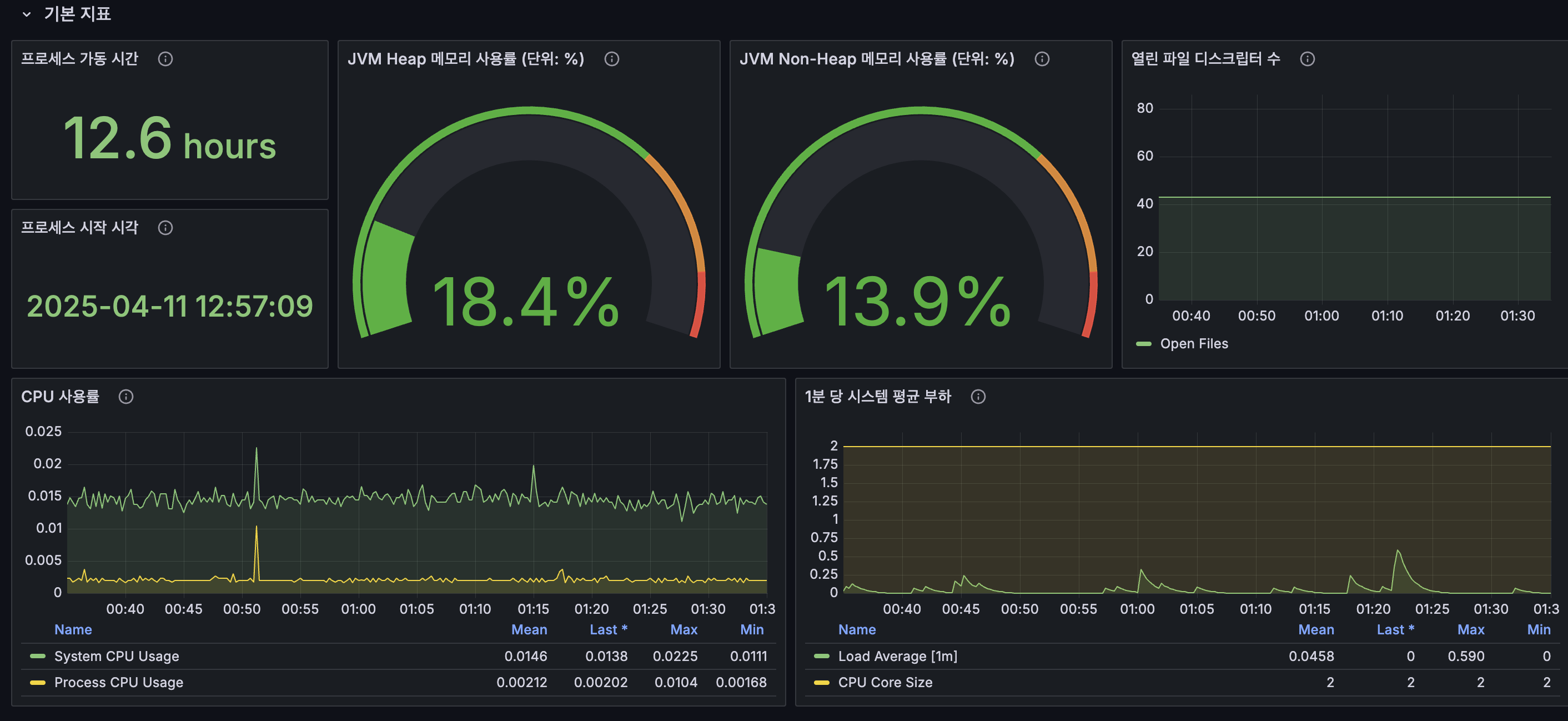
로그의 경우, 유튜브 영상을 보면서 따라 만들었는데 나쁘지 않았다. 완성된 대시보드는 아래와 같다.
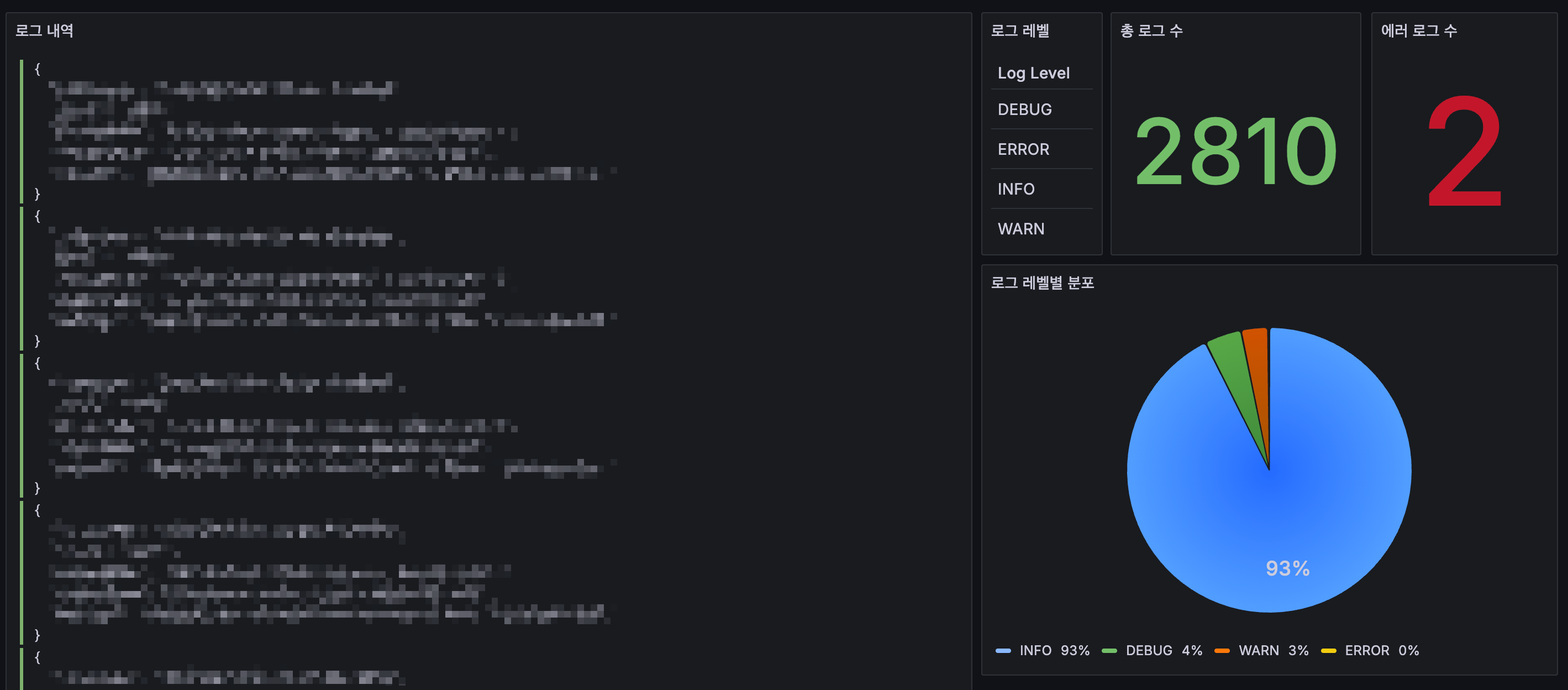
6. 정리
기존 모니터링 시스템의 한계를 느끼고 이를 개선하기 위해 새로운 모니터링 시스템을 구축해보았다.
이로써 초반에 계획했던 목표를 거의 대부분 만족시킨 것 같다.
Slack으로 임계점 알림도 Grafana Alerting 기능을 이용해 진행하였는데, 단순한 작업이기도 하고 글이 너무 길어질 것 같아서 생략했다.
추가적으로 고려해야 하는 사항에 대해 아래와 같이 생각해보았다.
- 각 애플리케이션 서버에서 모니터링 서버로 메트릭과 로그 정보를 전송할 때도 SSL 통신을 이용해 보안처리를 고려한다.
- Promtail, Loki, Prometheus 자체에 대한 모니터링도 별도로 고려한다.
- 추후 로그가 너무 많아지거나 자주 전송되는 환경을 고려해 메시지큐의 도입도 고려한다. (당분간은 괜찮다)
